PyTorch 中的 graph mode 在性能方面表示更为出色,本文介绍 Torch.FX 这个强大工具,可以捕捉和优化 PyTorch 程序 graph。
一、简介
PyTorch 支持两种执行模式:eager mode 和 graph mode。
eager mode 中,模型中的运算符在读取时会立即执行,它易于使用,对机器学习从业者更友好,因此被设置为默认的执行模式。
graph mode 中,运算符先被合成一个 graph,然后作为一个整体进行编译和执行,它的性能更高,因此在实际生产中大量使用。
具体来说,graph mode 支持算子融合,两个算子通过合并,可以降低或本地化内存读取以及内核启动总开销。
融合可以是横向 (horizontal) 的:采取应用于多个 operand 的单一操作(如 BatchNorm),并将这些 operand 合并到一个数组中。
融合也可以是纵向 (vertical) 的:将一个内核与另一个内核合并,后者需要使用第一个内核的输出(如 ReLU 后接卷积)。
Torch.FX(缩写为 FX)是一个公开可用的工具包,作为 PyTorch 软件包的一部分,支持 graph mode 的执行。它可以:
- 从 PyTorch 程序中获取 graph
- 允许开发者在获取的 graph 上编写 transformation**
Meta 内部先前已经在用 FX 来优化生产模型 (production model) 的训练吞吐量 (training throughput)。本文将通过介绍 Meta 开发的基于 FX 的优化,来展示利用图结构转换 (graph transformation) 优化 PyTorch 部署模型性能的方法
二、背景
embedding table 广泛存在于推荐系统中,本节将介绍 FX 和 embedding table 的背景知识。
2.1. FX
图 1 是一个简单示例,演示了如何用 FX 转换 PyTorch 程序,它包含三个步骤:
- 从程序中获取 graph
- 修改 graph(在本例中,我们用 GELU 代替 RELU)
- 从修改后的 graph 中生成一个新程序

图1:在 PyTorch 模块中用 GELU 取代 RELU 的 FX
FX API 为检查和转换 PyTorch 程序 graph 还提供了许多其他功能。
2.2. embedding table
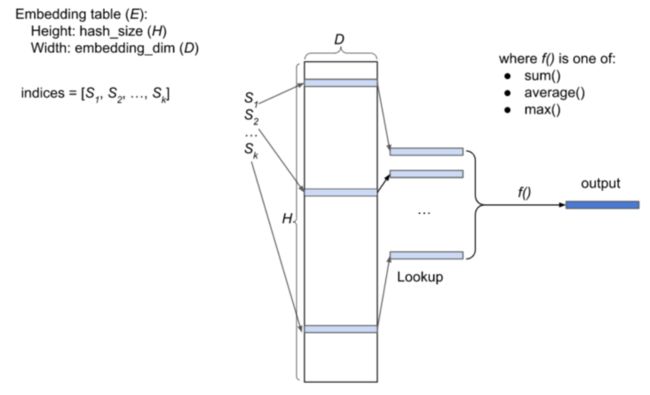
图2:批尺寸=1 的稀疏特征 embedding table 示意图
在推荐系统中,稀疏特征(例如,User ID,Story ID)由 embedding table 表示。
embedding table E 是一个 HxD 矩阵,其中 H 是哈希大小,D 是嵌入向量维度。E 的每一行都是一个浮点数向量。
feature hashing 的作用是将一个稀疏特征映射到 E的索引列表中,例如 [S1,S2,...,Sk],其中 0≤Si 为了充分利用 GPU,稀疏特征通常为批处理。批处理中的每个实体都有自己的索引列表。如果一个批次有 B 个实体,可以简单理解为一个表征有 B 个索引列表。 更为严谨的表示方法是将 B 个索引列表合并成一个索引列表,并添加一个索引长度的列表(该批中的每个实体都有一个长度 length)。 例如,如果一批包含 3 个实体,其索引列表如下: 则完整批尺寸的 indice 和 length 将是: 而整个 batch 的 embedding table 查询,输出为是一个 BxD 矩阵。 PyTorch 更新了 3 个 FX transformation,以加速对 embedding table 的访问,本节将逐一介绍。 下文 3.1 关于将多个小输入张量结合成一个大张量的转换;3.2 关于将多个并行计算链融合成一个计算链的转换;3.3 关于将通信与计算重叠的转换。 batch 中的每个输入稀疏特征,都可以表示为两个列表:一个索引列表和一个 B length 列表,其中 B 表示批尺寸。 在 PyTorch 中,这两个列表都可以以张量的形式存在。当 PyTorch 模型在 GPU 上运行时,embedding table 通常存储在 GPU 内存中(它更接近 GPU,读写带宽比 CPU 内存更高)。 需要使用输入稀疏特征时,两个张量都要先从 CPU 复制到 GPU。然而每个主机到设备的内存复制都需要启动内核,这对于实际的数据传输来说,会更加耗费时间。 如果一个模型使用了多个输入稀疏特征,这种复制可能成为性能瓶颈(例如,1000 个输入稀疏特征将需要从主机到设备复制 2000 个张量)。 一个减少主机到设备 memcpy 数量的优化方法,就是在多个输入稀疏特征发送到设备之前,先将其进行组合。 例如,给定以下三个输入特征: 组合后的形式为: Features_A_B_C: indices = [106, 211, 7, 52, 498, 616, 870, 1013, 2011, 19, 351, 790], lengths = [2, 1, 3, 2, 1, 3] 所以不需要从主机到设备复制 3x2=6 个张量,只需要复制 2 个张量。 图 3(b) 描述了这种优化的实现,它包含两个组件: 在一个生产模型中,每个 GPU 上有 10 个 embedding table 很常见。出于性能方面的考虑,对这些 table 的查询被分到一组,这样它们的输出就被串联在一个大张量中(见图 4(a)中的红色部分)。 为了对单个特征输出进行计算,使用 Split 算子将大张量分成 N 个小张量(其中 N 为特征的数量),然后将所需的计算应用于每个张量。 如图 4(a) 所示,应用于每个特征输出 O 的计算是Tanh(LayerNorm(O))。所有的计算结果都被串联成一个大的张量,然后传递给下游的算子(图 4(a) 中的 Op1)。 这里主要的 runtime cost 是 GPU 内核启动的开销。例如,图 4(a) 中的 GPU 内核的启动次数为 2*N+3(图中的每个椭圆都表示一个 GPU 内核)。这会影响性能,因为 LayerNorm 和 Tanh 在 GPU 上的执行时间,与它们的内核启动时间相比很短。 此外,Split 算子可能会创建一个额外的嵌入向量输出张量的副本,消耗额外的 GPU 内存。 用 FX 来实现一种叫做横向融合 (horizontal fusion) 的优化,可以大大减少 GPU 内核的启动次数(在这个例子中,优化后的 GPU 内核启动次数为 5,见图 4(b))。 使用 Add_middle_dim 算子代替显式 Split,将 shape 为 (B, NxD) 的 2D 嵌入张量重塑为 shape 为 (B, N, D) 的 3D 张量。接下来将一个单一的 LayerNorm 应用到它的最后一维。对 LayerNorm 的结果应用一个 Tanh。最后,用 Remove_middle_dim 算子将 Tanh 的结果恢复成 2D 张量。 由于 Add_middle_dim 和 Remove_middle_dim 只是重塑张量,并没有创建额外的副本,所以也可以减少 GPU 内存的消耗。 面向投产的推荐模型的训练,通常是在分布式 GPU 系统上完成的。由于每个 GPU 的设备内存容量不足以容纳模型中的所有 embedding table,因此需要将其分布在多个 GPU 上。 在训练步骤中,GPU 需要从其他 GPU 上的 embedding table 中读取/写入特征值。这被称为 all-to-all 通信,可能是影响性能的重要原因。 通过 FX 实现一个 transformation,可以将计算与 all-to-all 通信重叠。图 5(a) 显示了一个具备嵌入向量 table 访问 (EmbeddingAllToAll) 及其他算子的模型 graph 实例。如图 5(b) 所示,在没有任何优化的情况下,它们会在一个 GPU 流上顺序执行。 使用FX将 EmbeddingAllToAll 分成 EmbeddingAllToAll_Request和EmbeddingAllToAll_Wait,并在它们之间安排独立的算子。 图5:计算与通信的重叠 为了发现哪些模型会从这些 transformation 中受益,开发人员对 MAIProf 收集的运行在 Meta 数据中心的模型的性能数据进行分析。得出与 eager mode 相比,这些 transformation 在一组生产模型上实现了 2-3 倍的速度提升。 从性能角度考量,PyTorch 中的 graph mode 比生产环境中使用的 eager mode 更受欢迎。FX 是一个强大的工具,可以捕捉和优化 PyTorch 程序 graph。本文展示了三种 FX transformation,用于优化 Meta 内部的生产推荐模型。 最后希望更多 PyTorch 开发者可以使用 graph transformation 来提升模型的性能。 —— 完 ——
三、3 种 FX Transformation
3.1 结合输入稀疏特征
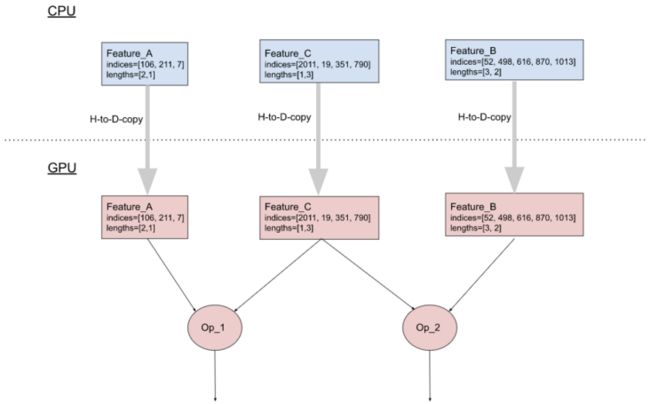
优化前:两个张量都要从 CPU 复制到 GPU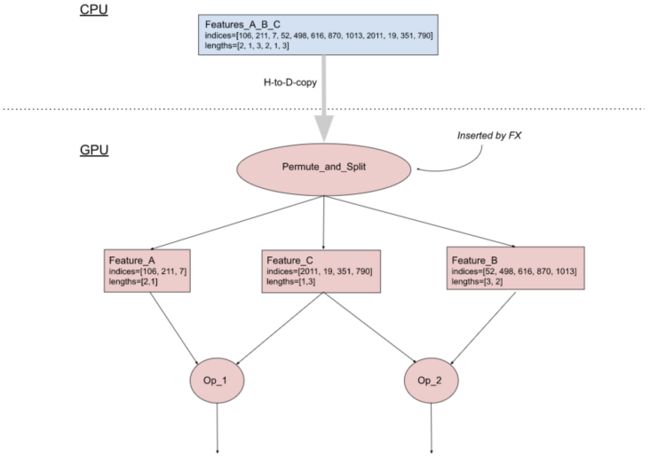
优化后:将输入稀疏特征进行组合3.2 从访问 embedding table 开始的计算链横向融合
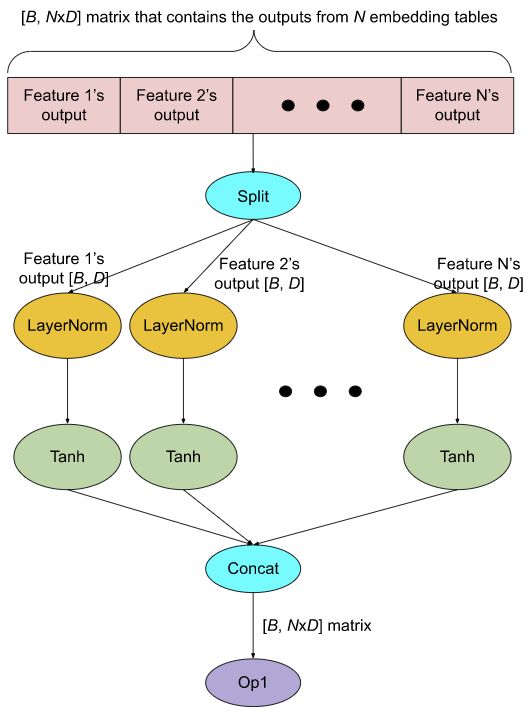
优化前:所有输出被串联到一个大张量中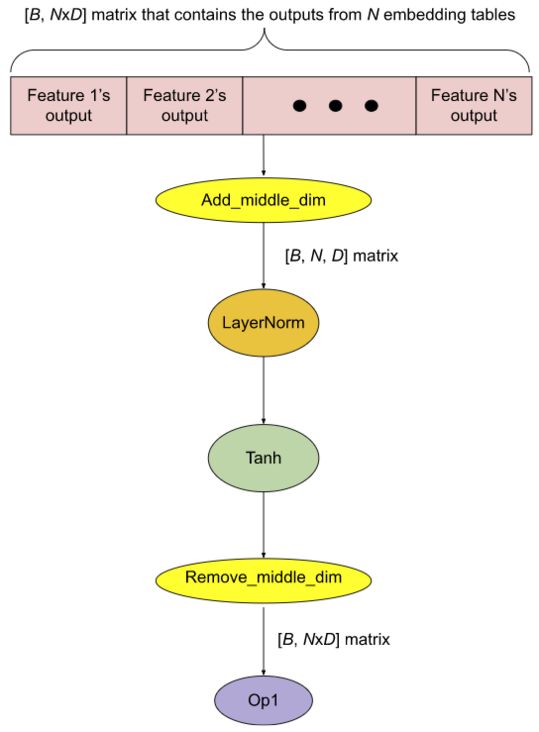
进行横向融合优化后3.3 计算与通信间的重叠 (overlap)
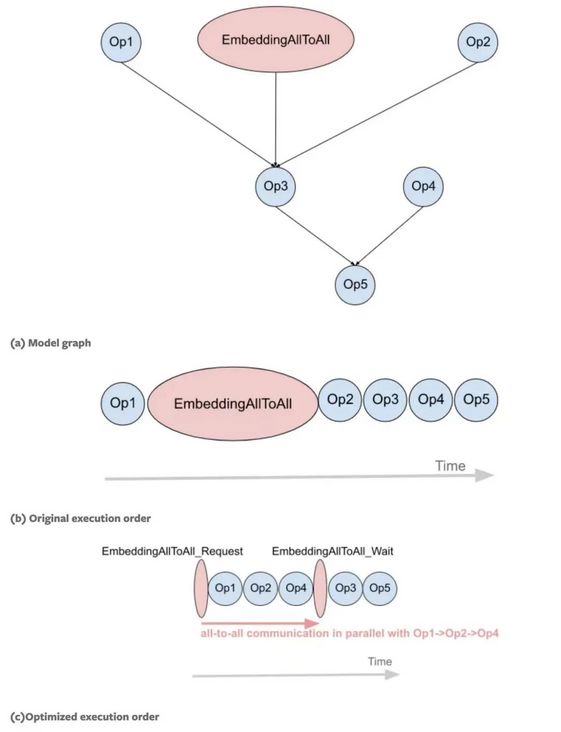
3.4 总结

表1:本节讨论的优化及解决的相应性能瓶颈四、结语