神经网络调参技巧:warmup策略
有一些论文对warmup进行了讨论,使用 SGD 训练神经网络时,在初始使用较大学习率而后期改为较小学习率在各种任务场景下都是一种广为使用的做法,在实践中效果好且最近也有若干文章尝试对其进行了理论解释。例如《On Layer Normalization in the Transformer Architecture》等,论文中作者发现Post-LN Transformer在训练的初始阶段,输出层附近的期望梯度非常大,所以没有warm-up的话模型优化过程就会非常不稳定。
虽然在实践中效果好且最近也有若干文章尝试对其进行了理论解释,但到底为何有效,目前还没有被充分证明。
Transformer中的warm-up可以看作学习率 lr 随迭代数 t 的函数:

学习率 lr 会以某种方式递减,学习率从0开始增长,经过 Twarmup 次迭代达到最大。论文中对Adam,SGD等有无warmup做了实验,
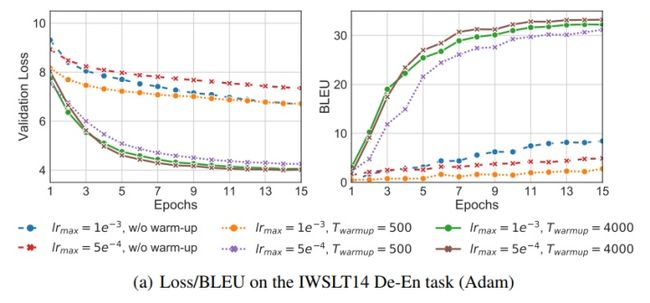
可以看到,warmup增加了训练时间,同时在最初阶段使用较大的学习率会导致Loss偏大,对模型的训练的影响是巨大的。warmup在这里对SGD是非常重要的。

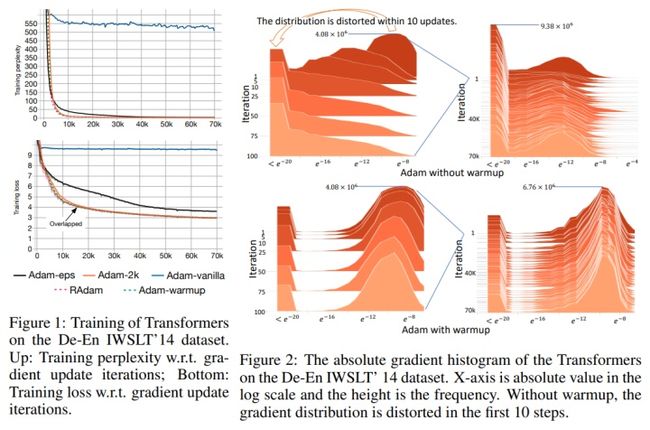
Rectified Adam针对warmup前期数据样本不足导致的biased variance的问题提出了解决方案,论文中实验结果看到还是有一定效果的。RAdam 由随机初始化带来的 Variance 比较小。即使隔离掉 warmup 部分的影响后Variance 也是要比 Adam 小的。


class AdamWarmup(Optimizer):
# DOTA
def __init__(self, params, lr=1e-3, betas=(0.9, 0.999), eps=1e-8, weight_decay=0, warmup = 0):
if not 0.0 <= lr:
raise ValueError("Invalid learning rate: {}".format(lr))
if not 0.0 <= eps:
raise ValueError("Invalid epsilon value: {}".format(eps))
if not 0.0 <= betas[0] < 1.0:
raise ValueError("Invalid beta parameter at index 0: {}".format(betas[0]))
if not 0.0 <= betas[1] < 1.0:
raise ValueError("Invalid beta parameter at index 1: {}".format(betas[1]))
defaults = dict(lr=lr, betas=betas, eps=eps,
weight_decay=weight_decay, warmup = warmup)
super(AdamW, self).__init__(params, defaults)
def __setstate__(self, state):
super(AdamW, self).__setstate__(state)
def step(self, closure=None):
loss = None
if closure is not None:
loss = closure()
for group in self.param_groups:
for p in group['params']:
if p.grad is None:
continue
grad = p.grad.data.float()
if grad.is_sparse:
raise RuntimeError('Adam does not support sparse gradients, please consider SparseAdam instead')
p_data_fp32 = p.data.float()
state = self.state[p]
if len(state) == 0:
state['step'] = 0
state['exp_avg'] = torch.zeros_like(p_data_fp32)
state['exp_avg_sq'] = torch.zeros_like(p_data_fp32)
else:
state['exp_avg'] = state['exp_avg'].type_as(p_data_fp32)
state['exp_avg_sq'] = state['exp_avg_sq'].type_as(p_data_fp32)
exp_avg, exp_avg_sq = state['exp_avg'], state['exp_avg_sq']
beta1, beta2 = group['betas']
state['step'] += 1
exp_avg_sq.mul_(beta2).addcmul_(1 - beta2, grad, grad)
exp_avg.mul_(beta1).add_(1 - beta1, grad)
denom = exp_avg_sq.sqrt().add_(group['eps'])
bias_correction1 = 1 - beta1 ** state['step']
bias_correction2 = 1 - beta2 ** state['step']
if group['warmup'] > state['step']:
scheduled_lr = 1e-8 + state['step'] * group['lr'] / group['warmup']
else:
scheduled_lr = group['lr']
step_size = scheduled_lr * math.sqrt(bias_correction2) / bias_correction1
if group['weight_decay'] != 0:
p_data_fp32.add_(-group['weight_decay'] * scheduled_lr, p_data_fp32)
p_data_fp32.addcdiv_(-step_size, exp_avg, denom)
p.data.copy_(p_data_fp32)
return lossclass RAdam(Optimizer):
def __init__(self, params, lr=1e-3, betas=(0.9, 0.999), eps=1e-8, weight_decay=0, degenerated_to_sgd=False):
if not 0.0 <= lr:
raise ValueError("Invalid learning rate: {}".format(lr))
if not 0.0 <= eps:
raise ValueError("Invalid epsilon value: {}".format(eps))
if not 0.0 <= betas[0] < 1.0:
raise ValueError("Invalid beta parameter at index 0: {}".format(betas[0]))
if not 0.0 <= betas[1] < 1.0:
raise ValueError("Invalid beta parameter at index 1: {}".format(betas[1]))
self.degenerated_to_sgd = degenerated_to_sgd
if isinstance(params, (list, tuple)) and len(params) > 0 and isinstance(params[0], dict):
for param in params:
if 'betas' in param and (param['betas'][0] != betas[0] or param['betas'][1] != betas[1]):
param['buffer'] = [[None, None, None] for _ in range(10)]
defaults = dict(lr=lr, betas=betas, eps=eps, weight_decay=weight_decay, buffer=[[None, None, None] for _ in range(10)])
super(RAdam, self).__init__(params, defaults)
def __setstate__(self, state):
super(RAdam, self).__setstate__(state)
def step(self, closure=None):
loss = None
if closure is not None:
loss = closure()
for group in self.param_groups:
for p in group['params']:
if p.grad is None:
continue
grad = p.grad.data.float()
if grad.is_sparse:
raise RuntimeError('RAdam does not support sparse gradients')
p_data_fp32 = p.data.float()
state = self.state[p]
if len(state) == 0:
state['step'] = 0
state['exp_avg'] = torch.zeros_like(p_data_fp32)
state['exp_avg_sq'] = torch.zeros_like(p_data_fp32)
else:
state['exp_avg'] = state['exp_avg'].type_as(p_data_fp32)
state['exp_avg_sq'] = state['exp_avg_sq'].type_as(p_data_fp32)
exp_avg, exp_avg_sq = state['exp_avg'], state['exp_avg_sq']
beta1, beta2 = group['betas']
exp_avg_sq.mul_(beta2).addcmul_(1 - beta2, grad, grad)
exp_avg.mul_(beta1).add_(1 - beta1, grad)
state['step'] += 1
buffered = group['buffer'][int(state['step'] % 10)]
if state['step'] == buffered[0]:
N_sma, step_size = buffered[1], buffered[2]
else:
buffered[0] = state['step']
beta2_t = beta2 ** state['step']
N_sma_max = 2 / (1 - beta2) - 1
N_sma = N_sma_max - 2 * state['step'] * beta2_t / (1 - beta2_t)
buffered[1] = N_sma
# more conservative since it's an approximated value
if N_sma >= 5:
step_size = math.sqrt((1 - beta2_t) * (N_sma - 4) / (N_sma_max - 4) * (N_sma - 2) / N_sma * N_sma_max / (N_sma_max - 2)) / (1 - beta1 ** state['step'])
elif self.degenerated_to_sgd:
step_size = 1.0 / (1 - beta1 ** state['step'])
else:
step_size = -1
buffered[2] = step_size
# more conservative since it's an approximated value
if N_sma >= 5:
if group['weight_decay'] != 0:
p_data_fp32.add_(-group['weight_decay'] * group['lr'], p_data_fp32)
denom = exp_avg_sq.sqrt().add_(group['eps'])
p_data_fp32.addcdiv_(-step_size * group['lr'], exp_avg, denom)
p.data.copy_(p_data_fp32)
elif step_size > 0:
if group['weight_decay'] != 0:
p_data_fp32.add_(-group['weight_decay'] * group['lr'], p_data_fp32)
p_data_fp32.add_(-step_size * group['lr'], exp_avg)
p.data.copy_(p_data_fp32)
return loss