智慧城市-疫情流调系列1-Prompt-文本分类
参考资料
Universal Information Extraction
视频教程
AI快车道|通用信息抽取技术与产业应用实战https://www.bilibili.com/video/BV1Q34y1E7SW/?vd_source=6824a60429337b880936b4f7a2d42d38
AI快车道|ERNIE轻量级模型揭秘与落地案例分享
原理论文和代码参考
https://github.com/JunnYu/GPLinker_pytorch
GPLinker:基于GlobalPointer的实体关系联合抽取:https://kexue.fm/archives/8888
GlobalPointer:用统一的方式处理嵌套和非嵌套NER:https://kexue.fm/search/globalpointer/
https://github.com/bojone/bert4keras
https://github.com/CBLUEbenchmark/CBLUE
论文:
https://arxiv.org/pdf/2203.12277.pdf
UIE:
https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/uie
DuUIE:
PyTorch:https://github.com/universal-ie/UIE
PaddlePaddle:https://github.com/PaddlePaddle/PaddleNLP/tree/develop/examples/information_extraction/DuUIE
https://aistudio.baidu.com/aistudio/competition/detail/161/0/task-definition
AI Studio项目集合,
UIE相关的都可以学习:
PaddleNLP信息抽取技术重磅升级!开放域信息抽取来了!三行代码用起来~:https://aistudio.baidu.com/aistudio/projectdetail/3914778:https://aistudio.baidu.com/aistudio/projectdetail/3914778
五条标注数据搞定快递单信息抽取,PaddleNLP信息抽取技术重磅升级!:https://aistudio.baidu.com/aistudio/projectdetail/4038499
使用PaddleNLP UIE模型抽取PDF版上市公司公告:https://aistudio.baidu.com/aistudio/projectdetail/4497591
文本分类-提示学习(Prompt Learning)
小样本场景下的二/多分类任务指南:https://github.com/PaddlePaddle/PaddleNLP/tree/develop/applications/text_classification/multi_class/few-shot
小样本场景下的多标签分类任务指南:https://github.com/PaddlePaddle/PaddleNLP/tree/develop/applications/text_classification/multi_label/few-shot
小样本场景下的多标签层次分类任务指南:https://github.com/PaddlePaddle/PaddleNLP/tree/develop/applications/text_classification/hierarchical/few-shot
非常实用的数据增强检验和策略
可信AI检测:https://github.com/PaddlePaddle/TrustAI
数据增删改查增强:https://github.com/PaddlePaddle/PaddleNLP/blob/develop/docs/dataaug.md
linux训练
数据
wget https://paddlenlp.bj.bcebos.com/datasets/few-shot/tnews.tar.gz
tar zxvf tnews.tar.gz
mv tnews data
Prompt训练
python train.py --data_dir ./data/ --output_dir ./checkpoints/ --prompt "这条新闻写的是" --model_name_or_path ernie-3.0-base-zh --max_seq_length 128 --learning_rate 3e-5 --ppt_learning_rate 3e-4 --do_train --do_eval --num_train_epochs 100 --logging_steps 5 --per_device_eval_batch_size 32 --per_device_train_batch_size 8 --do_predict --metric_for_best_model accuracy --load_best_model_at_end --evaluation_strategy epoch --save_strategy epoch
微调训练
python train.py --dataset_dir "./data/" --save_dir "./checkpoints" --max_seq_length 128 --model_name "ernie-3.0-base-zh" --batch_size 8 --learning_rate 3e-5 --epochs 100 --logging_steps 5 --early_stop
win10训练
python train.py
--data_dir ./data/ --output_dir ./checkpoints/ --prompt "这条新闻写的是" --model_name_or_path ernie-3.0-base-zh --max_seq_length 128 --learning_rate 3e-5 --ppt_learning_rate 3e-4 --do_train --do_eval --num_train_epochs 100 --logging_steps 5 --per_device_eval_batch_size 2 --per_device_train_batch_size 2 --do_predict --metric_for_best_model accuracy --load_best_model_at_end --evaluation_strategy epoch --save_strategy epoch --device cpu
数据格式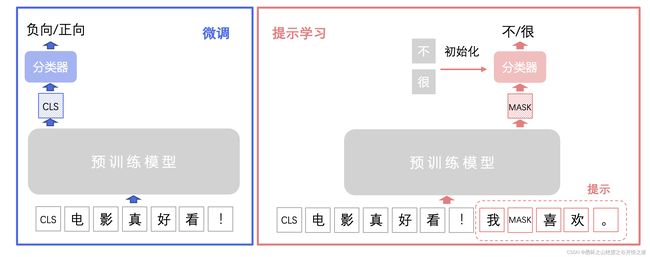


笔记
数据标注-模型训练-模型调优-模型压缩-预测部署全流程
类别:人的环境-自我修炼-自我优化-自我减负-服务社会全流程
提示学习,使用待预测字的预训练向量来初始化分类器参数
1、【方案介绍】提示学习的主要思想是将文本分类任务转换为构造提示中掩码 [MASK] 的分类预测任务,也即在掩码 [MASK]向量后接入线性层分类器预测掩码位置可能的字或词。提示学习使用待预测字的预训练向量来初始化分类器参数(如果待预测的是词,则为词中所有字的预训练向量平均值),充分利用预训练语言模型学习到的特征和标签文本,从而降低样本需求。提示学习同时提供 R-Drop 和 RGL 策略,帮助提升模型效果。
2、我们以下图情感二分类任务为例来具体介绍提示学习流程,分类任务标签分为 0:负向 和 1:正向 。在文本加入构造提示 我[MASK]喜欢。 ,将情感分类任务转化为预测掩码 [MASK] 的待预测字是 不 还是 很。具体实现方法是在掩码[MASK]的输出向量后接入线性分类器(二分类),然后用不和很的预训练向量来初始化分类器进行训练,分类器预测分类为 0:不 或 1:很 对应原始标签 0:负向 或 1:正向。而预训练模型微调则是在预训练模型[CLS]向量接入随机初始化线性分类器进行训练,分类器直接预测分类为 0:负向 或 1:正向。
3、本质上要下游应用的时候和预训练的思想和策略保持一致,更好应用预训练提取出来的特征,微调是通过训练的方式,告诉当前模型要做的任务,Prompt是通过提示的方式,在数据集很少的情况下,挖掘预训练截断本身蕴含的信息。
提示学习(Prompt Learning) 的主要思想是将二/多分类任务转换为掩码预测任务,充分利用预训练语言模型学习到的特征,从而降低样本需求。以情感分类任务为例,标签分为1-正向,0-负向两类,如下图所示,通过提示我[MASK]喜欢。,原有1-正向,0-负向的标签被转化为了预测空格是很还是不。
模型裁剪!
丢弃不重要的东西,避免不重要对自己的干扰,同时在从老师身上学一遍,青出于蓝而胜于蓝
现实部署场景需要同时考虑模型的精度和性能表现,文本分类应用接入PaddleNLP 模型压缩 API 。采用了DynaBERT 中宽度自适应裁剪策略,对预训练模型多头注意力机制中的头(Head )进行重要性排序,保证更重要的头(Head )不容易被裁掉,然后用原模型作为蒸馏过程中的教师模型,宽度更小的模型作为学生模型,蒸馏得到的学生模型就是我们裁剪得到的模型。实验表明模型裁剪能够有效缩小模型体积、减少内存占用、提升推理速度。模型裁剪去掉了部分冗余参数的扰动,增加了模型的泛化能力,在部分任务中预测精度得到提高。

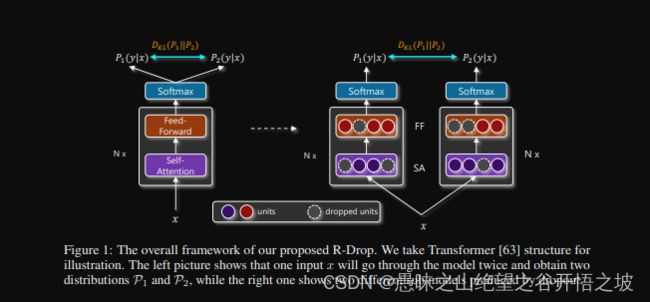
R-Drop: Regularized Dropout for Neural Networks
看摘要,看图,看公式
为了训练和预测的一致性,训练截断的dropout就应该靠的更近
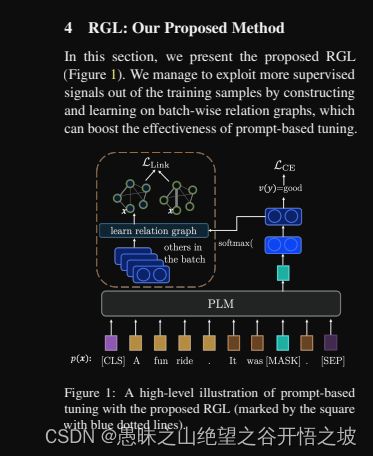
RGL: A Simple yet Effective Relation Graph Augmented Prompt-based Tuning Approach for Few-Shot Learning
By constructing relation graphs and learning to approximate the edge labels eˆij defined in (3), RGL rules samples from the same class to
be connected and otherwise disconnecte
同一个类的近,不同类的远,相当于增加了正样本和负样本的信息而已
Python 函数参数有冒号 声明后有-> 箭头
Python 函数参数有冒号 声明后有-> 箭头
在官方文档指明.__annotations__是函数的参数注释和返回值注释:
所以打印出Annotations: {‘ham’:
其实并没有指定类型 只是写函数的人提醒用函数的人最好传什么类型的参数,因为最后需要两个参数进行字符串拼接;
当然,也可以直接写字符串提醒:
1 def f(ham: str, eggs: str = 'eggs') -> str :
2 print("Annotations:", f.__annotations__)
3 print("Arguments:", ham, eggs)
4 return ham + ' and ' + eggs
5
6 print(f("test","abc"))

python中的类方法(@classmethod)
python中的类方法(@classmethod)
我对Man这个类进行实例化2次,每个实例的id都不一样。这就依靠类方法来实现了:首先,用@classmethod描述类方法,然后用"cls"代表本类。类方法对类属性进行的处理是有记忆性的。
需要注意的是,类方法处理的变量一定要是类变量。因为在类方法里你用不了self来寻址实例变量,所以需要把类变量放到最前面描述,如上面的"id=0"所示。类变量是可以被self访问的,所以,在类变量定义好了以后,不需要在_init_函数里对类变量再一次描述。所以,上面代码里self.id不一定需要。
对于研究深度学习的朋友,可以有效利用这个trick,来进行模型的加载。比如,把模型封装成一个类,把初始化网络和加载模型用类方法来描述,这样一次load之后,可以一直实用模型。