CPM-2细节发布!10大技术打通大模型「任督二脉」,单卡单机跑「千亿模型」不再是梦...

智源导读:最近两年,预训练模型的参数量以每年 10 倍的速度迅猛增长,然而其计算效率的瓶颈也日渐显现。
例如以单块NVIDIA V100 GPU训练,GPT-1的计算时间是 3 天,到GPT-2 计算时间就达到了200天,GPT-3的计算时间则增加到90年。
因此如何在提升模型性能的基础上,提升模型计算效率,成为大规模预训练模型研究的重点,也成为预训练模型能否走向实际应用的关键。
近日,以清华大学副教授刘知远牵头的“悟道·文源”团队发布的 CPM-2,尝试了从大模型预训练的整个流程去提升计算效率。
CPM-2技术文章:https://arxiv.org/abs/2106.10715
整理:贾伟,张正彦
校对:张正彦,刘知远
CPM-2,即大规模高效预训练语言模型(Large-Scale Cost-Effective Pre-Trained Language Models),其中的“2”则是相对于去年 10月份该团队发布的 CPM-1,这是一个以中文为核心的大规模预训练语言模型(Large-Scale Chinese Pre-Trained Language Model)。
本次发布模型整体情况如下:

团队利用50TB大规模数据和智源算力平台制作发布的CPM-2模型,兼具中英文语言的理解和生成能力,在识记、阅读、分类、推理、跨语、生成、概括等七大机器语言能力测试中,与现有开源预训练模型相比整体性能显著最优。公开可下载的CPM-2模型分为3个不同版本:110亿参数中文模型、110亿参数中英模型以及1980亿中英MoE模型。
模型下载地址:https://resource.wudaoai.cn
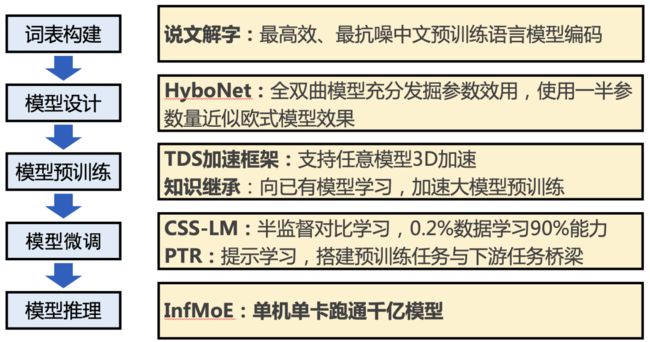
CPM-2的高效预训练框架围绕三个部分进行:模型预训练、模型微调和模型推理。以下我们将把 CPM-2的总体架构分为对应三个部分,来分别介绍其关键技术。

01
模型预训练
针对模型预训练,悟道·文源团队从数据集、知识继承以及训练方式等各个环节进行了优化和改进。整个预训练过程,简单来说:
对50TB的原始数据进行清洗得到2.6TB训练数据集,结合TDS加速框架和知识继承,采用先中文、再多语言、再MoE的多阶段预训练方案。
1、训练数据集:50TB到2.6TB的清洗
CPM-2的预训练数据集来自于智源研究院发布WuDaoCorpus(resource.wudaoai.cn),其中包含全球最大的中文文本数据集,该数据集从 50TB的数据中清洗出了 2.3TB的中文数据,以及 300GB英文数据。这些数据分别来自百科、小说、问答、科学文献、电子书、新闻和评论等多种领域。
2、TDS加速框架:支持任意模型加速
在模型的预训练方面,充分利用大的算力(多机多卡)进行计算,是提升大规模预训练的关键。悟道·文源团队认为,现有的大规模并行框架,没有办法同时支持不同类型的神经网络模型。

针对此问题,他们将Encoder、Decoder和Encoder+Decoder三种不同网络统一到同一个框架TDS TransformerLayer当中。除了支持任意神经网络模型的加速外,TDS(Tsinghua DeepSpeed,https://github.com/TsinghuaAI/TDS)同样可以支持三种不同类型的加速方法,包括数据并行、流水并行和模型并行。
3、知识继承:利用已有模型知识
当前市面上已经有许多训练好的模型,这些模型已经从大规模数据中学到许多有用的知识,如果能够有一种办法,不仅能够从数据中学习,还能够利用已有的模型的信息,那么必然会加速模型的训练过程。

基于这种思考,CPM-2中设计了三阶段的预训练步骤。首先进行纯中文语料预训练,打好中文语言能力基础;再进行中英混合语料预训练,通过调整中英文本比例,缓解灾难性遗忘,同时使用中文词向量初始化英文词向量,进行词表继承;最后使用中英模型初始化对应MoE模型,增大模型学习能力的同时保留原有知识。
02
模型微调
Prompt 两阶段微调:更好的微调机制
悟道·文源团队围绕CPM-2探索了全参微调、Prompt微调,以及先Prompt微调后全参微调,三种微调机制。
他们的实验发现,在全参微调机制下,CPM-2相比 mT5-XXL(也同样是一个110亿参数的模型),在8大任务(识记、阅读、检索、跨语言、数值计算、概括、分类、生成)上显著更优,对应的智源指数(CUGE Score)取得了4%的提升。(小括号为单个数据集的智源指数得分)

其次他们考虑到,如果对110亿参数进行全部微调,本身对算力要求较高。因此他们尝试仅微调Prompt参数,这种微调方法能够节省99%的微调参数量,从而节省50%的显存使用,结果显示在 7 大任务上与前面全参微调效果基本相当。

更进一步,当你有足够算力去做全参微调时,他们通过实验发现,如果你能够先进行Prompt微调,自动搜索较好的prompt,再进行全参微调,效果上会有显著提升。因此,在足够算力的情况下,prompt+全参微调的机制,能够更好地发挥大模型的优势。

技术报告中还对于Prompt的插入位置和Prompt的运行机制进行了进一步的深入分析,具体细节参见技术报告。
03
模型推理
InfMoE:让普通研究组也可以跑得起大模型
当下的模型越来越大,导致只有企业界才能够跑得起,普通研究组只能望洋兴叹。悟道·文源团队希望能够解决这个问题,让大模型的成果平民化,让所有的研究组都能够用得上大模型。

针对这一问题,他们在推理阶段提出了InfMoE的机制(https://github.com/TsinghuaAI/InfMoE),采用参数offload动态调度(同时利用显存和内存存储模型参数),以及基于TensorRT实现MoE层高效推理的插件,并将对接Prompt实现单机千亿参数模型微调。这种机制实现了能够利用单机单卡GPU,去完成千亿参数模型的推理计算。
04
最新探索
在CPM-2模型之外,悟道·文源团队围绕高效预训练框架进行了更加深入的探索,具体突破如下:
说文解字:具有字形和字音特征的中文编码技术,兼具高效编码和抗噪音特性;
HyboNet:全双曲表示Transformer架构,仅用一半参数即可达到欧氏空间模型效果;
知识继承:高效预训练技术,训练速度提升37%以上;
CSS-LM:基于少样本对比学习的微调技术,仅使用0.2%数据即可达到完整数据训练90%的效果;
PTR:基于Prompt的微调技术设计模板,充分利用人工设计规则,挖掘预训练模型能力。
1、“说文解字”:高效中文编码
与拉丁字母相比,汉语中的字多种多样,如何高效编码并能够学习那些低频甚至生僻的字,一直是一个未解决的问题。
悟道·文源团队提出“说文解字”中文编码的方案(https://arxiv.org/abs/2106.00400)是:采用基于字音(说文)和字形(解字)特征的汉字编码器(tokenizer)。

相比现有的中文编码器(例如BERT-Chinese),采用这种新的编码机制,能够获得更好的效果,最大的好处是能够在形近字、同音字以及高噪音的情况(例如错别字)下达到鲁棒抗噪的效果。
2、高效模型:双曲空间Transformer
在模型设计方面,悟道·文源团队认为双曲空间(一种非欧空间)可以更加高效地对复杂结构数据进行建模。

基于此种思考,他们构建了全双曲Transformer(https://arxiv.org/abs/2105.14686),并实现了所有计算双曲化,包括线性层、残差层、分类层、注意力层以及向量层等。在机器翻译任务评测中,这种双曲化的Transformer的性能要大幅超过基于欧式空间的模型,此外仅适用一半参数量就能够达到欧式模型的效果。
3、知识继承:吸收任意模型知识
基于CPM-2的探索,悟道·文源团队进一步挖掘如何让模型能够同时从文本和已有模型中学习的“知识继承”能力。相关实验表明,这种方式在预训练的前期可以实现37.5%的提速,从而大大减少了训练大模型所带来的能源消耗。此外,这种基于“知识继承”的方法可以持续吸收任意架构、在任意数据上训练、使用任意训练策略的语言模型知识,从而不断增强大模型的能力;还能够在不接触隐私的数据基础上,仅通过模型的知识交换形成高效、安全的知识吸收。

4、CSS-LM:利用半监督学习的微调
大模型在通用语料进行训练之后,进行有监督数据微调时,往往会面临的一个问题是,现有领域的标注数据相对有限。随着预训练模型越来越大,这种现象也约明显,这导致微调变得越来越困难。
悟道·文源团队针对这个问题,在CPM-2中提出了CSS-LM(Contrastive Semi-Supervised Finetune)方法,可以有效利用有限标注数据来实现高效微调。

具体来说,这是一种对比学习机制,把下游的微调过程改造成一个半监督学习的过程。因为在具体的任务当中,我们可以利用的不只是标注数据,还有充足的无监督数据,这两者结合起来将更加高效提升学习结果。
悟道·文源团队在 6 个分类数据集上的相关实验表明,只需要0.2%的下游微调训练数据,就可以习得90%的任务能力。
这样的结果,给我们提供一个非常广阔的想象力,下游任务的微调可能有更多的探索空间。
5、PTR:建立预训练与下游任务微调的桥梁
在微调的过程中,悟道团队发现,当下游任务比较复杂时,下游任务的形式会与上游预训练的形式具有较大的不一致,这种不一致会极大地限制模型任务的适配效果。
基于这种考虑,在今年3月份“悟道1.0”发布时,悟道团队成员、智源青年科学家杨植麟博士指出可以使用基于规则的多类别提示(Prompt),将分类任务分解为若干个逻辑条件判断,为每个逻辑条件设计独立的sub-prompt,然后利用逻辑规则将sub-prompt组合成任务最重的prompt,从而建立预训练与下游任务微调的桥梁。
悟道·文源团队基于此种思想提出了PTR(Prompt Tuning with Rules, https://arxiv.org/abs/2105.11259)方法。这种方法在实体关系抽取相关的实验中,相比传统微调方法可以将错误率下降15%以上。
05
未来计划
基于以上十项技术改进,悟道·文源团队构建了全流程的高效预训练框架。
目前该项目所有代码已经开源:https://github.com/TsinghuaAI/CPM
技术报告也已经公开:https://arxiv.org/abs/2106.10715
针对未来研究布局,项目主要负责人刘知远教授称,“我们在去年11月份,发布了26亿参数的CPM-1,这个模型主要是给中文世界带来大规模的预训练模型;现在我们发布的CPM-2,是希望能够提供一个高效地计算框架。在接下来的半年时间里,我们将继续努力,以CPM-2为蓝本,打造CPM-3,一方面持续吸纳其他模型和数据,让性能进一步提升;另一方面,我们希望能够提供更加高效地接口,让大模型能够真正地飞入‘寻常百姓家’,让所有的研究组都能够用上大模型,开展他们关心的场景任务。我们认为,这件事情在接下来的一两年内会成为非常重要的研究课题。”


如果你正在从事或关注预训练学习研究、实现与应用,欢迎加入“智源社区-预训练-交流群”。在这里,你可以:
学习前沿知识、求解疑难困惑
分享经验心得、展示风貌才华
参与专属活动、结识研究伙伴
扫描下方二维码,或点击阅读原文申请加入(选择“兴趣交流群→预训练”)
