【内联函数详解】
本文主要介绍了C++中内联函数的使用,本质上是一种以空间换时间的提高代码效率的方法,相对于C语言中宏的缺陷进行了相应的改进。本文对内联的详细实现和底层的汇编指令进行了分析,总结了内联的几种使用方法,并提供了详细的代码示例,这也是我初学C++ primer plus的学习笔记,如有错误,欢迎在评论区批评指正。
文章目录
- 内联函数
-
- 内联函数的引出
- 什么时候选择使用内联函数?
- 什么时候不使用inline
- 如何使用inline? (具体语法) 使用inline的注意事项!
- 内联函数在类定义中的应用
- 内联与宏的缺陷
参考文献:
C++ primer plus
内敛与宏的缺陷
浙大翁恺内联函数
内联函数
内联函数的引出
常规函数调用
int f(int i){
return i*2;
}
main(){
int a = 4;
int b = f(a);
}
//对应的汇编代码
//以下汇编代码仅仅是为了方便理解这个过程发生了什么,并不是编译器真的编译后生成的汇编代码(实际上要比这个复杂一些)
_f_int:
add ax,@sp[-8],@sp[-8]
ret //ret指令将栈中保存的地址出栈,返回mov @sp[-4],ax处进行取指令操作,即执行程序
_main:
add sp,#8
mov ax,#4
mov @sp[-8],ax
mov ax,@sp[-8]
push ax //实参值送到堆栈中去
call _f_int //函数调用在汇编中是call指令,需要将下一条指令的地址入栈保存,并修改IP寄存器跳转到标号_f_int处执行程序
mov @sp[-4],ax
pop ax
可以看到,在调用程序过程中,需要做一些额外的动作,
- 将被调用函数的参数push进堆栈里面去
- 比如保存当前指令的地址,用于程序返回
- 在堆栈中push进的东西都需要在pop出来一遍
那么能不能将这些函数调用过程的额外开销给节省掉,从而加快代码的执行效率呢?
c++新增了inline,内联函数特性正是用于解决这个问题,它的基本思路是直接将被调用函数的代码段嵌入在对应的代码处,所以直接往下执行即可,不需要再跳转内存中另一处再跳转回来,从而避免了额外的开销,提高了代码的执行效率。但同时存在的问题是,如果在代码中多次调用内联函数,这种方法必然造成“代码膨胀”,*相当于是一种用增大代码空间来减小代码执行时间的方法
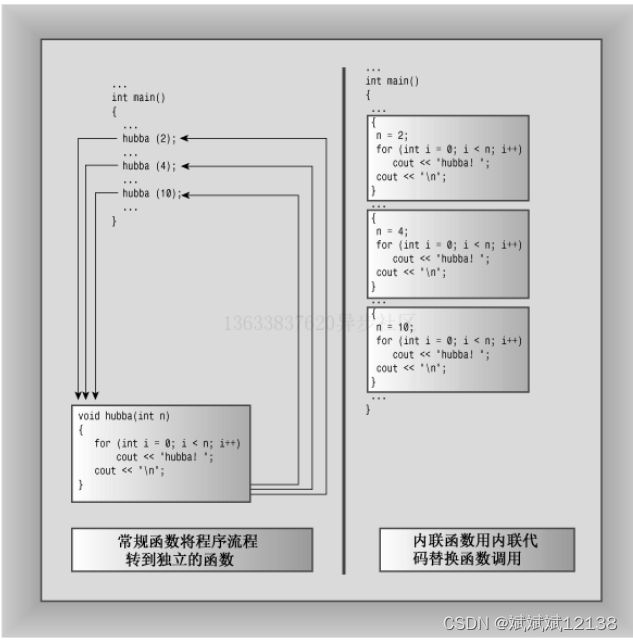
加上inline之后的效果
inline int f(int i){
return i*2;
}
main(){
int a = 4;
int b = f(a);
}
//代码其实就相当于:
main(){
int a = 4;
int b = a +a;
}
//对应的汇编代码就相当于
_main:
add sp,#8
mov ax,#4
mov @sp[-8],ax
add ax,@ap[-8]
mov @sp[-4],ax
什么时候选择使用内联函数?
- 函数的代码很短(所以函数调用时间相对于函数执行时间较长),一般2,3行
- 调用过程节省的时间其实很短,所以调用次数较多的时候节省的时间才会比较明显。当一个较短的函数被大量调用的时候值得我们inline
什么时候不使用inline
- . 函数过大或者函数发生了递归的时候不能使用内联函数
- . 函数内不要有循环语句之类的
- . 内联修饰符inline只是一个建议,并不是强制,
如何使用inline? (具体语法) 使用inline的注意事项!
- 在.h和.cpp中的函数声明和定义都必须加上inline修饰。
- 通常做法是省略原型声明,将整个定义放在本应该提供函数声明的地方。
在.h文件中声明inline ,在.cpp文件中定义时也加上inline,在main函数中包含该.h文件,一般来说这样是没问题的,但是实际上编译器会报一个warning:inline function 'void f(int ,int)'use but never difined undefined symbols for architecture x86_64: ‘f(int ,int)’,referenced from: _main in cc3kixgj.o
ld:symbol(s) not found for architecture x86_64
即编译器知道这是个内联函数,但是没找到定义,实际上编译后采用的还是函数调用方式。
编译器在同一时间只能看到一个文件,在编译main.cpp文件时,由于包含了.h文件,所以只能看到一个inline的声明,但是inline实际上想做的是将函数体代码块直接嵌入到main.cpp中的函数体内,但这个时候却看不到inline函数的定义(定义在另一个.cpp文件中),所以只能放弃内联,在这里进行一个函数调用,而在.cpp文件中看到inline,编译器说ok,你已经嵌入到main函数体中了,我不需要在这里再产生任何代码了,所以link时就找不到这段代码里的内容。
所以解决的办法是直接在.h文件中将函数定义放到这里即可,省略原型声明
// a.h 将定义放到这里,省略函数声明
inline f(int i,int j) {return i+j;}
// main。cpp
#include"a.h"
int main()
{
int f = f(1,2);
}
//不需要a.cpp文件了
内联函数在类定义中的应用
//cup.h文件
class Cup {
int color;
public:
int getColor();
void setColor(int color);
};
inline int Cup::getColor() { return color;}
inline void Cup::setColor(int color) {this->color = color;}
//省略在,cpp文件中对类里面的函数的定义
//main.cpp
#include"cup.h"
int main(){
Cup::setColor(1);
Cup::getColor();
//这里就相当于直接对color进行操作,省略了函数调用的开销,相当于将函数体直接插入到这里,
//效率更高,占用的内存空间也增大了。
}
内联与宏的缺陷
- 宏相当于是一种文本替换,并不是真正的函数
- 宏不能按值传递
- 宏函数没有作用域
#define MyAdd1(x,y) x+y
#define MyAdd2(x,y) ( (x) + (y) )
void test01{
int ret = MyAdd1(10,20); // = 30没问题
int ret1 = MyAdd1(10,20)*20; //预期结果是30*20 = 600 ,但实际上是10+20*20 = 410;
//这是由于宏是文本替换来实现的,也可以通过加括号来改进
int ret2 = MyAdd2(10,20)*20; //这个结果就对了,是600
}
#define MyCompare(a,b) ( (a) < (b) ) ? (a) : (b)
void test02(){
int a = 10;
int b = 20;
int ret = MyCompare(a,b); //返回10没问题
int ret1 = MyCompare(++a,b); //按预期应该++a = 11 ,函数返回较小值11 ,但是实际上这里返回的是12
//因为是 ( (++a) < (b) ) ? (++a) : (b),这里执行了两次++a ,宏并不是函数传参,只是一个文本替换,所以这里出现了问题。
}
而inline内联函数是一个真正的函数,就和常规函数一样,也是按值来传递的,所以不会出现这些问题,这使得C++内联功能远远胜过C语言的宏定义。