CCF推荐系统项目代码解读!
Datawhale干货
作者:阿水,北京航空航天大学,Datawhale成员
本文以CCF大数据与计算智能大赛(CCF BDCI)图书推荐系统竞赛为实践背景,使用Paddle构建用户与图书的打分模型,借助Embedding层来完成具体的匹配过程。后台回复 211208 可获取完整代码。
代码地址:
https://aistudio.baidu.com/aistudio/projectdetail/2556840
实践背景
赛题背景
赛事地址:
https://www.datafountain.cn/competitions/542
随着新型互联网的发展,人类逐渐进入了信息爆炸时代。新型电商网络面临的问题也逐渐转为如何让用户从海量的商品中挑选到自己想要的目标。推荐系统正是在互联网快速发展之后的产物。
为帮助电商系统识别用户需求,为用户提供其更加感兴趣的信息,从而为用户提供更好的服务,需要依据真实的图书阅读数据集,利用机器学习的相关技术,建立一个图书推荐系统。用于为用户推荐其可能进行阅读的数据,从而在产生商业价值的同时,提升用户的阅读体验,帮助创建全民读书的良好社会风气。
赛题任务
依据真实世界中的用户-图书交互记录,利用机器学习相关技术,建立一个精确稳定的图书推荐系统,预测用户可能会进行阅读的书籍。
赛题数据
数据集来自公开数据集Goodbooks-10k,包含网站Goodreads中对10,000本书共约6,000,000条评分。为了预测用户下一个可能的交互对象,数据集已经处理为隐式交互数据集。该数据集广泛的应用于推荐系统中。
数据文件夹包含3个文件,依次为:
训练集: train.csv 训练数据集,为用户-图书交互记录
测试集: test.csv 测试数据集,只有需要进行预测用户ID
提交样例: submission.csv 仅有两个字段user_id/item_id
解题思路
使用深度学习模型构建隐式推荐算法模型,并构建负样本,最终按照模型输出的评分进行排序,做出最终的推荐。具体可以分为以下几个步骤:
步骤1:读取数据,对用户和图书进行编码;
步骤2:利用训练集构建负样本;
步骤3:使用Paddle构建打分模型;
步骤4:对测试集数据进行预测;
步骤1:读取数据集
首先我们使用pandas读取数据集,并对数据的字段进行编码。这里可以手动构造编码过程,也可以使用LabelEncoder来完成。
这一步骤的操作目的是将对用户和图书编码为连续的数值,原始的取值并不是连续的,这样可以减少后续模型所需要的空间。
步骤2:构建负样本
由于原始训练集中都是记录的是用户已有的图书记录,并不存在负样本。而在预测阶段我们需要预测用户下一个图书,此时的预测空间是用户对所有图书的关系。
这里构建负样本的操作非常粗暴,直接是选择用户在训练集中没有图书。这里可以先使用协同过滤的思路来构建负样本,即将负样本是相似用户都没有记录的图书。
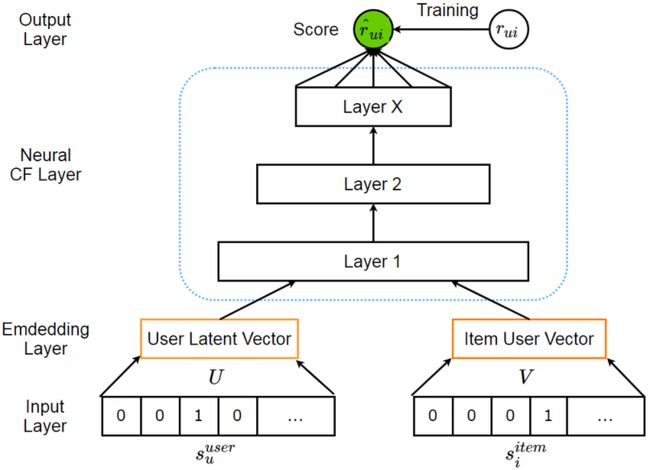
步骤3:Paddle搭建打分模型
这里使用Paddle构建用户与图书的打分模型,借助Embedding层来完成具体的匹配过程。这里用最简单的dot来完成匹配,没有构建复杂的模型。
步骤4:对测试集进行预测
首先将测试集数据转为模型需要的格式,然后一行代码完成预测即可,然后转换为提交格式。
改进思路
由于现有的代码写的比较基础,所以有很多改进的步骤:
对模型精度进行改进,可以考虑构建更加复杂的模型,并对训练集负样本构造过程进行改进。
对模型使用内存,可以考虑使用Numpy代替Pandas的操作。
代码实践
读取数据集
# 查看当前挂载的数据集目录, 该目录下的变更重启环境后会自动还原
# View dataset directory.
# This directory will be recovered automatically after resetting environment.
!unzip /home/aistudio/data/data114712/train_dataset.zip
Archive: /home/aistudio/data/data114712/train_dataset.zip
inflating: train_dataset.csv
!cp /home/aistudio/data/data114712/test_dataset.csv ./
!head train_dataset.csv
user_id,item_id
import pandas as pd
import numpy as np
import paddle
import paddle.nn as nn
from paddle.io import Dataset
df = pd.read_csv('train_dataset.csv')
user_ids = df["user_id"].unique().tolist()
user2user_encoded = {x: i for i, x in enumerate(user_ids)}
userencoded2user = {i: x for i, x in enumerate(user_ids)}
book_ids = df["item_id"].unique().tolist()
book2book_encoded = {x: i for i, x in enumerate(book_ids)}
book_encoded2book = {i: x for i, x in enumerate(book_ids)}
df["user"] = df["user_id"].map(user2user_encoded)
df["movie"] = df["item_id"].map(book2book_encoded)
num_users = len(user2user_encoded)
num_books = len(book_encoded2book)
user_book_dict = df.iloc[:].groupby(['user'])['movie'].apply(list)
user_book_dict
user构造负样本
neg_df = []
book_set = set(list(book_encoded2book.keys()))
for user_idx in user_book_dict.index:
book_idx = book_set - set(list(user_book_dict.loc[user_idx]))
book_idx = list(book_idx)
neg_book_idx = np.random.choice(book_idx, 100)
for x in neg_book_idx:
neg_df.append([user_idx, x])
neg_df = pd.DataFrame(neg_df, columns=['user', 'movie'])
neg_df['label'] = 0
df['label'] = 1
train_df = pd.concat([df[['user', 'movie', 'label']],
neg_df[['user', 'movie', 'label']]], axis=0)
train_df = train_df.sample(frac=1)
del df;自定义数据集
# 自定义数据集
# 映射式(map-style)数据集需要继承paddle.io.Dataset
class SelfDefinedDataset(Dataset):
def __init__(self, data_x, data_y, mode = 'train'):
super(SelfDefinedDataset, self).__init__()
self.data_x = data_x
self.data_y = data_y
self.mode = mode
def __getitem__(self, idx):
if self.mode == 'predict':
return self.data_x[idx]
else:
return self.data_x[idx], self.data_y[idx]
def __len__(self):
return len(self.data_x)
from sklearn.model_selection import train_test_split
x_train, x_val, y_train, y_val = train_test_split(train_df[['user', 'movie']].values,
train_df['label'].values.astype(np.float32).reshape(-1, 1))
traindataset = SelfDefinedDataset(x_train, y_train)
for data, label in traindataset:
print(data.shape, label.shape)
print(data, label)
break
train_loader = paddle.io.DataLoader(traindataset, batch_size = 1280*4, shuffle = True)
for batch_id, data in enumerate(train_loader):
x_data = data[0]
y_data = data[1]
print(x_data.shape)
print(y_data.shape)
break
val_dataset = SelfDefinedDataset(x_val, y_val)
val_loader = paddle.io.DataLoader(val_dataset, batch_size = 1280*4, shuffle = True)
for batch_id, data in enumerate(val_loader):
x_data = data[0]
y_data = data[1]
print(x_data.shape)
print(y_data.shape)
break定义模型
EMBEDDING_SIZE = 32
class RecommenderNet(nn.Layer):
def __init__(self, num_users, num_movies, embedding_size):
super(RecommenderNet, self).__init__()
self.num_users = num_users
self.num_movies = num_movies
self.embedding_size = embedding_size
weight_attr_user = paddle.ParamAttr(
regularizer = paddle.regularizer.L2Decay(1e-6),
initializer = nn.initializer.KaimingNormal()
)
self.user_embedding = nn.Embedding(
num_users,
embedding_size,
weight_attr=weight_attr_user
)
self.user_bias = nn.Embedding(num_users, 1)
weight_attr_movie = paddle.ParamAttr(
regularizer = paddle.regularizer.L2Decay(1e-6),
initializer = nn.initializer.KaimingNormal()
)
self.movie_embedding = nn.Embedding(
num_movies,
embedding_size,
weight_attr=weight_attr_movie
)
self.movie_bias = nn.Embedding(num_movies, 1)
def forward(self, inputs):
user_vector = self.user_embedding(inputs[:, 0])
user_bias = self.user_bias(inputs[:, 0])
movie_vector = self.movie_embedding(inputs[:, 1])
movie_bias = self.movie_bias(inputs[:, 1])
dot_user_movie = paddle.dot(user_vector, movie_vector)
x = dot_user_movie + user_bias + movie_bias
x = nn.functional.sigmoid(x)
return x
model = RecommenderNet(num_users, num_books, EMBEDDING_SIZE)
model = paddle.Model(model)
optimizer = paddle.optimizer.Adam(parameters=model.parameters(), learning_rate=0.003)
loss = nn.BCELoss()
metric = paddle.metric.Precision()
## 设置visualdl路径
log_dir = './visualdl'
callback = paddle.callbacks.VisualDL(log_dir=log_dir)
model.prepare(optimizer, loss, metric)
model.fit(train_loader, val_loader, epochs=5, save_dir='./checkpoints', verbose=1, callbacks=callback)预测测试集
test_df = []
with open('sub.csv', 'w') as up:
up.write('user_id,item_id\n')
book_set = set(list(book_encoded2book.keys()))
for idx in range(int(len(user_book_dict)/1000) +1):
test_user_idx = []
test_book_idx = []
for user_idx in user_book_dict.index[idx*1000:(idx+1)*1000]:
book_idx = book_set - set(list(user_book_dict.loc[user_idx]))
book_idx = list(book_idx)
test_user_idx += [user_idx] * len(book_idx)
test_book_idx += book_idx
test_data = np.array([test_user_idx, test_book_idx]).T
test_dataset = SelfDefinedDataset(test_data, data_y=None, mode='predict')
test_loader = paddle.io.DataLoader(test_dataset, batch_size=1280, shuffle = False)
test_predict = model.predict(test_loader, batch_size=1024)
test_predict = np.concatenate(test_predict[0], 0)
test_data = pd.DataFrame(test_data, columns=['user', 'book'])
test_data['label'] = test_predict
for gp in test_data.groupby(['user']):
with open('sub.csv', 'a') as up:
u = gp[0]
b = gp[1]['book'].iloc[gp[1]['label'].argmax()]
up.write(f'{userencoded2user[u]}, {book_encoded2book[b]}\n')
del test_data, test_dataset, test_loader
整理不易,点赞三连↓