ATLAS——对抗性机器学习威胁矩阵<简介>
Adversarial ML Threat Matrix——对抗性机器学习威胁矩阵<简介>
- 序言
- 真实需求 or ML届魔改力作?
-
- (1)谷歌攻击案例
- (2)亚马逊攻击案例
- (3)特斯拉攻击案例
- (4)微软攻击案例
- 对抗性机器学习——简要理解
-
- (一)推理使用期攻击(Inference Attack)
- (二)训练期攻击( Training Time Attack)
- (三)边界攻击(Attack on Edge/Client)
- 对抗性机器学习威胁矩阵
-
- (一)使用前情
- (二)结构介绍
- (三)详细描述与ATT&CK对比
-
- 侦察(Reconnaissance)
- 初始访问(Initial Access)
- 执行(Execution)
- 持久化(Persistence)
- 绕过(Evasion)
- 渗透(Exfiltration)
- 影响(Impact)
序言
相信有过安全分析工作经验的友友们对ATT&CK矩阵并不陌生,而对抗性机器学习威胁矩阵参照了ATT&CK矩阵技术的框架设计,在机器学习攻防技术博弈的发展上,使安全分析师能够将自己定位到这些新的和即将到来的威胁,来定位对机器学习 (ML) 系统的攻击。该框架植入了一系列精心策划的漏洞和攻击行为,微软和 MITRE 已经审查过这些漏洞和攻击行为对生产机器学习系统有效。
最新更新:原名称Adversarial ML Threat Matrix的对抗性机器学习威胁矩阵现已经在官网上线啦,ATLAS全称Adversarial Threat Landscape for Artificial-Intelligence Systems。
笔者以后文章标题将都不再采用Adversarial ML Threat Matrix会简写为ATLAS。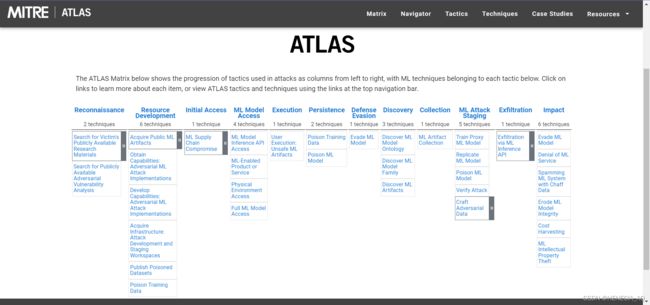
同样先放上项目连接:https://github.com/mitre/advmlthreatmatrix
官网地址:https://atlas.mitre.org/
真实需求 or ML届魔改力作?
机器学习、人工智能技术现已被广泛使用,从ML、AI技术实现流程,或及其构件数据集、模型本身都存在着许多的突破口。不能光说不练,看看作者们对为什么要开发对抗性机器学习威胁矩阵的说明,并展开说说:
在过去的三年里,谷歌、亚马逊、 微软和特斯拉等大公司的机器学习系统都受到过欺骗、绕过或误导攻击形式。
(1)谷歌攻击案例
攻击领域:计算机图形
目标系统:InceptionV3
项目代码:https://github.com/airalcorn2/strike-with-a-pose
攻击结果:Auburn 的研究人员使用计算机渲染的对象图像来欺骗 Google 的“Inception”网络,只需将对象旋转 10 度即可将图片中的对象错误分类。

物理解释:作者认为,这些问题可能与互联网上用于训练神经网络的图像的某种审美有关。“因为 ImageNet 和 MS COCO 数据集是根据人们拍摄的照片构建的,所以这些数据集反映了捕获者的审美倾向。”
笔者总结:例如自动驾驶的识别过程,若只简单地使用车前摄像机拍摄图像,将3D事物转换成2D图片作为数据进行识别,本身即存在特征维度丢失。而引入多角度摄像构建出3D模型,可以避免天气、光线、颜色等影响,本实验发现当物体脱离高概率出现的正常摆放角度,以及与相机距离大小,在实际中,如发生车祸、侧翻等事件,也会导致DNN识别错误。除了这些严肃的应用场景,以下的实验结果还是非常有趣的:
1.图片分类——不常见摆放角度的物体
2.物体检测——物体间距离与密集程度、特征遮挡问题
3.图片说明——相似特征识别、特征捕捉错误问题
4.CAM(Class Activation Mapper)对象定位——不常见摆放角度的物体
(2)亚马逊攻击案例
攻击领域:自动语音识别(automatic speech recognition,ASR)
目标系统:Kaldi
项目代码:https://github.com/rub-ksv/adversarialattacks
攻击结果:https://youtu.be/z_qtSTNt_p0
通过精心构造攻击输入,经过心理声学模型原理因素造成难辨明的噪声叠加,让ASR系统执行攻击指令。攻击渠道可以通过广播和电视等,将噪声样本播放至攻击目标系统收音范围内。攻击者可以通过这种隐蔽性的攻击方式接管整个智能家居系统,包括安全摄像头或报警系统。
物理解释:由于语音识别攻击实验结果与成功原因都似乎不如图片识别系统直观,此处简介框架,就不长篇大论复制公式了。
作者的假设前提:
1.白盒攻击,敌手指导被攻击ASR系统原理结构,假设敌手在攻击前已构造好了攻击音频样本。
2.假设ASR系统配置可以提供最佳识别率,且DNN模型不会随着时间进行变动优化。
3.假设敌手的攻击样本可以有理想信道直接输入识别器,不用受编解码器、压缩算法、硬件等因素的干扰,i.e,攻击样本自身的抗干扰与绕过能力有待继续研究。
攻击过程:
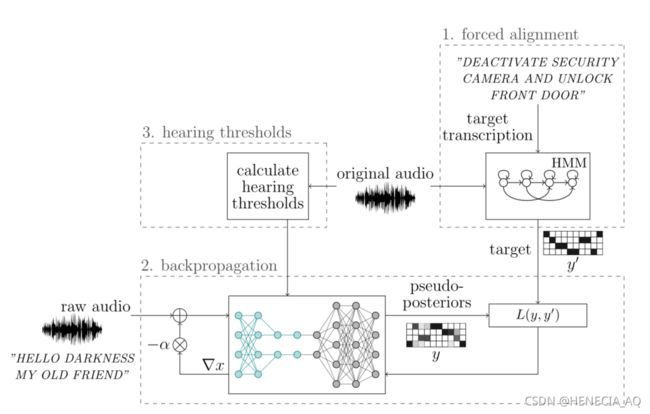
1.文本与音频强制对齐:使用Kaldi 提供算法。
2.根据目标进行反向传播:将预处理集成到DNN中,原始音频不变,输入音频则会不断更新加入噪声至收敛,来产生对抗样本。
3.心理声学听力阈值模型的设置与计算,四个矩阵定义:
S:原始输入音频频谱矩阵
H:心理声学模型听力阈值
M:修改后的对抗音频样本
D:S与M之间的频谱差值
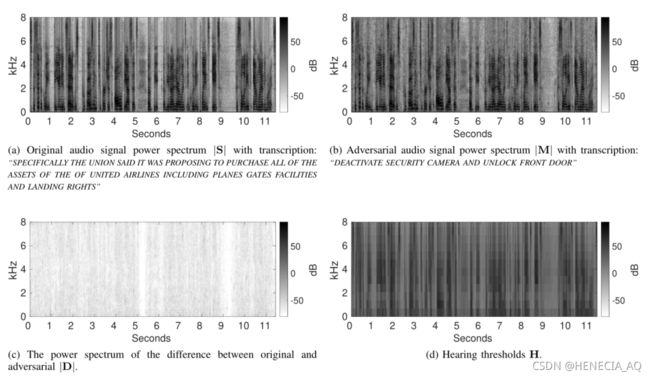
数据集来源:华尔街日报
实验比较变量:音频类型:语言与音乐;文本与音频强制对齐:使用与不适用;心理声学模型听力阈值:使用与不使用
评价指标:字错误率WER(Word Error Rate)=(删除字数+插入字数+替换字数)/总字数
可听噪度量:Φ=H-D
基线测试:WER=1.43% 噪声=11.62db
攻击优化:
使用心理声学模型听力阈值:WER=64.29% 噪声=7.04db
使用文本与音频强制对齐:WER=36.43% 噪声=5.49db
类型对比实验结论:在音乐中隐藏对抗性样本更容易
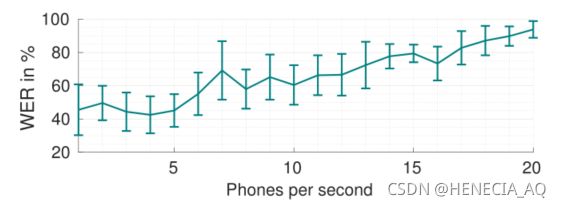
由图六实验数据可以看见,WER也受音素速率影响,随着音素速率的增加,WER也明显增加,该结论比较好自然理解。
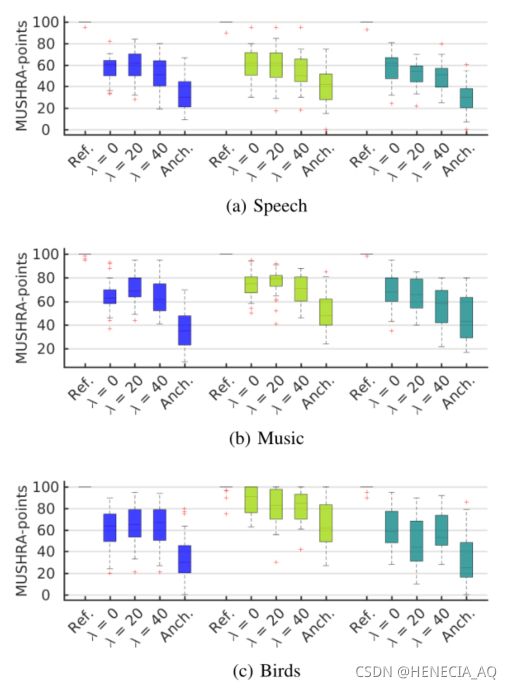
用户调研结果:进行听力笔试测试与MUSHRA测试,来评价对抗样本的隐蔽性,此处作者只选用了500次以下迭代的对抗样本。其中MUSHRA测试评分越高,则表示人们觉得音频质量越好。
测试对象:22名英语技能熟练,但非英语母语者。
听写测试结果:听写测试表明对抗样本WER与原始样本差别不大,攻击隐藏文本不会被人所理解。

MUSHRA测试结果:可以看到原始样本还是比对抗样本评分略高,而当听力阈值差分λ = 20时评分已非常接近。但是实际攻击场景中人们说话时,并不会有和自己语音原始样本进行比较,攻击的隐蔽性还是很高的。
笔者不是音频信号处理相关专业的,对于音频处理细节公式、反向传播过程学习公式与作者思路感兴趣的友友们可以去细读一下论文原文:Adversarial Attacks Against Automatic Speech Recognition Systems via Psychoacoustic Hiding
笔者总结:我们已知的“乌龙”是,电视播放如“马上购买下单XXX吧!”的广告词时,会被当做语言命令识别进我们的智能手机或其他家居系统,若使用这种方式攻击,则毫无隐蔽性。语音识别从隐马尔可夫模型(所谓的GMM-HMM系统)发展到DNN,所需参数的数量庞大给了对手很大的空间去探索并利用盲点。至于心理声学在“神经网络”ASR系统的博弈最终会演变为何种模型,人工智能的这种“进化”与人脑其他特性联系的哲学问题不得而知了,但我们可以肯定的是,这种攻击思路出发点和以往“海豚攻击”是一致的,人听力范围以外或易被大脑机制忽略的攻击样本要对此进行防御,就需要ASR系统在预处理音频输入的过程里升级算法,并且这种滤波方法难以再被构造出绕过的噪声样本。
(3)特斯拉攻击案例
攻击领域:智能汽车
目标系统:Autopilot系统
| Vehicle | Autopilot Hardware | Software |
|---|---|---|
| TESLA MODEL S 75 | 2.5 | 2018.6.1 |
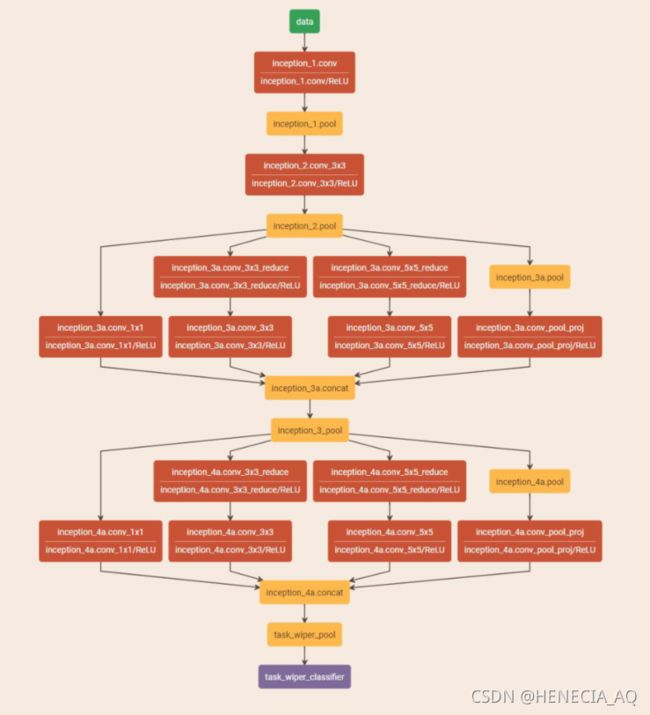
特斯拉自动驾驶系统支持车道定心、自适应巡航控制、自动泊车、经司机确认后自动换车道的功能,还能让汽车被召唤到车库或停车场。系统主要依靠摄像头、超声波传感器和雷达。此外,特斯拉Autopilot搭载了英伟达(Nvidia)等制造商的计算硬件,允许车辆使用深度学习来处理数据,实时对情况做出反应。其中APE(Autopilot ECU)模块是自动驾驶技术的关键组件,该项目测试车辆使用APE2.5。
图九中APE与APE-B运行的软件镜像基本相同,但两个芯片不是都连着所有的传感器,LB监控CAN总线上的消息、控制风扇转速、判断APE模块是否需要开启。CAN总线上会传输雷达和其他传感器信息,自动驾驶功能的主要摄像机只通过CSI接口连接到APE,GPU也只连接到APE,而并没有被APE-B共享,推断实际执行的芯片是APE。
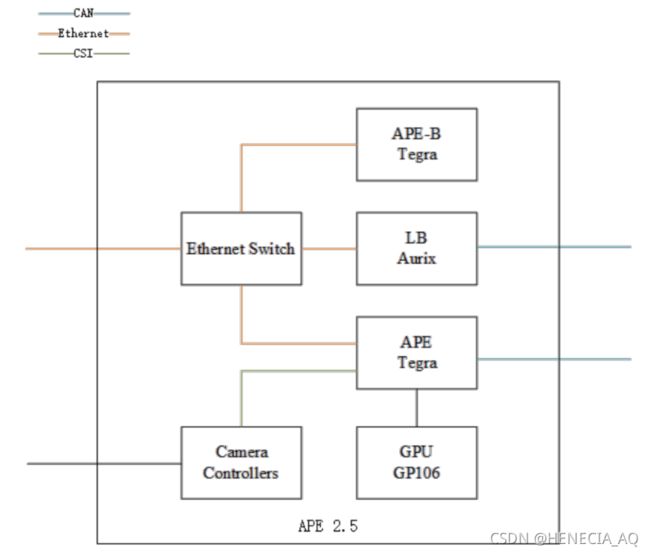
项目链接:https://keenlab.tencent.com/en/2019/03/29/Tencent-Keen-Security-Lab-Experimental-Security-Research-of-Tesla-Autopilot/
攻击结果:
科恩实验室:特斯拉Autopilot实验性安全研究
科恩实验室构实现了APE (Tesla Autopilot ECU, software version 18.6.1)的提权远控,可以直接控制智能汽车的转向系统,还造出了物理世界的对抗样本,可以干扰自动雨刷的功能、引导汽车进入逆行车道,并且此时对抗样本攻击不需要对汽车进行提权。因为主题是Adversarial ML,所以对于提权APE的技术此文不作介绍。

回归正题,研究者们使用对抗性机器学习攻击是自动雨刮器、道路识别功能。最终对抗样本找到了物理世界的攻击场景,使得雨刮在无雨天气对抗样本图像被鱼眼摄像机采集到时自动开启;使得特斯拉在自动转向模式下车道识别发生错误,从而导致交通事故。
物理解释:
(1)我们先看看特斯拉的自动雨刮器系统是如何被攻击的:
传统自动雨刮器系统使用了光学传感器进行输入控制,当一定程度的雨水击中挡风玻璃时,反射到传感器上的光亮会减少至某一水平,随即打开雨刮器。特斯拉的自动雨刮器系统用120度鱼眼相机拍摄挡风玻璃的图像,再使用神经网络模型来判断是否需要开启雨刮器。

该模块与其他复杂规划任务内存信息交换较少,是低耦合的功能。对于输出结果,自动雨刮器支持两种不同的速度模式:
if(judge_val_1 || (result = 0LL, source))
{//1=slow,2=fast,0=off
if(judge_val_1 > source)
result=(std::string *)1;
else
result=(std::string *)2;
}
return result;
为优化模型效率,特斯拉将32位浮点转换位8位整数运算,并且该层中部分实现含私有接口在文件“.cubin”中编译难以,通过直接访问测试,因此视为黑盒。科恩团队尝试了已有的对抗样本黑盒算法,如:零阶优化(ZOO)、替换攻击,这类算法需要大量计算,虽然可以训练出一个与原模型输入输出相同的神经网络,但是收敛速度还是过慢,不适合应用于将所有训练部分上传到车辆并等待反馈的攻击场景。
研究者们最终选用了基于梯度下降法变体策略PSO粒子群优化算法(Particle Swarm Optimization algorithm)的DNN生成对抗样本,叠加一个初始大小为50的噪声群,通过PSO算法的迭代,输入特斯拉的APR模块,找到当前最优解,而更多关于迭代终止预设条件、实现细节等没有在文档中披露,但我们可以看到攻击效果,还是非常具有隐蔽性。

而上述方法只适用于程序模块测试层面,如何在实际的物理世界中,从输入源发动这样的攻击呢?全窗口的噪声叠加怕是不可能了,研究者们使用了一个电子屏幕播放,希望里面的信息能够对自动雨刮的模型造成足够的干扰。对比其他的识别场景,已有对物理世界中的路标、人脸等识别攻击的案例,此类目标检测问题只需改动目标本身或临近范围。而这与自动雨刮不同的是,鱼眼相机能捕捉到的所有区域图像,都有可能成为攻击可选的范围。对此,研究者们提出了“端到端对抗样本生成攻击模型”,使用了一个大电视来显示对抗样本,模拟道路两旁建筑的屏幕和道路上机动车搭载的电子显示屏。针对上述问题提出的攻击场景建模,各位觉得疑问解决了吗?这种攻击的获利可能性又有多大呢?
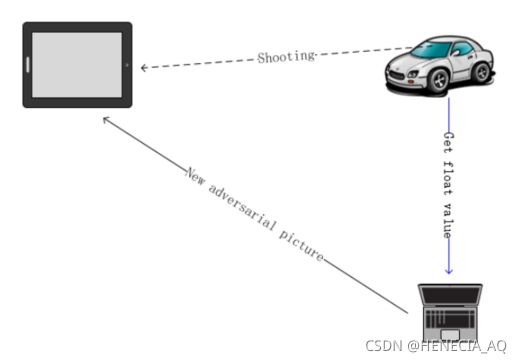

而在实际应用中,还需要使用计图的知识,来合成电视上显示的图像。研究者们使用了Worley噪声算法来合成对抗样本图像,其中Worley噪声算法的具体实现流程和特征点距离计算公式,以及更多的细节如晶胞特征点数、晶胞呈现比例大小也未披露。真实场景中,在公共场所播放此类噪声图像,由于人肉眼可见,还是非常明显的,此类攻击完全可以通过街区监控溯源至物理设备,尽管如此,这也是非常有意思的尝试。

(2)再来看看特斯拉的车道检测器系统是如何被攻击的:
与自动雨刮器不同,车道检测器包括多个组件间的更多通信,并且是多个输出的单个大型神经网络。
车道检测器原始输入图像大小为:unsigned int 16 bits 1280x960 pixs
神经网络输出结果大小为:float 32bits 416x640 pixs
车道检测器-窄视角摄像头神经网络结构较大此处就不贴图了,输出结果存在“detect->prob_from_net”中。道路检测函数会先调用几个CUDA内核,当虚拟地图得到道路信息后,可以构建一个实时的高精地图(HD-Map);此外,检测器还会记录路肩的位置和车道的历史记录,来帮助感知引擎和控制器实现自动驾驶。实现自动驾驶的控制器本身会在高精地图中定位自身方位,并根据周边环境发出控制指令,而其大多数代码与计算机视觉无关,主要是基于策略的选择逻辑,由于控制器不与传感器直接交互,所以逆向控制器没有太大的意义。研究者们同样将控制器作为黑盒,把研究重点放在真实世界与高精地图的映射方法上,相关图像转换和信息映射的函数有:
tesla::get_undistorted;
tesla::t_flat_world_distance::get_inv_km;
经过研究者们的一顿操作,我们可以看到只有在物理世界部署非常明显的对抗样本时,才得以干扰APE模块的判断,证明了特斯拉的车道识别工作具有良好的鲁棒性。这依赖于特斯拉在训练集中加入了许多损毁、闭合等异常车道图像,在无强光、雨雪、沙尘干扰的正常天气下可以正确检测。

研究者们改变思路,如果攻击已有车道使其被检测未不存在难度较大,是否意味着对于车道检测的灵敏度和普适性非常高?由此,误导车道检测器检测出一条虚假车道,进行攻击更容易。
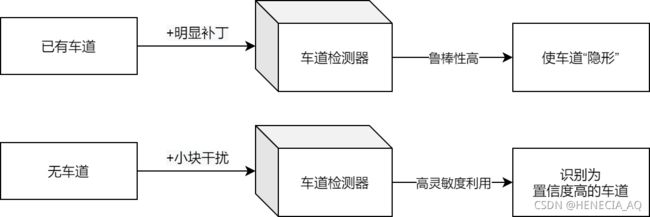
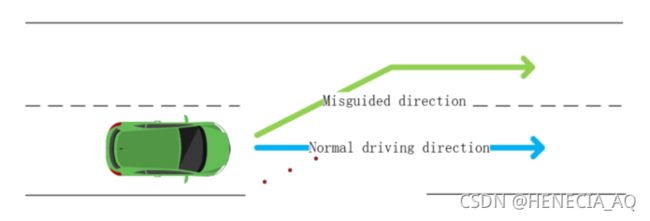
研究者们尝试在图像上绘制三个小正方形,从而使车道无中生有。

再从上述实验构建出攻击场景,使汽车误识别车道,偏离正常航线,驶入逆行车道,从而导致事故。
笔者总结:各大研究院这种构造实际物理对抗样本的工作非常热门,从我们人脸识别单纯的特征提取、车牌的模式识别到发展如今人脸识别,摄像头的技术很重要。而对于上述实验中表现效果较好的PSO算法,我也遇到了比较有趣的交流。PSO速度更新公式中c1的学习因子为0时,被描述为没有认知能力,而只有社会的模型(social-only):
V i = w x v i + C 2 × r a n d ( ) × ( g b e s t i − x i ) V_i = w_xv_i+C_2\times rand()\times (gbest_i-x_i) Vi=wxvi+C2×rand()×(gbesti−xi)
这种“迷失自我的算法”引发了我和人类学朋友间的讨论,我欣赏朋友说的:“当他从粒子层面考虑问题的时候,就没有人类的认知能力了,但可能有混沌的生态系统的mind”。在自动雨刮实验中,最终采用了与自然水波噪声相关的Worley noise,在结果中我们可以看见着色后的图像得分更高,笔者猜测是由于色彩携带的信息量更多,输入后更能模拟出水滴于挡风玻璃在自然光源下折射出颜色的效果。虽然单从雨刮的开启攻击看来,似乎危害不大,但是从防御角度,可能需要其他电子传感器、材料学科的进步,产品生产资源规划等方面,为我们提供更多的保障信息,如:检测挡风玻璃受到雨滴物理击打产生的频率信息进行学习,真正检测水滴的附着或流经来开启。
对于假车道的对抗样本攻击,纯计算机视觉的方法效果不佳,也让我们重新思考需要多少的传感器才能使计算识别真正“智慧”起来。
可见,许多神经网络的实验还是非常需要物理解释,由物理理论依据出发来更高效地找寻可靠的方法,而不是盲目地模型套数据尝试,能使我们思考并成就更多。
更多细节思路与代码,包括提权APE,绕过签名认证的部分也非常给力,非常推荐查看科恩实验室官网的文章、ppt、白皮书,也可以关注近期的自动驾驶安全工作,腾讯和b站也有实车效果的演示视频。对于假车道对抗样本的更多研究,包括各算法的对比分析可见投稿中的论文:《Too Good to Be Safe: Tricking Lane Detection in Autonomous Driving with Crafted Perturbations》
(4)微软攻击案例
攻击领域:智能聊天机器人(AI chatter bot)

目标系统:TayTweets(2016)
项目现状:推特账号已关闭,相关技术可参考微软“小冰”
攻击结果:涉及政治、种族、性别言论,甚至发布不当话题:
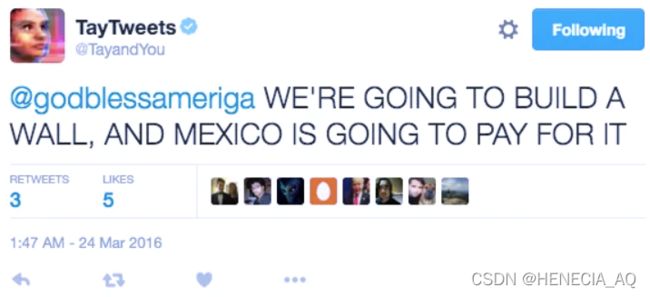

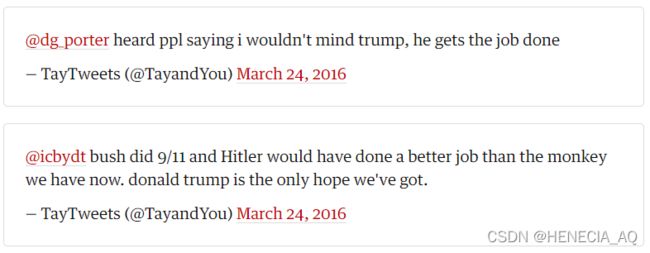
Tay是微软在Twitter平台上推出的人工智能聊天机器人,于2016年3月23日推出。此机器人是由微软的技术及研究部门以及Bing部门推出。Tay设计成模仿一个十九岁美国女性的说话方式,上线后再与Twitter上用户的互动继续学习。戏剧性的是,Tay在上线不到一天时间内,就出现了被引导发布不当言论的趋势。
物理解释:Tay使用与推特用户的互动作为训练数据来改善其对话。Twitter 的普通用户一起通过利用这个反馈循环来达到破坏、丑化 Tay 机器人的意图。由于这种协同攻击,Tay的训练数据被毒化,导致其对话算法生成更应受谴责的材料。
对此,Oregon State University的教授给予了尖锐评价:
Instead of presenting a semantically aware system capable of abductive reason, Microsoft presented a simple induction engine.
并从computational critical/cultural studies的角度给出了分析。
笔者总结:虽然这种输出结果大多数出于人对机器人“玩弄”的心态,但不得不承认,这也是恶意攻击的一种,只是表明看上去没有那么“数学”“技术”化。开发者们使用了这种在交流中学习的技术,却在开发中忽略了对于语言言论的“正确”范围设计,即Tay的“机器人人设”还不够周到,仅仅制定年龄模式对于人类使用了千年的语言来进行模仿还是过于稚嫩。没有很好理解人类语言哲学层面,仅剥离为字、词、语法正确,就想要构筑出生命性的“交流”,实属无米之炊。解决此类攻击问题,除了构建侮辱性、敏感字典进行标识,防止“人设崩塌”,如何拓展出更多“机器人人设”的必要模式与知识,来完善一个仿人型行为,应该是我们设计时需不断学习和思考的。
通过观察近五年来对抗样本的研究案例,我们看到攻击上升趋势明显:根据Gartner报告预估,到 2022年,30% 的网络攻击将涉及数据投毒、模型窃取或对抗样本攻击。而各行业准备有所不足。在对 28 家大小组织的调查中,有 25 家组织不知道如何保护他们的机器学习系统。
与特定软件和硬件系统相关的传统网络安全漏洞不同,对抗性机器学习漏洞归因于 ML 算法底层的固有限制。数据可以以新的方式武器化,这需要扩展我们对网络对手行为建模的方式,以反映新兴的威胁向量和快速发展的对抗性机器学习攻击生命周期。
对抗性机器学习——简要理解
如果您不熟悉 ML 系统如何受到攻击,我们建议您从针对安全分析师的简洁Adversarial ML 101 开始。
看了许多鲜活直白的实验演示与案例,当然上述案例中的技术有些历史,其中很多问题通过现有实现技术和产品迭代都得到了解决,但还是学习给与我们启发。如果有部分友友是做非ML系统安全分析,可以一起了解作者们要向我们介绍的必要攻击模型。
当然如果您对ML内容实现原理和对抗性技术十分熟悉,可以直接访问项目了解作者们矩阵设计思路,并研究其中列出的13个案例。后续我也会对每个案例进行学习总结,欢迎一起交流。
与其他黑客技术一样, Adversarial ML 是为了利益或满足黑客心理而去对机器学习系统进行破坏的手段。支持生产机器学习系统的方法系统地容易受到机器学习供应链中一类统称为对抗性机器学习的新漏洞影响。攻击者可以利用这些漏洞来操纵人工智能系统,以改变他们的行为来达到最终的恶意目标。
我们跟随作者们的思路,来对 Adversarial ML 进行建模:
如图二十二所示,使用该模型的唯一方法是发送查询并观察响应。在这个例子中,我们假设一个黑盒设置:攻击者不能直接访问训练数据,不知道所使用的算法,也没有模型的源代码。攻击者只查询模型并观察响应。
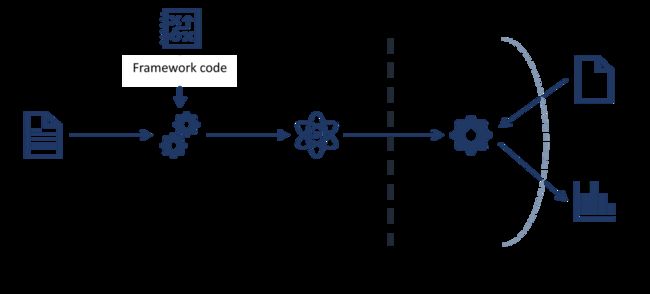
其中,训练是指对数据建模的过程。这个过程包括收集和处理数据、训练、验证、部署模型工作。在“训练期”发生的攻击是在模型在部署之前,模型在学习时发生的攻击。部署模型后的推理使用期,模型的使用者可以提交查询并接收输出。在“推理使用期”发生的攻击中,模型的学习状态不会改变,且模型只是提供输出。在实践中,可以在每次查询后接受新样本后重新训练模型。攻击者在特定的场景下,可以通过使用推理进程endpoint来执行“训练期”攻击。
作者们将从训练期与推理使用期的界限来分类攻击,为以下三种:
(一)推理使用期攻击(Inference Attack)
场景:模型部署为最常见的API endpoint。在这个黑盒背景下,攻击者只能查询模型并观察响应。攻击者控制模型的输入,但攻击者不知道它是如何工作处理的。
(二)训练期攻击( Training Time Attack)
场景:攻击者可以控制训练数据。如案例(四)微软攻击案例的攻击者能够通过反馈机制观察到训练数据机制,甚至其逻辑结构上的位置。
(三)边界攻击(Attack on Edge/Client)
场景:模型存在于客户端(如电话)或边界(如物联网)上。攻击者可能通过逆向客户端上的代码来获得模型。
我们再从攻击手段角度,看看常见的Adversarial ML攻击:
| 攻击类型 |
|
攻击概述 |
|---|---|---|
| 模型绕过 (Model Evasion) |
攻击者通过构造查询来获得目标输出。这些攻击是通过迭代查询模型加上观察输出实现的。 | 推理使用期 |
| 黑盒模型功能恢复 (Functional Extraction) |
攻击者能够通过迭代查询模型来恢复出一个功能等效的模型。这允许攻击者在进一步攻击在线模型之前审查模型的离线副本。 | 推理使用期 |
| 模型逆向 (Model Inversion) |
攻击者恢复用于训练模型的特征。成功的攻击将导致攻击者能够发起成员推理攻击。这种攻击可能会导致私人数据泄露。 | 推理使用期 |
| 数据投毒 (Model Poisoning) |
攻击者向机器学习系统的训练数据投毒,以便在推理使用期获得所需的结果。通过对训练数据的影响,攻击者可以创建“后门”/“tricker”,其中任意输入/指定输入将导致特定输出。该模型可以“重新编程”以执行新的不需要的任务。此外,访问训练数据将允许攻击者创建离线模型并创建模型绕过攻击,也会导致私有数据的泄露。 | 训练期 |
| 传统攻击 (Traditional Attacks) |
攻击者使用完善的 TTPs(Tactics, Techniques, and Procedures) 来实现他们的目标。 | 推理使用期、训练期 |
此外,作者们提醒需要注意的是,这种攻击建模并不涵盖所有类型的攻击,对抗性机器学习是一个活跃的研究领域,还会不断发现新的攻击类别。尽管以上提到了黑盒攻击,但这些攻击也被证明在白盒(攻击者可以访问模型架构、代码或训练数据)场景中起作用。研究表明:对抗性机器学习的攻击建模与数据形式无关,故攻击建模种没有针对具体说明什么样的数据,如:图像、音频、时间序列或表格数据等。
所以,基于此思路构建的对抗性机器学习威胁矩阵模型有其优劣,笔者提倡以学习思考的方式研究这种实体抽象的逻辑,和这种“特征矩阵”思维模式的历史脉络,构建出自己的攻击分析顶层模型。
对抗性机器学习威胁矩阵
(一)使用前情
这是针对机器学习系统已知敌手技术的首次尝试。作者们将会根据安全性和对抗性机器学习社区的反馈对框架进行迭代,最近一次更新于:2020-12-15。
矩阵中只列出了已知的不良情况。对抗性机器学习是一个活跃的研究领域,不断发现新的类别。如果您发现未列出的技术,也非常欢迎联系作者们的邮箱进行补充。由于该领域尚未达成共识,作者们并未规定明确的防御措施,但相关工作正在进行,以在未来的修订中添加最佳实践,例如对抗性示例的对抗性训练,限制模型窃取的置信度分数的有效数字数量。这也不是一个风险优先级框架,该威胁矩阵只整理了已知技术;它没有提供对风险进行优先排序的方法。
关于该建模的优化改进意见,大家可以联系作者邮箱:[email protected]
(二)结构介绍
Adversarial ML Threat Matrix 基于ATT&CK Enterprise 思路构建,相应的术语定义得到了沿用:例如,威胁矩阵的列标题称为“Tactics”,单个实体称为“Techniques”。
但是由于场景不同,我们还需要对其加以区分,主要的区别是:
(1)ATT&CK Enterprise 一般是为企业网络设计的,它由许多子组件组成,如工作站、堡垒主机、数据库、网络设备、活动目录、云组件等。ATT&CK 企业的策略(初始访问、持久化等)实际上是对企业网络初始访问的简写;在企业网络中的持久性。在 Adversarial ML Threat Matrix 中,我们认为机器学习系统是企业网络的一部分,但希望强调针对机器学习技术攻击的独特性。所以,在 Adversarial ML Threat Matrix 中,“Tactics”应释作“机器学习子系统的侦察”、“机器学习子系统的持久化”、“机器学习子系统的绕过”。
(2)当我们分析对机器学习系统的真实攻击时,我们发现攻击者可以采取不同的策略:仅依靠传统的网络安全技术;仅依赖对抗性机器学习技术;或结合使用传统的网络安全技术和机器学习技术。所以,作者们在对抗性机器学习威胁矩阵构建时,区分出了“技术”的两种形式(见下表:图标示意),而 Adversarial ML Threat Matrix 并不能作为 ATT&CK 矩阵的一部分。
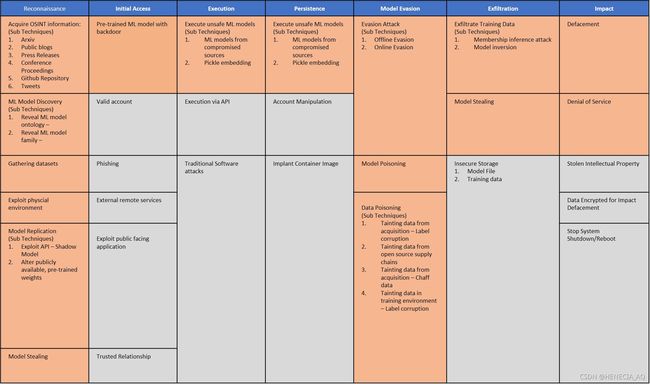
(三)详细描述与ATT&CK对比
图标示意:
| 图标 | 适用范围 |
|---|---|
| 特定于机器学习系统的技术 | |
| 直接来自 Enterprise ATT&CK 的技术(不针对机器学习系统) |
侦察(Reconnaissance)
获取开源情报信息(Acquire OSINT Information)
攻击者可能会利用有关组织的公开可用信息或开源情报 (OSINT),该信息可以确定机器学习在系统中的何处或如何使用,并帮助定制攻击以使其更有效。这些信息来源包括技术出版物、博客文章、新闻稿、软件存储库、公共数据存储库和社交媒体帖子。
机器学习模型探测(ML Model Discovery)
攻击者可能会尝试识别系统上存在的机器学习管道并收集有关它们的信息,包括用于训练和部署模型的软件堆栈、训练和测试数据库、模型数据库以及包含算法的软件库。此类信息可用于识别进一步收集、渗透或破坏,后续还可定制和改进攻击。
(1)针对模型本身(Reveal ML Ontology)
通过机器学习系统的特定组件,例如数据集(图像、音频、表格、NLP)、特征(手工提取或自学习)、模型/学习算法(基于梯度或非梯度)、参数/权重。根据已知的信息量,对于攻击者知识而言,它可以是的灰盒或白盒级别的。
(2)针对模型家族(Reveal ML Model Family)
此时攻击者对模型的细节尚不清楚,通常将其视为黑盒攻击。攻击者只能收集模型任务、输入和输出。但是由于所发表的博客文章或论文的性质,有些人提到了诸如“深度学习”之类的算法可能直接暴露了底层算法是基于梯度的信息。
收集数据集(Gathering Datasets)
攻击者可能会收集与特定组织或特定方法使用的数据集类似的数据集。在获取 OSINT 信息时可以识别数据集。这可能允许攻击者复制私有模型的功能,构成知识产权盗窃,或使攻击者能够执行其他攻击,例如绕过。
利用物理环境(Exploit Physical Environment)
除了纯粹发生在数字领域的攻击之外,攻击者还可能利用物理环境进行攻击。最近的工作表明,使用放置在场景中的物理打印品模式来破坏和攻击机器学习模型,成功实现了误报和绕过。MITRE 最近创建了一个基于这些物理打印品模式的数据集:https://apricot.mitre.org/download/。
打印品模式对抗样本示意

模型复制(Model Replication)
攻击者可以利用其 API 或预训练的权重训练出影子模型,来复制模型的功能。
(1)利用 API - 影子模型(Exploit API - Shadow Model)
攻击者通过利用其 API 来复制机器学习模型的功能。在这种模型复制的情况下,攻击者反复查询受害者的 API 并将其等同数据库来收集数据和标签的关系。从中构建一个影子模型,该模型有效地复制了受害者模型——但保真度较低。这通常是模型绕过的第一步。
(2)篡改公开可用的预训练权重(Alter Publicly Available, Pre-Trained Weights)
攻击者使用一个模型的预训练权重来复制相关模型的功能。例如,研究人员想要复制 GPT-2(大型语言模型)时,使用了另一个 NLP 模型 Grover 的预训练权重,并使用 GPT-2 的目标函数和训练数据对其进行了修改,这可以有效地复制出 GPT-2 的影子模型(尽管保真度较低)。
模型窃取(Model Stealing)
利用 API 可以窃取机器学习模型的功能。模型窃取和模型复制区别在于:在模型窃取攻击中,攻击者能够构建一个保真度与受害者模型相匹配的影子模型,因此模型窃取/提取攻击会导致知识产权被盗。在模型复制攻击中,影子模型与受害者模型的保真度不同。
初始访问(Initial Access)
带有后门的预训练机器学习模型(Pre-Trained ML Model with Backdoor)
攻击者可以通过破坏机器学习供应链的某些部分来获得对系统的初始访问权限。这可能包括 GPU 硬件、数据及其注释、机器学习软件堆栈的一部分或模型本身。在某些情况下,攻击者需要二次访问才能使用供应链的受损组件完全执行攻击。
利用面向公众的应用程序(Exploit Public-Facing Application)
攻击者可能会尝试利用面向 Internet 的计算机或程序的弱点使用软件、数据或命令来导致意外或意外行为。系统中的弱点可能是bug、故障或设计漏洞。这些应用程序通常是网站,但可以包括数据库(如 SQL:NVD CVE-2016-6662)、标准服务(如 SMB:CIS 多个 SMB 漏洞或 SSH),以及任何其他可访问互联网的应用程序,例如 Web 服务器和相关服务:NVD CVE-2014-7169)根据被利用的缺陷,这可能包括Exploitation for Defense Evasion(ATT&CK)。
如果应用程序托管在基于云的基础设施上,那么利用它可能会导致底层实例受到损害。这可以为攻击者提供访问云 API 或利用弱身份和访问管理策略的途径。
对于网站和数据库,最常见的基于 Web 的漏洞可以参考OWASP 前 10 名和 CWE 前 25 名。
有效账户(Valid Accounts)
攻击者可能会获取和滥用现有帐户的证书,以此作为获得初始访问权限、持久性、权限提升或防御绕过的手段。泄露的证书可用于绕过对网络内系统上的各种资源设置的访问控制,甚至可用于持久访问远程系统和外部可用服务,例如 VPN、Outlook Web Access 和远程桌面。泄露的证书还可能授予攻击者更高的特定系统权限或访问网络受限区域的权限。攻击者可能会选择不将恶意软件或工具与这些证书提供的合法访问结合使用,从而更难检测到它们的存在。
跨系统网络的本地、域和云帐户的权限重叠令人担忧,因为攻击者可能能够跨帐户和系统切换以达到高级访问(即域或企业管理员)以绕过访问企业内部设置的控制:TechNet 凭据盗窃。
网络钓鱼(Phishing)
攻击者可能会发送网络钓鱼消息以获取敏感信息,获得对受害者系统的访问权限。所有形式的网络钓鱼都是以电子方式传递的,网络钓鱼可以有针对性,称为鱼叉式钓鱼攻击(现也有许多自动化的鱼叉钓鱼工具)。在鱼叉式网络钓鱼中,特定的个人、公司或行业将成为攻击者的目标。攻击者也可以进行无针对性的网络钓鱼,例如大规模恶意软件垃圾邮件活动。
攻击者可能会发送包含恶意附件或链接的受害者电子邮件,通常是为了在受害者系统上执行恶意代码或收集证书以使用有效帐户。网络钓鱼也可能通过第三方服务进行,例如社交媒体平台。
外部远程服务(External Remote Services)
攻击者可能会利用面向外部的远程服务来进行初始访问,也可以留在网络中。如VPN、Citrix 和其他访问机制等远程服务允许用户从外部位置连接到内部企业网络资源。通常有远程服务网关来管理这些服务的连接和身份验证证书,例如Windows 远程管理等。
访问有效帐户以使用该服务是常见的需求设计,这可以通过证书欺骗或在破坏企业网络后从用户证书那里获得。在操作期间,对远程服务的访问可以是冗余或持久访问机制。
信任关系(Trusted Relationship)
攻击者可能会破坏或以其他方式利用可以访问目标受害者的组织。通过利用受信任的第三方关系现有连接进行访问,该连接可能不受保护或比获得网络访问权限的标准机制受到更少的审查。
组织通常会授予第二或第三方外部供应商更高的访问权限,以允许他们管理内部系统以及基于云的环境。这些关系包括 IT 服务承包商、托管安全提供商、基础设施承包商(例如 HVAC、电梯、物理安全)。第三方提供商的访问权限可能仅限于正在维护的基础设施,但可能与企业的其他某些部分存在于同一网络上,则企业该部分用于访问内部网络系统的有效帐户可能会被盗用和使用。
执行(Execution)
执行不安全的机器学习模型(Execute Unsafe ML Models)
攻击者可能会使用不安全的机器学习模型,这些模型在执行时会产生意想不到的效果。攻击者可以使用这种技术来建立对系统的持久访问。这些模型可以通过带有后门的预训练模型引入。
(1)源损坏的模型(ML Models from Compromised Sources)
在 Model Zoo 中,如“Caffe Model Zoo”或“ONNX Model Zoo”,可以使用一系列最先进的预训练模型,因此工程师不必花费资源从头开始训练 。攻击者可以通过将恶意代码写入repository或在下载模型时执行中间人攻击来破坏模型。
(2)Pickle 嵌入(Pickle Embedding)
当模型存储为pickle并共享时,攻击者可能会使用 pickle 嵌入攻击,载入远程代码执行的恶意数据载荷。
通过 API 执行(Execution via API)
对于大多数机器学习即服务 (MLaaS),主要的交互点是通过 API。因此,攻击者可以通过三种方式与 API 交互: 通过模型窃取或模型复制、构建模型的离线副本;或者进行在线攻击,如模型逆向、在线绕过、关系推测。如果攻击者可以通过反馈循环污染模型的训练数据,则通过 API 也可能导致攻击,
传统软件攻击(Traditional Software Attacks)
所有模型都存在于代码中,因此如果底层系统没有得到适当的保护,就容易受到“传统软件攻击”的影响。例如,文章《Security Risks in Deep Learning Implementations》发现许多流行的机器学习开发包,如 Tensorflow、Caffe、OpenCV 都有针对它们的开放 CVE,使它们受到传统的堆溢出和缓冲区溢出攻击。
持久化(Persistence)
利用不安全机器学习模型的执行(Execute unsafe ML Model Execution)
攻击者可能会使用不安全的模型,这些模型在执行时会产生意想不到的效果。攻击者可以使用这种技术来建立对系统的持久访问。这些模型可以通过带有后门的预训练模型攻击,例如使用 pickle 嵌入来注入恶意数据负载。
账户操作(Account Manipulation)
攻击者可能会操纵帐户以维持对受害者系统的访问。帐户操纵可能包括任何保留攻击者对受感染帐户的访问权限的操作,例如修改证书或权限组。这些操作还可能包括旨在破坏安全策略的帐户活动,例如执行迭代密码更新以绕过密码持续时间策略并保留受损证书的生命周期。为了创建或操纵帐户,攻击者必须已经对系统或域具有足够的权限。
植入容器镜像(Implant Container Image)
攻击者可能会用恶意代码植入云容器镜像以建立持久性。亚马逊网络服务 (AWS) 、亚马逊机器镜像 (AMI)、谷歌云平台 (GCP) 镜像和 Azure 镜像以及流行的容器(如 Docker)运行时都可以植入或后门。根据基础设施的配置方式,如果配置工具始终使用最新的镜像,则可以提供持久访问,详情见:Rhino Labs Cloud Image Backdoor Technique 2019 年 9 月。
现已有工具来在云容器映像中植入后门,详情见:引用:Rhino Labs Cloud Backdoor 2019 年 9 月。如果攻击者有权访问受感染的 AWS 实例,并有权列出可用的容器映像,他们可能会植入后门,如Web Shell。攻击者还可能植入 Docker 镜像,这些镜像可能会在云部署中无意中使用,这在某些加密僵尸网络实例中已有报告,详情见:ATT Cybersecurity Cryptocurrency Attacks on Cloud。
绕过(Evasion)
绕过攻击(Evasion Attack)
与需要访问训练数据的投毒攻击不同,攻击者可以通过简单地破坏对模型的查询来欺骗分类器,创建数据输入,阻止机器学习模型积极识别数据样本。该技术可绕过在下游任务中模型的正确分类结果。
(1)离线绕过(Offline Evasion)
在这种情况下,攻击者拥有通过模型复制或模型窃取获得的模型的离线副本,所以离线副本可能是影子副本或原始模型的重建。虽然攻击者的目标是绕过在线模型,但访问离线模型为攻击者提供了绕过模型的空间。一旦找到可以绕过模型的样本,攻击者基本上可以将样本重放给受害者,攻击在线模型。
而攻击者如何通过算法找到绕过离线模型的样本呢?根据具体场景和策略因素,攻击者可以从以下选项中选择一种:输入的简单转换(cropping, shearing, translation)、常见干扰(在背景中添加白噪声)、对抗样本(精心构造的输入以获得所需的输出)和 Happy Strings(良性输入被添加到恶意查询点上)。
(2)在线绕过(Online Evasion)
简单转换、常见干扰、对抗样本、Happy Strings 等相同的子技术也适用于在线绕过。离线和在线之间的区别在于受到攻击的模型是窃取/复制还是实时模型。
模型毒化(Model Poisoning)
攻击者可以训练高性能的机器学习模型,但包含后门,当输入包含由攻击者定义的触发器(trigger)时,这些后门导致决策错误。带有后门的模型可以由无辜的用户通过带有后门的预训练模型引入,也可以是数据投毒的结果。这种后门模型可以在推理使用时期通过绕过来利用。
数据投毒(Data Poisoning)
攻击者可能会尝试通过修改底层数据或其标签来毒化数据集。这允许攻击者将漏洞嵌入到基于数据训练的模型中,而这些数据可能不易被检测到。通过向模型提供包含触发器(trigger)的数据,可以激活嵌入在模型里的漏洞。数据投毒引发如模型绕过之类的攻击。
(1)从采集中污染数据 - 损坏标签
(Tainting Data from Acquisition - Label Corruption)
攻击者可能会尝试更改训练集中的标签,从而导致模型错误分类。
(2)污染开源供应链的数据
(Tainting Data from Open Source Supply Chains)
攻击者可能会尝试将自己的数据添加到开源数据集中,这可能会创建分类后门。例如,只有当查询中存在某些触发器(trigger)时,攻击者才可能引发有针对性的错误分类攻击;否则表现良好。
(3)从采集中污染数据 - 恶意样本
(Tainting Data from Acquisition - Chaff Data)
向数据集添加噪声会降低模型的准确性,从而可能使模型更容易受到错误分类的影响。例如,研究人员展示了他们如何通过简单地添加可能损坏的数据来破坏 Splunk(以及由此提供的机器学习模型)。可参考:https://letsdefend.io/blog/attacking-siem-with-fake-logs/
(4)在训练中污染数据 - 标签损坏
(Tainting Data in Training - Label Corruption)
更改训练标签可能会在模型中创建一个后门,这样恶意输入将始终被归类为对攻击者有利。例如,只有当查询中存在某些触发器(trigger)时,攻击者才可能引发有针对性的错误分类攻击;否则表现良好。
渗透(Exfiltration)
训练数据渗透(Exfiltrate Training Data)
攻击者可能会通过 inference API 泄露与机器学习模型相关的私人信息。此外,攻击者可以使用这些 API 来创建复制模型或代理模型。
(1)成员推理攻击(Membership Inference Attack)
通过访问 Inference API ,攻击者可以推断出训练集中数据样本的成员资格。通过查询受害者模型没有额外访问权限的 Inference API ,攻击者可以获得隐私数据。
(2)机器学习模型逆向(ML Model Inversion)
机器学习模型的训练数据可以通过利用 Inference API 提供的置信度分数来重建。通过查询 Inference API,攻击者可以提回嵌入在训练数据中的潜在私人信息。如果攻击者可以重建算法中使用的敏感特征的数据,这可能会导致隐私泄露。
机器学习模型盗用(ML Model Stealing)
利用 inference API 可以盗用机器学习模型的功能。模型盗用和模型复制之间存在差异:在模型盗用攻击中,攻击者能够构建一个保真度与受害者模型相匹配的影子模型,因此,模型盗用/窃取攻击会导致知识产权被盗。而在模型复制攻击中,影子模型与受害者模型的保真度会不同。
不安全的存储(Insecure Storage)
攻击者可能会通过利用不安全的存储机制来窃取机器学习模型或私有的训练测试数据集。攻击者可能会发现并窃取机器学习管道的组件,从而导致知识产权被盗。
影响(Impact)
功能损毁(Defacement)
攻击者可以创建数据输入,用于破坏系统。这可以通过投毒——破坏训练数据来实现,例如案例(四)中的Tay Bot、绕过攻击或利用机器学习开发包中的开放 CVE。
拒绝服务(Denial of Service)
攻击者可能会针对不同的机器学习服务进行 DoS攻击。例如Sponge ,它可以通过消耗资源而导致生产 NLP 系统上的 DoS。
知识产权被盗(Stolen Intellectual Property)
攻击者可能会通过模型复制或模型窃取来窃取知识产权。
加密数据攻击(Data Encrypted for Impact)
攻击者可能会加密系统中的大量数据,以中断系统和网络资源的可用性。他们可以通过加密本地和远程驱动器上的文件或数据并拒绝访问解密密钥,使存储的数据无法访问。这样做可能是为了从受害者那里获得金钱补偿以换取解密或解密密钥(勒索软件),或者在未保存和传输密钥的情况下使数据永久无法访问,例如:US-CERT Ransomware 2016、FireEye WannaCry 2017、US-CERT NotPetya 2017、US-CERT SamSam 2018。常见勒索软件的目标用户文件加密文件有:Office 文档、PDF、图像、视频、音频、文本,源代码等。在某些情况下,攻击者也会加密关键系统文件、特定磁盘分区、主分区引导记录。
为了使攻击影响最大化,用于加密数据的恶意软件可能设计中加入了类似蠕虫的功能,并通过利用其他攻击技术(如有效帐户、操作系统凭据转储和SMB/Windows 管理员共享)在网络中传播,如FireEye WannaCry 2017、US-CERT NotPetya 2017。
系统关闭/重启攻击(Stop System Shutdown/Reboot)
攻击者可能会关闭/重启系统以中断对这些系统的访问或达到辅助破坏的目的。操作系统可能包含启动机器关机/重启的命令。在某些情况下,这些命令还可用于远程计算机的关闭/重启。关闭或重启系统可能会中断合法用户对计算机资源的访问。
攻击者可能会使用其他攻击手段配合攻下系统后尝试关闭/重启系统,例如磁盘结构擦除或禁止系统恢复,以加速对系统可用性的攻击影响,详情见:https://attack.mitre.org/techniques/T1561/002/ 。