Quartz深度实战
概述
Java语言中最正统的任务调度框架,几乎是首选。后来和Spring Schedule平分秋色;再后来会被一些轻量级的分布式任务调度平台,如XXL-Job取代。另外近几年Quartz的维护和发布几乎停滞,但这并不意味着Quartz被淘汰,还有学习和使用的价值。
入门
SB版本是2.0.0+,则spring-boot-starter-quartz中已经包含quart的依赖,可直接使用:
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-quartzartifactId>
dependency>
SB 1.5.9及以下版本,需添加依赖:
<dependency>
<groupId>org.quartz-schedulergroupId>
<artifactId>quartzartifactId>
dependency>
<dependency>
<groupId>org.springframeworkgroupId>
<artifactId>spring-context-supportartifactId>
dependency>
配置类QuartzConfig,一个简单的SimpleScheduleBuilder,每隔10s调度执行一次:
@Configuration
public class QuartzConfig {
@Bean
public JobDetail teatQuartzDetail() {
return JobBuilder.newJob(TestQuartz.class).withIdentity("testQuartz").storeDurably().build();
}
@Bean
public Trigger testQuartzTrigger() {
SimpleScheduleBuilder scheduleBuilder = SimpleScheduleBuilder.simpleSchedule()
.withIntervalInSeconds(10).repeatForever();
return TriggerBuilder.newTrigger().forJob(teatQuartzDetail())
.withIdentity("testQuartz").withSchedule(scheduleBuilder).build();
}
}
创建demo类继承QuartzJobBean:
@Slf4j
public class TestQuartz extends QuartzJobBean {
@Override
protected void executeInternal(JobExecutionContext context) {
log.info("quartz task " + new Date());
}
}
控制台打印输出:
2022-11-24 22:02:06.517 [INFO][quartzScheduler_Worker-3]:com.johnny.demo.TestQuartz [executeInternal:16] quartz task Thu Nov 24 22:02:06 CST 2022
2022-11-24 22:02:16.518 [INFO][quartzScheduler_Worker-4]:com.johnny.demo.TestQuartz [executeInternal:16] quartz task Thu Nov 24 22:02:16 CST 2022
实战
实际应用中,一般都是使用CronTrigger:
@Slf4j
@Service
public class JobService implements InitializingBean {
@Resource
private SchedulerFactoryBean schedulerFactoryBean;
private void configScheduler() {
Scheduler scheduler = schedulerFactoryBean.getScheduler();
try {
scheduler.clear();
} catch (SchedulerException e) {
log.error("clear scheduler failed: ", e);
}
try {
DashboardDataset dataset = datasetMapper.getDataset(id);
// 数据集定时任务的cron表达式不为空
if (StringUtils.isNotEmpty(dataset.getCronExp())) {
JobDetail jobDetail = JobBuilder.newJob(DatasetJobExecutor.class).withIdentity("dataset_" + dataset.getId().toString()).build();
CronTrigger trigger = TriggerBuilder.newTrigger().withIdentity("dataset_" + dataset.getId().toString()).withSchedule(CronScheduleBuilder.cronSchedule(dataset.getCronExp())).build();
jobDetail.getJobDataMap().put("dataset", dataset);
scheduler.scheduleJob(jobDetail, trigger);
}
} catch (Exception e) {
logger.error("start dataset job error:{}", e);
}
}
@Override
public void afterPropertiesSet() throws Exception {
configScheduler();
}
}
public class DatasetJobExecutor implements Job {
@Override
public void execute(JobExecutionContext context) throws JobExecutionException {
DatasetMapper datasetMapper = ((ApplicationContext) context.getScheduler().getContext().get("applicationContext")).getBean(DatasetMapper.class);
// 业务逻辑
}
}
配置
配置文件quartz.properties:
org.quartz.scheduler.instanceName=quartzScheduler
org.quartz.scheduler.instanceId=AUTO
org.quartz.jobStore.class=org.quartz.impl.jdbcjobstore.JobStoreTX
org.quartz.jobStore.driverDelegateClass=org.quartz.impl.jdbcjobstore.StdJDBCDelegate
org.quartz.jobStore.tablePrefix=QRTZ_
org.quartz.jobStore.isClustered=true
org.quartz.jobStore.clusterCheckinInterval=20000
org.quartz.threadPool.class=org.quartz.simpl.SimpleThreadPool
# 设置线程池
org.quartz.threadPool.threadCount=200
org.quartz.threadPool.threadPriority=5
org.quartz.threadPool.threadsInheritContextClassLoaderOfInitializingThread=true
原理
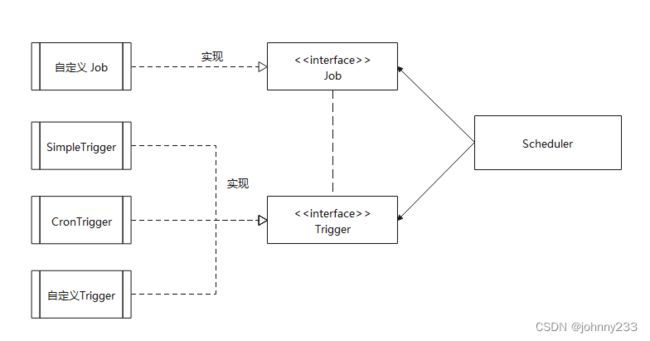
Quartz设计的核心类包括Scheduler,Job及Trigger。Job负责定义需要执行的任务,Trigger负责设置调度策略,Scheduler将二者组装在一起,并触发任务开始执行。
Job
Job接口的源码:
public interface Job {
void execute(JobExecutionContext var1) throws JobExecutionException;
}
JobExecutionContext类提供调度应用的一些信息。使用者只需创建一个 Job 的实现类,实现其中的execute方法。
Trigger
用于设置调度策略。Quartz设计多种类型的Trigger,但最常用只有2种:
- SimpleTrigger
适用于在某一特定的时间执行一次,或在某一特定的时间以某一特定时间间隔执行多次。参数包括 start-time,end-time,repeat count,repeat interval。- Repeat count:取值为>=0的整数,或常量
SimpleTrigger.REPEAT_INDEFINITELY - Repeat interval:取值为>=0的长整型。当 Repeat interval 取值为零且Repeat count 取值大于零时,将会触发任务的并发执行
- Start-time 与 end-time 取值为
java.util.Date。同时指定 end-time 与 repeat count 时,优先考虑 end-time。一般地,可以指定 end-time,并设定 repeat count 为 REPEAT_INDEFINITELY
- Repeat count:取值为>=0的整数,或常量
- CronTrigger
用途更广,相比基于特定时间间隔进行调度安排的 SimpleTrigger,适用于基于日历的调度安排,需要指定 start-time 和 end-time,Cron。Cron由七个字段组成:Seconds、Minutes、Hours、Day-of-Month、Month、Day-of-Week、Year (Optional field)。
Job 与 Trigger 的松耦合设计,其优点在于同一个 Job 可以绑定多个不同的 Trigger,同一个 Trigger 也可以调度多个 Job,灵活性很强。
Scheduler
代表Quartz的一个独立运行容器, Trigger和JobDetail可注册到Scheduler中, 两者在Scheduler中拥有各自的组及名称, 组及名称是Scheduler查找定位容器中某一对象的依据, Trigger的组及名称必须唯一, JobDetail的组和名称也必须唯一(但可以和Trigger的组和名称相同,因为它们是不同类型的)。Scheduler定义多个接口方法,允许外部通过组及名称访问和控制容器中Trigger和JobDetail。
Scheduler可以将Trigger绑定到某一JobDetail中, 这样当Trigger触发时, 对应的Job就被执行。一个Job可以对应多个Trigger, 但一个Trigger只能对应一个Job。可以通过SchedulerFactory创建一个Scheduler实例。Scheduler拥有一个SchedulerContext,它类似于ServletContext,保存着Scheduler上下文信息,Job和Trigger都可以访问SchedulerContext内部信息。SchedulerContext内部通过一个Map以键值对的方式维护这些上下文数据,SchedulerContext为保存和获取数据提供多个put()和getXxx()的方法。可通过Scheduler.getContext()获取对应的SchedulerContext实例。
JobDetail
源码如下:
public interface JobDetail extends Serializable, Cloneable {
public JobKey getKey();
public String getDescription();
/**
* Get the instance of Job that will be executed.
*/
public Class<? extends Job> getJobClass();
/**
* Get the JobDataMap that is associated with the Job.
*/
public JobDataMap getJobDataMap();
/**
* Whether or not the Job should remain stored after it is orphaned (no @Triggers point to it).
* If not explicitly set, the default value is false.
* @return true if the Job should remain persisted after being orphaned.
*/
public boolean isDurable();
/**
* @return whether the associated Job class carries the @PersistJobDataAfterExecution annotation.
*/
public boolean isPersistJobDataAfterExecution();
/**
* @return whether the associated Job class carries the @DisallowConcurrentExecution annotation.
*/
public boolean isConcurrentExectionDisallowed();
/**
* Instructs the Scheduler whether or not the Job should be re-executed if a 'recovery' or 'fail-over' situation is encountered.
* If not explicitly set, the default value is false.
*/
public boolean requestsRecovery();
public Object clone();
/**
* Get a JobBuilder that is configured to produce a JobDetail identical to this one.
*/
public JobBuilder getJobBuilder();
}
JobDetail负责封装Job及Job的属性,并将其提供给 Scheduler 作为参数。每次 Scheduler 执行任务时,首先会创建一个 Job 的实例。注意到,不是直接接受一个Job的实例,相反它接收一个Job实现类(即JobDetail),运行时通过newInstance()的反射机制实例化Job,然后再调用 execute 方法执行。Quartz 没有为 Job 设计带参数的构造函数,因此需要通过额外的 JobDataMap 来存储 Job 的属性。JobDataMap可存储任意数量的 Key,Value 对。
任务执行结束后,关联的Job对象实例会被释放,且会被JVM GC清除。
为什么设计成JobDetail + Job,不直接使用Job?
JobDetail 定义的是任务数据,而真正的执行逻辑是在Job中。因为任务有可能并发执行,如果Scheduler直接使用Job,就会存在对同一个Job实例并发访问的问题。Sheduler每次执行,都会根据JobDetail创建一个新的Job实例,这样就可以 规避并发访问 的问题。
Listener
Quartz提供Listener功能:JobListener,TriggerListener及 SchedulerListener。用于当系统发生故障,通知到配置的告警人。当任务被执行时系统发生故障,Listener监听到错误,立即发送邮件给管理员。
Quartz拥有完善的事件和监听体系,大部分组件都拥有事件,如任务执行前事件、任务执行后事件、触发器触发前事件、触发后事件、调度器开始事件、关闭事件等,可注册相应的监听器处理感兴趣的事件。
Calendar
即org.quartz.Calendar,java.util.Calendar不同, 是一些日历特定时间点的集合。 一个Trigger可以和多个Calendar关联, 以便排除或包含某些时间点。比如,安排每周一早上10:00执行任务,但碰到法定节假日,任务不执行,这时就需要在Trigger触发机制的基础上使用Calendar进行定点排除。针对不同时间段类型,Quartz在org.quartz.impl.calendar包下提供若干个Calendar的实现类,如AnnualCalendar、MonthlyCalendar、WeeklyCalendar分别针对每年、每月和每周进行定义;
ThreadPool
Scheduler使用一个线程池作为任务运行的基础设施,任务通过共享线程池中的线程提高运行效率。
有无状态
Job有一个StatefulJob子接口,代表有状态的任务,该接口是一个没有方法的标签接口,其目的是让Quartz知道任务的类型,以便采用不同的执行方案。无状态任务在执行时拥有自己的JobDataMap拷贝,对JobDataMap的更改不会影响下次的执行。而有状态任务共享共享同一个JobDataMap实例,每次任务执行对JobDataMap所做的更改会保存下来,后面的执行可以看到这个更改,也即每次执行任务后都会对后面的执行发生影响。
正因为这个原因,无状态的Job可以并发执行,而有状态的StatefulJob不能并发执行,这意味着如果前次的StatefulJob还没有执行完毕,下一次的任务将阻塞等待,直到前次任务执行完毕。有状态任务比无状态任务需要考虑更多的因素,程序往往拥有更高的复杂度,因此除非必要,应该尽量使用无状态的Job。StatefulJob接口在2.2.3版本已经被标记为@deprecated。
如果Quartz使用数据库持久化任务调度信息,无状态的JobDataMap仅会在Scheduler注册任务时保持一次,而有状态任务对应的JobDataMap在每次执行任务后都会进行保存。
Trigger自身也可以拥有一个JobDataMap,其关联的Job可以通过JobExecutionContext.getTrigger().getJobDataMap()获取Trigger中的JobDataMap。不管是有状态还是无状态的任务,在任务执行期间对Trigger的JobDataMap所做的更改都不会进行持久,也即不会对下次的执行产生影响。
注解
@DisallowConcurrentExecution
如果任务不能支持并发执行(比如任务还没执行完, 下一轮就trigger时间到达, 如果没做同步处理可能造成严重的数据问题), 则在任务类加上注解:@DisallowConcurrentExecution,等待任务执行完毕以后再去执行。
@PersistJobDataAfterExecution
An annotation that marks a Job class as one that makes updates to its JobDataMap during execution, and wishes the scheduler to re-store the JobDataMap when execution completes.
Jobs that are marked with this annotation should also seriously consider using the @DisallowConcurrentExecution annotation, to avoid data storage race conditions with concurrently executing job instances.
执行后保留作业数据
插件
即Plug-Ins,Quartz提供一个SPI接口org.quartz.spi.SchedulerPlugin来实现插件(plugging-in)功能。装配给Quartz的Plugins能提供不同的有用功能,参考org.quartz.plugins包下面已经提供的插件:
- LoggingJobHistoryPlugin & LoggingTriggerHistoryPlugin:调度器启动时自动调度jobs,记录job和triggers事件的历史;
- ShutdownHookPlugin:当JVM退出时确保调度器关闭;
- XMLSchedulingDataProcessorPlugin:可通过配置属性文件来使用自己实现或Quartz自带的插件。
misfire
不触发指令
总结
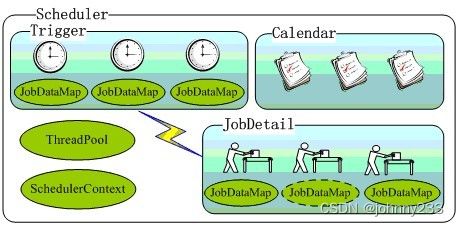
Scheduler的内部组件结构,SchedulerContext提供Scheduler全局可见的上下文信息,每一个任务都对应一个JobDataMap,虚线表达的JobDataMap表示对应有状态的任务:
集群
生产环境中使用Quartz时,服务不可能只部署在一个节点,容易出现单点故障,至少都有2个节点。这种分布式集群情况,Quart自然也是支持的,集群架构图:
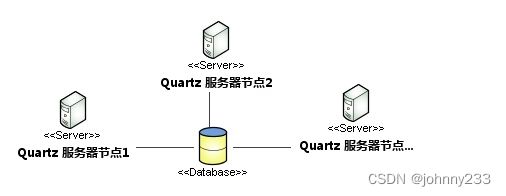
根据这个图,不难得出结论:Quartz是通过数据库锁(悲观锁)来保证多个节点的应用只进行一次调度,即某一时刻的调度任务只由其中一台服务器执行。
集群配置项:org.quartz.jobStore.class=org.quartz.impl.jdbcjobstore.JobStoreTX,从源码可看到JobStoreTX extends JobStoreSupport。
QuartzSchedulerThread职责是触发任务, 是一个不间断运行的Quartz主线程,在QuartzSchedulerThread的run()方法里面调用的acquireNextTriggers、 triggersFired、 releaseAcquiredTrigger方法都进行加锁处理。
以JobStoreSupport.acquireNextTriggers为例:
public List<OperableTrigger> acquireNextTriggers(final long noLaterThan, final int maxCount, final long timeWindow) throws JobPersistenceException {
String lockName;
if(isAcquireTriggersWithinLock() || maxCount > 1) {
lockName = LOCK_TRIGGER_ACCESS;
} else {
lockName = null;
}
}
而LOCK_TRIGGER_ACCESS是个常量:
protected static final String LOCK_TRIGGER_ACCESS = "TRIGGER_ACCESS";
这个常量传入加锁的核心方法executeInNonManagedTXLock: 处理逻辑前获取锁, 处理完成后在finally里面释放锁(一种典型的同步处理方法)
protected <T> T executeInNonManagedTXLock(String lockName, TransactionCallback<T> txCallback, final TransactionValidator<T> txValidator) throws JobPersistenceException {
boolean transOwner = false;
Connection conn = null;
try {
if (lockName != null) {
// If we aren't using db locks, then delay getting DB connection until after acquiring the lock since it isn't needed.
if (getLockHandler().requiresConnection()) {
conn = getNonManagedTXConnection();
}
// 获取锁
transOwner = getLockHandler().obtainLock(conn, lockName);
}
if (conn == null) {
conn = getNonManagedTXConnection();
}
final T result = txCallback.execute(conn);
try {
commitConnection(conn);
} catch (JobPersistenceException e) {
rollbackConnection(conn);
if (txValidator == null || !retryExecuteInNonManagedTXLock(lockName, new TransactionCallback<Boolean>() {
@Override
public Boolean execute(Connection conn) throws JobPersistenceException {
return txValidator.validate(conn, result);
}
})) {
throw e;
}
}
Long sigTime = clearAndGetSignalSchedulingChangeOnTxCompletion();
if (sigTime != null && sigTime >= 0) {
signalSchedulingChangeImmediately(sigTime);
}
return result;
} catch (JobPersistenceException e) {
rollbackConnection(conn);
throw e;
} catch (RuntimeException e) {
rollbackConnection(conn);
throw new JobPersistenceException("Unexpected runtime exception: " + e.getMessage(), e);
} finally {
try {
// 释放锁
releaseLock(lockName, transOwner);
} finally {
cleanupConnection(conn);
}
}
}
getLockHandler那么可以思考下这个LockHandler怎么来的?最后发现在JobStoreSupport的initialize方法赋值:
public void initialize(ClassLoadHelper loadHelper, SchedulerSignaler signaler) throws SchedulerConfigException {
// If the user hasn't specified an explicit lock handler, then choose one based on CMT/Clustered/UseDBLocks.
if (getLockHandler() == null) {
// If the user hasn't specified an explicit lock handler, then we *must* use DB locks with clustering
if (isClustered()) {
setUseDBLocks(true);
}
if (getUseDBLocks()) {
// 在初始化方法里面赋值
setLockHandler(new StdRowLockSemaphore(getTablePrefix(), getInstanceName(), getSelectWithLockSQL()));
} else {
getLog().info("Using thread monitor-based data access locking (synchronization).");
setLockHandler(new SimpleSemaphore());
}
}
}
可以在StdRowLockSemaphore里面看到:
public static final String SELECT_FOR_LOCK = "SELECT * FROM " + TABLE_PREFIX_SUBST + TABLE_LOCKS + " WHERE " + COL_SCHEDULER_NAME + " = " + SCHED_NAME_SUBST + " AND " + COL_LOCK_NAME + " = ? FOR UPDATE";
public static final String INSERT_LOCK = "INSERT INTO " + TABLE_PREFIX_SUBST + TABLE_LOCKS + "(" + COL_SCHEDULER_NAME + ", " + COL_LOCK_NAME + ") VALUES (" + SCHED_NAME_SUBST + ", ?)";
可看出采用悲观锁的方式对triggers表进行加行锁的细粒度锁, 以保证任务同步的正确性。
当线程使用上述的SQL对表中的数据执行操作时,数据库对该行进行行加锁; 于此同时, 另一个线程对该行数据执行操作前需要获取锁, 而此时已被占用, 那么这个线程就只能等待, 直到该行锁被释放。Quartz的锁存放在:
CREATE TABLE `scheduler_locks` (
`SCHED_NAME` varchar(120) NOT NULL COMMENT '调度名',
`LOCK_NAME` varchar(40) NOT NULL COMMENT '锁名',
PRIMARY KEY (`SCHED_NAME`,`LOCK_NAME`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
锁名和上述常量一一对应:
| SCHED_NAME | LOCK_NAME |
|---|---|
| scheduler | STATE_ACCESS |
| scheduler | TRIGGER_ACCESS |
JobStoreTX & JobStoreCMT
查看JobStoreCMT源码:
JobStoreCMT is meant to be used in an application-server environment that provides container-managed-transactions. No commit / rollback will be handled by this class.
If you need commit / rollback,use JobStoreTX instead.
查看JobStoreTX源码:
JobStoreTX is meant to be used in a standalone environment. Both commit and rollback will be handled by this class.
If you need a JobStore class to use within an application-server environment, use JobStoreCMT instead.
翻译后的大致意思:
JobStoreCMT不管理事务,将事务托管给配置文件中指定的全局事务管理程序去管理事务并参与到全局事务(JTA)。完成数据库操作时,不提交(commit),由全局的事务管理程序来对全局事务进行统一的提交或回滚。CMT还可以配置一个不参与全局事务的数据库连接,用于配置如quartz的持久化数据库表,在持久化Job和Tirgger后自动提交。
如果你不需要绑定其他事务处理,可使用quartz自带的事务,即JobStoreTX方式,这也是最常见的选择。
参考
- 2.3.2 API document