深度学习与人类语言处理-语音识别(part1)
深度学习与人类语言处理课程笔记,上节回顾深度学习与人类语言处理-introduction。这节课将会简单介绍语音识别的最新研究方法,请看正文
语音识别该何去何从?
1969年,J.R. PIERCE:“语音识别就像把水变成汽油、从大海中淘金、治疗癌症、人类登陆月球”
当然,这是50年前的想法,那么语音识别该如何做呢?
一个典型的语音识别系统如下,输入一段语音到模型,模型输出一段文本

Speech:表示一个长度为T,维度为d的向量序列
Text:一个token序列,长度为N,V个不同的token,通常T>N
接下来看看输入可以有哪些可能,输出有哪些可能,首先看下输出部分
输出Token
音位(phoneme,发音的基本单位)
在深度学习没有流行之前,以音位为输出是很常见的,因为音位和声音的对应关系比较强,那输出是一系列音位,怎么变成我们能看懂的文字呢?需要一个词典,需要语言学家标出来,音位同样也需要语言学家帮忙
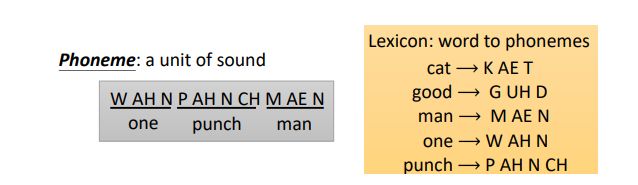
字母(Grapheme,书写的基本单位)
英文(基本书写单位:字母)
总的token:26个英文字母+一个空格+标点符号
one_punch_man;N=13,V=26+?
中文(基本书写单位:单个汉字)
总的token:常用的汉字(和英文区别在于没有空格)
"一",“拳”,“超人”,“人”;N=4,V=4000+
词(word)
英文:one punch man;N=3,通常V>100K
中文:“一拳 ”超人“;N=2,V=?
使用词做为输出单位很难,因为中文没有空格,没有词的明确分界,对于一些语言,V可能超大,无法穷举
语素(Morpheme,可以传达意思的最小单位,小于词,大于字母)
例如英文中:unbreakable可以拆成 “un“ ”break“ ”able”
那语素如何获取呢?
请语言学家告诉我们;使用统计学方法
字节(bytes)
使用字节作为输出系统是language independent,不受语言限制
所有的语言都用UTF-8编码表示:

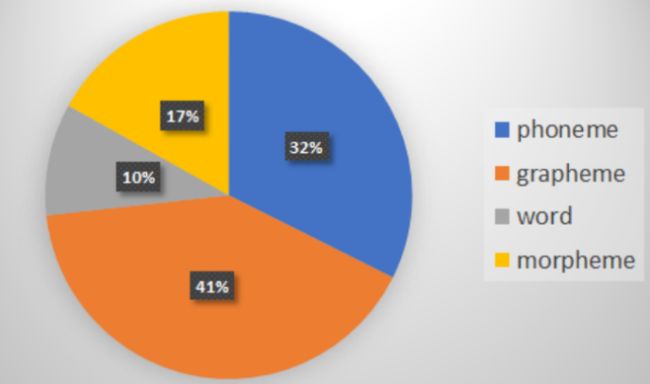
那么哪个Token最受欢迎呢,统计了19年语音三大顶会paper ( INTERSPEECH’19, ICASSP’19, ASRU’19 )。发现最多人使用的是grapheme
除了上述形式,还有哪些输出呢?
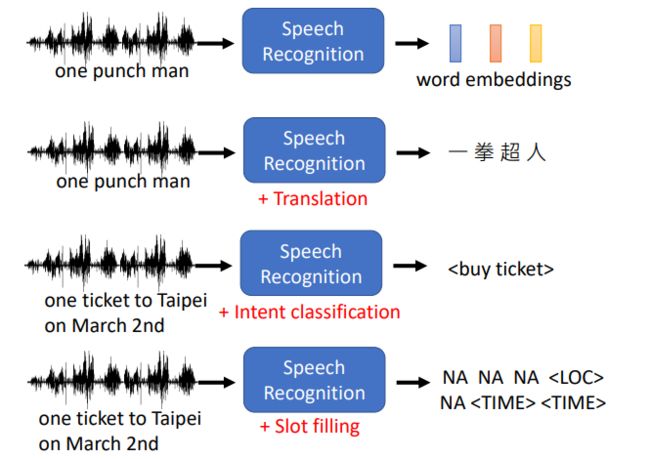
输入语音,输出word embedding
和翻译系统结合,直接输出另一种语言文本
加入意图识别,输出对应的意图
输出输入中所包含的关键词
输入部分(声学特征,acoustic feature)
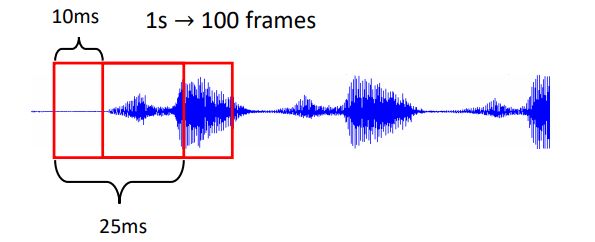
对输入的声音信号,使用25ms的时间窗取出一个frame,对应就有400个采样点(16KHz)(使用MFCC会得到39维向量、filter bank输出是80维),通常的每个时间窗的间隔为10ms,那么1s内就有100个frame,如何处理每个frame呢,请看下图
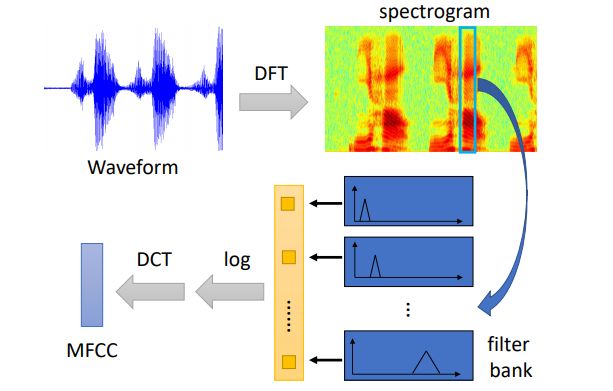
输入声音信号 经过 离散傅里叶变换 变成 频谱图,经过多个不同的 filter bank (古圣先贤们设计出来的) 处理后, 得到向量 使用对数变换,经过 离散余弦变换,使用MFCC方法得到向量
同样我们看下哪种输入信号最受欢迎,19年filter bank成为主流

训练一个语音识别系统需要多少数据?
很多很多,google语音识别系统用了上十万的语音数据。。。
语音识别模型的两个不同的角度

seq-to-seq将要被介绍的模型
Listen, Attend, and Spell (LAS)
Connectionist Temporal Classification (CTC)
RNN Transducer (RNN-T)
Neural Transducer
Monotonic Chunkwise Attention (MoChA)
同样我们看下,19年的趋势
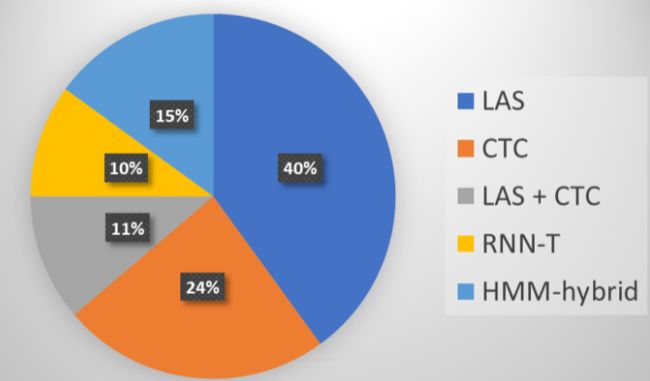
下节课。我们将会依次介绍上述提到的模型
接下来深度学习与人类语言处理-语音识别(part2)
references: