Unet网络实现叶子病虫害图像分割
作者|李秋键
出品|AI科技大本营(ID:rgznai100)
智能化农业作为人工智能应用的重要领域,对较高的图像处理能力要求较高,其中图像分割作为图像处理方法在其中起着重要作用。图像分割是图像分析的关键步骤,在复杂的自然背景下进行图像分割,
难度较大。
在传统的病虫害图像分割算法中应用最多的是基于统计模式识别、K-均值聚类、模糊C-均值聚类、Otsu、levelset、EM等算法。Gui等人提出了一种基于复杂背景的彩色叶片图像的大豆叶病检测系统,该系统根据K均值算法和结合经验阈值,基于显著性映射从大豆叶片病害图像中分割出显著区域,Kaur等人提出了一种基于K均值聚类算法的葡萄病害叶片图像分割方法.Chaudhary等人提出了一种基于图像处理技术的植物叶片病斑分割算法,比较了CIELAB、HSI和YCbCr颜色空间在病害检测过程中的效果.Mohammad等人比较了阈值法、分水岭法、边缘检测法、模糊C-均值聚类法和K-均值聚类法在植物病害检测中的应用,指出它们适合于任务重叠聚类。
而Unet网络作为图像分割的经典深度学习算法,在植物叶片病虫害区域分割中也起着重要作用。故本项目通过使用python语言搭建Unet图像分割技术实现对植物病虫害区域的分割。其简单训练几轮后的模型效果如下图可见:
1.基本介绍
1.1 环境要求
本次环境使用的是python3.6.5+windows平台。主要用的库有:
opencv模块。在计算机视觉项目的开发中,opencv作为较大众的开源库,拥有了丰富的常用图像处理函数库,采用C/C++语言编写,可以运行在Linux/Windows/Mac等操作系统上,能够快速的实现一些图像处理和识别的任务。
numpy模块。numpy系统是Python的一种开源的数值计算扩展。这种工具可用来存储和处理大型矩阵,比Python自身的嵌套列表结构(nested list structure)要高效得多(该结构也可以用来表示矩阵(matrix))。
pytorch模块。pytorch是一个基于Torch的Python开源机器学习库,用于自然语言处理等应用程序。它主要由Facebookd的人工智能小组开发,不仅能够 实现强大的GPU加速,同时还支持动态神经网络,这一点是现在很多主流框架如TensorFlow都不支持的。PyTorch提供了两个高级功能:1.具有强大的GPU加速的张量计算(如Numpy) 2.包含自动求导系统的深度神经网络 除了Facebook之外,Twitter、GMU和Salesforce等机构都采用了pytorch。
visdom模块。visdom一个灵活的可视化工具,可用来对于 实时,富数据的 创建,组织和共享。支持Torch和numpy还有pytorch。visdom 可以实现远程数据的可视化,对科学实验有很大帮助。我们可以远程的发送图片和数据,并进行在ui界面显示出来,检查实验结果,或者debug。
1.2 Unet模型介绍
U-Net 网络模型是在 2015 年由 Ronneberger 等人提出的。U-Net 基于全卷积网络 FCN,其网络结构与 FCN 相似,都采用了编码器和解码器,以及跳跃连接的拓扑结构,能够实现在少量训练图像上进行更加精准的分割。但是 U-Net 与 FCN 不同之处在于 U-Net 网络是左右对称的。其左侧是用于捕获上下文信息的收缩路径,网络右侧是用于精确定位的扩张路径,与收缩路径对称,以恢复图像大小。编码器对应层的输出特征图经复制、裁减后与反卷积后的特征图通过跳跃连接进行特征融合,然后作为下一层的输入,继续上采样。U-Net 网络在上采样过程中有大量的特征通道,这使得网络能够将上下文信息传到更高分辨率的层。
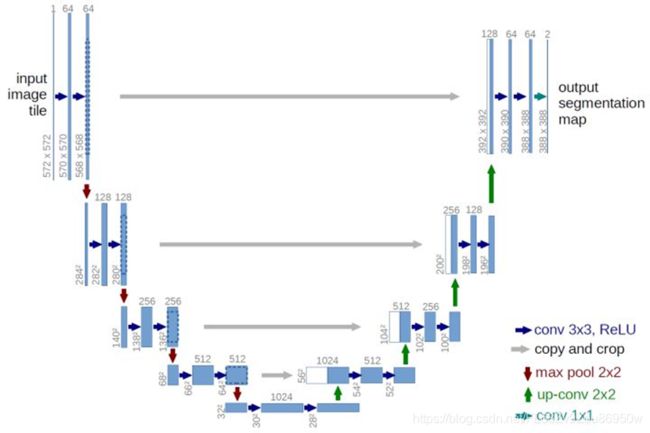
2.模型搭建
2.1数据集准备
首先我们使用labelme工具对需要准备好的数据集进行处理标注。生成对应的json文件放置同一目录即可。其中labelme可以实现对图像进行多边形,矩形,圆形,多段线,线段,点形式的标注(可用于目标检测,图像分割,等任务)。处理格式如下:
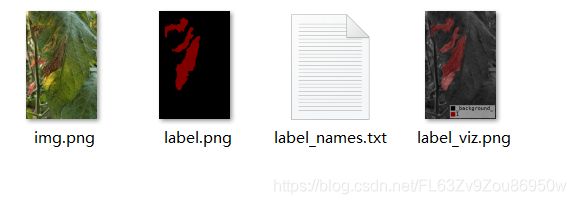
2.2模型创建
U-Net 网络模型结构主要包括编码器、解码器和跳跃连接部分。编码器用于抽象特征、提取信息,解码器部分使得图像逐步恢复原始尺寸,而跳跃连接则将不同层次的特征进行了融合。在这里我们使用segmentation_models_pytorch库实现对unet的直接调用
其中UNet编解码器初始化代码如下:
def __init__(
self,
encoder_name: str = "resnet34",
encoder_depth: int = 5,
encoder_weights: Optional[str] = "imagenet",
decoder_use_batchnorm: bool = True,
decoder_channels: List[int] = (256, 128, 64, 32, 16),
decoder_attention_type: Optional[str] = None,
in_channels: int = 3,
classes: int = 1,
activation: Optional[Union[str, callable]] = None,
aux_params: Optional[dict] = None,
):
super().__init__()
self.encoder = get_encoder(
encoder_name,
in_channels=in_channels,
depth=encoder_depth,
weights=encoder_weights,
)
self.decoder = UnetDecoder(
encoder_channels=self.encoder.out_channels,
decoder_channels=decoder_channels,
n_blocks=encoder_depth,
use_batchnorm=decoder_use_batchnorm,
center=True if encoder_name.startswith("vgg") else False,
attention_type=decoder_attention_type,
)
self.segmentation_head = SegmentationHead(
in_channels=decoder_channels[-1],
out_channels=classes,
activation=activation,
kernel_size=3,
)
2.3 模型训练
设置模型基本参数,其中包括学习率,batchsize,迭代次数,损失值等初始化。UNet 网络及大部分使用 Relu 函数进行激活,能够有效避免和纠正梯度消失问题。
def __init__(self, model):
self.num_workers = 0
self.batch_size = {"train": 8, "val":1}
self.accumulation_steps = 32 // self.batch_size['train']
self.lr = 1e-3
self.num_epochs = 100
self.best_loss = float("inf")
self.best_dice = float(0)
self.phases = ["train", "val"]
self.device = torch.device("cuda:0")
torch.set_default_tensor_type("torch.cuda.FloatTensor")
self.net = model
self.criterion = nn.BCEWithLogitsLoss()
self.optimizer = optim.Adam(self.net.parameters(), lr=self.lr)
self.scheduler = ReduceLROnPlateau(self.optimizer, mode="min", patience=4, verbose=True)
self.net = self.net.to(self.device)
cudnn.benchmark = True
self.dataloaders = {
phase: provider(
image_path=image_path,
phase=phase,
mean=(0.485, 0.456, 0.406),
std=(0.229, 0.224, 0.225),
batch_size=self.batch_size[phase],
num_workers=self.num_workers,
)
for phase in self.phases
}
self.losses = {phase: [] for phase in self.phases}
self.iou_scores = {phase: [] for phase in self.phases}
self.dice_scores = {phase: [] for phase in self.phases}
2.4模型评估
损失函数是神经网络寻找最优权重参数的指标。常用的损失函数有均方误差、交叉熵损失函数等。U-Net 网络中使用了交叉熵损失函数在最后的特征图上通过像素级的 soft-max进行计算。Loss可以通过标准二值交叉熵(binary cross-entropy)和 Dice 损失计算,这是评估图像分割成功与否的常用性能标准。交并比(IoU) 是基于像素的评价标准,通常用于评估分割性能。这里考虑了目标矩阵与结果矩阵之间的不同像素比。这个度量与Dice计算也有关。
def __init__(self, phase, epoch):
self.base_threshold = 0.5 # <<<<<<<<<<< here's the threshold
self.base_dice_scores = []
self.dice_neg_scores = []
self.dice_pos_scores = []
self.iou_scores = []
def update(self, targets, outputs):
probs = torch.sigmoid(outputs)
dice, dice_neg, dice_pos, _, _ = metric(probs, targets, self.base_threshold)
self.base_dice_scores.append(dice)
self.dice_pos_scores.append(dice_pos)
self.dice_neg_scores.append(dice_neg)
preds = predict(probs, self.base_threshold)
iou = compute_iou_batch(preds, targets, classes=[1])
self.iou_scores.append(iou)
def get_metrics(self):
dice = np.mean(self.base_dice_scores)
dice_neg = np.mean(self.dice_neg_scores)
dice_pos = np.mean(self.dice_pos_scores)
dices = [dice, dice_neg, dice_pos]
iou = np.nanmean(self.iou_scores)
return dices, iou
2.5可视化
通过设置visdom模块中的provider建立训练过程中的可视化,然后使用命令“python -m visdom.server”实现浏览器访问训练过程。
def provider(image_path, phase, mean=None, std=None, batch_size=4, num_workers=0,
):
image_list = glob(os.path.join(image_path, "*"))
train_idx, val_idx = train_test_split(range(len(image_list)), random_state=4396, test_size=0.1)
index = train_idx if phase == "train" else val_idx
dataset = CatDataset(index, image_list, phase=phase)
dataloader = DataLoader(dataset, batch_size=batch_size, num_workers=num_workers, pin_memory=True, shuffle=True,)
return dataloader
完整代码:
链接:https://pan.baidu.com/s/11quQOLw7uIP-JJ8LPBIIuQ
提取码:dyrt
作者简介:
李秋键,CSDN博客专家,CSDN达人课作者。硕士在读于中国矿业大学,开发有taptap竞赛获奖等。