2--Kaggle: 房价预测
2.1 数据导入
首先在Kaggle网站进行注册(如不想参加比赛也许可以不用注册)
比赛地址:House Prices - Advanced Regression Techniques | Kaggle
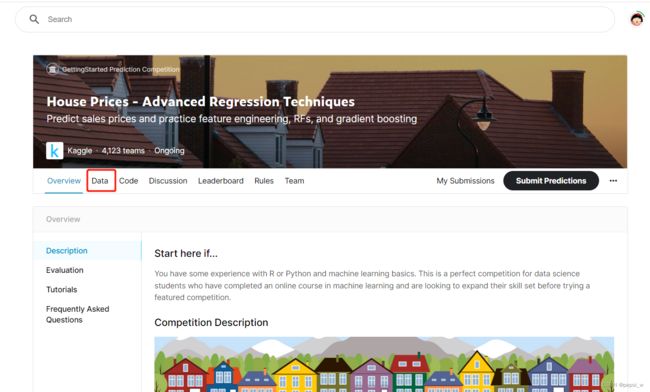
这里有两种方法将数据放在colab上使用,第二种是直接本地下载后上传到Goole硬盘后,移动到创建的colab会话中并进行解压缩。
第一种是在colab会话中使用 Kaggle API 下载数据集,并解压缩并存放到实例的磁盘上
点击头像页下的Account,https://www.kaggle.com/
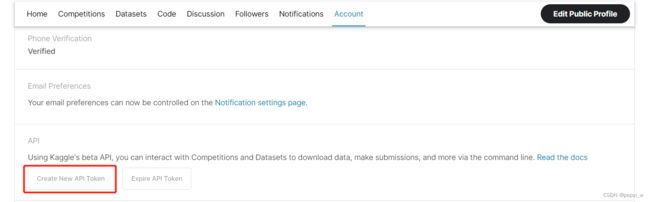
往下滑找到API,点击Create New API Token,生成一个json文件。
创建一个colab会话后,点击左侧的文件夹选项,然后将上一步下载的kaggle.json文件上传到该会话储存空间。
在colab中运行以下语句:
!pip install kaggle
! mkdir -p ~/.kaggle
! cp /content/kaggle.json ~/.kaggle/
! chmod 600 ~/.kaggle/kaggle.json
#这个命令在该网站获得:
#https://www.kaggle.com/competitions/house-prices-advanced-regression-techniques/data
!kaggle competitions download -c house-prices-advanced-regression-techniques在左边刷新一下就可以看见下载的数据压缩包 :
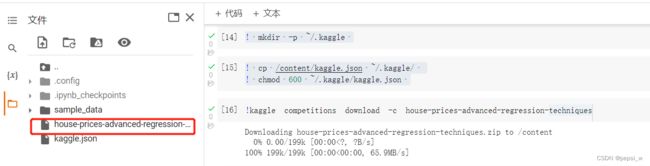
对该数据压缩包进行解压缩,解压缩的文件就会在该会话的存储空间中,就可以直接使用了:
! unzip -q /content/house-prices-advanced-regression-techniques.zip
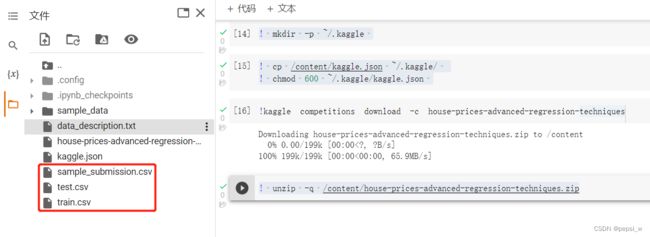
第二种是直接本地下载并解压后再放到goole云盘中,这样比较简单。下载路径:
House Prices - Advanced Regression Techniques | Kaggle

2.2 实现代码
!pip install pandas
!pip install git+https://github.com/d2l-ai/d2l-zh@release # installing d2l
!pip install matplotlib==3.0.0
%matplotlib inline
import numpy as np
import pandas as pd
import torch
from torch import nn
from d2l import torch as d2l
train_data = pd.read_csv('/content/drive/MyDrive/data/house-prices-advanced-regression-techniques/train.csv')
test_data = pd.read_csv('/content/drive/MyDrive/data/house-prices-advanced-regression-techniques/test.csv')
#print(train_data.shape)
#print(test_data.shape)
#print(train_data.iloc[0:4,[0,1,2,3,-3,-2,-1]])
#print(test_data.iloc[0:4,[0,1,2,3,-3,-2,-1]])
all_features = pd.concat((train_data.iloc[:,1:-1],test_data.iloc[:,1:]))
#print(all_features.shape)
# 若无法获得测试数据,则可根据训练数据计算均值和标准差
numeric_features = all_features.dtypes[all_features.dtypes != 'object'].index
all_features[numeric_features] = all_features[numeric_features].apply(
lambda x: (x-x.mean()) / (x.std()))
# 在标准化数据之后,所有均值消失,因此我们可以将缺失值设置为0
all_features[numeric_features] = all_features[numeric_features].fillna(0)
#处理离散值
#根据独热编码,如果“MSZoning”的原始值为“RL”, 则:“MSZoning_RL”为1,“MSZoning_RM”为0
# “Dummy_na=True”将“na”(缺失值)视为有效的特征值,并为其创建指示符特征
all_features = pd.get_dummies(all_features,dummy_na=True)
all_features.shape#这里的列数变多了 因为离散值的每一列都会变成很多列 每个数值为true的情况
#print(all_features.iloc[0:4,[-4,-3,-2,-1]])
n_train = train_data.shape[0]#得到训练数据的个数
train_features = torch.tensor(all_features[:n_train].values,dtype=torch.float32)
test_features = torch.tensor(all_features[n_train:].values,dtype=torch.float32)
train_labels = torch.tensor(train_data.SalePrice.values.reshape(-1,1),dtype=torch.float32)
loss = nn.MSELoss()
in_features = train_features.shape[1]#特征的个数
def get_net():
#net = nn.Sequential(nn.Linear(in_features,1)) 线性结构
net = nn.Sequential(nn.Linear(in_features,128),nn.ReLU(),nn.Linear(128, 1))# 两层MLP
return net
def log_rmse(net,features,labels):
# 为了在取对数时进一步稳定该值,将小于1的值设置为1
clipped_preds = torch.clamp(net(features),1,float('inf'))
rmse = torch.sqrt(loss(torch.log(clipped_preds),torch.log(labels)))
return rmse.item()
def train(net,train_features,train_labels,test_features,test_labels,num_epochs,lr,weight_decay,batch_size):
train_ls,test_ls = [],[]
train_iter = d2l.load_array((train_features,train_labels),batch_size)
# 这里使用的是Adam优化算法
optimizer = torch.optim.Adam(net.parameters(),lr=lr,weight_decay=weight_decay)
for epoch in range(num_epochs):
for X, y in train_iter:
optimizer.zero_grad()
l = loss(net(X),y)
l.backward()
optimizer.step()
train_ls.append(log_rmse(net,train_features,train_labels))
if test_labels is not None:
test_ls.append(log_rmse(net,test_features,test_labels))
return train_ls, test_ls
def get_k_fold_data(k, i, X, y):
assert k > 1
fold_size = X.shape[0] // k
X_train, y_train = None, None
for j in range(k):
idx = slice(j * fold_size, (j + 1) * fold_size)
X_part, y_part = X[idx, :], y[idx]
if j == i:
X_valid, y_valid = X_part, y_part
elif X_train is None:
X_train, y_train = X_part, y_part
else:
X_train = torch.cat([X_train, X_part], 0)
y_train = torch.cat([y_train, y_part], 0)
return X_train, y_train, X_valid, y_valid
def k_fold(k, X_train, y_train, num_epochs, learning_rate, weight_decay,
batch_size):
train_l_sum, valid_l_sum = 0, 0
for i in range(k):
data = get_k_fold_data(k, i, X_train, y_train)
net = get_net()
train_ls, valid_ls = train(net, *data, num_epochs, learning_rate,
weight_decay, batch_size)
train_l_sum += train_ls[-1]
valid_l_sum += valid_ls[-1]
if i == 0:
d2l.plot(list(range(1, num_epochs + 1)), [train_ls, valid_ls],
xlabel='epoch', ylabel='rmse', xlim=[1, num_epochs],
legend=['train', 'valid'], yscale='log')
print(f'折{i + 1},训练log rmse{float(train_ls[-1]):f}, '
f'验证log rmse{float(valid_ls[-1]):f}')
return train_l_sum / k, valid_l_sum / k
k,num_epochs,lr,weight_decay,batch_size = 4,300,4,0,40
train_l, valid_l = k_fold(k, train_features,train_labels,num_epochs,lr,weight_decay,batch_size)
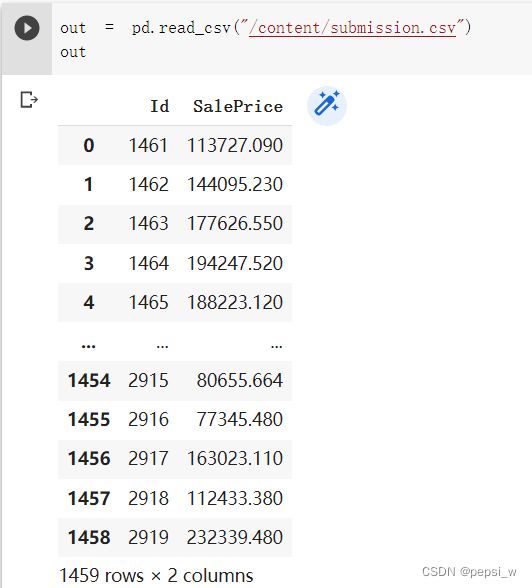
print(f'{k}-折: 平均训练log rmse: {float(train_l):f}, 'f'平均验证log rmse: {float(valid_l):f}')运行结果:
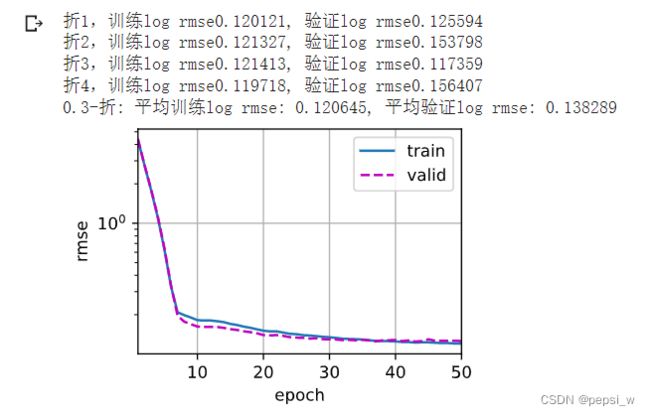
2.3 提交预测
def train_and_pred(train_features, test_features, train_labels, test_data,num_epochs, lr, weight_decay, batch_size):
net = get_net()
train_ls, _ = train(net, train_features, train_labels, None, None,
num_epochs, lr, weight_decay, batch_size)
d2l.plot(np.arange(1, num_epochs + 1), [train_ls], xlabel='epoch',
ylabel='log rmse', xlim=[1, num_epochs], yscale='log')
print(f'训练log rmse:{float(train_ls[-1]):f}')
# 将网络应用于测试集。
preds = net(test_features).detach().numpy()
# 将其重新格式化以导出到Kaggle
test_data['SalePrice'] = pd.Series(preds.reshape(1, -1)[0])
submission = pd.concat([test_data['Id'], test_data['SalePrice']], axis=1)
submission.to_csv('submission.csv', index=False)
k,num_epochs,lr,weight_decay,batch_size = 4,300,4,0,40
train_and_pred(train_features, test_features, train_labels, test_data,
num_epochs, lr, weight_decay, batch_size)运行结果: