kaggle房价预测
目录
- 数据探索
-
- 初步探索数据及缺失值
- 探索标签分布
- 探索最正相关和最负相关的10个特征
- 探索特征异常值
- 去除异常值
- 绘制标签与各特征的关系
- 少量缺失值和分类变量处理
- 模型训练与预测
-
- 训练模型获得初始模型评估分数
- 网格搜索或学习曲线获得最优参数
- 模型融合
- 对各预测结果进行组合
- 预测最终房价
数据探索
初步探索数据及缺失值
import pandas as pd
import numpy as np
import matplotlib.pylab as plt
#加载数据
train=pd.read_csv(r'D:\机器学习\kaggle预测\房价预测\train.csv',index_col=0)#1460*80
test=pd.read_csv(r'D:\机器学习\kaggle预测\房价预测\test.csv',index_col=0)#1459*79
#数据探索
train.drop_duplicates(inplace=True)
train.info(),train.isnull().sum(),test.info()
train['LotFrontage'].value_counts()#LotFrontage房产到街道的直线距离
#填补缺失值占比高的特征
train['LotFrontage']=train['LotFrontage'].fillna(train['LotFrontage'].mode()[0])#Alley入口通道类型
test['LotFrontage']=test['LotFrontage'].fillna(train['LotFrontage'].mode()[0])#Alley是入口通道类型
train['Alley']=train['Alley'].fillna('unknow')#Alley入口通道类型
test['Alley']=test['Alley'].fillna('unknow')#Alley是入口通道类型
train['FireplaceQu'].value_counts()#FireplaceQu壁炉质量
train['FireplaceQu']=train['FireplaceQu'].fillna('unknow')#
test['FireplaceQu']=test['FireplaceQu'].fillna('unknow')
train['PoolQC'].value_counts()#PoolQC游泳池质量
train['PoolQC']=train['PoolQC'].fillna('unknow')
test['PoolQC']=test['PoolQC'].fillna('unknow')
train['Fence'].value_counts()#Fence栅栏质量
train['Fence']=train['Fence'].fillna('unknow')
test['Fence']=test['Fence'].fillna('unknow')
train['MiscFeature'].value_counts()#MiscFeature其他未包含的杂项类别
train['MiscFeature']=train['MiscFeature'].fillna('unknow')
test['MiscFeature']=test['MiscFeature'].fillna('unknow')
test.info()
Int64Index: 1460 entries, 1 to 1460
Data columns (total 80 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 MSSubClass 1460 non-null int64
1 MSZoning 1460 non-null object
2 LotFrontage 1201 non-null float64
3 LotArea 1460 non-null int64
4 Street 1460 non-null object
5 Alley 91 non-null object
......
探索标签分布
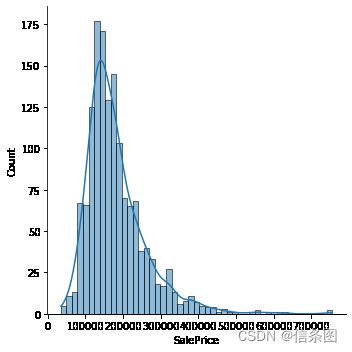
#绘制y的统计分布
import seaborn as sns
sns.displot(train['SalePrice'],kde=True)
plt.show()
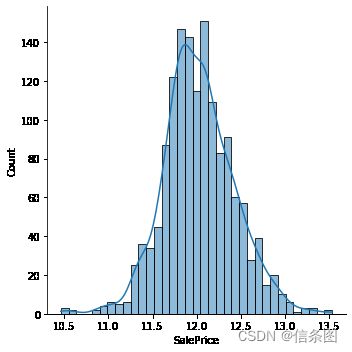
train['SalePrice']=np.log(train['SalePrice'])
sns.displot(train['SalePrice'],kde=True)
plt.show()
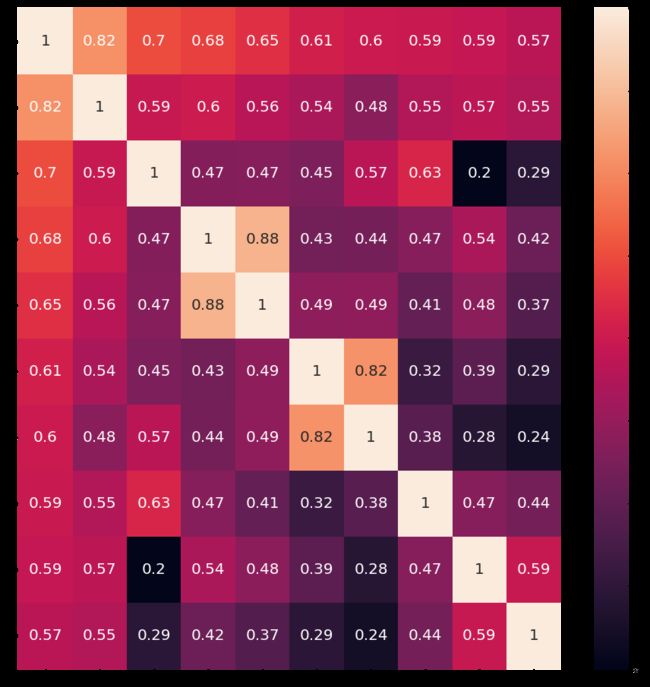
探索最正相关和最负相关的10个特征
#探索corr的前10个特征和后10个特征
import seaborn as sns
plt.figure(figsize=(16,16))
corrmat=train.corr()
corrmat.nlargest(10,'SalePrice')#输出前10个与'SalePrice
columns=corrmat.nlargest(10,'SalePrice')['SalePrice'].index#获得了10个相关关系高的索引
train_=train[columns]#直接用pandas得到新的特征
corr_=train_.corr()
sns.heatmap(corr_,cbar=True,annot=True,annot_kws={'size':20})#annot是否显示值
plt.show()
a=corrmat.nlargest(10,'SalePrice')['SalePrice'].index.tolist()
import seaborn as sns
plt.figure(figsize=(16,16))
corrmat=train.corr()
corrmat.nsmallest(10,'SalePrice')#输出后10个与'SalePrice
c=corrmat.nsmallest(10,'SalePrice')['SalePrice'].index#获得了10个相关关系低的索引
c=c.tolist()
c.append('SalePrice')
train_=train[c]#直接用pandas得到新的特征
corr_=train_.corr()
sns.heatmap(corr_,cbar=True,annot=True,annot_kws={'size':20})#annot是否显示值
plt.show()

探索特征异常值
#或得10个正相关,10个负相关特征描述性统计
a.extend(c)
b=[]
for i in a:
if train[i].dtypes!='object':
b.append(i)
train[b].describe([0.1,0.2,0.3,0.4,0.6,0.8,0.9,0.99]).T
#记录分类型变量特征
one_hot=['OverallQual','GarageCars','FullBath','KitchenAbvGr','MSSubClass','YrSold','OverallCond','BsmtHalfBath']
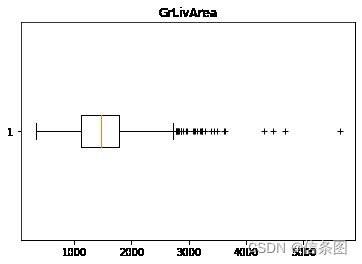
#探索相关特征的异常值
plt.boxplot(train['GrLivArea'],vert=False,sym='+')#利用统计值和业务参数iqr=q3-q1,q3+1.5iqr
plt.title('GrLivArea')
plt.show()
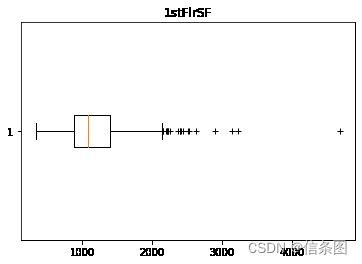
plt.boxplot(train['1stFlrSF'],vert=False,sym='+')
plt.title('1stFlrSF')
plt.show()
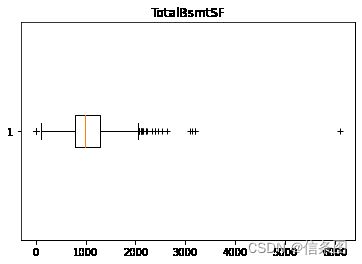
plt.boxplot(train['TotalBsmtSF'],vert=False,sym='+')
plt.title('TotalBsmtSF')
plt.show()
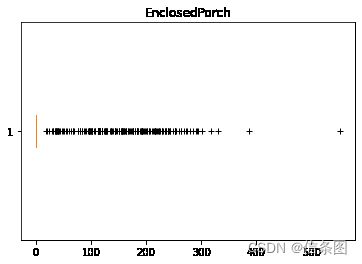
plt.boxplot(train['EnclosedPorch'],vert=False,sym='+')
plt.title('EnclosedPorch')
plt.show()
plt.boxplot(train['MiscVal'],vert=False,sym='+')
plt.title('MiscVal')
plt.show()

去除异常值
#剔除掉异常值
train=train[(train['GrLivArea']<4000)&(train['1stFlrSF']<3000)&(train['TotalBsmtSF']<3000)&(train['EnclosedPorch']<400)&(train['MiscVal']<6000)]
train=train.reset_index()
绘制标签与各特征的关系
#绘制y与各特征得关系
plt.figure(figsize=(4,3))
plt.grid()
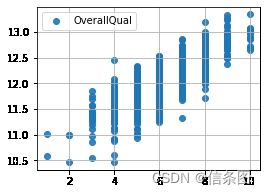
plt.scatter(train['OverallQual'],train['SalePrice'],alpha=0.9,label='OverallQual')
# plt.vlines(10,0,900000,linestyles='solid',zorder=2,colors='red')
plt.legend()
plt.show()#房价和GrLivArea是线性相关的
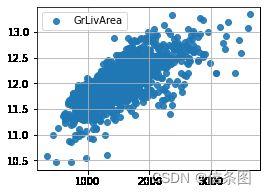
plt.figure(figsize=(4,3))
plt.grid()
plt.scatter(train['GrLivArea'],train['SalePrice'],alpha=0.9,label='GrLivArea')
# plt.vlines(4000,0,900000,linestyles='solid',zorder=2,colors='red')
plt.legend()
plt.show()#房价和GrLivArea是线性相关的
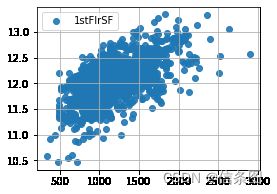
plt.figure(figsize=(4,3))
plt.grid()
plt.scatter(train['1stFlrSF'],train['SalePrice'],alpha=0.9,label='1stFlrSF')
# plt.vlines(3000,0,900000,linestyles='solid',zorder=2,colors='red')
plt.legend()
plt.show()#房价和1stFlrSF是线性相关的
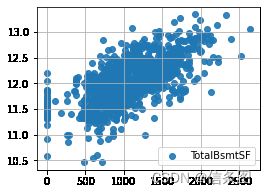
plt.figure(figsize=(4,3))
plt.grid()
plt.scatter(train['TotalBsmtSF'],train['SalePrice'],alpha=0.9,label='TotalBsmtSF')
# plt.vlines(3000,0,900000,linestyles='solid',zorder=2,colors='red')
plt.legend()
plt.show()#房价和TotalBsmtSF是线性相关的,'TotalBsmtSF'为0时,房价也很高,不是缺失值填值得因素
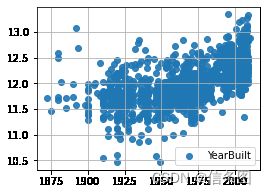
plt.figure(figsize=(4,3))
plt.grid()
plt.scatter(train['YearBuilt'],train['SalePrice'],alpha=0.9,label='YearBuilt')
#plt.vlines(3000,0,900000,linestyles='solid',zorder=2,colors='red')
plt.legend()
plt.show()#房价和TotalBsmtSF是线性相关的
少量缺失值和分类变量处理
#少量缺失值处理
def low(df):
a=df.columns
b=a[df.isnull().sum()>0]
#查看数据分布,并填充众数
for i in b:
#display(i,train[i].value_counts())
df[i]=df[i].fillna(df[i].mode()[0])
return df
#查看object特征,并对其进行编码
def lab(df):
a=[]
for i in df.columns:
if (df[i].dtypes=='object')or (i in one_hot):
df=pd.get_dummies(df,columns=[i])
return df
train1=train.dropna()
train1=low(train1)
test1=low(test)
#display(train.info(),test.info())
#将训练集的数据类型于测试集的类型统一
for i in test.columns:
if train[i].dtypes==test[i].dtypes:
continue
else:
test[i]=test[i].astype(train[i].dtypes,copy=False)
train1=lab(train1)
test1=lab(test1)
模型训练与预测
训练模型获得初始模型评估分数
#划分特征和标签
x=train1.loc[:,~train1.columns.isin(['SalePrice','Id'])]
y=train1.loc[:,'SalePrice']
xtest_x=test1.loc[:,test1.columns!='Id']
x,xtest_x=x.align(xtest_x,join='inner',axis=1)
from sklearn.model_selection import train_test_split
xtrain_,xtest_,ytrain_,ytest_=train_test_split(x,y,test_size=0.3,random_state=2)
from sklearn.svm import SVR
from sklearn.ensemble import RandomForestRegressor
from sklearn.linear_model import Lasso,Ridge
from xgboost import XGBRegressor
from sklearn.model_selection import cross_val_score,KFold
#选取回归模型,查看rmse
clfs={'svm':SVR()
,'RandomForestRegressor':RandomForestRegressor()
,'Lasso':Lasso()
,'Ridge':Ridge()
,'XGBRegressor':XGBRegressor()}
for clf in clfs:
try:
clfs[clf].fit(x,y)
score=np.sqrt(abs(cross_val_score(clfs[clf],x,y,scoring='neg_mean_squared_error',cv=10).mean()))
print(f'{clf}的score:{score}')
except:
pass
svm的score:0.1996936276759078
RandomForestRegressor的score:0.13624613654727127
Lasso的score:0.16515414043201035
Ridge的score:0.10995180787185048
XGBRegressor的score:0.13167717794877737
网格搜索或学习曲线获得最优参数
#利用网格搜索核学习曲线探索最优参数
SVR=SVR(kernel='rbf',gamma=0.012244897959183675)
rfr=RandomForestRegressor(n_estimators=89,max_features=27,random_state=0)
lasso=Lasso(alpha=0.0002,max_iter= 200)
Ridge=Ridge(alpha=4)
xgbr=XGBRegressor(objective='reg:squarederror'
,n_estimators=71
,max_depth=4
)
模型融合
#模型融合
class StackingRegressor():
def __init__(self,fir_models,fir_model_names,sec_model,cv):
#第一层的基模型
self.fir_models=fir_models
self.fir_model_names=fir_model_names
#第二层用来预测结果的模型
self.sec_model=sec_model
#交叉验证模式,必须为k
self.cv=cv
def fit_predict(self,x,y,test):#x,y,test必须为dataframe
#创建空dataframe
stacked_train=pd.DataFrame()
stacked_test=pd.DataFrame()
n_fold=0
#遍历每个模型,做交叉验证
for i ,model in enumerate(self.fir_models):
#初始化stacked_train
stacked_train[self.fir_model_names[i]]=np.zeros(shape=(x.shape[0],))
#遍历每一折交叉验证
for train_index,valid_index in self.cv.split(x):#输出10折交叉验证1196,113
#初始化stacked_test
n_fold+=1
#某列等于svr,1
stacked_test[self.fir_model_names[i]+str(n_fold)]=np.zeros(shape=(test.shape[0],))#新建一个
#print(stacked_test)
#划分数据集
X_train, y_train = x.iloc[train_index, :], y.iloc[train_index]#得到训练集
X_valid, y_valid = x.iloc[valid_index, :], y.iloc[valid_index]#得到测试集
# 训练模型并预测结果
model.fit(X_train, y_train)
stacked_train.loc[valid_index, self.fir_model_names[i]] = model.predict(X_valid)#对stacked_train新增模型的预测数据
print(model.predict(test))
print(stacked_test)
stacked_test.loc[:,self.fir_model_names[i]+str(n_fold)] = model.predict(test)#
print('{} is done.'.format(self.fir_model_names[i]))
# stacked_train加上真实值标签
y.reset_index(drop=True, inplace=True)
stacked_train['y_true'] = y
# 计算stacked_test中每个模型预测结果的平均值
for i, model_name in enumerate(self.fir_model_names):
stacked_test[model_name] = stacked_test.iloc[:, :10].mean(axis=1)
stacked_test.drop(stacked_test.iloc[:, :10], axis=1, inplace=True)
# 打印stacked_train和stacked_test
print('----stacked_train----\n', stacked_train)
print('----stacked_test----\n', stacked_test)
# 用sec_model预测结果
self.sec_model.fit(stacked_train.drop(columns='y_true'), stacked_train['y_true'])
y_pred = self.sec_model.predict(stacked_test)
return y_pred
models=[rfr,lasso,Ridge]
model_names=['rfr','la','ri']
kf = KFold(n_splits=10, random_state=50, shuffle=True)
sr =StackingRegressor(models, model_names, xgbr, kf)
stacking_pred = sr.fit_predict(xtrain_, ytrain_,xtest_)
from sklearn.metrics import mean_squared_error
def rmse(y, y_pred):
rmse = np.sqrt(abs(mean_squared_error(y, y_pred)))
return rmse
stacking_score = rmse(ytest_, stacking_pred)
print(stacking_score)
0.11275309999910874
对各预测结果进行组合
def blending(x,y,test):
rfr.fit(x,y)
rfr_pred = rfr.predict(test)
lasso.fit(x,y)
lasso_pred = lasso.predict(test)
Ridge.fit(x,y)
Ridge_pred = Ridge.predict(test)
stacking_pred = sr.fit_predict(x, y,test)
# 加权求和
blended_pred = (
0.15 * rfr_pred +
0.1* lasso_pred +
0.25* Ridge_pred +
0.5* stacking_pred)
return blended_pred
blended_pred=blending(xtrain_,ytrain_,xtest_)
blending_score = rmse(ytest_, blended_pred)
print(blending_score)
0.09957009274911828
预测最终房价
blended_pred=blending(x,y,xtest_x)
y_pred_b1=np.exp(blended_pred)
y_pred_b1=pd.DataFrame(y_pred_b1)
y_pred_b1.columns=['SalePrice']
y_pred_b1.index=xtest_x.index
y_pred_b1.to_csv(r'D:\机器学习\kaggle预测\房价预测\sample_submission7.csv')
最终kaggle模型评分是0.131517202428642