论文阅读——U^2-Net:Going deeper with nested U-structure for salient object detection
U^2-Net:Going deeper with nested U-structure for salient object detection
Abstract
本文提出一种简洁高效的目标显著性检测框架——U2Net。U2Net包含两层嵌套的UNet结构,具有以下优点:
(1)在本文提出的残差U形模块(RSU)中通过不同尺寸感受野的混合可以有效捕获不同尺度的上下文信息;
(2)RSU模块中的池化操作在不显著增加计算成本的前提下进一步加深了网络的深度。这种网络架构使得我们可以从头训练深层网络而无需使用一些图像识别任务中的基线模型。
Section I Introduction
目标显著性检测指的是将图像中最显著的物体进行分割,广泛用于视觉追踪和图像分割任务中。随着CNN尤其是FCN在分割任务中大放异彩,目标显著性检测也获得飞速发展。我们不禁要问:我们遗漏了什么?让我们回看一下还存在什么挑战性问题。绝大多出目标检测框架的通用模式是借助已有的一些基准网络框架提取深层特征,如AlexNet,VGG,ResNet,DenseNet等,但是这些网络最初是用于图像分类的,提取的是更具表征能力的语义信息,并不是针对包含更加细节的信息或者具有全局对比性的信息的,而后面两类信息对SOD更为重要。并且他们多半需要在ImageNet上预训练,如果目标任务训练数据有限的话。
因此,第一个问题就是:是否可以搭建一个用于SOD的框架允许从头训练无需预训练就达到较好的性能?
而SOD目前的一些网络框架还存在以下问题:首先他们一般都比较复杂,主要是需要在基准网络外添加额外的特征聚合模块;其次深度网络的搭建是以牺牲特征图谱空间分辨率为代价的,特征图谱不断通过下采样被压缩,但是空间分辨率对于分割任务至关重要。
因此我们的另一个问题是:能否在获得深层特征的同时保持特征图的分辨率,并且花费较少的内存和计算资源。
本文提出一种简洁新颖的网络架构;U2Net,通过两层UNet的嵌套搭建起来用于SOD任务,而且无需预训练支持直接从头训练。并且这一网络可以搭建至较深层次的同时保持较高分辨率,这主要通过嵌套的RSU残差U形网络(RSU)在不降低特征图分辨率的前提下提取多尺度特征。U2Net整体如Fig 5所示,在6大目标检测数据集上均取得了SOTA并且满足实时性的需求,还提供了精简版本的U2Net_Light.
Section II Related Works
传统的目标显著性检测多基于人工特征的,如foreground consistenct, heperspectural information,superpixels’ similarity,histograms等,而基于深度学习的SOD框架可以取得更加的检测性能。
Part A Multi-level feature integration
许多SOD算法通过多级特征聚合提升检测效果,如通过引入dropout和upsampling模块减轻棋盘格效应,还有借助short connections或者提出新的聚合策略,通过多级特征聚合确实大大提升了基于深度学习进行SOD检测的性能。
Part B Multi-scale feature extraction
因为目标检测需要局部和全局信息的共同参与,早期多常用的的3x3卷积可以有效提取局部信息却难以提取全局信息,而增大卷积核尺寸又会增加参数量和计算负担。因此前人有使用空间金字塔池化、多级refinement策略等来有效提取局部和全局信息,还有引入注意力模块来预测前景物体的空间分布等,也有在损失函数上进行改进的。
这一方向的探索提出了许多新奇高效的特征提取模块。
但是也能发现几乎上述所有方法都是基于图像分类的一些基线网络进行的改进,通过增加额外的模块或策略等。而本文则是提出一种全新的架构,可以直接提取多级特征用于目标检测。
Section III Proposed method
首先介绍residual U-Block随后介绍整个nested U-NetYi以及网络的监督策略、损失函数。

Part A Residual U-Blocks
局部和全局信息对目标检测和其他分割任务均至关重要,在常用的CNN网络,如VGG,AlexNet,ResNet,DenseNet中常使用1x1,3x3等小尺寸的卷积核来提取特征,这样大小卷积核对应的感受野只能提取局部信息,如果想要提取更加全局的信息很直观的想法就是扩大感受野范围。如Fig 2(d)展示的Inception module,通过不同膨胀率的空洞卷积有效提取了局部和全局信息;但是在网络浅层就是用多个空洞卷积十分消耗内存和计算资源.
因有的方法如PoolNet使用了金字塔池化,但还有一个问题是将不同分辨率的特征直接通过上采样后级联往往会导致精度下降。
受启发于UNet,本文提出RSU(Residual U-Block)残差连接的U形模块,具体如Fig 2(e)所示,其中L是U形Block中编码的层数(深度),Cin,Cout分别指的是输入输出的通道数,M指的是Block中每一层的通道数。
因此RSU包含3大部分:
(1)输入卷积层,负责将输入的特征图进行通道变换;
(2)U形的编解码模块负责提取多尺度的上下万信息并进行编码,L越大表明RSU越深,对应感受野越大,越能提取到全局信息,因此可以获得任意分辨率的特征图;并且是通过渐进的上采样完成深层特征图谱的编码,比直接上采样造成的损失少;
(3)通过残差连接有效的完成了特征的融合。
残差连接可以表示为:
![]()

RSU与残差模块的区别在于,RSU将单一的卷积替换为了UNet结构,这样每一个残差内部能够提取到多尺度特征,而且由于都是在降采样后的特征图谱上进行操作因此替换为:
![]()
UNet后增加的计算量并不显著。在Fig4中的对比中也能看出RSU并没有明显增加计算资源的需求,与Dense block,inception block相比,计算资源均会随内部通道数M指数增长,并且RSU增长的系数更小。
 Part B U2Net
Part B U2Net
前人的研究中通向将多个U形结构堆叠成一个序列,但会随着堆叠次数使得计算成本大大增加。
本文则使用新的组合方式-U^n Net,通过嵌套而不是级联的方式来组合UNet,其中指数n可以是任意正数,本文取n=2.
因此整体结构如Fig5所示,外层UNet中每一层均是一个RSU模块,外层包含6层编码网络、5层解码网络以及中间的特征融合模块。

En_1,2,3,4分别使用7,6,5,4层的RSU,而En5,6此时特征图分辨率以及很小因此采用L=4,并且使用的是空洞卷积,因此在这两层的RSU中的特征图分辨率保持不变。
而解码结构与编码网络是对应的,以及同样将解码网络对应层在上采样前进行了级联;
最后一部分则是显著性图谱融合模块,主要就是产生显著性的概率图谱,本文通过3x3卷积从前面的En_6,De_5,4,3,2,1经过sigmoid激活后获得显著性图谱,随后通过1x1 conv进行融合或者最终的概率图谱。
这样搭建的U^ 2 Net搭建个更深层次网络、能够捕获更多尺度的特征同时没有增加维阿的计算成本,并且可以灵活多变配置成不同规模,本文搭建了两种规模的U ^ 2 Net分别为176.3MB和轻量级的4.7MB的版本。
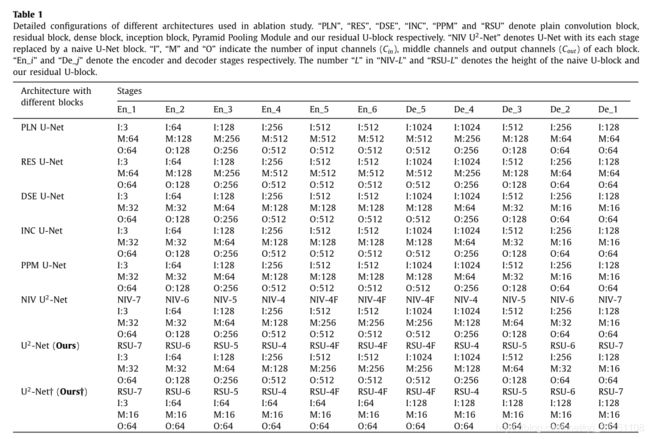
Table 1展示了U^2 Net的具体信息。I,M,O分别代表输入通道数、中间通道数和输出通道数。NIV代表原始的UNet,RSU代表本文提出的模块,后面的数字则代表L层。
Part C Supervision
训练阶段使用与HED类似的监督手段,因此损失函数定义为:

包含每一层(Sup1-6)输出的显著性图谱以及最后混合后的显著性图谱Sup0,而每一层的损失函数则计算的是交叉熵损失函数。

Section IV Experimental results
Part A Datasets
Training Dataset:
DUTS-TR 是DUTS数据集的一部分,包含10533张 图像,是目前用于显著性目标检测最常用也是规模最大的数据集;本文还使用了水平翻转进行数据增强,因此共21106张训练图像。
Evaluation datasets:
使用了6个基准数据集,分别是:DUT_OMRON,DUTS-TE,HKU-IS,ECSSD,PASCAL-S,SOD,分别包含5168,5019,4447,1000,850和300张图像。有的数据集十分具有挑战性。
Part B Evaluation metrics
显著性目标检测的输出通常与输入的分辨率一致,每一点像素在0-255之间或(0,1)之间,而GT一般是一个2分类图像,如0代表背景1代表前景物体。本文使用的评价指标包括:
PR
Curve
maximal
F-measure
Mean Absolute Error
weighted F-measure
structure measure
relaxed boundary F-measure
Part C Implementation details
图像resize到(320x320)并且随机翻转裁剪至(288x288) 两项损失函数的权重均设置为1
使用Adam优化器 超参数设置为:
![]()
总共训练时间:120hrs 框架 Pytorch0.4.0
Section V Ablation Study
为了验证U^2 Net的有效性开展了一系列消融实验,从以下三方面:基础模块、网络连接方式、神经网络模型 进行实验分析。
Part A Basic Blocks
主要就是验证RSU基础模块的有效性,对照有:
PLN(普通的卷积模块),RSE(残差连接模块),DSE(密集连接模块),INC(Inception类模块)和PPM(金字塔池化模块),详细的结构可以回顾Fig 2(a)-(d)。
而Table 2则展示了以上结构的性能对比,可以看到改进后的模块均比原始的UNet性能要高,因为他们要不具有更深的层次要不就提取多尺度的特征,但依旧比不过本文提出的U ^ 2 Net以及轻量级版本的U^ Net_L.

Part B Architecture
前文也提到过前人研究有通过堆叠更多类似的基本结构搭建更具表征能力的网络,如HourglassNet 和CU Net都是具有代表性的网络,因此本文选择他们与本文嵌套(nested)的方式进行对比,通过Table 2的结果也能看出 本文U^2 Net采用嵌套方式比采用级联的上述两类网络性能更好,并且速度也更快。
Part C Backbones
前人的研究多半基于许多基准网络(如VGG,ResNet)作为编码器,本文无需任何基准网络,因此是backbone free的,但本文还是对比了将本文encoder部分替换为不同的backbone模型,也取得了比前人更为优异的结果,但最好的还是本文的U^2Net,因此本文完全由理由相信这种backbone free的方式具有足够强的表征能力用于SOD任务。
Section VI Comparison with SOTA
Part A Quantitative comparison
本文选择了20种SOTA框架进行对比。Fig 6展示了在六类数据集上本文与其他模型的性能对比。数据对比结果罗列在Table3,4.



可以看到本文提出的U ^ 2 Net基本上都取得了最佳的性能或者前几的性能,并且值得注意的是轻量级版本的U^2 Net仅有4.7MB是目前最小的用于SOD框架,虽然性能略有下降但是非常适合计算资源和内存资源有限的应用场景。

Part B Qualitative comparison
Fig 7则可视化了显著性目标检测的结果,(c)(d)是本文的目标检测结果,可以看到本文框架可以handle不同类型的目标,产生更加精确的目标检测结果,可以看到目标尺度从小到大都可以很好的检测,而其他模型有的会遗漏较小目标或者对大型目标检测效果不佳,而本文对一些形状复杂的目标依旧有较为突出的检测结果,主要得益于U^2 Net有效利用了不同尺度特征,并且以较高分辨率提取到了局部和全局信息。因此可以适应不同场景,产生更为精确的目标检测结果。
Section VII Conclusion
本文提出U ^ 2 Net用于显著性目标检测,主要是嵌套的两层Unet结构,借助本文提出的RSU Block使得网络得以捕获网络不同层次更为丰富的局部和全局信息,并且无需其他backbone网络支持从头训练;
本文还设计了两种不同规模的U^2 Net用于适应不同的场景,实验结果显示本文的性能与其他20种SOTA结果具有可比性。
未来本文将会进一步探索不同技术提升网络的速度、精简网络模型,用于移动端或计算及存储资源有限的应用场景。