多样性强化学习:不光要赢,还要赢得精彩 | 清华吴翼
导读:在 OpenAI 工作期间,吴翼曾经完成了一个非常有趣的「捉迷藏」游戏项目,蓝色智能体需要藏起来,躲避红色智能体的抓捕。
在该项目构建的开放物理世界中,智能体学会了许多有趣、神奇的行为,比如说跳起来或通过梯子爬上盒子。从这个「捉迷藏」游戏出发,研究者引出了多智能体强化学习中的多样性学习问题。在这个新的强化学习范式中,AI不仅仅要得高分,还要尽可能用不同方式得高分。
作为智源大会“强化学习与决策智能论坛”的报告嘉宾,清华交叉信息学院助理教授、青源会会员吴翼,向智源社区介绍了他在多样性强化学习上的研究进展,并从「通过奖励随机化发现多样性的多智能体策略」和「通过奖励转换策略优化连续发现新策略」两个方面介绍了其团队在多样性强化学习方面的最新研究进展。

吴翼,清华大学交叉信息研究院助理教授,曾任OpenAI全职研究员,研究领域为强化学习的泛化性,多智能体学习,自然语言理解,机器人学习等。2019年在美国加州大学伯克利分校获得博士学位,师从Stuart Russell教授;2014年本科毕业于清华大学交叉信息院计算机科学实验班(姚班)。其代表作包括:NIPS2016最佳论文,Value Iteration Network;多智能体深度强化学习领域最高引用论文,MADDPG算法;以及OpenAI hide-and-seek 项目等。

01
研究背景
多样性强化学习是强化学习的重要子课题。在强化学习的设定下,人工智能体在与环境交互的过程中会得到一些奖励,而强化学习的目标则是最大化累积奖励,即智能体在环境中要得到最高的奖励分数。

时至今日,研究者们在强化学习领域已经取得了一系列突破性的进展。例如,智能体可以在很多复杂的游戏中取得超越人类的表现。强化学习还可以被用来做自适应控制。如上图所示,吴翼团队在 ICRA 2022 上发表了论文「Learning Design and Construction with Varying-Sized Materials via Prioritized Memory Resets」,他们通过强化学习算法,使机械臂能够根据不同的材料和场景自适应地搭建积木桥。

吴翼在 OpenAI 工作期间曾经完成了一个非常有趣的「捉迷藏」游戏项目,蓝色智能体需要藏起来,躲避红色智能体的抓捕。在该项目中,他们构建了一个开放的物理世界,智能体可以学会许多有趣、神奇的行为(例如,跳起来或通过梯子爬上盒子)。其中,蓝色智能体有一个很重要的行为:用箱子将自己围起来,构建一个堡垒保护自己。
既然小蓝人可以将自己围住让自己不被看到,他们是否可以反过来将小红人围住呢?实际上,吴翼团队在「捉迷藏」游戏的环境中添加了一些金币,设计了一个名为「金币保护者」的游戏变种。在该游戏中,小蓝人除了要保护自己不被小红人看到,还要尽可能保护金币不被小红人吃掉,否则都会被扣分。而在该环境下, 小蓝人确实学会了用障碍物将小红人围在角落中。

实际上,如果小蓝人在原版的捉迷藏游戏中将小红人围在墙角,也可以获得很高的分数,是非常合理的行为。那么,一个值得探究的问题是:为什么将小红人围起来的行为没有出现在原版的「捉迷藏」游戏中?是因为探索不足?还是奖励机制不够完善?

为此,我们首先尝试了使用「基于计数的探索」方法,让智能体能够访问更多的状态。尽管智能体可以学会更多有趣的行为,但是仍然无法学会将小红人围在墙角。此外,我们还尝试了将探索的奖励和自博弈进化的奖励相结合,发现这样仍然很难学到将小红人围在墙角的策略。
02
通过奖励随机化发现多样性的多智能体策略

在 ICLR 2021 上,吴翼团队发表了题为「Discovering Diverse Multi-Agent Strategic Behavior via Reward Randomization」的论文,探究了如何发现多样性的多智能体策略行为的问题。

早在 18 世纪,卢梭就在其著作《论人类不平等的起源和基础》中提到了一个名为「猎鹿博弈」的故事:有两个猎人,他们的目的是捕获一头鹿,同时他们自己本身已经非常饥饿。由于鹿十分谨慎,猎人挖好了陷阱,在雪地里埋伏了很久。此时突然出现了一只兔子,两名饥肠辘辘的猎人都需要在以下两个选项中做出抉择:(1)抓住兔子美餐一顿,但是兔子的肉少并且会把鹿吓跑再也抓不到了(2)忽略眼前的诱惑继续等待鹿掉入陷阱,忍受饥饿。

可见,该游戏中存在两种纳什均衡:(1)两人都等待鹿掉入陷阱(2)两人都去抓兔子。然而,如果一个人选择等待,另一个人选择抓兔子。则选择等待的人损失很大,既没有迟到兔子,也无法再捕获鹿。那么,如果我们使用强化学习自博弈来学习猎鹿博弈,算法会收敛到哪种状态呢?

当我们只考虑两种纳什均衡时,假设每个人捕获鹿可以获得 4 的奖励,捕获兔子可以获得 2 的奖励。此时,强化学习的随机性较大,收敛到两种纳什均衡状态的可能性差别不大。
然而,如果进一步考虑一名猎人选择等待,另一名猎人选择抓兔子的情况,则抓兔子的人会得到 3 的奖励;而等待的人会被饿死,其收益为 -100。此时,两名猎人之间的合作是非常危险的,如果遭到背叛则会得到很低的期望收益。仿真实验结果表明,当死亡的惩罚越来越大时,算法都会收敛到非合作策略上,智能体会选择抓住兔子。

假设收益与损失之比很小,则死亡惩罚很大。即使在 2*2 的博弈矩阵中,完全不存在探索的问题,智能体也需要尝试多次才能发现最优的纳什均衡。如上图所示,x 轴代表策略空间、y 轴代表奖励。在高低起伏的奖励的 Landscape 中,存在一段很长的平缓区域,代表非合作策略(抓兔子)。
当智能体初始化状态位于这段平缓区域时,它几乎一定会收敛到非合作策略状态。如果我们希望智能体发现最优的合作策略,就必须让智能体处于「尖峰」处附近,才有可能收敛到合作策略上。
既然当奖励的 Landscape 在合作策略处过于「陡峭」,以至于智能体难以学到这样的最优策略,我们是否可以通过构造新的环境,将奖励的 Landscape 在「尖峰」处「拉平」,从而让智能体能够更容易学到合作策略?也就是说,我们可以对原始环境进行扰动,得到一种新的任意的 2*2 博弈,此时智能体有很大概率收敛到合作策略状态。我们让智能体在新的环境中找到合作策略,再将智能体置于原本我们关心的环境中进行评估。如果该智能体也可以找到原始环境中的最优合作策略,就满足了我们的要求。

如果我们可以在「回报矩阵」(pay-off matrix)上做随机化搜索,则这样找到最优策略的概率与奖励的 Landscape 是无关的,也就很有可能会搜索到非常平缓的奖励 Landscape,从而找到合作策略。

换而言之,在某个游戏中非常难以找到的策略,可能在另一个游戏中很容易找到。我们本质上实在奖励空间中进行了探索,而奖励空间的规模要远远小于策略空间。具体而言,我们在算法中首先定义了一个合适的奖励空间(通常为各项的线性函数),接着从奖励空间中采样到一组奖励函数。针对每个奖励函数,我们都要学习一个最优策略。最后,我们在原始游戏中对得到的最优策略进行评估和调优。
时序信任困境:网格世界
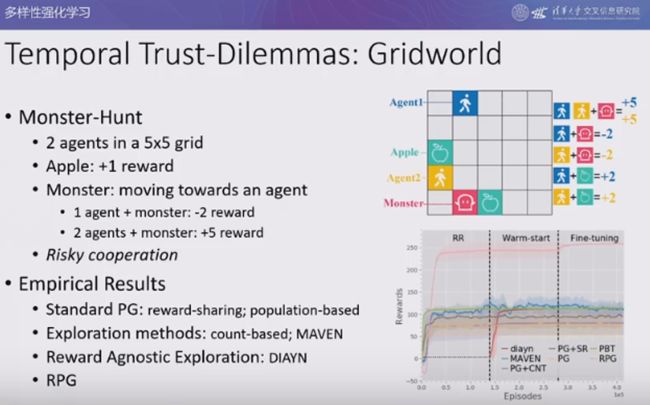
我们在一个时序信任困境游戏——网格世界中验证上述算法的性能。在该游戏中,两个智能体处于一个 5*5 的网格世界中,智能体吃到苹果可以得一分。网格世界中还存在一个怪兽,怪兽会不断朝着距离最近的智能体移动。如果单个智能体遇到怪兽则会被怪兽吃掉,扣 2 分;如果两个智能体一起遇到怪兽,则会将怪兽击败,智能体各加 5 分。
因此,智能体之间存在风险合作,只有彼此信任才能击败怪兽,如果有一方逃跑则令一方会被吃掉。实验结果表明,标准策略梯度算法、基于计数的探索方法、MAVEN、DIAYN、RPG 等算法都会收敛到非合作策略上。

在所有找到的策略中,RPG 算法在进行了奖励随机化之后,回到原始游戏中调优后找到的最优策略为:两个智能体迅速汇聚到一起再也不分开,并一同朝着怪兽前进出,从而不断获得 +5 的奖励。两个智能体一起躲在角落也可以实现纳什均衡,是一种次优但是合理的策略。
时序信任困境:Agar.io

我们还在 Agar.io(球球大作战)游戏中研究了时序信任困境问题。在该游戏中,玩家需要操作一些球体,球体可以通过吃掉比自己小的球得分,同时球体也会变大。然而,球的体积越大则行动的速度也会变慢。除了「吃掉」小球,我们还可以将球体分解为多个较小的球,并同时控制它们,从而加快行动速度。
我们将该游戏简化为双人版,形成了一种新的风险合作机制。如上图所示,环境中存在黄色、蓝色代表的两个玩家,以及红色的脚本智能体代表的食物。

由于食物小球的速度往往比我们控制的球体快,如果想要抓住食物就需要将其尽可能封在角落里。两个智能体合作抓捕食物的成功概率更大。然而,此时两个智能体的十分接近,合作捕食的过程中也有可能被另一方吃掉,因此具有一定的风险。
在这一环境中,智能体学会了合作捕食的「合作」策略、单纯吞并其它智能体的「侵略性」策略、即使不能捕食也坚持与其它智能体保持较大距离的「非合作」策略、在合作过程中偶尔吞并合作者某部分的「侵略性合作」策略、将自己牺牲给其它智能体的「牺牲」策略、智能体之间持续交换部分机体的「部分牺牲」策略。其中,最优策略为平衡「相互牺牲」、「单独捕食」、「合作捕食」的结果。
小结

在该工作中,我们通过奖励随机化发现了多样性的策略。该工作表明,奖励的引导对于得到人类易于理解的策略至关重要;对奖励空间的探索远比对状态空间的探索更高效。该工作也引出了一些开放性的问题,例如:(1)如何设计奖励空间?(2)如何发现更细粒度的策略模式?
03
通过奖励转换策略优化连续发现新策略

如前文所述,奖励随机化方法要求我们拥有一个奖励空间。但是在大多数情况下,这种奖励空间并不能够直接获得。为此,吴翼团队在 ICLR 2022 上发表了论文「Continuously Discovering Novel Strategies via Reward-Switching Policy Optimization」,讨论如何在没有奖励空间的情况下发现有趣的智能体行为。
4 球游戏
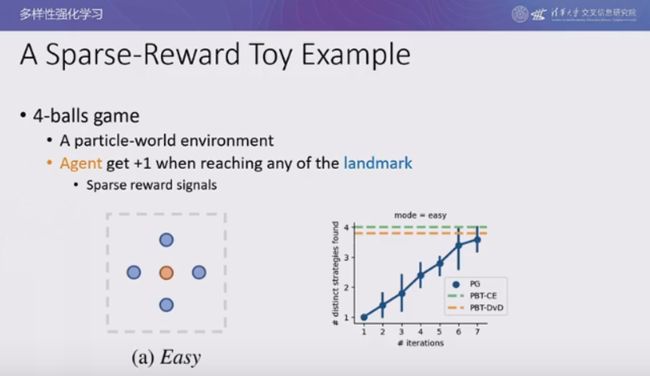
我们考虑单智能体的运动问题:4 球游戏。如上图所示,黄色的智能体周围有 4 个标志物,只要智能体碰到一个标志物就可以得到一分,游戏的奖励是稀疏的。我们证明了,在随机重置反复实验的情况下,即使是最简单的算法都可以找到所有 4 个最优策略。
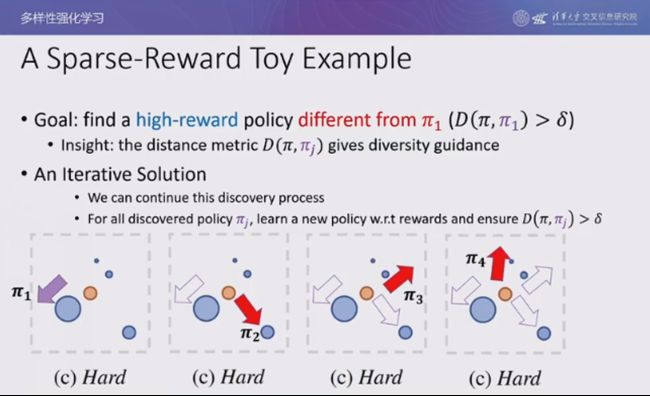
现在,我们考虑困难一些的情况,假设 4 个标志物的大小不一,在距离智能体较近的地方有一个很大的球,在距离较远的地方有一个很小的球。实验结果表明,由于智能体开始采用随机探索的策略,大多数的随机运动轨迹都会碰到较近的大球,很难绕过所有的障碍物找到较远的小球。在大多数情况下,智能体会收敛到寻找较近的大球的情况。
此时,我们并没有奖励空间,无法进行奖励随机化。为了让智能体学会所有 4 个最优策略,我们考虑设计一种基于策略差异度量的引导,为与已知策略不同的策略赋予额外的奖励,或惩罚与已知策略相近的策略。通过上述方法,我们不断将新找到的策略加入已知的策略空间,在剩余的策略空间中搜索新的策略,以此循环往复,直至找到最优的最优策略。

基于上述思想,我们可以设计一个迭代算法:在每一轮迭代中,我们希望找到奖励最大的策略,并且希望它与之前所有的策略都不同。具体而言,我们选择交叉熵作为策略的距离度量,希望当前策略生成的轨迹在已知的参考策略下出现的概率较小。为了满足对策略距离的约束,我们将拉格朗日乘子作为距离度量的系数加入到目标函数中。由于目标函数的两项都是关于轨迹的期望,因此可以将两项合并起来,式中的第一项为环境奖励,第二项为内在奖励。
然而,在强化学习场景下,拉格朗日乘子往往是个常数。但是根据优化理论,为了保证收敛,该系数必须是自适应的。但实际上策略梯度存在方差大的问题,难以得到自适应的稀疏,调参难度十分大,算法很容易收敛到之前的策略上。因此,我们试图强迫使找到的新策略与已知策略不同。

以第二轮迭代为例,我们希望最大化累积奖励,同时希望第二轮找到的策略与第一轮找到的策略不同,此时的约束是一个关于轨迹的期望负对数似然(NLL)的形式,我们希望所有轨迹的平均 NLL 系数大于 δ。理想情况下,我们可以丢弃所有不满足约束的轨迹,仅仅保留满足约束的轨迹,这样最终一定会收敛到与先前策略不同的解上。
轨迹过滤

我们将上述方法称为「基于轨迹过滤的策略优化」,我们在迭代求解过程中加入了一个示性函数来看过滤不符合约束的策略,从而使最终收敛到符合约束的策略上。然而,在深度学习范式下,我们不可能列举所有的情况,只能进行有限的采样。而在策略梯度算法运行的早期,很有可能列举出的样本都是不符合约束的,从而将所有数据全都丢弃,就无法计算梯度了。

然而,我们仍然可以对被丢弃掉的轨迹数据加以利用,将这些数据作为负样本,使策略能够避免生成这种较差的轨迹数据。为此,我们使用内在奖励,为负样本施加惩罚,负样本的质量越差(与已知策略越接近)则惩罚越大。
奖励转换

我们将整个框架称为「基于奖励转换的策略优化」(RSPO),将轨迹分为合理的轨迹(红色)和不合理的轨迹(蓝色)。对于合理的轨迹,我们优化环境奖励,让其收敛到局部最优。对于不合理的轨迹,我们优化内在奖励,使其远离负样本。这样一来,我们就可以利用所有的样本。实验结果表明,如果不使用内在奖励,则算法运行一段时间后就会产生缺乏正样本的情况;当我们使用奖励转换技巧后,尽管正样本数变少了,但是会内在奖励会将策略推向新的区域,进而产生越来越多的正样本,样本效率会重新提高。

如前文所述,使用拉格朗日乘子法优化时我们将环境奖励和内在奖励线性组合相加,但是这是一种较弱的多样性约束,导致最终收敛到的策略很有可能与之前发现的策略相同。而使用奖励转换后,我们一定可以满足新的约束。
实验结果
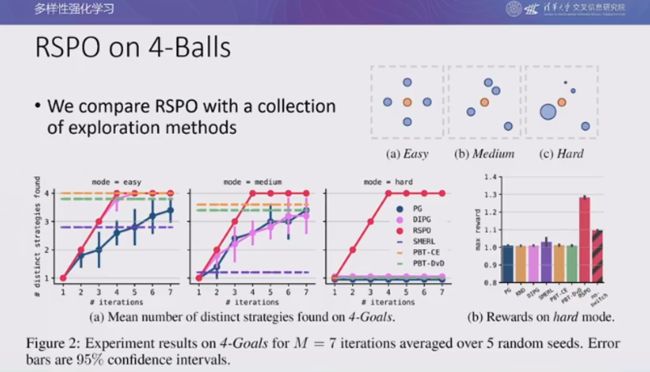
我们在 4 球游戏中评估 RSPO 优化的性能。在困难的环境中,现有的所有平滑约束的方法都很难跳出具有迷惑性的局部模式,而 RSPO 则十分稳健,在 4 轮迭代后就可以找到所有的模式。此外,奖励转换也起到了十分重要的作用。将奖励转换移除后,RSPO 只能找到两种模式。

在前文提到的网格世界信任困境游戏中,假设 RSPO 并不能利用奖励空间,在运行了 20 轮后,可以找出 20 种策略。如上图所示,起初智能体学到了吃苹果的策略,接着学到了智能体一起躲在角落、智能体合作追逐怪兽等策略。有趣的是,此时智能体还学会了一起在边界上来回移动的策略。

我们在 MuJoCo 连续控制环境中测试了 RSPO 算法。该算法可以发现各种跳跃的 Hopper、行走的 Walker、以各种姿势前进的 Humanoid。

我们在星际争霸游戏中测试了 RSPO 算法。在六轮训练中,RSPO 算法都可以找到六个完全不同的获胜策略,并且其中胜率最低策略的胜率也超过了 84.4%。
小结

RSPO 可以连续地发现新的策略。我们起初使用拒绝采样的方法丢弃掉不符合约束的样本。为了提升样本利用效率,我们进一步采用了奖励转换机制,合理利用负样本来优化内在奖励。此外,针对前文提到的「金币保护者」游戏,我们仍然在设法解决学习稳定性、多样性评估、提升收敛保障和样本效率等问题。目前,我们也发现了一些有趣的新的行为,例如:小红人搭起人梯,踩着同伴从箱子上翻进堡垒。

最后,上述项目均基于多智能体策略优化算法MAPPO,感兴趣的读者可以通过上图中的链接访问相关资源。
本次智源大会“强化学习与决策智能论坛”邀请到了贝壳找房副总裁、首席科学家,智源学者叶杰平、伦敦大学学院计算机系教授汪军、美国耶鲁大学统计与数据科学系助理教授杨卓然、阿里巴巴达摩院决策智能实验室负责人印卧涛、Lyft网约车实验室首席科学家秦志伟等,为大家介绍在强化学习领域最新前沿进展。
