【论文阅读】DMLNet:深度度量学习开放世界语义分割
title: DMLNet
date: 2022-05-03 20:07
Tag:
- 深度学习
- 异常分割
- 度量学习
开放世界语义分割
- 开集语义分割模块
- 闭集语义分割子模块
- 异常分割子模块
- 增量小样本学习模块
我是短小精悍的文章摘要(๑•̀ㅂ•́) ✧
CODE
multiscale 是自己设定的吗 cfg.DATASET.imgSizes = (300, 375, 450, 525, 600)
Seg 转化为long Tensor的目的是什么
colors的作用是什么
几个辅助函数的作用:
Normalization(x): x − m i n ( x ) m a x ( x ) − m i n ( x ) \dfrac{x - min(x)}{max(x) - min(x)} max(x)−min(x)x−min(x)
Coefficient_map(x, thre): 1 1 + e x p ( 50 ∗ ( x − t h r e ) ) \dfrac{1}{1 + exp(50*(x - thre))} 1+exp(50∗(x−thre))1
normfun(x, mu, sigma): e x p ( − ( x − m u ) 2 2 ∗ σ 2 ) σ ∗ 2 ∗ π \dfrac{exp(-\frac{(x - mu)^2}{2 * \sigma^2})}{\sigma * \sqrt{2*\pi}} σ∗2∗πexp(−2∗σ2(x−mu)2)
论文阅读
引言
Classical close-set semantic segmentation networks have limited ability to detect out-of-distribution (OOD) objects, which is important for safety-critical applications such as autonomous driving. Incrementally learning these OOD objects with few annotations is an ideal way to enlarge the knowledge base of the deep learning models. In this paper, we propose an open world semantic segmenta- tion system that includes two modules:
(1) an open-set semantic segmentation module to detect both in-distribution and OOD objects.
(2) an incremental few-shot learning module to gradually incorporate those OOD objects into its existing knowledge base.
This open world semantic segmentation system behaves like a human being, which is able to identify OOD objects and gradually learn them with corresponding supervision.
We adopt the Deep Metric Learning Network (DMLNet) with contrastive clustering to implement open-set semantic segmentation. Compared to other open-set semantic segmentation methods, our DMLNet achieves state-of-the-art performance on three challenging open-set semantic segmentation datasets without using additional data or generative models.
On this basis, two incremental few-shot learning methods are fur- ther proposed to progressively improve the DMLNet with the annotations of OOD objects
经典的闭集语义分割网络检测分布外 (OOD) 对象的能力有限,这对于自动驾驶等安全关键型应用很重要。 增量学习这些带有少量注释的 OOD 对象是扩大深度学习模型知识库的理想方法。 在本文中,我们提出了一个开放世界语义分割系统,包括两个模块:
(1) 一个开放集语义分割模块,用于检测内分布和OOD对象。
(2) 一个增量的小样本学习模块,逐渐将这些 OOD 对象纳入其现有的知识库。
这个开放世界的语义分割系统就像一个人,能够识别OOD对象并在相应的监督下逐渐学习它们。
我们采用具有==对比聚类的深度度量学习网络(DMLNet)==来实现开放集语义分割。 与其他开放集语义分割方法相比,我们的 DMLNet 在三个具有挑战性的开放集语义分割数据集上实现了最先进的性能,而无需使用额外的数据或生成模型。
在此基础上,进一步提出了两种增量少样本学习方法,通过 OOD 对象的注释逐步改进 DMLNet
6. Conclusion
We introduce an open world semantic segmentation system which incorporates two modules:
- an open-set segmentation module
- an incremental few-shot learning module.
Our proposed open-set segmentation module is based on the deep metric learning network, and it uses the Euclidean distance sum criterion to achieve state-of-the-art performance.
Two incremental few-shot learning methods are proposed to broaden the perception knowledge of the network. Both modules of the open world semantic segmentation system can be further studied to improve the performance. We hope our work can draw more researchers to contribute to this practically valuable research direction.
我们介绍了一个开放世界语义分割系统,它包含两个模块:一个开放集分割模块和一个增量小样本学习模块。
我们提出的开放集分割模块基于深度度量学习网络,它使用欧几里德距离和标准来实现最先进的性能。
提出了两种增量少样本学习方法来拓宽网络的感知知识。 开放世界语义分割系统的两个模块都可以进一步研究以提高性能。 我们希望我们的工作能够吸引更多的研究人员为这个具有实际价值的研究方向做出贡献
1. 介绍
得益于高质量的数据集 [3,4,5],深度卷积网络在语义分割任务 [1, 2] 中取得了巨大成功。 这些语义分割网络在许多应用中被用作感知系统,如自动驾驶[6]、医疗诊断[7]等。然而,这些感知系统中的大多数都是闭集和静态的。 闭集语义分割假设测试中的所有类都已经在训练期间参与,这在开放世界中是不正确的。 如果闭集系统错误地将分发中标签分配给 OOD 对象 [8],它可能会在安全关键型应用程序(如自动驾驶)中造成灾难性后果。 同时,静态感知系统无法根据所见内容更新其知识库,因此,它仅限于特定场景,需要在一定时间后重新训练。 为了解决这些问题,我们提出了一种开放集的动态感知系统,称为开放世界语义分割系统。 它包含两个模块:
(1)一个开放集语义分割模块,用于检测OOD对象并将正确的标签分配给分布中的对象。
(2) 一个增量的小样本学习模块,将这些未知对象逐步合并到其现有的知识库中。
我们提出的开放世界语义分割系统的整个流程如图 1 所示
开放集语义分割和增量小样本学习都没有得到很好的解决。
对于开集语义分割,最重要的部分是在一张图像的所有像素中识别OOD像素,称为异常分割。 异常分割的典型方法是将图像级的开集分类方法应用于像素级的开集分类。
这些方法包括基于不确定性估计的方法 [9, 10, 11, 12] 和基于自动编码器的方法 [13, 14]。 然而,这两种方法已被证明在驾驶场景中无效,因为基于不确定性估计的方法会给出许多假阳性异常值检测 [15] 并且自动编码器无法重新生成复杂的城市场景 [16]。 最近,基于生成对抗网络(基于 GAN)的方法 [16, 17] 已被证明是有效的,但它们远非轻量级,因为它们需要在管道中使用多个深度网络。
对于增量少样本学习,我们不仅要处理增量学习的挑战,例如灾难性遗忘[18],还要处理少样本学习的挑战,包括从少量样本中提取代表性特征[19]
在本文中,我们建议使用 DMLNet 来解决开放世界语义分割问题。 原因有三:
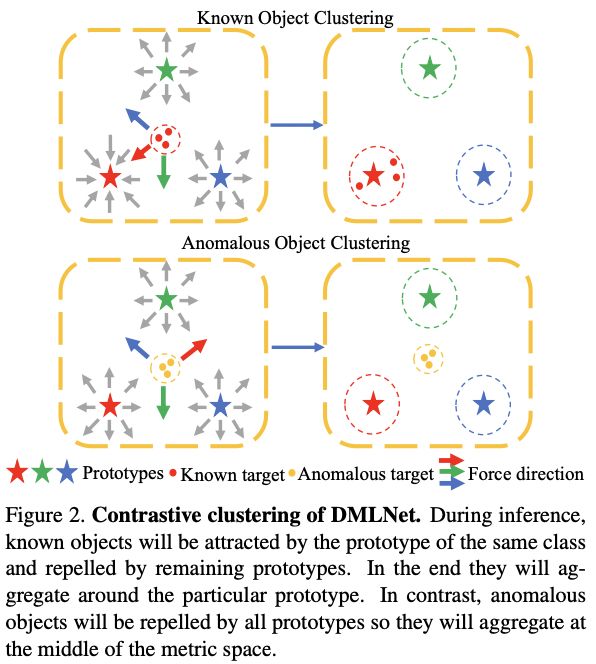
(1) DMLNet的分类原理是基于对比聚类,可以有效识别异常物体,如图2所示
度量学习:从数据中学习一种度量数据对象间距离的方法。其目标是使得在学得的距离度量下,相似对象间的距离小,不相似对象间的距离大。
传统的度量学习方法只能学习出线性特征,虽然有一些能够提取非线性特征的核方法被提出,但对学习效果也没有明显提升
深度度量学习:深度学习的激活函数学习非线性特征的优秀能力,深度学习方法能够自动地从原始数据中学出高质量的特征。因此深度学习的网络结构与传统的度量学习方法相结合能够带来理想的效果。
(2) DMLNet结合原型非常适合few-shot 任务[19]。
(3) DMLNet 的增量学习可以通过添加新的原型来实现,这是一种自然而有用的方法 [20]。
基于 DMLNet 架构,我们为开放集语义分割模块开发了两种未知识别标准,为增量少样本学习模块开发了两种方法。
根据我们的实验,这两个模块都被验证为有效且轻量级的。 总而言之,我们的贡献如下:
- 我们率先推出开放世界语义分割系统,在实际应用中更加稳健实用。
- 我们提出的基于 DMLNet 的开放集语义分割模块在三个具有挑战性的数据集上实现了最先进的性能。
- 我们提出的few-shot 增量学习模块方法在很大程度上缓解了灾难性遗忘问题。
- 通过结合我们提出的开放集语义分割模块和增量少样本学习模块,实现了一个开放世界语义分割系统。
2. Related Work
2.1 异常语义分割
异常语义分割的方法可以分为两种趋势: 基于不确定性估计的方法和基于生成模型的方法。
不确定性估计的基线是最大softmax概率(MSP),它首先在[9]中提出。 Dan 等人没有使用 softmax 概率。 [11]提出使用最大logit(MaxLogit)并取得更好的异常分割性能。 贝叶斯网络采用深度学习网络的概率观点,所以它们的权重和输出是概率分布而不是特定的数字 [21, 22]。 在实践中,Dropout [10] 或集成 [12] 通常用于近似贝叶斯推理。
自动编码器(AE)[23, 13] 和 RBM [14] 是典型的生成方法,假设 OOD 图像的重建误差大于分布内图像
最近,另一种基于 GAN 再合成的生成模型被证明可以基于其可靠的高分辨率像素到像素转换结果实现最先进的性能。 SynthCP [17] 和 DUIR [16] 是基于 GAN 再合成的两种方法。 不幸的是,它们离轻量级还很远,因为必须依次使用两个或三个神经网络来进行 OOD 检测。
与它们相比,我们证明了基于对比聚类的 DMLNet 具有更好的异常分割性能,而只需要推理一次
2.2 深度度量学习网络
DMLNets 已用于多种应用,包括视频理解 [24] 和人员重新识别 [25]。 DMLNet 使用欧几里得、马氏距离或 Matusita 距离 [26] 将此类问题转换为计算度量空间中的嵌入特征相似度。
卷积原型网络和 DMLNets 通常一起用于解决特定问题,例如检测图像级 OOD 样本 [27、28、29] 和用于语义分割的小样本学习 [19、30、31]。 我们也按照这种组合构建了第一个用于开放世界语义分割的 DMLNet
2.3 开放世界分类和检测
开放世界分类首先由 [32] 提出。这项工作提出了最近非异常值 (NNO) 算法,该算法在增量添加对象类别、检测异常值和管理开放空间风险方面非常有效。
最近约瑟夫等人。 [33]提出了一种基于对比聚类、未知感知提议网络和基于能量的未知识别标准的开放世界对象检测系统。 我们的开放世界语义分割系统的管道与他们的相似,除了两个重要的区别使我们的任务更具挑战性:(1)在他们的开放集检测模块中,他们依赖于区域提议网络(RPN)是 类不可知,因此也可以检测到未标记的潜在 OOD 对象。 这样,OOD样本的信息对于训练是有效的。 但是,我们专注于语义分割,其中训练中使用的每个像素都被分配了一个分布内标签,因此不能将 OOD 样本添加到训练中。 (2) 在增量学习模块中,他们使用新类的所有标记数据,而我们专注于自然更困难的少样本条件。 很少有研究集中在增量小样本学习上,其中包括用于分类的增量小样本学习[34]、对象检测[35]和语义分割[36]
3. 开放世界语义分割
在本节中,我们给出了开放世界语义分割系统的工作流程。 该系统由一个开放集语义分割模块和一个增量小样本学习模块组成。 假设 C i n = { C i n , 1 , C i n , 2 , . . . , C i n , N } \mathcal{C}_{in} = \{\mathcal{C}_{in,1}, \mathcal{C}_{in,2},...,\mathcal{C}_{in,N} \} Cin={Cin,1,Cin,2,...,Cin,N} 是 N 个分布内的类,它们都在训练数据集中进行了注释,并且 C o u t = { C o u t , 1 , C o u t , 2 , . . . , C o u t , M } \mathcal{C}_{out} = \{\mathcal{C}_{out,1},\mathcal{C}_{out,2},...,\mathcal{C}_{out,M} \} Cout={Cout,1,Cout,2,...,Cout,M} 是训练数据集中没有遇到的 M 个 OOD 类
开集语义分割模块又分为两个子模块:闭集语义分割子模块和异常分割子模块。
- Y ^ c l o s e \hat{Y}^{close} Y^close 是闭集语义分割子模块的输出图,所以每个像素的类别 Y ^ i , j c l o s e ∈ C i n \hat{Y}^{close}_{i,j} ∈ C_{in} Y^i,jclose∈Cin。
- 异常分割子模块的功能是识别OOD像素,其输出称为异常概率图: P ^ ∈ [ 1 , 0 ] H × W \hat{P} \in [1,0]^{H \times W} P^∈[1,0]H×W,其中 H H H 和 W W W 表示输入图像的高度和宽度。
基于 Y ^ c l o s e \hat{Y}_{close} Y^close 和 P ^ \hat{P} P^,开集语义分割图 Y ^ o p e n \hat{Y}^{open} Y^open 给出为:
Y ^ i , j o p e n = { C a n o m a l y P ^ i , j > λ o u t Y ^ i , j c l o s e P ^ i , j ≤ λ o u t (1) \hat{Y}^{open}_{i,j} = \begin{cases} \mathcal{C}_{anomaly} \quad \ \hat{P}_{i,j} > \lambda_{out} \\ \hat{Y}_{i,j}^{close} \quad \quad \hat{P}_{i,j} \le \lambda_{out} \end{cases} \tag{1} Y^i,jopen={Canomaly P^i,j>λoutY^i,jcloseP^i,j≤λout(1)
C a n o m a l y \mathcal{C}_{anomaly} Canomaly :表示 OOD 类别
λ o u t λ_{out} λout :确定 OOD 像素的阈值。
因此,openset语义分割模块应该识别OOD像素并分配正确的分布标签。然后 Yopen 可以转发给可以从 C o u t C_{out} Cout 中识别 C a n o m a l y C_{anomaly} Canomaly 并给出新类的相应注释的标注者 增量少样本学习模块用于在有新标签时将近集分割子模块的知识库从 C i n C_{in} Cin 一个一个更新为 C i n + M C_{in+M} Cin+M,其中 C i n + t = C i n ∪ { C o u t , 1 , C o u t , 2 , . . . , C o u t , t } , t ∈ 1 , 2 , . . . , M C_{in+t} = Cin \cup \{C_{out,1},C_{out,2},...,C_{out,t}\},t ∈{1,2,...,M} Cin+t=Cin∪{Cout,1,Cout,2,...,Cout,t},t∈1,2,...,M。 图 1 显示了开放世界语义分割系统的循环工作流水线
图 1. 开放世界语义分割系统。 第 1 步:识别已知和未知对象(蓝色箭头)。 第 2 步:注释未知对象(红色箭头)。 第 3 步:应用增量少样本学习来增加网络的分类范围(绿色箭头)。 第 4 步:在增量少样本学习之后,DMLNet 可以在更大的域中输出结果(紫色箭头)。

4. 方法
我们采用 DMLNet 作为我们的特征提取器,并在 4.1 节讨论架构和损失函数。 开放集分割模块和增量少样本学习模块在 4.2 和 4.3 节中进行了说明
4.1 深度度量学习网络
Classical CNN-based semantic segmentation networks can be disentangled into two parts:
- a feature extractor f ( X ; θ f ) f(X;θ_f) f(X;θf) for obtaining the embedding vector of each pixel
- a classifier g ( f ( X ; θ f ) ; θ g ) g(f(X;θ_f);θ_g) g(f(X;θf);θg) for generating the decision boundary,
where X X X, θ f θ_f θf and θ g θ_g θg denote the input image, parameters of the feature extractor and classifier respectively.
This learnable classifier is not suitable for OOD detection because it assigns all feature space to known classes and leaves no space for OOD classes.
传统CNN-based语义分割网络:
- f ( X ; θ f ) f(X;\theta_f) f(X;θf) 特征提取器:获取每个像素的嵌入向量
- g ( f ( X ; θ f ) ; θ g ) g(f(X;\theta_f);\theta_g) g(f(X;θf);θg) 分类器:生成决策边界
这种可学习的分类器不适用于 OOD 检测,因为它将所有特征空间分配给已知类,并且没有为 OOD 类留下空间。
In contrast, the classifier is replaced by the Euclidean distance representation with all prototypes M i n = { m t ∈ R 1 × N ∣ t ∈ { 1 , 2 , . . . , N } } \mathcal{M}_{in} = \{ m_t \in \mathbb{R}^{1 \times N}|t \in \{1,2,...,N\} \} Min={mt∈R1×N∣t∈{1,2,...,N}} in DMLNet, where m t m_t mt refers to the prototype of class C i n , t \mathcal{C}_{in,t} Cin,t. The feature extractor f ( X ; θ f ) f(X;θ_f) f(X;θf) learns to map the input X X X to the feature vector which has the same length as the prototype in metric space. For the close-set segmentation task, the probability of one pixel X i , j X_{i,j} Xi,j belonging to the class C i n , t \mathcal{C}_{in,t} Cin,t is formulated as:
DMLNet 中, 所有原型的欧几里得距离表示代替了传统的可学习分类器
- m t m_t mt 指的是 C i n , t \mathcal{C}_{in,t} Cin,t 类的原型。
特征提取器 f ( X ; θ f ) f(X;θ_f) f(X;θf)学习将输入 X 映射到与度量空间中的原型长度相同的特征向量。
对于闭集分割任务,一个像素 X i , j X_{i,j} Xi,j 属于类 C i n , t \mathcal{C}_{in,t} Cin,t 的概率公式为:
p t ( X i , j ) = e x p ( − ∣ ∣ f ( X ; θ f ) i , j − m t ∣ ∣ 2 ) ∑ t ′ = 1 N e x p ( − ∣ ∣ f ( X ; θ f ) i , j − m t ′ ∣ ∣ 2 ) (2) p_t(X_{i,j}) = \frac{exp(-||f(X;\theta_f)_{i,j} - m_t||^2)}{\sum^N_{t'=1} exp(-||f(X;\theta_f)_{i,j} - m_{t'}||^2)} \tag{2} pt(Xi,j)=∑t′=1Nexp(−∣∣f(X;θf)i,j−mt′∣∣2)exp(−∣∣f(X;θf)i,j−mt∣∣2)(2)
基于这种基于欧几里德距离的概率,判别交叉熵 (DCE) 损失函数 L D C E ( X i , j , Y i , j ; θ f , M i n ) \mathcal{L}_{DCE}(X_{i,j},Y_{i,j};θ_f,M_{in}) LDCE(Xi,j,Yi,j;θf,Min) [27] 定义为:
L D C E = ∑ i , j − l o g ( e x p ( − ∣ ∣ f ( X ; θ f ) i , j − m Y i , j ∣ ∣ 2 ) ∑ k = 1 N e x p ( − ∣ ∣ f ( X ; θ f ) i , j − m k ∣ ∣ 2 ) (3) \mathcal{L}_{DCE} = \sum_{i,j} -log (\frac{exp(-||f(X;\theta_f)_{i,j} - m_{Y_{i,j}}||^2)}{\sum^N_{k=1} exp(-||f(X;\theta_f)_{i,j} - m_{k}||^2)} \tag{3} LDCE=i,j∑−log(∑k=1Nexp(−∣∣f(X;θf)i,j−mk∣∣2)exp(−∣∣f(X;θf)i,j−mYi,j∣∣2)(3)
Y Y Y:输入图像 X X X 的标签
L D C E \mathcal{L}_{DCE} LDCE 的分子和分母分别指图2中的吸引力和排斥力。
排斥力不需要除去本身所属的类,本身类的原型吗?
图 2. DMLNet 的对比聚类。 在推理过程中,已知对象将被同一类的原型所吸引,而被剩余的原型所排斥。 最后,它们将围绕特定的原型进行聚合。 相反,异常对象将被所有原型排斥,因此它们将聚集在度量空间的中间。
我们制定了另一个损失函数,称为方差损失 (VL) 函数 L V L ( X i , j , Y i , j ; θ f , M i n ) \mathcal{L}_{VL}(X_{i,j},Y_{i,j};θ_f,M_{in}) LVL(Xi,j,Yi,j;θf,Min),其定义为:
L V L = ∑ i , j ∣ ∣ f ( X ; θ f ) i , j − m Y i , j ∣ ∣ 2 (4) \mathcal{L}_{VL} = \sum_{i,j} ||f(X;\theta_f)_{i,j} - m_{Y_{i,j}}||^2 \tag{4} LVL=i,j∑∣∣f(X;θf)i,j−mYi,j∣∣2(4)
L V L \mathcal{L}_{VL} LVL 只有吸引力作用,没有排斥力作用。
使用 DCE 和 VL,混合损失定义为: L = L D C E + λ V L L V L \mathcal{L}= \mathcal{L}_{DCE} + λ_{VL}\mathcal{L}_{VL} L=LDCE+λVLLVL,其中 λ V L λ_{VL} λVL 是权重参数
4.2 开集语义分割模型
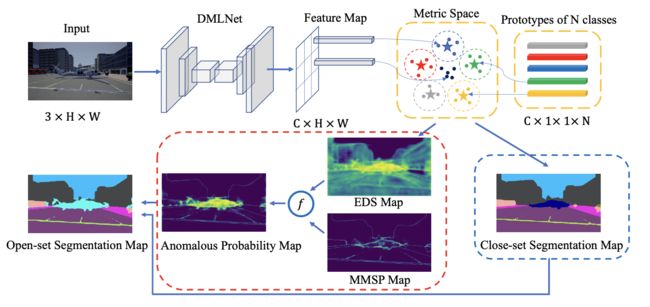
开集语义分割模块由闭集语义分割子模块和异常分割子模块组成。 开放集语义分割模块的流程如 图3 所示。
图3.闭集分割子模块包含在蓝色虚线框内,异常分割子模块包含在红色虚线框内。 开集分割图是这两个子模块生成的结果的组合。 在开放集分割图中预测分布内类和 OOD 类。 EDS map 和 MMSP map 的定义请参考 4.2 节。
-
闭集语义分割子模块为一幅图像的所有像素分配分布标签。 由于一个像素 X i , j X_{i,j} Xi,j 属于类 C i n , t \mathcal{C}_{in,t} Cin,t 的概率是用公式 2 表示,闭集分割图为:
Y ^ i , j c l o s e = a r g m a x t p t ( X i , j ) (5) \hat{Y}_{i,j}^{close} = argmax_t \ p_t(X_{i,j}) \tag{5} Y^i,jclose=argmaxt pt(Xi,j)(5) -
异常分割子模块检测OOD像素。 我们提出了两个未知的识别标准来测量异常概率,包括_基于度量的最大softmax概率(MMSP)和_欧几里得距离和(EDS)。
-
以下是基于 MMSP 的异常概率:
P ^ i , j M M S P = 1 − m a x p t ( X i , j ) , t ∈ { 1 , 2 , 3... , N } (6) \hat{P}^{MMSP}_{i,j} = 1 - max \ p_t(X_{i,j}),\ t \in \{ 1,2,3...,N \} \tag{6} P^i,jMMSP=1−max pt(Xi,j), t∈{1,2,3...,N}(6) -
EDS 是根据以下发现提出的:如果特征位于 OOD 像素聚集的度量空间的中心,则与所有原型的欧几里得距离和更小,即异常的欧几里得距离较小。 EDS 定义为:
S ( X i , j ) = ∑ t = 1 N ∣ ∣ f ( X ; θ f ) i , j − m t ∣ ∣ 2 (7) S(X_{i,j}) = \sum_{t=1}^N ||f(X;\theta_f)_{i,j} - m_t||^2 \tag{7} S(Xi,j)=t=1∑N∣∣f(X;θf)i,j−mt∣∣2(7)
基于 EDS 的异常概率计算如下:
P ^ i , j E D S = 1 − S ( X i , j ) m a x S ( X ) (8) \hat{P}^{EDS}_{i,j} = 1- \frac{S(X_{i,j})}{maxS(X)} \tag{8} P^i,jEDS=1−maxS(X)S(Xi,j)(8)
-
EDS 是类独立的,因此所有类的原型应该均匀分布在度量空间中,并且在训练期间不移动。 可学习的原型会在训练期间导致不稳定,并且对更好的性能没有贡献 [37]。 因此,我们以 one-hot 向量形式定义原型:只有 m t m_t mt 的第 t 个元素是 T T T,而其他元素保持为零,其中 t ∈ {1,2,…,N}
PAnS是什么情况?
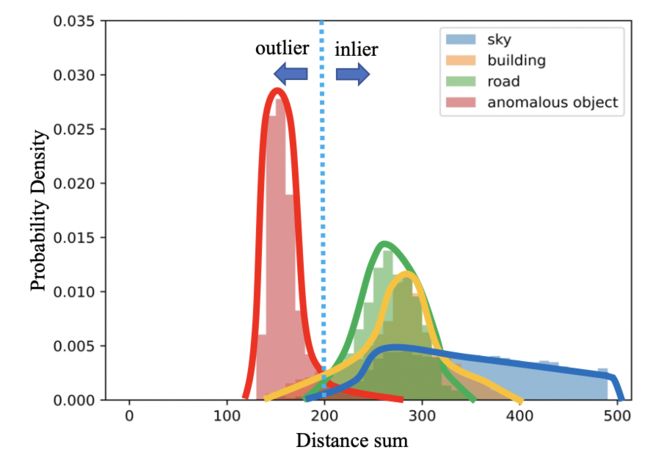
EDS 是相对于所有像素之间的最大距离和的比率,即使图像中没有 OOD 对象,高异常分数区域肯定存在于每幅图像中。 此外,每个分布内类别的距离总和分布彼此略有不同,如图4所示。
将MMSP与EDS相结合,以抑制那些实际上处于分布状态的具有中间响应的像素。
混合函数为:
P ^ = α P ^ E D S + ( 1 − α ) P ^ M M S P (9) \hat{P} = \alpha \hat{P}^{EDS} + (1-\alpha)\hat{P}^{MMSP} \tag{9} P^=αP^EDS+(1−α)P^MMSP(9)
-
α :
α = 1 1 + e x p ( − β ( P ^ E D S − γ ) ) (10) \alpha = \frac{1}{1 + exp(-\beta(\hat{P}^{EDS} - \gamma))} \tag{10} α=1+exp(−β(P^EDS−γ))1(10)- β 和 γ 是控制抑制效果和阈值的超参数。
通过方程 9 得到异常概率图和方程 5 得到闭集分割图后,我们应用方程 1 生成最终的开集分割图
5. 实验
Our experiments are divided into three parts.
- We first evaluate our open-set semantic segmentation approach in Section 5.1.
Then we demonstrate our incremental few-shot learning results in Section 5.2.Based on the open-set semantic segmentation module and incremental few-show learning module, the whole open world semantic segmentation is realized in Section 5.3.
5.1 开集语义分割
数据集。 三个数据集包括 StreetHazards [11]、Lost and Found [38] 和 Road Anomaly [16] 用于证明我们基于 DMLNet 的开放集语义分割方法的稳健性和有效性。
- StreetHazards 的大多数异常物体是大型稀有运输机器,例如直升机、飞机和拖拉机。
- Lost and Found 含许多小的异常物品,如货物、玩具和盒子。
- Road Anomaly 数据集不再限制城市场景中的场景,还包含村庄和山脉的图像。
指标。 开放集语义分割是封闭集分割和异常分割的组合,如 4.2 节所述。
- 对于闭集语义分割任务,我们使用 mIoU 来评估性能。
- 对于异常分割任务,根据 [11] 使用三个指标,包括 ROC 曲线下面积(AUROC)、95% 召回的误报率(FPR95)和精确召回曲线下面积(AUPR)。
实施细节。
-
对于 StreetHazards,我们遵循与 [11] 相同的训练程序,在 StreetHazards 的训练集上训练 PSPNet [2]。
[11]: Scaling out-of-distribution detection for real-world settings.
-
对于Lost and Found和 Road Anomaly,我们按照 [16] 使用 BDD-100k [39] 来训练 PSPNet。 请注意,PSPNet 仅用于提取我们在 4.1 节中讨论的特征(获得每个像素的嵌入向量)。 混合损失的 λ V L λ_{VL} λVL 为 0.01。 所有原型中非零元素 T T T 为 3。等式 10 中的 β 和 γ 分别为 20 和 0.8。
[16]: Detecting the unexpected via image resynthesis
基线。
- StreetHazards: MSP [9]、Dropout [10]、AE [13]、MaxLogit [11] 和 SynthCP [17]。
- Lost and Found 和 Road Anomaly: MSP、MaxLogit、Ensemble [12]、RBM [14] 和 DUIR [16]。
结果。
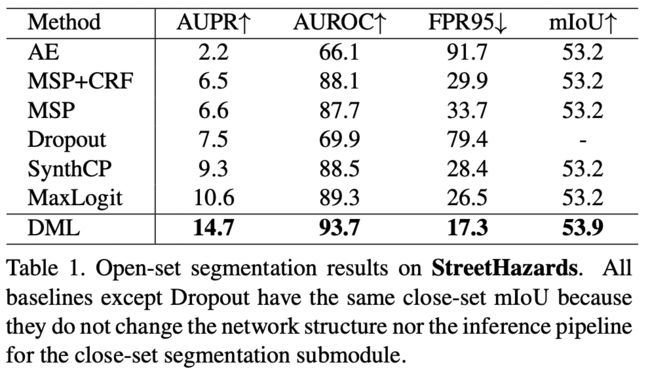
StreetHazards 的结果如表 1 所示。
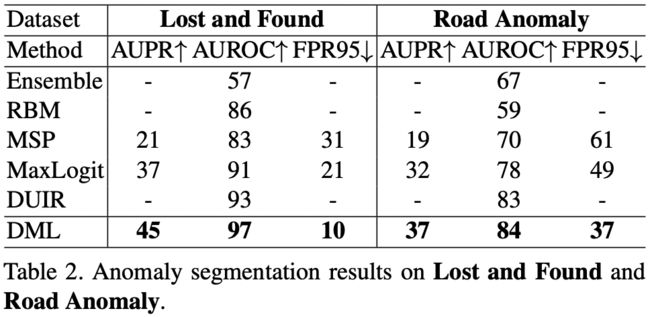
对于 Lost and Found 和 Road Anomaly,mIoU 是无效的,因为它们只提供 OOD 类标签,但没有特定的分布内类标签。 结果在表 2 中。
我们的实验表明:
- 基于 DMLNet 的方法在所有三个异常分割相关指标中都达到了最先进的性能。
- 与最近提出的基于 GAN 的方法(包括 DUIR 和 SynthCP)相比,我们的方法在异常分割质量方面优于它们,结构更轻量级,因为它们在整个流程中需要两个或三个深度神经网络,而我们只需要推理一次。
- StreetHazards 中闭集分割的 mIoU 值表明我们的方法对闭集分割没有危害。
一些定性结果如图 8 所示

消融研究。 我们仔细进行了消融实验,研究了不同损失函数(VL 和 DCE)和异常判断标准(EDS 和 MMSP)的影响,如表 3 所示。
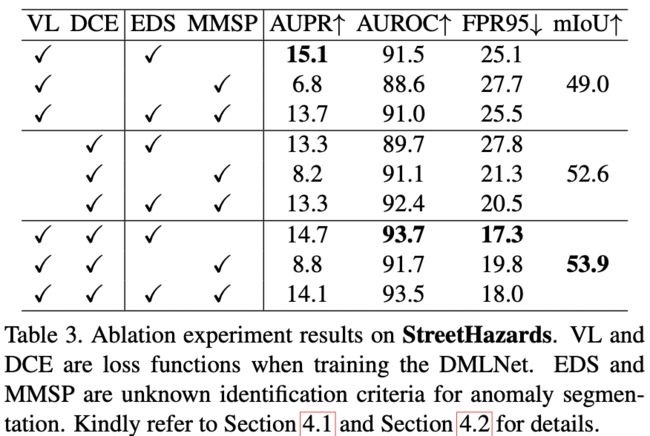
- DCE 在 mIoU 上的性能优于 VL 的事实表明了 排斥力。
- EDS 在所有损失下都优于 MMSP 函数,这意味着与类无关的标准更适合于异常分割任务