【python】Pandas(series、dataframe)
目录
Pandas
(一)定义
(二)使用场景
(三)安装
(四)导入
Series---pandas
(一)定义
(二)可存储数据类型
(三)函数
1、创建series
DataFrame---pandas
(一)定义
(二)可存储数据类型
(三)函数
1、创建DataFrame
2、加载数据 read_csv
3、查看哪里有空值 isnull().sum()
4、空值填充 fillna
5、行列选择 loc
6、获取数据具体某一个值 at 、iloc
7、分组 Grouping
Pandas
(一)定义
pandas是python的核心数据分析支持库(numpy是计算)
(二)使用场景
1、与 SQL 或 Excel 表类似的,含异构列的表格数据
2、 有序和无序(非固定频率)的时间序列数据
3、带行列标签的矩阵数据,包括同构或异构型数据
4、任意其它形式的观测、统计数据集, 数据转入 Pandas 数据结构时不必事先标记
(三)安装
pip install pandas
(四)导入
导入pandas(通常与numpy一起使用)
import pandas as pdSeries---pandas
(一)定义
带标签的一维同构数组
(二)可存储数据类型
可存储整数、浮点数、字符串、Python 对象等类型的数据
(三)函数
1、创建series
s = pd.Series(data, index=index)(1)参数
- data:
data 支持以下数据类型:
Python 字典
多维数组
标量值(如,5)
- index:行索引
(2)例子
① data为多维数组
s = pd.Series(np.random.randn(5),index=['a', 'b', 'c', 'd', 'e'])
print(s, type(s)) 
② data为Python 字典
d = {'a': 1, 'b': 2, 'c': 3}
e = pd.Series(d)
print(e)注意:
提取data里任意index对应的值,没有该索引的值为NaN
print(pd.Series(d, index=['a', 'q']))
与dict相同,如果key不存在,则用get NaN,不会报错
print(s.get('f',np.nan))

③标量值
标量值生成series,Series 按索引长度重复该标量值
# 3、标量值生成series,Series 按索引长度重复该标量值
q = pd.Series(416, index=['a', '1', 'c'])
print(q)
2、提取为series数组(有逗号)
print(q.array)
3、转换为npdrray数组 (无逗号)
print(q.to_numpy())![]()
DataFrame---pandas
(一)定义
带标签的、大小可变的二维异构表格
由多种类型的列构成的二维标签数据结构,类似于 Excel 、SQL 表,或 Series 对象构成的字典
(二)可存储数据类型
(三)函数
1、创建DataFrame
pd.DataFrame(d)例1:
import pandas as pd
import numpy as np
d = {'one': pd.Series([1., 2., 3.], index=['a', 'b', 'c']),
'two': pd.Series([1., 2., 3., 4.], index=['a', 'b', 'c', 'd'])}
df=pd.DataFrame(d)
print(df)one two:列索引
a、b、c、d:行索引

例2:
df2 = pd.DataFrame({'A': 1.,
'B': pd.Timestamp('20220705'),
'C': pd.Series(1, index=list(range(4)), dtype='float32'),
'D': np.array([3] * 4, dtype='int32'),
'E': pd.Categorical(["test", "train", "test", "train"]),
'F': 'foo'})
print(df2)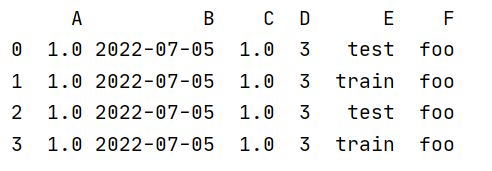
2、加载数据 read_csv
(读取的文件,分隔符,重新定义列名)
df = pd.read_csv("movieClassifyData.csv", sep=',', names=columns, header=0)3、查看哪里有空值 isnull().sum()
:统计每一列中为空的个数
print(df.isnull().sum())4、空值填充 fillna
:用c这一列的均值(mean)填充该空值,inplace=true 操作保存
# 填充:用c这一列的均值填充该空值,inplace=true 操作保存
df['c'].fillna(df.c.mean(),inplace=True)5、行列选择 loc
参数(行,列)::所有行 ['a','b'] 前两列(a.b两列)
print(df.loc[:,['a','b']])
6、获取数据具体某一个值 at 、iloc
①at(第几行,第几列)
print(df.at[1,'a'])
②iloc(第几行到第几行,第几列到第几列) 整数区间
前四行(0-3)、前两列(0-1)
print(df.iloc[0:4, 0:2])
例3:数据的输入输出
(1)加载数据 (读取的文件,分隔符,重新定义列名,)
import pandas as pd
import numpy as np
columns = ['a', 'b', 'c', 'label']
# 1.加载数据 (读取的文件,分隔符,重新定义列名,)
df = pd.read_csv("movieClassifyData.csv", sep=',', names=columns, header=0)
print(df)
(2)缺失值处理 处理空列-填充(均值、众数)/剔除
①查看哪里有空值:统计每一列中为空的个数
print(df.isnull().sum())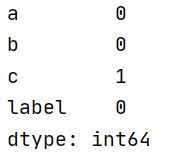
发现c这一列有一个空值,单独获取到这一列
print(df['c'])
②空值填充:用c这一列的均值(mean)填充该空值,inplace=true 操作保存
# 填充:用c这一列的均值填充该空值,inplace=true 操作保存
df['c'].fillna(df.c.mean(),inplace=True)
print(df['c'])
原本为空值的索引为3的这一行现在被c列均值填充为25.2
再检查一下是否还有空值
print(df.isnull().sum())
7、分组 Grouping
(1)读取数据 (待读取文件,分隔符,表头,是否有行号)
# 读取数据 (待读取文件,分隔符,表头,是否有行号)
df=pd.read_csv("student.txt",sep=',',names=columns,index_col=0)如果没有index_col=0:

(2)分组 groupby
# 分组:每个科目平均成绩
df_subj=df.groupby('学科')['成绩'].mean()
print(df_subj)
例4:
先创建表头
columns=['学号','学科','单元','成绩']
(1)读取数据
# 读取数据 (待读取文件,分隔符,表头,是否有行号)
df=pd.read_csv("student.txt",sep=',',names=columns,index_col=0)
print(df)
一般不要把文件内容全部打印,使用head和shape可以大概查看文件内容
# 查看结构,先打印前几行查看
print(df.head(),df.shape)可以看到将学号作为了行索引

(2)统计每个科目平均成绩 (分组依据:科目)
# 分组:每个科目平均成绩
df_subj=df.groupby('学科')['成绩'].mean()
print(df_subj)
拆分来看,先对学科进行分组
# 分组:每个科目平均成绩
df_subj=df.groupby('学科')
print(df_subj)
for i in df_subj:
print(i)可以看到根据学科分成了语文、数学、英语三组

再接着根据学科分组只显示成绩
df_subj=df.groupby('学科')['成绩']
print(df_subj)
for i in df_subj:
print(i)只显示成绩一列
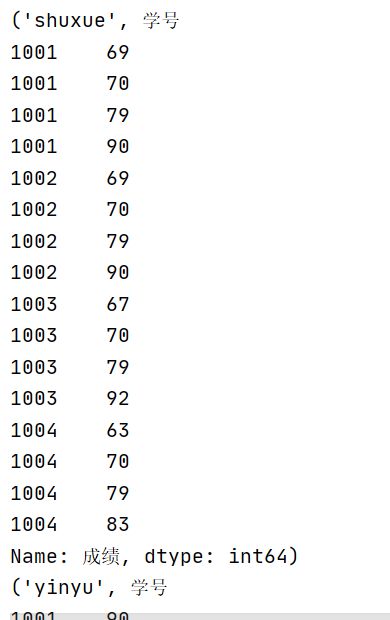
再求学科成绩平均数
# 分组:每个科目平均成绩
df_subj=df.groupby('学科')['成绩'].mean()
print(df_subj)
(3)统计每个同学每个科目平均成绩
根据两个点分组:学生和科目
# 分组:每个学生每门科目平均成绩
df_stubmn = df.groupby(['学号','学科'])['成绩']
print(df_stubmn)
for j in df_stubmn:
print(j)会显示每个同学每门科目的四个单元一组的成绩

加上平均数,可得到每个同学每门成绩的平均数
# 分组:每个学生每门科目平均成绩
df_stubmn = df.groupby(['学号','学科'])['成绩'].mean()
print(df_stubmn)
for j in df_stubmn:
print(j)