【研一小白论文精读】《Broaden Your Views for Self-Supervised Video Learning》
Intro
SimCLR
《A Simple Framework for Contrastive Learning of Visual Representations》
就是在编码器后面加一层mlp。

BYOL
《Bootstrap Your Own Latent A New Approach to Self-Supervised Learning》
之前不管是MoCO或者SimCLR都是有正负样本的,BYOL就已经没有负样本也能做对比学习,但是如果没有负样本容易出现模型坍塌,因为只需要相似物体的特征尽可能相似,这个时候就会有一个很明显的捷径解,也就是一个模型不管给他什么输入,它都返回同样的输出,做不了对比学习,loss永远是0,只有加上负样本,相似的物体有相似的特征,不相似的物体也要有相似的特征,而且负样本越多越好,模型才能学,所以负样本是对比学习最关键的地方,没有负样本就没有对比学习。但是BYOL之所以神奇的地方就是它就没有用负样本,正样本自己跟自己学。
一种新的自监督方法来学习特征,为下游视觉任务提供良好的开始。总结一下就是将MoCo和SimClr做一个结合,在加上他们发现了一些东西:

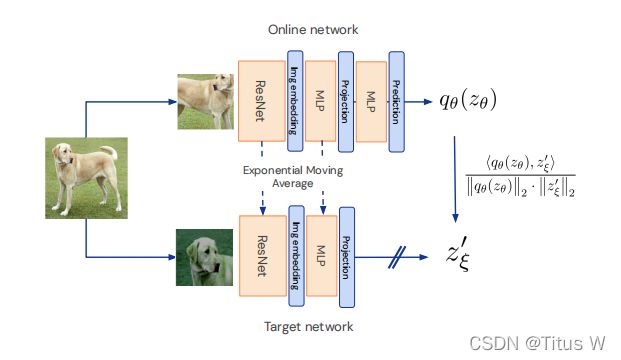
和moco一样的东西在于有两个网络,一个起名online,一个起名target。x会经过两种不同的图像增强策略,既有encoder(f)也有projector(g)。这篇论文研究在于又加了一个predictor得到一个prediction和下面的projection做损失。梯度不会传给target,所以指更新了online,而下面的f克赛和moco一样,梯度是不更新的,而是通过类似与动量的方法去更新。和Simclr相同,加入了projector,如果没有projector,仅仅y之间的相互关系并不明显,所以需要投影到更高维的laent space里面,因此要再使用一串神经网投影到更高维的空间里面得到z。在这个更高维的空间当中,z其实是向量对应的空间中是不同的点,即使两种z是来自同一物体,在在这个高维空间也不是相同的位置,这里本来应该直接做对比学习了,但是再加几层神经网络,也就是predictor,把它投影或者叫预测到target当中的projection里面,其是就相当于一个在同一个latent space里面,由一个vector向另一个vector去推,这样就能强迫这个encoder可以学习更加高级的表达,也就是将匹配问题换成了预测问题。并且在训练过程中是使online network向target network靠拢,而 target network其实是一种过去的online network,但是又没有完全跟上online network,所以就导致无论怎么训练这个模型其实都不能使模型满意。作者也说这里很像GAN,两个模型不断对抗,始终无法将loss降下来。

这里的损失函数就是两个高维vector经过归一化之后的MSE,打开之后就是这两个向量的夹角,越接近越好。
还会进行一次反转,如果把上下两路交换一下,就又得到一个对称的损失,再将这两种相加,就得到最后的损失:
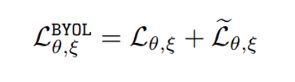
训练好online之后,再用online的参数更新target,所以这里又和moco有些相似。projection是一种更高维的特征z也即projection,上面只是多了一个q,计算完损失只是更新online network向taget network逼近,taget network通过动量也向online network靠拢,但是这两个网络的参数是永远不会与一样的。
所以整体流程就是先初始化online中的encoder,projector和predictor的参数,再初始化target的encoder,projector的参数,反向传播之后,得到对比损失。按照和moco一样动量的方法用online的参数去更新target,使target缓慢地像online靠拢。最后提取出online中的encoder(f),其他部分全部扔掉。
VideoMoco
《: Contrastive Video Representation Learning with Temporally Adversarial Examples》
通过训练一个drop frames有选择性的把视频中的一些帧去剔除,通过这种方式构建一个新的view
原来的moco是用在image上面的,但不能直接拿来做视
频,所以要做一些改进。
Temporally Adversarial Learning
这是一个有对抗的一种性质

输入一个video,上面经过一个生成器得到一个video,下面是原始的video,然后同一个video的两种view经过一个encoder,得到两种rrepresentation做对比学习。原始video先过卷积LSTM得到可一个repretation,这个repretation是对视频每一帧的重要性的预测,LSTM会对视频每一帧的重要性打一个分数,根据这个得分去掉百分之25的帧,可以看到里面有一些帧已经变空了。但是这里做了对抗,为什么是对抗呢?因为Encoder或者叫discriminator希望两种representation尽量接近,因为我们知道这两种representation来源于同一个video,他们理应在feature space里非常接近,但是生成器又会把一些关键的帧drop掉,尽可能让判别器以为这两个输入是两个视频,这样一来一去对抗的过程也产生了。
BraVe

本文提出的narrow view配合multi-mod的Broad View来做contrasting learning。
首先需要先了解两个概念,作者是这么介绍的:
Broad View:如果时间比较长的clip叫做Broad View
Narrow View:一个视频中切出非常短的一个clip形成一个Narrow View
所以这里很自然的就能做一个假设,因为Broad View和Narrow View都是来自同一个视频的,所以他们具有一定的关系,所以他们可以被用来监督对比学习。
Architecture


如图,左边有Narrow view,右边有不同模态的Broad View,他们各自有各自的backbone,fn代表Narrow的网络,提取出一些representation来,fb代表Broad View,右上角的角标代表不同的模态。所以这个视频经过encoder提出representation来,过projector再过predictor可以做contrastive loss,这个contrastive loss其实非常简单用的就是BYOL的vector做nomroalize之后做MSE。这里和BYOL一样,既可以预测从Narrow到Broad,也可以预测从Broad到Narrow,这样两个网络虽然网络结构是不对称的,但是输入是可以相互对称的。
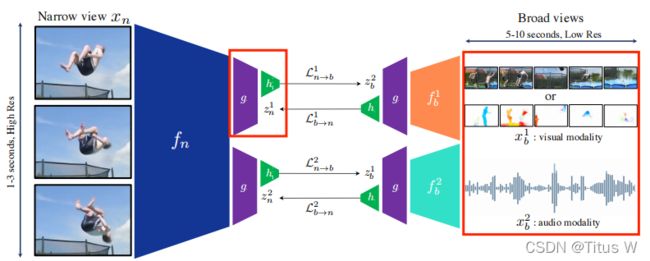
这里需要注意projecter和predictor是在所有的网络中,所有的modality中都是通用的共用一套参数的。不管是Broad View不同的modality,还是Narrow view的这个encoder f都是各自不同的,这种配置作者也是说经过实验是最好的。

对于一个Narrow View,对于一个Broad View来说,他们BYOL的这个loss,sg指只传递一支梯度,也可把这个函数扩展到很多个Broad Views,但是Narrow View始终只有一个。

假如这里有一个Narrow View和很多个Broad Views,最后的这个损失函数,假如有K个Broad View。
Sample and Augmentations
Sample
首先是采样的过程:
broad view:像素比较低,时间比较长,比如定义10s,假如达不到这个长度就做padding把视频循环一遍,把缺失的帧填上就行了。
narrow view:相对讲究一些,clip比较短,也就1s左右,所以不需要padding
Augmentation
Visual:random cropping,horizontal flipping
RGB: Gaussian-blurring, scale, color jittering, (random convolutions)
Audio: sync with narrow
Syncing View
broad view和narrow view从一个时间点出发

同步的话,性能的下降还是比较明显的,这是为什么呢?如果broad view和narrow viewSync之后呢,对于narrow view来说只是单纯做一个predictor,而所有的任务都是做predication。而从broad view到narrow view就更简单了,直接把前面几层留下后面几层都不要,所以Syncing没有必要,不要用。
Importance of the Broad View

作者发现1.3秒和10秒的组合好像还不错,那就这样吧。
Visual Transformation for the Broad View

broad view该用什么样的模态,光流大部分情况都是ok的,在K600上RGB原始像素也还行。
Number of Broad Views

Broad Views越多越好,也能带来提升。
Weight Sharing

Broad Views和Narrow View的backbone是不一样的,而他们的projector和predictor是一样的,为什么这么设计呢,那是因为作者都试过了,发现这一种最好。但是下面不还有种更好的吗?但是假如一种是图像,一种是音频,现实情况下backone是不能一样的。