商品评价实体情感识别项目
任务描述:
任务目标为使用深度学习算法,通过对商品的评价进行分析,得到评价中指代的实体商品位置和其对应的情感(好评/差评)。 输入一串文字序列,通过网络模型进行预测,最终输出该文字序列的实体标签和情感标签。本项目采用实体预测和情感预测双模块结构,经过bert分词之后词向量分为两份,其中一份用来进行实体识别任务,另一份用来进行情感分类任务。
第一步:数据预处理
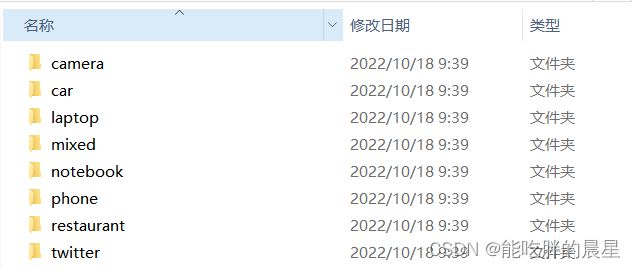
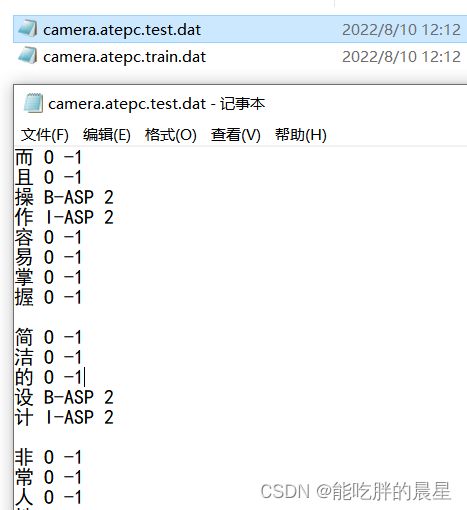
首先观察数据,原始数据都是以文件夹的形式存储,每个文件夹中有.test和.train文件。其中第一列为电商评论,第二列为BIO实体标注,第三列为情感标注(其中-1为不关心 0为不好 2为好评价),每句话之间以空行形式进行分割。
我们需要将这些杂乱的数据进行处理,转化为我们能利用上的格式。首先将上面.test和.train文件中一行一个字的形式转化为一行一句话的形式(字与字之间用空格进行分割)。为了看起来直观,我们将情感分类中的-1 0 2 转化为-1 0 1。
# 转化为一行一句话的形式
def format_sample(file_paths, output_path):
text = bio = pola = ''
items = []
for file_path in file_paths:
with open(file_path, encoding='UTF-8') as f:
for line in f.readlines():
if line == '\n':
items.append({'text': text.strip(), 'bio': bio.strip(), 'pola': pola.strip()})
text = bio = pola = ''
continue
t, b, p = line.split(' ')
text += t + ' '
bio += b + ' '
# 将感情2改为1
p = str(1) if p.strip() == str(2) else p.strip()
pola += p + ' '
df = pd.DataFrame(items)
df.to_csv(output_path, index=None)
# 将错误的样本删除 e.g.如果实体是B,情感是-1则删除
def check_label():
# pola中 -1是不关心 0是差评 1是好评
df = pd.read_csv(TRAIN_FILE_PATH)
dct = {}
for index, row in df.iterrows():
for b, p in zip(row['bio'].split(), row['pola'].split()):
if b == 'B-ASP' and p == '-1':
print(index, row)
df.drop(index=index, inplace=True)
cnt = dct.get((b,p), 0)
dct[(b,p)] = cnt+1
print(dct)
df.to_csv(TRAIN_FILE_PATH, index=None)
format_sample([
'./input/camera/camera.atepc.train.dat',
'./input/car/car.atepc.train.dat',
'./input/notebook/notebook.atepc.train.dat',
'./input/phone/phone.atepc.train.dat',
], TRAIN_FILE_PATH)
format_sample([
'./input/camera/camera.atepc.test.dat',
'./input/car/car.atepc.test.dat',
'./input/notebook/notebook.atepc.test.dat',
'./input/phone/phone.atepc.test.dat',
], TEST_FILE_PATH)
check_label()
第二步:定义Dataset并读取数据
由于每个样本句子过短且每句中所含实体个数少,所以我们将样本中相邻的两句话用分号(;)拼接,实体标签用O进行拼接,情感标签用-1进行拼接,形成新的训练样本并按照每个batch中最长的句子来进行padding填充。返回时,除了返回batchsize个input_id,mask(bool形式,用于后面CRF层传入参数),实体和情感标签之外,还要返回batchsize个句子中每个句子随机选择的一个实体得到的cdm和cdw用来后续预测情感分类。还要返回所有实体的位置和情感的标签作为一个元组,用来计算模型预测的准确率。
class Dataset(data.Dataset):
def __init__(self, type='train'):
super().__init__()
file_path = TRAIN_FILE_PATH if type == 'train' else TEST_FILE_PATH
self.df = pd.read_csv(file_path)
self.tokenizer = BertTokenizer.from_pretrained(BERT_MODEL_NAME)
def __len__(self):
return len(self.df) - 1
def __getitem__(self, index):
# 相邻两个句子拼接
text1, bio1, pola1 = self.df.loc[index]
text2, bio2, pola2 = self.df.loc[index+1]
text = text1 + ' ; ' + text2
bio = bio1 + ' O ' + bio2
pola = pola1 + ' -1 ' + pola2
# 为避免样本中有中英混用导致模型分词错误的情况,我们采用手动tokenize
tokens = ['[CLS]'] + text.split(' ') + ['[SEP]']
input_ids = self.tokenizer.convert_tokens_to_ids(tokens)
# 实体标签转id
bio_arr = ['O'] + bio.split(' ') + ['O']
bio_label = [BIO_MAP[l] for l in bio_arr]
# 情感标签转数字
pola_arr = ['-1'] + pola.split(' ') + ['-1']
pola_label = list(map(int, pola_arr))
return input_ids, bio_label, pola_label
def collate_fn(self, batch):
# 统计最大句子长度
batch.sort(key=lambda x: len(x[0]), reverse=True)
max_len = len(batch[0][0])
# 变量初始化
batch_input_ids = []
batch_bio_label = []
batch_mask = []
batch_ent_cdm = []
batch_ent_cdw = []
batch_pola_label = []
batch_pairs = []
for input_ids, bio_label, pola_label in batch:
# 获取实体位置,没有实体跳过
ent_pos = get_ent_pos(bio_label)
if len(ent_pos) == 0:
continue
# 填充句子长度
pad_len = max_len - len(input_ids)
batch_input_ids.append(input_ids + [BERT_PAD_ID] * pad_len)
batch_mask.append([1] * len(input_ids) + [0] * pad_len)
batch_bio_label.append(bio_label + [BIO_O_ID] * pad_len)
# 实体和情感分类对应
pairs = []
for pos in ent_pos:
pola = pola_label[pos[0]]
pairs.append((pos, pola))
batch_pairs.append(pairs)
# 由于训练样本中有可能一句话中有不定的实体数量,为避免造成系统不稳定,
# 我们采用每句话只取一个实体来进行训练,其他的实体可能会在其他的epoch中得到训练
sg_ent_pos = random.choice(ent_pos)
cdm, cdw = get_ent_weight(max_len, sg_ent_pos)
batch_ent_cdm.append(cdm)
batch_ent_cdw.append(cdw)
# 实体第一个字的情感极性
pola = pola_label[sg_ent_pos[0]]
batch_pola_label.append(pola)
return (
torch.tensor(batch_input_ids),
torch.tensor(batch_mask).bool(),
torch.tensor(batch_bio_label),
torch.tensor(batch_ent_cdm),
torch.tensor(batch_ent_cdw),
torch.tensor(batch_pola_label),
batch_pairs,
)
def get_ent_weight(max_len, ent_pos):
cdm = []
cdw = []
for i in range(max_len):
dst = min(abs(i - ent_pos[0]), abs(i - ent_pos[-1]))
if dst <= SRD:
cdm.append(1)
cdw.append(1)
else:
cdm.append(0)
cdw.append(1 - (dst - SRD + 1) / max_len)
return cdm, cdw
第三步:构建模型
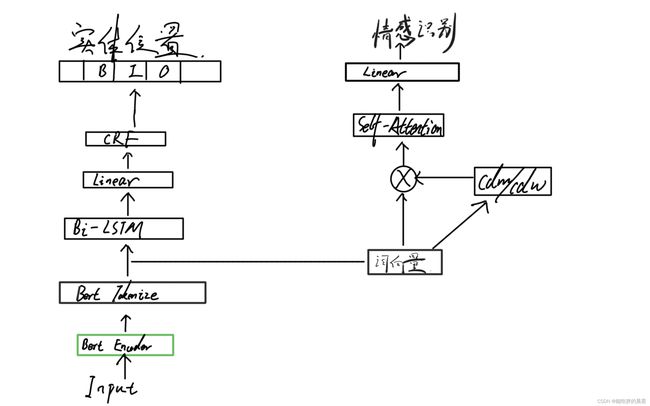
由于项目有两个任务,对实体的提取和对情感的提取,所以可以分两块来进行。在进行实体识别时,在原论文的基础上增加了CRF层,可以使实体识别更加准确在转为bert词向量后直接进入linear层得到实体的预测位置,再经过CRF层进行校正得到实体的预测输出。 在进行情感识别时,根据得到的词向量生成cdm和cdw,将词向量、cdw、cdm在特征维度进行拼接,经过自注意力层最后输入到线性层中进行预测输出。
config = BertConfig.from_pretrained(BERT_MODEL_NAME)
class Model(nn.Module):
def __init__(self):
super().__init__()
self.bert = BertModel.from_pretrained(BERT_MODEL_NAME)
# 冻结Bert参数
for name, param in self.bert.named_parameters():
param.requires_grad = False
self.lstm = nn.LSTM(BERT_DIM, HIDDEN_SIZE, batch_first=True, bidirectional=True)
self.ent_linear = nn.Linear(HIDDEN_SIZE * 2, ENT_SIZE)
self.crf = CRF(ENT_SIZE, batch_first=True)
self.pola_linear = nn.Linear(BERT_DIM * 3, BERT_DIM)
self.attention = BertAttention(config)
self.pooler = BertPooler(config)
self.dropout = nn.Dropout()
def get_text_encoded(self, input_ids, mask):
return self.bert(input_ids, attention_mask=mask)[0]
def get_entity_fc(self, text_encoded):
return self.ent_linear(text_encoded)
def get_entity_crf(self, entity_fc, mask):
return self.crf.decode(entity_fc, mask)
def get_entity(self, input_ids, mask):
text_encoded = self.get_text_encoded(input_ids, mask)
lstm_out = self.lstm(text_encoded)
entity_fc = self.get_entity_fc(lstm_out )
pred_ent_label = self.get_entity_crf(entity_fc, mask)
return pred_ent_label
def get_pola(self, input_ids, mask, ent_cdm, ent_cdw):
text_encoded = self.get_text_encoded(input_ids, mask)
# shape [b, c] -> [b, c, 768]
ent_cdm_weight = ent_cdm.unsqueeze(-1).repeat(1, 1, BERT_DIM)
ent_cdw_weight = ent_cdw.unsqueeze(-1).repeat(1, 1, BERT_DIM)
cdm_feature = torch.mul(text_encoded, ent_cdm_weight)
cdw_feature = torch.mul(text_encoded, ent_cdw_weight)
out = torch.cat([text_encoded, cdm_feature, cdw_feature], dim=-1)
out = self.pola_linear(out)
# self-attension 结合上下文信息,增强语义
out = self.attention(out, None)
# pooler 取[CLS]标记位作为整个句子的特征
out = torch.sigmoid(self.pooler(torch.tanh(out[0])))
return self.pola_linear(out)
def ent_loss_fn(self, input_ids, ent_label, mask):
text_encoded = self.get_text_encoded(input_ids, mask)
entity_fc = self.get_entity_fc(text_encoded)
return -self.crf.forward(entity_fc, ent_label, mask, reduction='mean')
def pola_loss_fn(self, pred_pola, pola_label):
return F.cross_entropy(pred_pola, pola_label)
def loss_fn(self, input_ids, ent_label, mask, pred_pola, pola_label):
return self.ent_loss_fn(input_ids, ent_label, mask) + self.pola_loss_fn(pred_pola, pola_label)
第四步:训练模型
定义好model和dataste之后,就可以在kaggle云服务器上进行网络模型的训练了,一批取两条数据进行模型训练。预测实体标签和情感标签来得到总损失,进行梯度更新。每100次计算下模型的准确率(实体位置和情感标签都预测正确才算对),每五次计算准确率之后保存一次模型。
model = Model().to(DEVICE)
optimizer = torch.optim.Adam(model.parameters(), lr=LR)
dataset = Dataset()
loader = data.DataLoader(dataset, batch_size=2, shuffle=False, collate_fn=dataset.collate_fn)
for e in range(EPOCH):
for b, batch in enumerate(loader):
input_ids, mask, ent_label, ent_cdm, ent_cdw, pola_label, pairs = batch
input_ids = input_ids.to(DEVICE)
mask = mask.to(DEVICE)
ent_label = ent_label.to(DEVICE)
ent_cdm = ent_cdm.to(DEVICE)
ent_cdw = ent_cdw.to(DEVICE)
pola_label = pola_label.to(DEVICE)
# 实体部分
pred_ent_label = model.get_entity(input_ids, mask)
# 情感部分
pred_pola = model.get_pola(input_ids, mask, ent_cdm, ent_cdw)
# 损失计算
loss = model.loss_fn(input_ids, ent_label, mask, pred_pola, pola_label)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if b % 10 == 0:
print('>> epoch', e, 'batch:', b, 'loss:', loss.item())
if b % 100 != 0:
continue
# 计算准确率
correct_cnt = pred_cnt = gold_cnt = 0
for i in range(len(input_ids)):
# 累加真实值数量
gold_cnt += len(pairs[i])
# 根据预测的实体label,解析出实体位置,并预测情感分类
b_ent_pos, b_ent_pola = get_pola(model, input_ids[i], mask[i], pred_ent_label[i])
if not b_ent_pos:
continue
# 解析实体和情感,并和真实值对比
pred_pair = []
cnt = 0
for ent, pola in zip(b_ent_pos, torch.argmax(b_ent_pola, dim=1)):
pair_item = (ent, pola.item())
pred_pair.append(pair_item)
# 判断正确,正确数量加1
if pair_item in pairs[i]:
cnt += 1
# 累加数值
correct_cnt += cnt
pred_cnt += len(pred_pair)
# 指标计算
precision = round(correct_cnt / (pred_cnt + EPS), 3)
recall = round(correct_cnt / (gold_cnt + EPS), 3)
f1_score = round(2 / (1 / (precision + EPS) + 1 / (recall + EPS)), 3)
print('\tcorrect_cnt:', correct_cnt, 'pred_cnt:', pred_cnt, 'gold_cnt:', gold_cnt)
print('\tprecision:', precision, 'recall:', recall, 'f1_score:', f1_score)
if e % 5 == 0:
torch.save(model, MODEL_DIR + f'model_{e}.pth')
第五步:预测
将训练好的模型从kaggle下载到本地。读取模型,由于预测的文本是字符串的形式,故当我们转化为list时就自动完成了分词。再将分开的字用bert tokenizer转化为id值,将input_id和mask都进行升维操作来添加批量维度。再计算好实体位置之后,反向提取出文本中对应的信息。由于bert转为词向量之后添加了开头的(cls)和句尾的(sep),所以要减一来得到对应文本中的位置。最终返回三个值:实体的文本、实体的情感标签、实体的位置。
model = torch.load(MODEL_DIR+'model_9.pth', map_location=DEVICE)
with torch.no_grad():
text =TEXT
tokenizer = BertTokenizer.from_pretrained(BERT_MODEL_NAME)
tokens = list(text)
input_ids = tokenizer.encode(tokens)
mask = [1] * len(input_ids)
# 实体部分
input_ids = torch.tensor(input_ids).unsqueeze(0)
mask = torch.tensor(mask).unsqueeze(0).bool()
pred_ent_label = model.get_entity(input_ids, mask)
# 情感分类
b_ent_pos, b_ent_pola = get_pola(model, input_ids[0], mask[0], pred_ent_label[0])
if not b_ent_pos:
print('\t', 'no result.')
else:
pred_pair = []
for ent_pos, pola in zip(b_ent_pos, torch.argmax(b_ent_pola, dim=1)):
aspect = text[ent_pos[0] - 1:ent_pos[-1]]
pred_pair.append({'aspect': aspect, 'sentiment': POLA_MAP[pola], 'position': ent_pos})
print('\t', text)
print('\t', pred_pair)