【21.09-21.10】近日Paper Quichthrough汇总
文本分类
1. PTR: Prompt Tuning with Rules for Text Classification
Paper Url
摘要:
经过微调的预先训练的语言模型(PLMs)在几乎所有的NLP任务中都取得了令人惊叹的表现。通过使用额外的提示对plm进行微调,我们可以进一步激发分布在plm中的丰富知识,更好地服务于下游任务。提示调优在情感分类和自然语言推理等少数分类任务中取得了很好的效果。然而,手工设计大量语言提示符既麻烦又容易出错。对于那些自动生成的提示,在非少数场景中验证它们的有效性也是昂贵和耗时的。因此,即时调优处理多类分类任务仍然具有挑战性。为此,我们提出了多类文本分类的提示规则调优(PTR),并应用逻辑规则构造带有多个子提示的提示。通过这种方式,PTR能够将每个类的先验知识编码为提示调优。我们对关系分类这一典型而复杂的多类分类任务进行了实验,结果表明,PTR能够显著且一致地优于现有的最新基线。这表明PTR是一种很有前途的方法,可以利用人类的先验知识和plm来完成复杂的分类任务。
内容提要:
总结了promt learning 用于文本分类的范式,

比较了learning model from scratch、fine-tuning、prompt在不同PTM上的效果。

2. XAI Methods for Neural Time Series Classification: A Brief Review
Comment: 8 pages, 0 figures, Accepted as a poster presentation
Link: http://arxiv.org/abs/2108.08009
Abstract
Deep learning models have recently demonstrated remarkable results in avariety of tasks, which is why they are being increasingly applied inhigh-stake domains, such as industry, medicine, and finance. Considering thatautomatic predictions in these domains might have a substantial impact on thewell-being of a person, as well as considerable financial and legalconsequences to an individual or a company, all actions and decisions thatresult from applying these models have to be accountable. Given that asubstantial amount of data that is collected in high-stake domains are in theform of time series, in this paper we examine the current state of eXplainableAI (XAI) methods with a focus on approaches for opening up deep learning blackboxes for the task of time series classification. Finally, our contributionalso aims at deriving promising directions for future work, to advance XAI fordeep learning on time series data.
TSI: an Ad Text Strength Indicator using Text-to-CTR and Semantic-Ad-Similarity
Comment: Accepted for publication at CIKM 2021
Link: http://arxiv.org/abs/2108.08226
Abstract
Coming up with effective ad text is a time consuming process, andparticularly challenging for small businesses with limited advertisingexperience. When an inexperienced advertiser onboards with a poorly written adtext, the ad platform has the opportunity to detect low performing ad text, andprovide improvement suggestions. To realize this opportunity, we propose an adtext strength indicator (TSI) which: (i) predicts the click-through-rate (CTR)for an input ad text, (ii) fetches similar existing ads to create aneighborhood around the input ad, (iii) and compares the predicted CTRs in theneighborhood to declare whether the input ad is strong or weak. In addition, assuggestions for ad text improvement, TSI shows anonymized versions of superiorads (higher predicted CTR) in the neighborhood. For (i), we propose a BERTbased text-to-CTR model trained on impressions and clicks associated with an adtext. For (ii), we propose a sentence-BERT based semantic-ad-similarity modeltrained using weak labels from ad campaign setup data. Offline experimentsdemonstrate that our BERT based text-to-CTR model achieves a significant liftin CTR prediction AUC for cold start (new) advertisers compared to bag-of-wordsbased baselines. In addition, our semantic-textual-similarity model for similarads retrieval achieves a precision@1 of 0.93 (for retrieving ads from the sameproduct category); this is significantly higher compared to unsupervisedTF-IDF, word2vec, and sentence-BERT baselines. Finally, we share promisingonline results from advertisers in the Yahoo (Verizon Media) ad platform wherea variant of TSI was implemented with sub-second end-to-end latency
4. Fine-Grained Element Identification in Complaint Text of Internet Fraud
Comment: 5 pages, 5 figures, 3 tables accepted as a short paper to CIKM 2021
Link: http://arxiv.org/abs/2108.08676
Abstract
Existing system dealing with online complaint provides a final decisionwithout explanations. We propose to analyse the complaint text of internetfraud in a fine-grained manner. Considering the complaint text includesmultiple clauses with various functions, we propose to identify the role ofeach clause and classify them into different types of fraud element. Weconstruct a large labeled dataset originated from a real finance serviceplatform. We build an element identification model on top of BERT and proposeadditional two modules to utilize the context of complaint text for betterelement label classification, namely, global context encoder and label refiner.Experimental results show the effectiveness of our model.
PTM
1. TopicBERT: A Topic-Enhanced Neural Language Model Fine-Tuned for Sentiment Classification
Paper Url. IEEE TRANSACTIONS ON NEURAL NETWORKS AND LEARNING SYSTEMS
摘要:
情感分类是数据分析的一种形式,从数据中挖掘出人们对某个话题的感受和态度。这种“预测时代精神”的诱人力量意味着,情感分类长期以来一直吸引着人们的兴趣,但结果好坏参半。然而,BERT框架及其训练前的神经语言模型在情感分类方面取得了新的成功。BERT模型通过掩码语言建模来获取单词级信息,通过下一个句子预测任务来获取句子级上下文。对于某些自然语言处理任务来说,它们是现成的模型。然而,大多数模型都使用特定领域的信息进行了进一步的微调,以提高准确性和实用性。基于进一步的微调步骤将提高下游情感分类任务的性能的想法,我们开发了TopicBERT——一个经过微调的BERT模型,除了在单词和句子级别识别主题外,还可以在语料库级别识别主题。TopicBERT包括两个变体:TopicBERT-atp(方面主题预测),它通过辅助训练任务捕获主题信息,TopicBERT-TA,其中主题表示直接注入主题增强层进行情感分类。使用TopicBERT-ATP,主题是由LDA机制和坍塌吉布斯取样预先确定的。使用TopicBERT-TA,主题可以在训练过程中动态变化。实验结果表明,在SemEval 2014 Task 4中,这两种方法在两个不同的领域都具有最先进的性能。然而,在方法的测试中,直接增强优于进一步的训练。综合分析的形式消融,参数,和复杂性研究伴随结果。
主要内容:
2. Frustratingly Simple Pretraining Alternatives to Masked Language Modeling
Paper Url. EMNLP 2021. Github Code.
摘要:
掩蔽语言建模(MLM)是一种自我监督的预训练目标,广泛应用于自然语言处理中学习文本表示。传销训练一个模型来预测输入令牌的随机样本,这些令牌在整个词汇表的多类设置中已被[MASK]占位符替换。在进行预培训时,通常会在代币或序列水平上与传销一起使用其他辅助目标,以提高下游业绩(例如,下一句话预测)。然而,到目前为止,还没有前人的工作试图检验其他更简单的语言直觉目标是否可以作为主要的训练前目标单独使用。在本文中,我们探讨了5个简单的基于令牌级别分类任务的前训练目标作为传销的替代。在GLUE和SQuAD上的实验结果表明,我们提出的方法可以达到与使用BERT-BASE架构的传销相当或更好的性能。我们使用更小的模型进一步验证了我们的方法,结果显示,在使用41%的BERT-BASE参数进行预训练的模型中,BERT-MEDIUM只导致我们最佳目标下GLUE分数下降1%。
主要内容:
AMMUS : A Survey of Transformer-based Pretrained Models in Natural Language Processing
Comment: Preprint under review
Link: http://arxiv.org/abs/2108.05542
Abstract
Transformer-based pretrained language models (T-PTLMs) have achieved greatsuccess in almost every NLP task. The evolution of these models started withGPT and BERT. These models are built on the top of transformers,self-supervised learning and transfer learning. Transformed-based PTLMs learnuniversal language representations from large volumes of text data usingself-supervised learning and transfer this knowledge to downstream tasks. Thesemodels provide good background knowledge to downstream tasks which avoidstraining of downstream models from scratch. In this comprehensive survey paper,we initially give a brief overview of self-supervised learning. Next, weexplain various core concepts like pretraining, pretraining methods,pretraining tasks, embeddings and downstream adaptation methods. Next, wepresent a new taxonomy of T-PTLMs and then give brief overview of variousbenchmarks including both intrinsic and extrinsic. We present a summary ofvarious useful libraries to work with T-PTLMs. Finally, we highlight some ofthe future research directions which will further improve these models. Westrongly believe that this comprehensive survey paper will serve as a goodreference to learn the core concepts as well as to stay updated with the recenthappenings in T-PTLMs.
相似度计算
1. LadRa-Net: Locally Aware Dynamic Reread Attention Net for Sentence Semantic Matching.
Paper Url. IEEE TRANSACTIONS ON NEURAL NETWORKS AND LEARNING SYSTEMS(Second Tier)
摘要:
句子语义匹配需要一个agent来确定两个句子之间的语义关系,它被广泛应用于各种自然语言任务,如自然语言推理(NLI)和意译识别(PI)。近年来,这一领域取得了很大的进展,特别是基于注意的方法和基于预训练语言模型的方法。然而,这些方法大多以静态的方式关注句子中所有重要的部分,只强调单词对查询的重要性,抑制了注意机制的能力。为了克服这一问题,提高注意机制的性能,我们提出了一种新的动态重读(DRr)注意,它可以在每一步密切关注句子的一个小区域,并重新阅读重要的部分,以获得更好的句子表征。基于这种注意变异,我们开发了一种用于句子语义匹配的DRr网络(DRr- net)。此外,在DRr注意中选择一个小区域似乎不足以解决句子语义问题,使用预先训练好的语言模型作为输入编码器将会引入不完整和脆弱的表示问题。为此,我们将DRr- net扩展到local aware dynamic reread attention net (LadRa-Net),该网络利用句子的局部结构来缓解预训练语言模型中字节对编码(BPE)的不足,提高DRr注意性能。在两个热门的句子语义匹配任务上的大量实验表明,DRr-Net能够显著提高句子语义匹配的性能。同时,LadRa-Net通过考虑句子的局部结构可以获得更好的性能。另外,非常有趣的是,我们实验中的一些发现与心理学研究中的一些发现是一致的。
主要内容:
2. Similarity Judgment Within and Across Categories: A Comprehensive Model Comparison.
Paper Url. Cognitive Science(SSCI II)
摘要:
相似性是人类认知中最重要的关系之一,它可以辅助类别学习和分类、泛化和辨别、判断和决策等认知功能。研究人员提出了一系列可能在相似性判断中起作用的表征和指标,但尚未全面比较这些表征和指标在预测不同语义类别内部和跨语义类别之间的相似性方面的能力。我们通过将9个重要的向量语义表示与7个已建立的可对这些表示进行操作的相似度度量,以及相似度函数中维度加权的监督方法来进行这样的比较。该方法产生了一个包含126个不同表征度量对的析因模型结构,我们在一个新的8类共下名词对之间的相似性判断数据集上进行了测试。我们发现,余弦相似度和皮尔森相关是表现最好的非加权相似函数,而且从自由联想规范衍生出来的词向量通常优于从文本衍生出来的词向量(包括那些专门用于相似度的词向量)。重要的是,在所有类型的相似函数和表示中,使用人类相似性判断来学习特定类别维度权重的模型比所有未加权方法产生了更好的预测,尽管维度权重在语义类别中不能很好地泛化,表明在相似判断中有很强的类别背景效应。我们讨论了这些结果对认知建模和自然语言处理的影响,以及关于相似性的表征和度量的理论
主要内容:
CV/NER Intuition
1. Your Classifier is secretely an Energy Based Model
Paper Url. B站讲解. ICLR2020
摘要:
我们建议将p(y|x)的标准判别分类器重新解释为p(x,y)联合分布的基于能量的模型。在这种设置下,可以很容易地计算标准类别概率以及p(x)和p(x|y)的非归一化值。在这个框架中,可以使用标准的鉴别架构,模型也可以在未标记的数据上进行训练。我们证明,基于能量的联合分布训练提高了校准、鲁棒性和分布外检测,同时也使我们的模型生成的样本质量与最近的GAN方法相媲美。我们改进了最近提出的扩大基于能量模型的训练的技术,并提出了一种比标准分类训练增加较少开销的方法。我们的方法是第一个在一个混合模型中实现与最新的生成和区别学习相匹敌的性能。
主要内容:
2. A Frustratingly Easy Approach for Entity and Relation Extraction
Paper Url. NAACL 2021. Github Code
摘要:
端到端关系抽取的目的是识别命名实体并提取它们之间的关系。最近的工作是将这两个子任务联合建模,要么将它们放入一个结构化的预测框架中,要么通过共享表示执行多任务学习。在这项工作中,我们提出了一种简单的流水线方法来提取实体和关系,并在标准基准(ACE04, ACE05和SciERC)上建立了新的技术水平,与之前使用相同的预训练编码器的关节模型相比,关系F1获得了1.7%-2.8%的绝对改善。我们的方法基本上建立在两个独立的编码器上,并且仅仅使用实体模型来构造关系模型的输入。通过一系列仔细的检查,我们验证了学习实体和关系的不同上下文表示、在关系模型中早期融合实体信息和合并全局上下文的重要性。最后,我们还提出了一种有效的近似方法,该方法在推理时只需要通过实体和关系编码器一次,实现了8-16 × \times ×加速,但精度略有降低。
3. LabOR: Labeling Only if Required for Domain Adaptive Semantic Segmentation
Comment: Accepted to ICCV 2021 (Oral)
Link: http://arxiv.org/abs/2108.05570
Abstract
Unsupervised Domain Adaptation (UDA) for semantic segmentation has beenactively studied to mitigate the domain gap between label-rich source data andunlabeled target data. Despite these efforts, UDA still has a long way to go toreach the fully supervised performance. To this end, we propose a Labeling Onlyif Required strategy, LabOR, where we introduce a human-in-the-loop approach toadaptively give scarce labels to points that a UDA model is uncertain about. Inorder to find the uncertain points, we generate an inconsistency mask using theproposed adaptive pixel selector and we label these segment-based regions toachieve near supervised performance with only a small fraction (about 2.2%)ground truth points, which we call “Segment based Pixel-Labeling (SPL)”. Tofurther reduce the efforts of the human annotator, we also propose “Point-basedPixel-Labeling (PPL)”, which finds the most representative points for labelingwithin the generated inconsistency mask. This reduces efforts from 2.2% segmentlabel to 40 points label while minimizing performance degradation. Throughextensive experimentation, we show the advantages of this new framework fordomain adaptive semantic segmentation while minimizing human labor costs.
4. Contextual Convolutional Neural Networks
Comment: Accepted at ICCV Workshop on Neural Architectures (NeurArch 2021)
Link: http://arxiv.org/abs/2108.07387
Abstract
We propose contextual convolution (CoConv) for visual recognition. CoConv isa direct replacement of the standard convolution, which is the core componentof convolutional neural networks. CoConv is implicitly equipped with thecapability of incorporating contextual information while maintaining a similarnumber of parameters and computational cost compared to the standardconvolution. CoConv is inspired by neuroscience studies indicating that (i)neurons, even from the primary visual cortex (V1 area), are involved indetection of contextual cues and that (ii) the activity of a visual neuron canbe influenced by the stimuli placed entirely outside of its theoreticalreceptive field. On the one hand, we integrate CoConv in the widely-usedresidual networks and show improved recognition performance over baselines onthe core tasks and benchmarks for visual recognition, namely imageclassification on the ImageNet data set and object detection on the MS COCOdata set. On the other hand, we introduce CoConv in the generator of astate-of-the-art Generative Adversarial Network, showing improved generativeresults on CIFAR-10 and C
对比学习
1. Smoothed Contrastive Learning for Unsupervised Sentence Embedding
Paper Url
摘要:
对比学习已逐渐被应用于学习高质量的无监督句子嵌入。在之前的无监督方法中,据我们所知,最先进的方法是无监督SimCSE (unsup-SimCSE)。unsuper - simcse在训练阶段使用InfoNCE的loss函数,将语义相似的句子拉到一起,将不相似的句子分开。理论上,我们希望在unsup-SimCSE中使用更大的批次,以获得更充分的样品比较,避免过拟合。然而,增加批大小并不一定会带来改进,甚至会在批大小超过阈值时导致性能下降。通过统计观察,我们发现这可能是由于增加批量后引入了低置信负对。为了缓解这个问题,我们在InfoNCE损失函数上引入了一种简单的平滑策略,称为高斯平滑InfoNCE (GS-InfoNCE)。具体地说,我们加入随机高斯噪声向量作为负样本,作为负样本空间的平滑。所提出的平滑策略虽然简单,但对unsuper - simcse带来了实质性的改进。我们在标准的语义文本相似度(STS)任务上评估GS-InfoNCEon。在BERT-base、BERT-large、RoBERTa-base和RoBERTa-large的基础上,GS-InfoNCE的平均spearman相关性分别为1.38%、0.72%、1.17%和0.28%,优于最先进的unsuper - simcse。
主要工作:
将SimCSE的loss:
ℓ i = − log e sim ( h i , h i + ) τ ∑ j = 1 N e sim ( h i , h j ) τ \ell_{i}=-\log \frac{e^{\operatorname{sim}\left(\mathbf{h}_{i}, \mathbf{h}_{i}^{+}\right) \tau}}{\sum_{j=1}^{N} e^{\operatorname{sim}\left(\mathbf{h}_{i}, \mathbf{h}_{j}\right) \tau}} ℓi=−log∑j=1Nesim(hi,hj)τesim(hi,hi+)τ
加上了高斯平滑( G ∼ N ( μ , σ 2 ) G\sim N(\mu,\sigma^2) G∼N(μ,σ2)):
ℓ i = − log e sim ( h i , h i + ) / τ ∑ j = 1 N e sim ( h j , h i ) / τ + λ ⋅ ∑ k = 1 M e sim ( g k , h i ) / τ \ell_{i}=-\log \frac{e^{\operatorname{sim}\left(\mathbf{h}_{i}, \mathbf{h}_{i}^{+}\right) / \tau}}{\sum_{j=1}^{N} e^{\operatorname{sim}\left(\mathbf{h}_{j}, \mathbf{h}_{i}\right) / \tau}+\lambda \cdot \sum_{k=1}^{M} e^{\operatorname{sim}\left(\mathbf{g}_{k}, \mathbf{h}_{i}\right) / \tau}} ℓi=−log∑j=1Nesim(hj,hi)/τ+λ⋅∑k=1Mesim(gk,hi)/τesim(hi,hi+)/τ
就加了三行代码:

效果提升也是比较明显的:

2. What’s Hidden in a One-layer Randomly Weighted Transformer?
paper url. EMNLP 2021 (short). Github code
摘要:
我们证明,隐藏在一层随机加权神经网络中的子网络,在机器翻译任务中可以实现令人印象深刻的性能,而不需要修改权值初始化。为了寻找单层随机加权神经网络的子网络,我们在相同的权值矩阵上应用不同的二元掩码来生成不同的层。在一层随机加权Transformer中,我们发现在IWSLT14/WMT14上可以实现29.45/17.29 BLEU的子网。使用固定的预先训练的嵌入层,先前发现的子网络小于,但可以匹配98%/92% (34.14/25.24 BLEU)的性能,一个训练的 T r a n s f o r m e r s m a l l / b a s e Transformer_{small/base} Transformersmall/baseIWSLT14/WMT14。此外,我们还演示了在这种设置下更大和更深层次的变压器的有效性,以及不同初始化方法的影响。
主要工作:
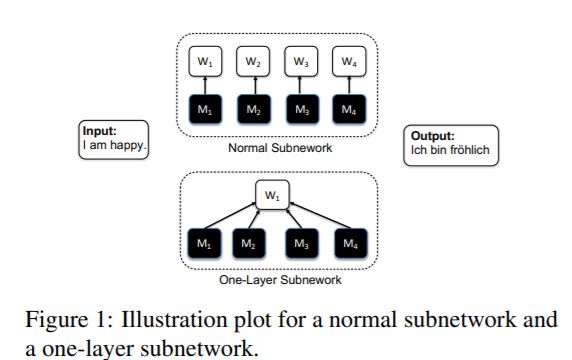
验证了“Supermask”(即掩盖一整部分token作为一个大的mask)随机权重单层神经网络的有效性。
3. ESimCSE: Enhanced Sample Building Method for Contrastive Learning of Unsupervised Sentence Embedding
Papar Url
摘要:
对比学习在非监督句子嵌入的学习中得到了广泛的关注。当前最先进的无监督方法是无监督SimCSE (unsup-SimCSE)。Unsup-SimCSE将dropout作为一种最小的数据增强方法,将相同的输入句子两次传递给预先训练过的Transformer编码器(dropout是打开的),得到两个对应的嵌入,构建正对。由于Transformer中使用了位置嵌入,句子的长度信息一般会被编码到句子嵌入中,所以unsup-simcse中的每对正数实际上包含相同的长度信息。因此,用这些正对训练的非超simcse可能是有偏见的,这可能会倾向于认为相同或相似长度的句子在语义上更相似。通过统计观察,我们发现unsup-SimCSE确实存在这样的问题。为了缓解这个问题,我们采用简单的重复操作来修改输入句子,然后将输入句子和修改后的对应句分别传递给预先训练好的Transformer编码器,得到正负对。此外,我们从计算机视觉社区汲取灵感,**引入动量对比,无需额外计算就增加了负对的数量。**将这两种改进方法分别应用于正负句对,构建了一种新的句子嵌入方法——Enhanced Unsup-SimCSE (ESimCSE)。基于语义文本相似度(STS)任务,在多个基准数据集上对ESimCSE算法进行了评价。实验结果表明,ESimCSE在BERT-base上的平均Spearman相关性为2.02%,优于最先进的unsuper - simcse。
内容提要:
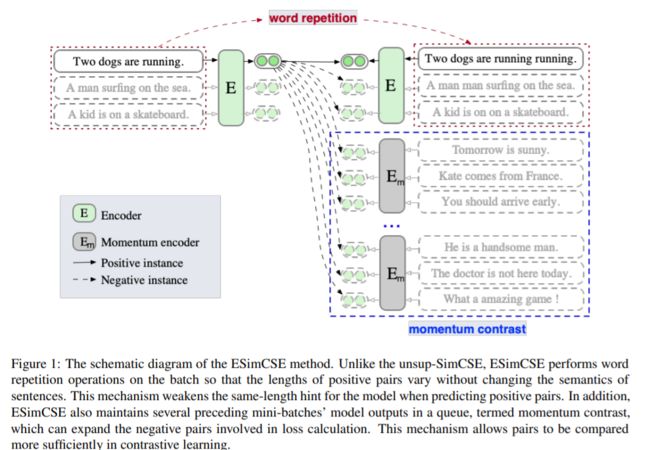
采用字词重叠,保证了构造的负样本对中和正样本对的样本句长是一样的,消除了等句长对model的提示作用。
4. Group-aware Contrastive Regression for Action Quality Assessment
Comment: Accepted to ICCV 2021
Link: http://arxiv.org/abs/2108.07797
Abstract
Assessing action quality is challenging due to the subtle differences betweenvideos and large variations in scores. Most existing approaches tackle thisproblem by regressing a quality score from a single video, suffering a lot fromthe large inter-video score variations. In this paper, we show that therelations among videos can provide important clues for more accurate actionquality assessment during both training and inference. Specifically, wereformulate the problem of action quality assessment as regressing the relativescores with reference to another video that has shared attributes (e.g.,category and difficulty), instead of learning unreferenced scores. Followingthis formulation, we propose a new Contrastive Regression (CoRe) framework tolearn the relative scores by pair-wise comparison, which highlights thedifferences between videos and guides the models to learn the key hints forassessment. In order to further exploit the relative information between twovideos, we devise a group-aware regression tree to convert the conventionalscore regression into two easier sub-problems: coarse-to-fine classificationand regression in small intervals. To demonstrate the effectiveness of CoRe, weconduct extensive experiments on three mainstream AQA datasets including AQA-7,MTL-AQA and JIGSAWS. Our approach outperforms previous methods by a largemargin and establishes new state-of-the-art on all three benchmarks.
5. Feature Stylization and Domain-aware Contrastive Learning for Domain Generalization
Comment: Accepted to ACM MM 2021 (oral)
Link: http://arxiv.org/abs/2108.08596
Abstract
Domain generalization aims to enhance the model robustness against domainshift without accessing the target domain. Since the available source domainsfor training are limited, recent approaches focus on generating samples ofnovel domains. Nevertheless, they either struggle with the optimization problemwhen synthesizing abundant domains or cause the distortion of class semantics.To these ends, we propose a novel domain generalization framework where featurestatistics are utilized for stylizing original features to ones with noveldomain properties. To preserve class information during stylization, we firstdecompose features into high and low frequency components. Afterward, westylize the low frequency components with the novel domain styles sampled fromthe manipulated statistics, while preserving the shape cues in high frequencyones. As the final step, we re-merge both components to synthesize novel domainfeatures. To enhance domain robustness, we utilize the stylized features tomaintain the model consistency in terms of features as well as outputs. Weachieve the feature consistency with the proposed domain-aware supervisedcontrastive loss, which ensures domain invariance while increasing classdiscriminability. Experimental results demonstrate the effectiveness of theproposed feature stylization and the domain-aware contrastive loss. Throughquantitative comparisons, we verify the lead of our method upon existingstate-of-the-art methods on two benchmarks, PACS and Office-Home.
6. ConSERT: A Contrastive Framework for Self-Supervised Sentence Representation Transfer
| 会议:ACL 2021
| 下载链接:https://arxiv.org/abs/2105.11741
向量表示
1. Joint Dynamic Manifold and Discriminant Information Learning for Feature Extraction.
Paper Url. IEEE TRANSACTIONS ON NEURAL NETWORKS AND LEARNING SYSTEMS
摘要:
邻域重构是学习局部流形结构的一个很好的方法。基于表示的判别分析方法通常学习每个样本与所有其他样本之间的重构关系。但这些方法构造的重构图存在三个局限性:1)不能保证重构系数的局部稀疏性;2)非均质样品可能具有非零系数;3)它们在降维之前学习了流形信息。由于原始空间中存在噪声和冗余特征,预学习的流形结构可能不准确。因此,会影响降维性能。在本文中,我们提出了一个联合模型,同时学习亲和关系,重建关系和投影矩阵。在该模型中,我们主动为每个样本分配邻居,并在降维过程中学习每个样本与其具有相同标签信息的邻居之间的重建系数。采用稀疏约束来保证邻居和重构系数的稀疏性。为了去除特征间的相关性,在投影矩阵上加上白化约束。提出了一种迭代算法来求解该方法。在玩具数据和公共数据集上的大量实验表明了该方法的优越性。
主要内容:
2. Adaptive Prototypical Networks With Label Words and Joint Representation Learning for Few-Shot Relation Classification.
Paper Url. IEEE TRANSACTIONS ON NEURAL NETWORKS AND LEARNING SYSTEMS
摘要:
关系分类(RC)任务是信息抽取的基本任务之一,旨在检测非结构化自然语言文本中实体对之间的关系信息,生成实体-关系三元结构的结构化数据。虽然远程监督方法可以有效缓解监督学习中训练数据不足的问题,但也会将噪声引入到数据中,仍然不能从根本上解决训练实例的长尾分布问题。为了使神经网络学习新知识通过几个实例像人类一样,这项工作关注few-shot关系分类(FSRC),一个分类器推广新类,应该没有出现在训练集,给出每个类的样本数量。为了充分利用已有的信息,为每个实例获得更好的特征表示,我们提出从两个方面对每个类原型进行自适应编码。首先,基于典型的网络,提出一种自适应混合机制添加标签词来表示类的原型,而我们所知,第一次尝试将标签信息集成到支持的每个类样本的特点,以获得更多的互动类的原型。其次,为了更合理地度量每个类别样本之间的距离,我们引入了一个用于联合表示学习的损失函数,以自适应的方式对每个支持实例进行编码。在FewRel上进行了不同少镜头(FS)设置下的大量实验,结果表明,所提出的带有标签词和联合表示学习的自适应原型网络不仅在准确率上有显著提高,而且提高了少镜头RC模型的泛化能力。
主要内容:
3. Learning Representations for Time Series Clustering
Paper Url. NIPS2019. B站讲解
摘要:
当类别信息不可用时,时间序列聚类是一种必要的无监督技术。它已被广泛应用于基因组数据、异常检测,以及任何模式检测很重要的领域。尽管基于特征的时间序列聚类方法对噪声和异常值具有鲁棒性,并能降低数据的维数,但它们通常依赖领域知识手工构建高质量的特征。序列到序列(seq2seq)模型可以通过设计适当的学习目标,如重构和上下文预测,以无监督的方式从序列数据学习表示。在将seq2seq应用于时间序列聚类时,如何有效地表示序列的时间动态、多尺度特征以及良好的聚类特性仍然是一个挑战。如何最大限度地提高编码器的性能仍然是一个悬而未决的问题。本文提出了一种新的无监督时间表示学习模型——深度时间聚类表示(Deep temporal Clustering representation, DTCR),该模型将时间重构和K-means目标集成到seq2seq模型中。这种方法可以改进集群结构,从而获得特定于集群的时间表示。同时,为了增强编码器的能力,我们提出了假样本生成策略和辅助分类任务。在大量时间序列数据集上进行的实验表明,与现有方法相比,DTCR是最先进的方法。可视化分析不仅表明了聚类特定表示的有效性,而且表明即使K-means出错,学习过程也是稳健的。
主要内容:
4. Twitter User Representation using Weakly Supervised Graph Embedding
Comment: accepted at 16th International AAAI Conference on Web and Social Media (ICWSM-2022), direct accept from May 2021 submission, 12 pages
Link: http://arxiv.org/abs/2108.08988
Abstract
Social media platforms provide convenient means for users to participate inmultiple online activities on various contents and create fast widespreadinteractions. However, this rapidly growing access has also increased thediverse information, and characterizing user types to understand people’slifestyle decisions shared in social media is challenging. In this paper, wepropose a weakly supervised graph embedding based framework for understandinguser types. We evaluate the user embedding learned using weak supervision overwell-being related tweets from Twitter, focusing on ‘Yoga’, ‘Keto diet’.Experiments on real-world datasets demonstrate that the proposed frameworkoutperforms the baselines for detecting user types. Finally, we illustrate dataanalysis on different types of users (e.g., practitioner vs. promotional) fromour dataset. While we focus on lifestyle-related tweets (i.e., yoga, keto), ourmethod for constructing user representation readily generalizes to otherdomains.
5. Fastformer: Additive Attention is All You Need
Category: NLP
Link: https://arxiv.org/abs/2108.09084
Abstract
Transformer is a powerful model for text understanding. It is inefficient due to its quadratic complexity to input sequence length. In Fastformer, instead of modeling the pair-wise interactionsbetween tokens, we first use additive attention mechanism to model global contexts.
6. Sentence-T5: Scalable Sentence Encoders from Pre-trained Text-to-Text Models
Category: NLP
Link: https://arxiv.org/abs/2108.08877
Abstract
Sentence embeddings are broadly useful for language processing tasks. While T5 achieves impressive performance on language tasks cast assequence-to-sequence mapping problems, it is unclear how to produce sentences from encoder-decoder models. We investigate three methods for extracting T5 sentences.
7.ExBERT: An External Knowledge Enhanced BERT for Natural Language Inference
链接:https://arxiv.org/abs/2108.01589
作者:Amit Gajbhiye,Noura Al Moubayed,Steven Bradley
机构: University of Sheffield, Sheffield, UK, University of Durham, Durham, UK
Label Name
Adaptive Prototypical Networks with Label Words and Joint Representation Learning for Few-Shot Relation Classification

Paper Url, 东华大学,IEEE transactions on neural networks and learning systems
关系分类(RC)任务是信息抽取的基本任务之一,旨在检测非结构化自然语言文本中实体对之间的关系信息,生成实体-关系三元结构的结构化数据。虽然远程监督方法可以有效缓解监督学习中训练数据不足的问题,但也会将噪声引入到数据中,仍然不能从根本上解决训练实例的长尾分布问题。为了使神经网络学习新知识通过几个实例像人类一样,这项工作关注few-shot关系分类,一个分类器推广新类,应该没有出现在训练集,给出每个类的样本数量。为了充分利用已有的信息,为每个实例获得更好的特征表示,我们提出从两个方面对每个类原型进行自适应编码。首先,基于典型的网络,提出一种自适应混合机制添加标签词来表示类的原型,而我们所知,第一次尝试将标签信息集成到支持的每个类样本的特点,以获得更多的互动类的原型。其次,为了更合理地度量每个类别样本之间的距离,我们引入了一个用于联合表示学习的损失函数,以自适应的方式对每个支持实例进行编码。在FewRel上进行了不同few-shot设置下的大量实验,结果表明,所提出的带有标签词和联合表示学习的自适应原型网络不仅在准确率上有显著提高,而且提高了少镜头RC模型的泛化能力。
模型

Putting Words in BERT’s Mouth: Navigating Contextualized Vector Spaces with Pseudowords

Paper url, EMNLP 2021 camera-ready version,
我们提出了一种在上下文化向量空间(特别是BERT空间)中探索单个点周围区域的方法,作为一种研究这些区域如何对应单词意义的方法。
通过在输入层中引入上下文化的伪词作为静态嵌入的替代,然后对句子中的单词进行掩码预测,我们能够以一种受控的方式围绕单个实例研究bert空间的几何结构。将我们的方法应用于一组精心构建的针对英语歧义词的句子中,我们发现语境化空间具有实质性的规律性,即对应不同词义的区域;但在这些区域之间,偶尔会出现与任何可理解的感觉不一致的感觉空洞
687295)]
Paper url, EMNLP 2021 camera-ready version,
我们提出了一种在上下文化向量空间(特别是BERT空间)中探索单个点周围区域的方法,作为一种研究这些区域如何对应单词意义的方法。
通过在输入层中引入上下文化的伪词作为静态嵌入的替代,然后对句子中的单词进行掩码预测,我们能够以一种受控的方式围绕单个实例研究bert空间的几何结构。将我们的方法应用于一组精心构建的针对英语歧义词的句子中,我们发现语境化空间具有实质性的规律性,即对应不同词义的区域;但在这些区域之间,偶尔会出现与任何可理解的感觉不一致的感觉空洞