只用2秒,轻松获取一线所有城市公交数据!
截止发文,北上广深一共有6510条公交线路
为了获取上面的这些线路信息,我写了一个爬虫,大概用了2秒左右就搞定,真爽!
说出来你们可能不信,别着急,用代码说话,往下看
先给一个代码的使用说明,源码和逻辑见后文
1、核心代码
首先是先获取目标城市的公交线路分类信息,需要传入的参数是城市名称
线路分类是在目标城市的首页会显示,获取起来也比较容易。此外,还需要根据线路标签构造访问的二级URL
其中,主函数代码如下:
# 获取公交线路分类信息
city = 'shenzhen'
dic_city = get_bus_list(city)其次是通过遍历每一个类型的公交线路,获取该线路下的所有的公交路线,并构造每一条公交路线的三级URL,方便后续的信息获取
最后将多个城市的数据合并在一起,就搞定了
# 解析并获取每个线路的数据
df_per_city = get_line_info(dic_city)
df_data = df_data.append(df_per_city, ignore_index=True)程序运行图如下:
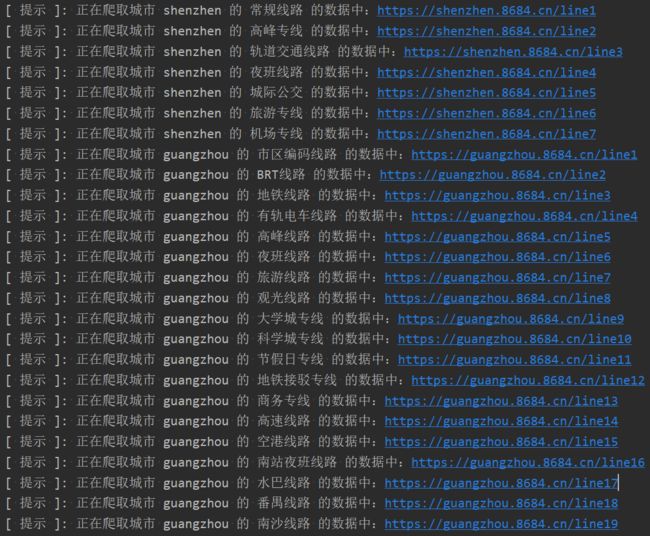
最终爬取的数据如下:
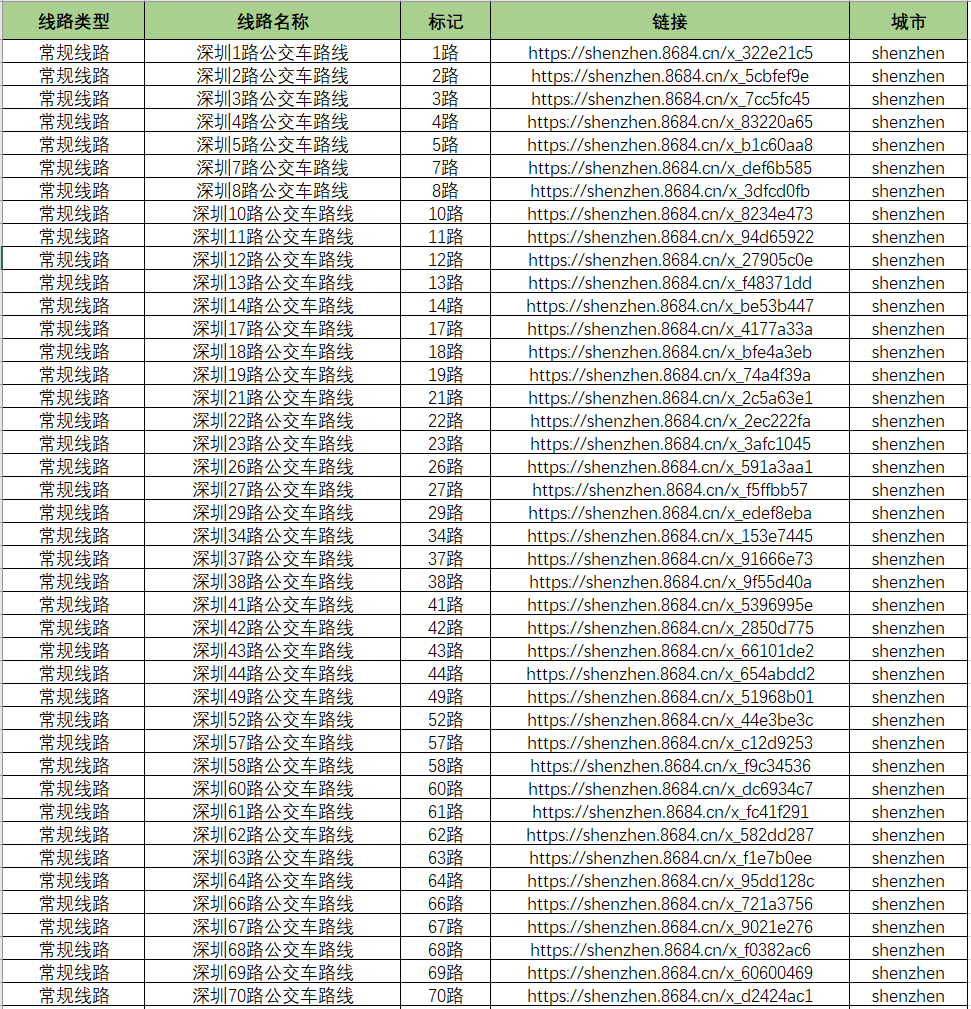
北上广深一共有6510条公交路线
2、爬虫思路
获取源码文件请直接在原文链接中回复 公交站点
原文链接:只用2秒,轻松爬取北上广深所有公交站点数据)
今天的源码其实之前有写过,但是因为过去时间比较久了,没有和官方的更新同步,所以在运行过程中会出现bug
这次我也是将存在的bug修复了,并优化了部分逻辑,比以前的代码运行速度会更快,更快!
今天爬取的网站上面有各种公交站点、地铁站点、违章、资讯等等数据,小功能做的相当不错。
页面长这样:
对应的我们点击热门公交中的某个城市,例如:深圳公交,注意看点击的时候网址栏发生的变化
此时的网址变成了:https://shenzhen.8684.cn/
以此类推,其他城市对应的访问链接想必你会很容易构造出来
点进去之后的页面是这样的:
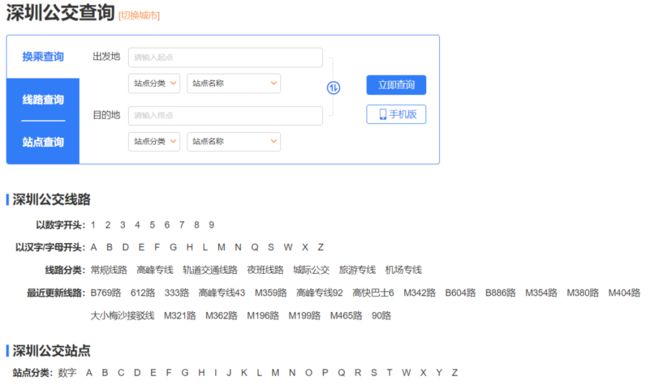
从这几种分类类型来看,路线分类那一栏一定是最标准的,而且在后期的分析过程中一定会最有用。
直接打开F12,进行源码分析(或者在某个超链接上点击右键->检查)内容一目了然
定位到 bus-layer depth w120 的这个 div,然后定位到它的第三个 class为‘pl10’ 的子div,这个就是我们我们需要的线路分类
对应上面的网页显示内容,源码都展开之后是这样的:
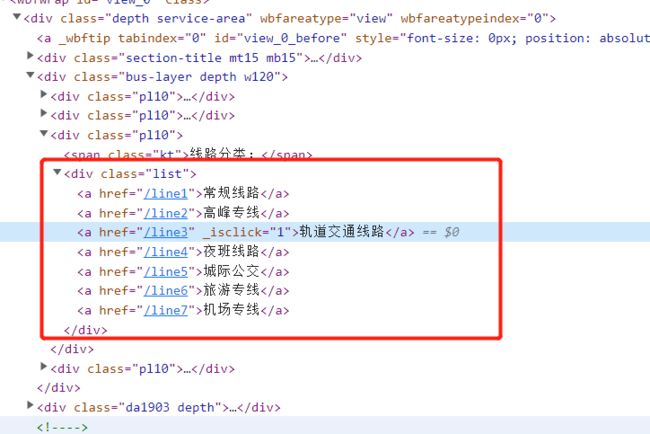
其中有两种标签:class="kt" 的span标签,对应的是分类的标题;class='list' 的div标签,子标签对应的是每一个分类的链接 href 和名称,有用的是第二个标签。
正常点击网页上的某一种分类线路,例如:常规线路,注意看点击的时候网址栏发生的变化
此时的网址变成了:https://shenzhen.8684.cn/line1,也就是在之前链接的结尾加上上面的 href 内容
再回到我们的网页上,可以看到显示的公交路线

同样分析源码,内容如下:
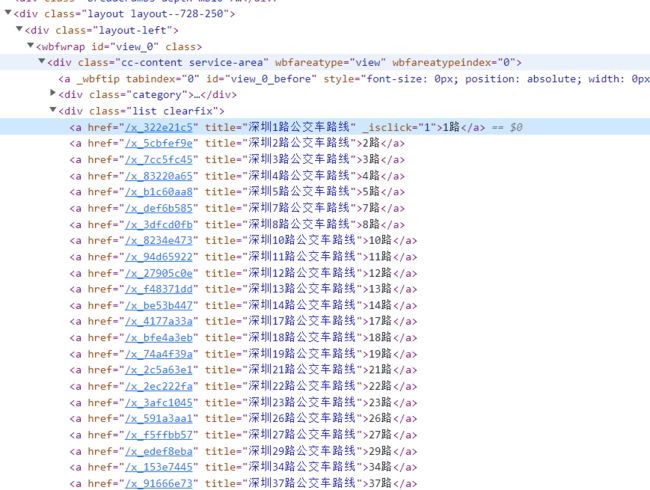
和上面一样的处理思路,在源码中可以直接定位到该类型线路的所有公交线路的详细信息,直接采集即可
代码复现起来也比较简单,但是由于篇幅问题,这里就只展示核心的代码部分
首先是解析公交路线类型,并构造每一个类型的二级URL
# 解析公交路线类型
if '线路分类' in name:
soup_a_list = soup_bus.find('div', class_='list')
for soup_a in soup_a_list.find_all('a'):
text = soup_a.get_text()
href = soup_a.get('href')
dic_result[text] = "https://{0}.8684.cn{1}".format(city, href)其次是解析每一条公交线路,包括的字段有:线路类型、线路名称、标记、链接和城市
其中的链接是每一个公交线路的详情链接,里面有该线路的票价、开始时间、结束时间、站点信息等等
核心代码如下:
# 解析每一条公交线路
for soup_a in soup_buslist.find_all('a'):
text = soup_a.get_text()
href = soup_a.get('href')
title = soup_a.get('title')
bus_arr.append([key, title, text, "https://{0}.8684.cn{1}".format(city, href), city, '未更新'])以上是核心源码,这里省去了非核心部分,需要请查看源码文件。
原文链接:只用2秒,轻松爬取北上广深所有公交站点数据)
原创不易,希望大家在看完文章的同时,记得一键三连