手写数字图片识别+导入csv训练集+预测训练集+csv导出预测结果
手写数字图片识别+导入csv训练集+预测训练集+csv导出预测结果
题目来源:
Dataset之MNIST:MNIST(手写数字图片识别+csv文件)数据集简介、下载、使用方法之详细攻略
- 导入csv训练集、测试集数据
- 构建神经网络
- 预测训练集
- csv导出预测结果
1. 导入csv训练集、测试集数据
“csv数据导入前,人为地删除表格第一行的图像像素序号”
#读取train.csv里的数据,数据与标签分开记录
filename = 'train.csv'
f = open(filename,'r')
train_images = []
train_lables = []
for i in f.readlines():
a = i.strip().split(',')
train_images.append([int(j) for j in a[1:]])
train_lables.append(int(a[0]))
#读取test.csv里的数据
filename = 'test.csv'
f = open(filename,'r')
test_images = []
for i in f.readlines():
a = i.strip().split(',')
test_images.append([int(j) for j in a[0:]])
#对图片的数据进行分行处理
import numpy
test_images=numpy.array(test_images)
train_images=numpy.array(train_images)
- 测试数据是否导入,通过print的方式
#对图像数据的某些输出进行测试
print('训练数据维度',train_images.shape)
print('测试图片个数',len(test_images))
print('训练集第4个数字图像的识别结果',train_lables[4])
#显示训练集第4个数字图像
import numpy as np
import matplotlib.pyplot as plt
plt.imshow(train_images[4].reshape(28, 28))
plt.show()
2. 构建神经网络
“参考网络的代码”
#构建网络
#神经网络的核心组件是层(layer),它是一种数据处理模块,可看成数据过滤器。
#此网络包含2个Dense层,
from keras.models import Sequential# 导入Sequential模型
from keras.layers import Dense
from keras.optimizers import Adam
# design model
network = Sequential()
network.add(Dense(512, activation='relu', input_shape=(28 * 28,)))
network.add(Dense(10, activation='softmax'))
adam = Adam(lr=0.001)
# compile model
network.compile(optimizer='rmsprop',loss='categorical_crossentropy',metrics=['accuracy'])
#在开始训练之前,对数据进行预处理,将其变换为网络要求的形状,并缩放到所有值都在[0, 1] 区间。
#需要将其变换为一个float32 数组(浮点型),其形状为(42000, 28 * 28),取值范围为0~1。
train_images = train_images.reshape((42000, 28 * 28))
train_images = train_images.astype('float32') / 255
test_images = test_images.reshape((28000,28*28))
test_images = test_images.astype('float32') / 255
#对标签进行分类编码
from keras.utils import to_categorical
train_lables = to_categorical(train_lables)
# training model,通过调用网络的fit 方法在训练数据上拟合(fit)模型。
#训练过程中显示了两个数字:一个是网络在训练数据上的损失(loss),另一个是网络在训练数据上的精度(acc)。
network.fit(train_images, train_lables, epochs=5, batch_size=128)
3. 预测训练集
这是自己写的代码,当时网上根本搜不到直接输出的代码。(我发现有人直接挪用发知识分享,注释都完全一样,望周知)
#预测测试集图像对应的数字
predict=[]
predict_test = network.predict(test_images)
predict = np.argmax(predict_test,1) #axis = 1是取行的最大值的索引,0是列的最大值的索引
#打印预测数据,检测其是否预测准确
print(predict)
4. csv导出预测结果
这是自己写的代码,当时网上根本搜不到直接输出的代码。(我发现有人直接挪用发知识分享,注释都完全一样,望周知)
#将预测数据用csv格式输出
import pandas as pd
a = []
b = []
for i in range(28000):
a.append(i+1)
b.append(predict[i])
#字典中的key值即为csv中列名
dataframe = pd.DataFrame({'ImageId':a,'Label':b})
#将DataFrame存储为csv,index表示是否显示行名,default=True
dataframe.to_csv("results.csv",index=False,sep=',')
- 展示测试集的图片
#展示测试集的图片
plt.imshow(test_images[2].reshape(28, 28))
plt.show()
- 测试结果:
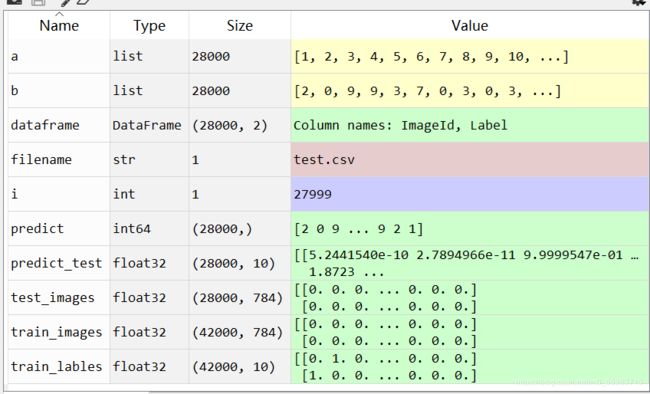

因为老师发布了任务,利用网络资源完成后,单纯是为了保存下劳动的成果,所以把程序发到这里和大家共享。
ps:感谢我的两位兄dei