吴恩达机器学习课后习题(多分类逻辑回归)
一、多分类逻辑回归
需要构建分类器,每次分类时,将多类分为第i类与非第i类两种类别,再利用逻辑回归的高级优化算法进行计算。
二、实现多分类逻辑回归
导入多个包,使用的数据集为.matlab格式,需要用到loadmat包读取mat文件。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
from scipy.io import loadmat
from sklearn.metrics import classification_report#这个包是评价报告
读取文件内容,文件中X中有5000个图像,每个图像有400个值大小。随机抽取其中100个图像,将这100个图像的行和列赋值给sample_images变量。使用ax_array变量循环记录100个matlab图像,并设置各图像不显示横纵坐标。
path = "E:\\Pycharm\\workspace\\ex3_Andrew\\ex3data1.mat"
data = loadmat(path) #loadmat方法获得matlab类型的数据
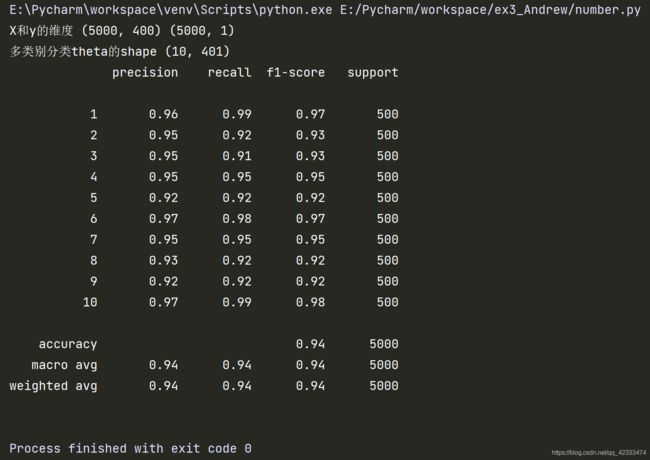
print("X和y的维度",data['X'].shape,data['y'].shape) #(5000, 400) (5000, 1),每个X里有400个值构成图片,每个y只有1个值对应数字
sample_idx = np.random.choice(np.arange(data['X'].shape[0]),100) #参数100是choice的参数
#np.arange()方法返回一个有起点和终点的排列,第一个参数为起点0,步长默认为1,排序出0,1,2...4999的数列
#np.random.choice()方法在数组中随机抽取元素,参数为a,共抽取100个随机数
sample_images = data['X'][sample_idx,:] #抽取X中的随机100行的每一列 (100,400)
fig,ax_array = plt.subplots(nrows=10,ncols=10,sharey=True,sharex=True,figsize=(8,8))
#subplots()函数用于创建画布,nrows为行数,ncols为列数;sharex,sharey设置各子图之间共享轴的属性
for r in range(10): #循环控制(r,n)为(0,0)(0,1)...(9,9)
for n in range(10):
ax_array[r,n].matshow(np.array(sample_images[10*r+n].reshape((20,20))).T,cmap=matplotlib.cm.binary)
#sample_images每次循环控制为(0,1,2...9,10,11...98,99),每个sample_images有400个属性,reshape()函数将其转化为20行20列,
#cmap代表一种颜色映射方式,matplotlib.cm.binary为二值图
plt.xticks(np.array([])) #显示x的刻度为空,即每个图片上没有刻度
plt.yticks(np.array([])) #显示y的刻度为空,即每个图片上没有刻度
#plt.show() #函数可以显示已做好的图像,是10行十列的数字图像
定义sigmoid函数,代价函数,梯度计算函数。代价函数中包含reg项为正则化项,梯度计算函数使用向量化方法计算(与之前的梯度函数计算公式不同,但结果相差不大)。
def sigmoid(z):
return 1/(1+np.exp(-z))
def cost(theta,X,y,learningrate):
theta = np.matrix(theta)
X = np.matrix(X)
y = np.matrix(y)
first = np.multiply(y,np.log(sigmoid(X*theta.T)))
second = np.multiply((1-y),np.log((1-sigmoid(X*theta.T))))
reg = (learningrate*np.sum(np.power(theta[:,1:theta.shape[1]],2)))/(2*len(X))
return -(np.sum(first+second))/len(X)+reg
def gradient(theta,X,y,learningrate): #梯度计算函数,另一种计算梯度用于高级优化算法的方法
theta = np.matrix(theta)
X = np.matrix(X)
y = np.matrix(y)
error = sigmoid(X*theta.T)-y
grad = ((X.T*error)/len(X)).T + (learningrate/len(X))*theta
grad[0,0] = np.sum(np.multiply(error, X[:, 0])) / len(X)
return np.array(grad).ravel()
构建分类器。导入minimize包使用高级优化算法TNC,分类器中zeros函数将all_theta初始化为10401的矩阵,用于和X数据集进行sigmoid运算,X矩阵增加第一列全1为5000401矩阵。
本项目为分类十种数字,故应循环十次,结果集y中有十种数字,y_i保存50001的向量,向量中1项为同类,0项为不同类。
在y_i中做好分类后,向量中仅剩0与1两种情况,才可以进行逻辑回归,使用高级优化算法进行逻辑回归,将算出的theta值附在all_theta矩阵中,最后返回整体的theta矩阵(10401)。
from scipy.optimize import minimize
def one_vs_all(X,y,num_labels,learning_rate):
rows = X.shape[0] #X的行数为5000
params = X.shape[1] #X的列数为400
all_theta = np.zeros((num_labels,params+1)) #返回数组类型,为num_lables行的401个属性的数组
X = np.insert(X,0,values=np.ones(rows),axis=1) #values为内容,5000个值为1,插入X的最前列,共401列数据
for i in range(1,num_labels+1): #y有十种分类,循环10次
theta = np.zeros(params+1) #theta向量初始化为401个为0的数组
y_i = np.array([1 if label==i else 0 for label in y]) #label变量等于y中的值时,结果返回1
y_i = np.reshape(y_i,(rows,1)) #将y_i向量转化为5000*1的向量
fmin = minimize(fun=cost, x0=theta, args=(X, y_i, learning_rate), method='TNC', jac=gradient)
all_theta[i-1,:]=fmin.x #minimize函数返回值中的x为计算出的theta向量
return all_theta #函数计算后得到theta矩阵
all_theta = one_vs_all(data['X'],data['y'],10,1) #y共有10种值,分别为十个数字,返回的theta向量
print("多类别分类theta的shape",all_theta.shape) #(10,401) 转置后401*10,与X矩阵(5000*401)相乘可以计算代价
对计算得出的结果进行预测与评价。使用h变量记录数据集X与刚算好的theta向量的sigmoid函数(5000*10),argmax函数以每一行为一组(一行10个数),返回最大值的0-9的索引,+1后返回给y_pre变量,用classfication_report方法返回报告,参数为真是数据与预测数据,得到准确率、召回率与f1值。
使用100个随机的数值进行预测计算,检查时使用原训练集中5000个数据项。
def predict_all(X,all_theta):
rows = X.shape[0]
X = np.insert(X,0,values=np.ones(rows),axis=1)
all_theta = np.matrix(all_theta)
h = sigmoid(X*all_theta.T) #X为(5000*401),all_theta.T为(401,10),返回为5000*10的矩阵,值为0-1之间
h_argmax = np.argmax(h,axis=1) #返回h中最大值的索引值,在0到9之间,(5000,1)
return h_argmax+1 #数字0对应的y值是10,故要+1
y_pre = predict_all(data['X'],all_theta) #y_pre为5000行1列向量,值为预测得出的y值
print(classification_report(data['y'], y_pre)) #打印精确度、召回率、F1值、support为出现的次数,参数为真实值与预测值
三、运行结果
读取mat文件且循环初始化记录时运行速度慢。原数据集中有5000个数字,每种数字500个。