CasRel关系抽取项目
任务描述:
任务目标为使用深度学习算法,通过对输入文本进行分析,得到文本中主体、客体和其之间对应的关系。本项目采用主体预测和关系预测两个模块。用bert分词之后词向量先预测主题subject位置,然后将预测位置的词向量加到整个句子的词向量得到新的词向量,通过新的词向量来预测此主体对应的客体和其对应关系。

数据集
本项目采用百度中文关系抽取数据集 DuIE 2.0。数据集包括48个已定义好的关系schema,43个简单知识schema,5个复杂知识的schema。其中predicate为48个主客体之间的关系。

训练样本格式为:text和sop_list两部分组成,每行为一个样本。

第一步:数据预处理
由于可能输入文本采用中英文混合,若bert分词方式采用中文的话其文本中的英文则被识别为< UNK>,预测位置不能和文本中英文位置对应。所以在原本的训练集样本后还要加上offset_mapping,其第一步处理后的数据结构为:
再次整理数据,只留下文本,分词id,offset_mapping,主体的头尾,文本中三元组关系(主体,关系,客体)和三元组关系的id值。
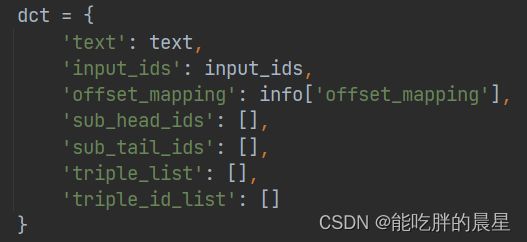
最后按批量对数据进行读取,按一个批量中最长的句子进行填充,返回三部分。batch_mask为填充的mask;batch_text为上图中的text文本、文本i分词后的id值、offset_mapping值和文本元组关系;batch_sub_rnd为一句话中的随机选择的一个主体;batch_sub为这句话中的所有主体;batch_obj_rel为随机选择的那个主体对应的客体和关系矩阵。其目的是:通过batch_text来预测全部主体batch_sub,通过一句话中的某一个主体batch_sub_rnd来预测这个主体对应的客体和关系矩阵batch_obj_rel。
class Dataset(data.Dataset):
def __init__(self, type='train'):
super().__init__()
_, self.rel2id = get_rel()
# 加载文件
if type == 'train':
file_path = TRAIN_JSON_PATH
elif type == 'test':
file_path = TEST_JSON_PATH
elif type == 'dev':
file_path = DEV_JSON_PATH
with open(file_path, encoding='UTF-8') as f:
self.lines = f.readlines()
# 加载bert
self.tokenizer = BertTokenizerFast.from_pretrained(BERT_MODEL_NAME)
def __len__(self):
return len(self.lines)
def __getitem__(self, index):
line = self.lines[index]
info = json.loads(line)
tokenized = self.tokenizer(info['text'], return_offsets_mapping=True)
info['input_ids'] = tokenized['input_ids']
info['offset_mapping'] = tokenized['offset_mapping']
return self.parse_json(info)
def parse_json(self, info):
text = info['text']
input_ids = info['input_ids']
dct = {
'text': text,
'input_ids': input_ids,
'offset_mapping': info['offset_mapping'],
'sub_head_ids': [],
'sub_tail_ids': [],
'triple_list': [],
'triple_id_list': []
}
for spo in info['spo_list']:
subject = spo['subject']
object = spo['object']['@value']
predicate = spo['predicate']
dct['triple_list'].append((subject, predicate, object))
# 计算 subject 实体位置
tokenized = self.tokenizer(subject, add_special_tokens=False)
sub_token = tokenized['input_ids']
sub_pos_id = self.get_pos_id(input_ids, sub_token)
if not sub_pos_id:
continue
sub_head_id, sub_tail_id = sub_pos_id
# 计算 object 实体位置
tokenized = self.tokenizer(object, add_special_tokens=False)
obj_token = tokenized['input_ids']
obj_pos_id = self.get_pos_id(input_ids, obj_token)
if not obj_pos_id:
continue
obj_head_id, obj_tail_id = obj_pos_id
# 数据组装
dct['sub_head_ids'].append(sub_head_id)
dct['sub_tail_ids'].append(sub_tail_id)
dct['triple_id_list'].append((
[sub_head_id, sub_tail_id],
self.rel2id[predicate],
[obj_head_id, obj_tail_id],
))
return dct
def get_pos_id(self, source, elem):
for head_id in range(len(source)):
tail_id = head_id + len(elem)
if source[head_id:tail_id] == elem:
return head_id, tail_id - 1
def collate_fn(self, batch):
batch.sort(key=lambda x: len(x['input_ids']), reverse=True)
max_len = len(batch[0]['input_ids'])
batch_text = {
'text': [],
'input_ids': [],
'offset_mapping': [],
'triple_list': [],
}
batch_mask = []
batch_sub = {
'heads_seq': [],
'tails_seq': [],
}
batch_sub_rnd = {
'head_seq': [],
'tail_seq': [],
}
batch_obj_rel = {
'heads_mx': [],
'tails_mx': [],
}
for item in batch:
input_ids = item['input_ids']
item_len = len(input_ids)
pad_len = max_len - item_len
input_ids = input_ids + [0] * pad_len
mask = [1] * item_len + [0] * pad_len
# 填充subject位置
sub_heads_seq = multihot(max_len, item['sub_head_ids'])
sub_tails_seq = multihot(max_len, item['sub_tail_ids'])
# 随机选择一个subject
if len(item['triple_id_list']) == 0:
continue
sub_rnd = random.choice(item['triple_id_list'])[0]
sub_rnd_head_seq = multihot(max_len, [sub_rnd[0]])
sub_rnd_tail_seq = multihot(max_len, [sub_rnd[1]])
# 根据随机subject计算relations矩阵
obj_head_mx = [[0] * REL_SIZE for _ in range(max_len)]
obj_tail_mx = [[0] * REL_SIZE for _ in range(max_len)]
for triple in item['triple_id_list']:
rel_id = triple[1]
head_id, tail_id = triple[2]
if triple[0] == sub_rnd:
obj_head_mx[head_id][rel_id] = 1
obj_tail_mx[tail_id][rel_id] = 1
# 重新组装
batch_text['text'].append(item['text'])
batch_text['input_ids'].append(input_ids)
batch_text['offset_mapping'].append(item['offset_mapping'])
batch_text['triple_list'].append(item['triple_list'])
batch_mask.append(mask)
batch_sub['heads_seq'].append(sub_heads_seq)
batch_sub['tails_seq'].append(sub_tails_seq)
batch_sub_rnd['head_seq'].append(sub_rnd_head_seq)
batch_sub_rnd['tail_seq'].append(sub_rnd_tail_seq)
batch_obj_rel['heads_mx'].append(obj_head_mx)
batch_obj_rel['tails_mx'].append(obj_tail_mx)
return batch_mask, (batch_text, batch_sub_rnd), (batch_sub, batch_obj_rel)
第二步:构建模型
模型都是根据bert分词加上线性层来进行预测,输入为整个句子id值和句中某个主体的头和尾。对主体sub部分的预测,先将整个句子的id值input_ids进行bert转化为bert输出值encoded_text,再经过linear层进行预测;对客体和关系矩阵预测则将句中某个主体的头尾分别乘整个句子的encoded_text,再将其与encoded_text相加来经过linear层预测某个关系的客体头和尾,遍历所有关系即可得到整个客体关系矩阵obj_rel。
class CasRel(nn.Module):
def __init__(self):
super().__init__()
self.bert = BertModel.from_pretrained(BERT_MODEL_NAME)
# 冻结Bert参数,只训练下游模型
for name, param in self.bert.named_parameters():
param.requires_grad = False
self.sub_head_linear = nn.Linear(BERT_DIM, 1)
self.sub_tail_linear = nn.Linear(BERT_DIM, 1)
self.obj_head_linear = nn.Linear(BERT_DIM, REL_SIZE)
self.obj_tail_linear = nn.Linear(BERT_DIM, REL_SIZE)
def get_encoded_text(self, input_ids, mask):
return self.bert(input_ids, attention_mask=mask)[0]
def get_subs(self, encoded_text):
pred_sub_head = torch.sigmoid(self.sub_head_linear(encoded_text))
pred_sub_tail = torch.sigmoid(self.sub_tail_linear(encoded_text))
return pred_sub_head, pred_sub_tail
def get_objs_for_specific_sub(self, encoded_text, sub_head_seq, sub_tail_seq):
# sub_head_seq.shape (b, c) -> (b, 1, c)
sub_head_seq = sub_head_seq.unsqueeze(1).float()
sub_tail_seq = sub_tail_seq.unsqueeze(1).float()
# encoded_text.shape (b, c, 768)
sub_head = torch.matmul(sub_head_seq, encoded_text)
sub_tail = torch.matmul(sub_tail_seq, encoded_text)
encoded_text = encoded_text + (sub_head + sub_tail) / 2
# encoded_text.shape (b, c, 768)
pred_obj_head = torch.sigmoid(self.obj_head_linear(encoded_text))
pred_obj_tail = torch.sigmoid(self.obj_tail_linear(encoded_text))
# shape (b, c, REL_SIZE)
return pred_obj_head, pred_obj_tail
def forward(self, input, mask):
input_ids, sub_head_seq, sub_tail_seq = input
encoded_text = self.get_encoded_text(input_ids, mask)
pred_sub_head, pred_sub_tail = self.get_subs(encoded_text)
# 预测relation-object矩阵
pred_obj_head, pred_obj_tail = self.get_objs_for_specific_sub(\
encoded_text, sub_head_seq, sub_tail_seq)
return encoded_text, (pred_sub_head, pred_sub_tail, pred_obj_head, pred_obj_tail)
第三步:训练网络
拿到dataset和model之后就可以进行网络模型的训练,其损失函数为预测主体sub的损失和客体与关系obj_rel损失两部分的加和。但预测主体是预测后面的先决条件故在主体上的罚要增大,而由于预测数据中01分布不均衡,为了预测出更多的1,我们需要在预测为0的后面再乘上权重来增大预测为1的概率。
def loss_fn(self, true_y, pred_y, mask):
def calc_loss(pred, true, mask):
true = true.float()
# pred.shape (b, c, 1) -> (b, c)
pred = pred.squeeze(-1)
weight = torch.where(true > 0, CLS_WEIGHT_COEF[1], CLS_WEIGHT_COEF[0])
loss = F.binary_cross_entropy(pred, true, weight=weight, reduction='none')
if loss.shape != mask.shape:
mask = mask.unsqueeze(-1)
return torch.sum(loss * mask) / torch.sum(mask)
pred_sub_head, pred_sub_tail, pred_obj_head, pred_obj_tail = pred_y
true_sub_head, true_sub_tail, true_obj_head, true_obj_tail = true_y
return calc_loss(pred_sub_head, true_sub_head, mask) * SUB_WEIGHT_COEF + \
calc_loss(pred_sub_tail, true_sub_tail, mask) * SUB_WEIGHT_COEF + \
calc_loss(pred_obj_head, true_obj_head, mask) + \
calc_loss(pred_obj_tail, true_obj_tail, mask)
定好损失函数后就可以进行反向梯度更新了。
model = CasRel().to(DEVICE)
optimizer = torch.optim.Adam(model.parameters(), lr=LR)
dataset = Dataset()
for e in range(EPOCH):
loader = data.DataLoader(dataset, batch_size=BATCH_SIZE, shuffle=True, collate_fn=dataset.collate_fn)
for b, (batch_mask, batch_x, batch_y) in enumerate(loader):
batch_text, batch_sub_rnd = batch_x
batch_sub, batch_obj_rel = batch_y
# 整理input数据并预测
input_mask = torch.tensor(batch_mask).to(DEVICE)
input = (
torch.tensor(batch_text['input_ids']).to(DEVICE),
torch.tensor(batch_sub_rnd['head_seq']).to(DEVICE),
torch.tensor(batch_sub_rnd['tail_seq']).to(DEVICE),
)
encoded_text, pred_y = model(input, input_mask)
# 整理target数据并计算损失
true_y = (
torch.tensor(batch_sub['heads_seq']).to(DEVICE),
torch.tensor(batch_sub['tails_seq']).to(DEVICE),
torch.tensor(batch_obj_rel['heads_mx']).to(DEVICE),
torch.tensor(batch_obj_rel['tails_mx']).to(DEVICE),
)
loss = model.loss_fn(true_y, pred_y, input_mask)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if b % 50 == 0:
print('>> epoch:', e, 'batch:', b, 'loss:', loss.item())
if e % 3 == 0:
torch.save(model, MODEL_DIR + f'model_{e}.pth')
在kaggle云gpu上进行训练50个eopch。
第四步:模型评估
经过50个eopch后获得模型,下载模型到本地进心模型评估。
model = torch.load(MODEL_DIR + f'model_27.pth', map_location=DEVICE)
dataset = Dataset('dev')
with torch.no_grad():
loader = data.DataLoader(dataset, batch_size=2, shuffle=False, collate_fn=dataset.collate_fn)
correct_num, predict_num, gold_num = 0, 0, 0
pred_triple_list = []
true_triple_list = []
for b, (batch_mask, batch_x, batch_y) in enumerate(loader):
batch_text, batch_sub_rnd = batch_x
batch_sub, batch_obj_rel = batch_y
# 整理input数据并预测
input_mask = torch.tensor(batch_mask).to(DEVICE)
input = (
torch.tensor(batch_text['input_ids']).to(DEVICE),
torch.tensor(batch_sub_rnd['head_seq']).to(DEVICE),
torch.tensor(batch_sub_rnd['tail_seq']).to(DEVICE),
)
encoded_text, pred_y = model(input, input_mask)
# 整理target数据并计算损失
true_y = (
torch.tensor(batch_sub['heads_seq']).to(DEVICE),
torch.tensor(batch_sub['tails_seq']).to(DEVICE),
torch.tensor(batch_obj_rel['heads_mx']).to(DEVICE),
torch.tensor(batch_obj_rel['tails_mx']).to(DEVICE),
)
loss = model.loss_fn(true_y, pred_y, input_mask)
print('>> batch:', b, 'loss:', loss.item())
# 计算关系三元组,和统计指标
pred_sub_head, pred_sub_tail, _, _ = pred_y
true_triple_list += batch_text['triple_list']
# 遍历batch
for i in range(len(pred_sub_head)):
text = batch_text['text'][i]
true_triple_item = true_triple_list[i]
mask = batch_mask[i]
offset_mapping = batch_text['offset_mapping'][i]
sub_head_ids = torch.where(pred_sub_head[i] > SUB_HEAD_BAR)[0]
sub_tail_ids = torch.where(pred_sub_tail[i] > SUB_TAIL_BAR)[0]
pred_triple_item = get_triple_list(sub_head_ids, sub_tail_ids, model, \
encoded_text[i], text, mask, offset_mapping)
# 统计个数
correct_num += len(set(true_triple_item) & set(pred_triple_item))
predict_num += len(set(pred_triple_item))
gold_num += len(set(true_triple_item))
pred_triple_list.append(pred_triple_item)
precision = correct_num / (predict_num + EPS)
recall = correct_num / (gold_num + EPS)
f1_score = 2 * precision * recall / (precision + recall + EPS)
print('\tcorrect_num:', correct_num, 'predict_num:', predict_num, 'gold_num:', gold_num)
print('\tprecision:%.3f' % precision, 'recall:%.3f' % recall, 'f1_score:%.3f' % f1_score)