mmdetection使用指定的显卡号并行分布式训练
后面的不用看了,直接看最省事版本:
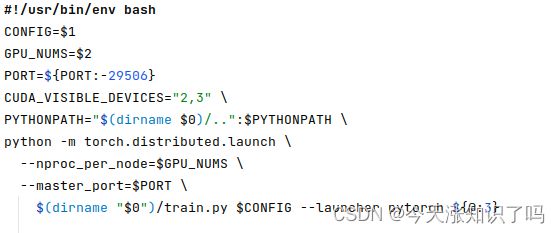
直接用CUDA_VISIBLE_DEVICES="2,3"指定多卡就可以,也可以给sh文件传参进去。但是,切记!切记!切记!sh文件里不能有空行,尤其是使用反斜杠 \ 连接多行的时候,我一开始尝试指定多卡不起作用,就是因为图美观手贱多了个空行,调试了好久。反面教材如下:

到这里就OK了,下面的正文不用看了。懒得删了(╯︵╰)
正文:
今天做目标检测的多卡训练,想两张卡并行跑一组参数,希望在0号和1号显卡上挂两组实验,在2号和3号显卡上挂两组实验,他们都用两张卡并行。为什么不用四张卡并行跑四个实验呢?因为显存不够。使用的命令是tools/dist_train.sh中的python -m torch.distributed.launch...
但是问题出现了:指定双卡并行时每次总会是用0号和1号卡,不管我怎么设置gpu_ids,devices或者local_rank,都不会看23显卡一眼,网上搜了半天,问了许多同学,都未果,于是自己折腾一晚上,终于搞定了。
首先,原理:我猜测是双卡时,两个进程的序号也就是rank会是0和1,于是mmdet分布式训练时就直接用rank序号作为GPU序号。体现在mmdet/apis/train.py中如下部分:
if distributed:
find_unused_parameters = cfg.get('find_unused_parameters', False)
# Sets the `find_unused_parameters` parameter in
# torch.nn.parallel.DistributedDataParallel
model = build_ddp(
model,
cfg.device,
device_ids=[int(os.environ['LOCAL_RANK'])],
broadcast_buffers=False,
find_unused_parameters=find_unused_parameters)
else:
model = build_dp(model, cfg.device, device_ids=cfg.gpu_ids)其中device_ids直接用的rank序号,省时确实省时,可把我折腾坏了。于是我稍作修改,当前两个进程的rank是0和1,我需要用2和3,只需要给他们各自加2即可。于是可以改成
device_ids=[int(os.environ['LOCAL_RANK'])+2],改完这一步后运行,会报错Expected all tensors to be on the same device, but found at least two devices, cuda:2 and cuda:0! 经过检查,发现数据是放到2和3号卡上了,但是模型model还在0和1号卡上,定位到mmdet/utils/util_distribution.py的build_ddp()函数,其中有一句
if device == 'cuda':
model = model.cuda() 这一句默认是放到0号开头的显卡上,需要我们再次加2,把model也放到2和3号卡上,如下:
if device == 'cuda':
from mmcv.runner import get_dist_info
rank, _ = get_dist_info()
model = model.cuda('cuda:{}'.format(rank+2)) 到此为止,就可以成功的把mmdet程序放到2号和3号显卡上训练了,实现过程的不足之处在于没有用参数的形式指定,相当于一个临时措施,我考虑赋值os.environ['LOCAL_RANK']="2,3",但是这是多进程,需要让一个进程看到2,另一个进程看到3,而非两个进程都看到2和3,所以可能需要再次rank, _ = get_dist_info(),根据当前进程的序号改变os.environ['LOCAL_RANK']的值。另外,前面的device_ids=[int(os.environ['LOCAL_RANK'])+2],我后来没有这样做,而是在main.py中os.environ['LOCAL_RANK'] = str(int(os.environ['LOCAL_RANK']) + 2),因为如果后面某些地方把data放大显卡上时仍然直接用rank值,那后面就不需要再给data把rank+2一次。
从上面过程也能看出,多卡并行训练时用哪些卡,主要还是model.cuda()要指定设备号,以及某些原作者图省事直接使用LOCAL_RANK环境变量的地方需要改成自己需要的数字。对了,LOCAL_RANK应该是pytorch自动生成的,我们无法在外围指定。