图片来源:cdn77.com
本文作者:xsy
前端应用的 bundle 体积是影响应用性能的主要方面之一,我们看下取自 HTTP Archive - Loading Speed 的两幅截图

大概是得益于设备性能以及带宽的提升,2022 年移动端页面资源的加载耗时相较 2017 年降低了 38.6%

JS 启动耗时指的是脚本被解析执行的耗时,随着前端应用承载了越来越多的功能,页面的 JS 文件体积逐渐增加,这就导致了浏览器需要花费更多的时间去解析脚本。2022 年移动端的 JavaScript 启动耗时相较 2017 年增加了 211.1%
结合上面两幅图,我们可以得到一个简单的结论:单纯地依赖硬件性能以及带宽的提升、来水到渠成地提高应用性能是不行的,我们需要自主地对应用的体积进行一些分析和优化
接下来我们将一起以傻瓜模式来分析应用的体积
分析目标
前端应用的体积构成包括:
- JavaScript 文件
- CSS 文件
- 图片、字体等其他资源文件
为了简化问题,我们将暂时只关注 JS 文件的体积
有两个比较直白主要原因会造成 JS 文件体积的膨胀:
- 包重复依赖
- 未正确配置 Tree-shaking
包重复依赖
包重复依赖指的是项目中引用了同一个包的多个不兼容的版本。发生这个问题的几个主要可能场景为:
项目中直接或者间接地引入了两个不兼容的版本
比如项目引入了 A 和 B,A 和 B 又分别依赖
{"C": "^1.0.0"}和{"C": "^2.0.0"}项目中的某个依赖锁了版本
比如项目中引入了 A 和 B,A 和 B 又分别引入了
{"C": "1.0.1"}和{"C": "^1.0.3"}- 项目中的
package-lock.json文件未及时更新,包含了一些不兼容的版本
为了方便后续后优化,我们的目标是分析出下面的内容:
- 重复的包名和版本号
- 各个重复版本的依赖路径
- 若包的重复依赖问题得到解决,预计可减少的体积
Tree-shaking
现在的打包工具,比如 Webpack 支持对应用体积进行 Tree-shaking 优化,将未使用的代码从最终结果中剔除
Tree-shaking 需要满足一些前置条件:
- 包的被导入位置使用的是 static import
- 包本身使用的是 ESM - ECMAScript modules
- 包标记了自身为 side-effect-free
我们的目标是:
- 分析出哪些包使用了 ESM,但是未设置 side-effect-free
- 若这些包正确配置了 Tree-shaking 后的体积
明确了目标后,我们就准备进入施工环节
Dependency Graph
任何分析工作的第一步都是先收集信息。为了分析应用的体积,我们需要先收集出应用内模块的依赖图(Dependency Graph)
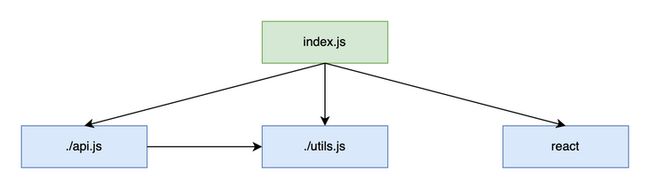
我们可以使用下面的步骤来生成依赖树
- 准备队列 $Queue_{pending}$,队列中的元素为待分析模块的路径 $module_{path}$
- 将分析的入口文件都加入到 $Queue_{pending}$ 中
- 从 $Queue_{pending}$ 中弹出一个元素 $module_{path}$,对其运用模块路径算法 $module\_resolve_\_algo$ 定位模块的文件系统路径 $filepath_{module}$
- 载入 $filepath_{module}$ 位置的文件内容,分析其中的导入语句,得到被导入的模块 $module_{path}'$ 继续加入到 $Queue_{pending}$ 中
- 如果 $Queue_{pending}$ 中还有未处理的元素,则继续第 3 步,否则进入第 6 步
- 结束分析
生成依赖图也是打包工具内部的首要工作,并且为了解析文件中的导入语句以得到 $module_{path}'$,还需要一个 JS 解析器,这些很容易就让人联想到 Webpack 和 Babel
既然是傻瓜模式,轮子是不能不造的,同时为了保证轮子的纯度,我们在造轮子的过程中必须尽可能的造轮子,于是我们可以先实现 JS 解析器,然后完成上面的依赖树生成工作
语法解析器
我们选择用 Go 来实现一个 JS 解析器 mole,由于 Go 并不是文本的主角,所以在最后一节解释为什么选择 Go
编译的基本知识是必备的,受限于篇幅就不展开了。如果需要的话,可以参考我之前整理的 使用 JavaScript 来实现解释器和编译器系列教程
实现解析器之前,我们需划定一个待支持的语法范围:
因为 JSX 和 TS 的语法是在 JS 语法上的增强,所以我们先实现 JS 语法的解析,然后在其基础上增加对 JSX 和 TS 的支持。为了简单,我们将手动的构造一个递归下降的解析器
解析器的编写是比较一个机械的过程,首先参照 Language Spec 中的 Production rules 写出它们对应的解析函数
比如,生产式 PrimaryExpression 的大致形式为:
PrimaryExpression[Yield, Await] :
this
IdentifierReference[?Yield, ?Await]
Literal- 解析器中会为每个生产式都编写对应的解析函数。比如
PrimaryExpression就会对应一个函数primaryExpr = () => PrimaryExpression - 生产式右边的每一行各表示一个展开情况,它们可以为另一个生产式或者终结符。比如
PrimaryExpression可以展开为this或IdentifierReference或Literal - 生产式右边的小写开头的表示终结符,也就是不能继续展开了,大写则表示另一个生产式,进而也会有各自的解析函数,比如
Literal会有一个对应的解析函数literal = () => Literal
对应到解析器实现中的代码结构类似:
function identRef() {}
function literal() {}
function primaryExpr() {
if (tok === T_THIS) return new ThisExpr();
if (tok === IDENT) return identRef();
return literal();
}根据上面的方式构造完解析器时会发现一个问题 - 解析函数相互调用的层数太深。比如,为了解析加法运算,需要经过下面的函数调用:
Expression
-> AssignmentExpression
-> ConditionalExpression
-> ShortCircuitExpression
-> LogicalORExpression
-> LogicalANDExpression
-> BitwiseORExpression
-> BitwiseXORExpression
-> BitwiseANDExpression
-> EqualityExpression
-> RelationalExpression
-> ShiftExpression
-> AdditiveExpression我们花些时间利用 [Operator-precedence parser
](https://en.wikipedia.org/wiki...) 即可优化上面的解析过程
在解析的过程中,我们常常需判断 $lookahead$ 是否为某个 Token 来进入不同的解析函数(比如 tok === T_THIS),而其中的一些 Token 存在歧义,比如:
(in JS(a,b)表示 ParenthesizedExpression 包含了一个 SequenceExpression(a, b) => {}表示箭头函数的定义,括号中的内容为 ArrowFormalParameters
{in JS({a: b})表示 ParenthesizedExpression 包含了一个 ObjectLiteral({a: b}) => {}表示箭头函数的定义,括号中的内容为 ArrowFormalParameters
<in TSa < b表示 RelationalExpressiona()表示 TS 中的 Function Callsb表示 TS 中的 Type Assertions表示 JSX 的 JSXElement
(in TSvar a: ({ a = c }: string | number) => number = 1表示箭头函数类型中形参列表的括号var a: (string | number) = 1表示 ParenthesizedType
当遇到歧义时,我们就需要借助上下文信息。为了尽量避免 Backtracking,遇到歧义时我们首先做下面的尝试:
- 对于有歧义的语法,我们先准备它们的超集。比如 $P1$ 和 $P2$ 的超集为 $P_{1,2} = P1 \cup P2$
- 然后我们在出现歧义的地方,使用 $P_{1,2}$ 进行解析
- 后续出现能够区分 $P1$ 和 $P2$ 的上下文信息时,再做 $P_{1,2} \to P1 \mathbin{|}P_{1,2} \to P2$ 的转换
比如上面的 「{ in JS」 的歧义就适用于这个方式 - 我们先按 ParenthesizedExpression(ObjectLiteral) 和 ArrowFormalParameters 的超集进行解析,然后根据根据是否出现 => 来做 unboxing
当遇到一些复杂的歧义时,则需要引入一些限制条件以及 Backtracking。比如上文提到的 TS 中符号 < 的歧义:
- 在开启 JSX 的情况下,禁用 Type Assertions 语法(使用
a as b替代),这样就解决了3和4之间的歧义,这也是 tsc 的行为 a < b和a()之间的歧义则需要使用到 Backtracking,大致逻辑为:a < b < c ▲ └── mark- 遇到
<先保存当前的解析状态 $mark_{parsingState}$ - 然后按 TypeArguments 进行解析,尝试匹配右侧的
>,如果匹配成功,则进入第 4 步,否则进入第 3 步 - 恢复之前保存的状态 $mark_{parsingState}$,按 RelationalExpression 继续进行解析,如果匹配成功,则进入第 4 步,否则抛出语法错误,终止解析过程
- 歧义完成消除
- 遇到
可以看到 Backtracking 的方式会降低解析的性能,这也是 Go 中使用 [] 作为泛型参数(丑得有理有据)的主要原因:
import "golang.org/x/exp/constraints"
func GMin[T constraints.Ordered](x, y T) T {
if x < y {
return x
}
return y
}我们使用 AST 作为解析结果的承载方式,并遵循 ESTree 中的定义,以使得解析器的处理结果可以被更多的工具消费
关于解析器的最后一点是通过 3656 个单测确保解析结果的准确性,并且方便解析后续功能迭代后进行回归测试
我们可以通过下面的代码来感受下解析器的使用方式:
package main
import (
"bytes"
"encoding/json"
"fmt"
"log"
"github.com/hsiaosiyuan0/mole/ecma/estree"
"github.com/hsiaosiyuan0/mole/ecma/parser"
"github.com/hsiaosiyuan0/mole/span"
)
func main() {
// imitate the source code you want to parse
code := `console.log("hello world")`
// create a Source instance to handle to the source code
s := span.NewSource("", code)
// create a parser, here we use the default options
opts := parser.NewParserOpts()
p := parser.NewParser(s, opts)
// inform the parser do its parsing process
ast, err := p.Prog()
if err != nil {
log.Fatal(err)
}
// by default the parsed AST is not the ESTree form because the latter has a little redundancy,
// however Mole supports to convert its AST to ESTree by using the `estree.ConvertProg` function
b, err := json.Marshal(estree.ConvertProg(ast.(*parser.Prog), estree.NewConvertCtx()))
if err != nil {
log.Fatal(err)
}
// below is nothing new, we just print the ESTree in JSON form
var out bytes.Buffer
json.Indent(&out, b, "", " ")
fmt.Println(out.String())
}AST Walker
有了语法解析器,就可以将 JS 源码转换成对等的 AST 形式,不过为了提取其中的模块导入语句,我们还需要遍历 AST
我们使用树形结构来存放解析的结果,因为它可以方便地体现语法元素之间层次关系。比如 2 * 3 + 4 有类似下面的结构:
node
/ | \
node + 4
/ | \
2 * 3对于树形结构的遍历有两种主要的模式:Listener 和 Visitor
Listener 模式下会自动帮我们做深度优先的遍历,在遇到不同的节点的时候,调用我们提供的 handler:
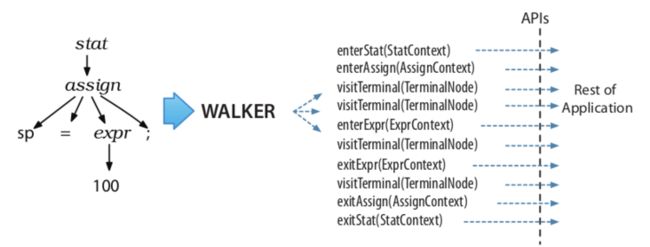
Visitor 模式下我们可以自己控制遍历的顺序,比如:
- 遍历的方式(深度优先还是广度优先,虽然通常是前者)
- 遍历的节点顺序,或者跳过某些节点
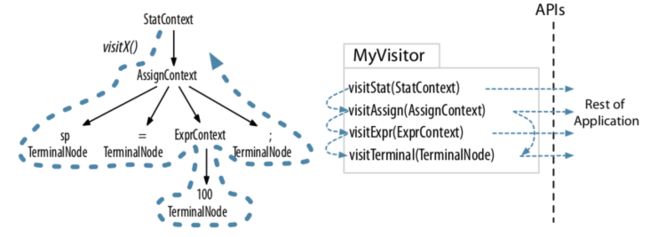
图片引用自 ANTLR Basics
Listener 和 Visitor 模式的选择是根据需求而定的,因此我们的 AST Walker 会同时支持这两种模式
Visitor 模式是可以灵活控制节点遍历顺序的,我们可以先实现 Visitor 模式,然后在它的基础上提供一个 Listener 的实现
我们以 AssignExpr 节点为例,来看一下遍历节点的方式,首先它的结构为:
type AssignExpr struct {
typ NodeType
op TokenValue // 赋值表达式的符号,比如 `=`,`+=` 等
lhs Node // 等号左边的节点
rhs Node // 等号右边的节点
}相应的遍历方式如下:
func VisitAssignExpr(node parser.Node, key string, ctx *VisitorCtx) {
n := node.(*parser.AssignExpr)
CallVisitor(N_EXPR_ASSIGN_BEFORE, n, key, ctx) // 为了支持 listen before 事件
defer CallVisitor(N_EXPR_ASSIGN_AFTER, n, key, ctx) // 为了支持 listen after 事件
VisitNode(n.Lhs(), "Lhs", ctx) // 默认先遍历等号左边
if ctx.WalkCtx.Stopped() {
return
}
VisitNode(n.Rhs(), "Rhs", ctx) // 然后遍历等号右边
if ctx.WalkCtx.Stopped() {
return
}
}我们的解析器所支持的语法范围中,包含类似 AssignExpr 这样的节点大概有 123 个,手动的编写这些代码有几个弊端:
- 首先是一个量不少的机械性工作
- 因为遍历的顺序是和节点定义相关的,节点如果进行了调整,那么对于的方法也需要进行调整。比如后续的 ECMA 语法调整可能会使得我们需要对某些节点增加一些子元素
这时候我们就需要依赖 Go 语言的元编程能力 go:generate,虽然看起来没有一些带宏的语言那么酷炫,但设计却挺灵活,我们可以借助它实现一个简单的宏功能
我们先简单设计一下这样一个简单的宏功能的语法:
Macro := '#[' CallSequence ']'
CallSequence := CallExpr (',' CallExpr)*
CallExpr := CallWithoutArg | CallWithArgs
CallWithoutArg := GoIdent
CallWithArgs := GoIdent '(' Args? ')'
Args := Arg (',' Arg)*
Arg := GoIdent | GoBasicLit | True | False | GoSelectorExpr
GoBasicLit := GoInt | GoFloat | GoString然后我们约定下宏可以在源码中出现的位置:
- 紧挨着结构体定义上面一行的注释
- 紧跟着结构体或者枚举字段后面的注释
比如:
// #[macro]
type BinExpr struct {
lhs Node // #[macro, macro1()]
rhs Node // #[macro], some other comments
}
const (
N_PROG // #[macro]
)确定了宏的语法之后,我们可以使用下面的步骤来解析宏定义:
- 利用 go/parser 来解析我们的 Go 源文件,得到 Go AST
- 遍历 Go AST 中的目标节点 - 即两个位置的注释,按照上面的宏定义的语法来解析注释的内容
- 将解析好的信息收集起来,交由另外的代码生成程序进行消费
比如 AssignExpr 为例,增加了宏后变为:
// #[visitor(Lhs,Rhs)]
type AssignExpr struct {
typ NodeType
op TokenValue
lhs Node
rhs Node
}我们的宏系统设计是解耦的,分为解析和代码生成两部分。对于上面的代码,解析部分收集到的信息为:
AssignExpr使用了一个名为visitor的宏函数- 并且
visitor宏函数有两个参数Lhs和Rhs
代码生成部分则可以根据实际的需求进行代码的生成,比如对于 visitor 来说,就是生成上面的 VisitAssignExpr 函数,并依次调用节点上的 Lhs 和 Rhs 两个方法
后续我们的节点有变化时,只需要修改宏定义并重新生成对应的遍历代码即可。这样简单设计的宏系统帮助我们自动生成了 4000 多行 用于节点遍历的代码
有了 AST Walker 之后,我们就可以通过下面的方式来收集到 JS 文件内的模块导入信息:
package main
import (
"bytes"
"encoding/json"
"fmt"
"log"
"github.com/hsiaosiyuan0/mole/ecma/estree"
"github.com/hsiaosiyuan0/mole/ecma/parser"
"github.com/hsiaosiyuan0/mole/span"
)
func main() {
// imitate the source code you want to parse
code := `
import { Button } from "ui"
export * from "./util"
function f() {
var require = a
require('a.js')
}
`
// create a Source instance to handle to the source code
s := span.NewSource("", code)
// create a parser, here we use the default options
opts := parser.NewParserOpts()
p := parser.NewParser(s, opts)
// inform the parser do its parsing process
ast, err := p.Prog()
if err != nil {
log.Fatal(err)
}
errs := make([]*NotPermittedSyntaxErr, 0)
ctx := walk.NewWalkCtx(ast, p.Symtab())
// 1. collect the import statements
walk.AddNodeAfterListener(&ctx.Listeners, parser.N_STMT_IMPORT, &walk.Listener{
Id: "parseDep",
Handle: func(node parser.Node, key string, ctx *walk.VisitorCtx) {
n := node.(*parser.ImportDec)
// ...
},
})
// 2. collect the export statements
walk.AddNodeAfterListener(&ctx.Listeners, parser.N_STMT_EXPORT, &walk.Listener{
Id: "parseDep",
Handle: func(node parser.Node, key string, ctx *walk.VisitorCtx) {
n := node.(*parser.ExportDec)
// ...
},
})
// 3. since `import` is keyword instead of variable, collect the import points directly
walk.AddNodeAfterListener(&ctx.Listeners, parser.N_IMPORT_CALL, &walk.Listener{
Id: "parseDep",
Handle: func(node parser.Node, key string, ctx *walk.VisitorCtx) {
candidates[node] = node
},
})
// 4. collect the require calls first, which will be filtered by below condition judgement
candidates := map[parser.Node]parser.Node{}
walk.AddNodeAfterListener(&ctx.Listeners, parser.N_EXPR_CALL, &walk.Listener{
Id: "parseDep",
Handle: func(node parser.Node, key string, ctx *walk.VisitorCtx) {
n := node.(*parser.CallExpr)
s := ctx.WalkCtx.Scope()
callee := n.Callee()
args := n.Args()
isRequire := astutil.GetName(callee) == "require" && s.BindingOf("require") == nil &&
len(args) == 1 && args[0].Type() == parser.N_LIT_STR
if isRequire {
candidates[node] = node
}
},
})
walk.VisitNode(ast, "", ctx.VisitorCtx())
}上面代码中需要解释的内容为:
- 对于
import和export语句引入的模块比较好处理,直接在对应的节点监听函数中提取信息即可,也就是1、2和3位置的内容 对于
require来说,我们在其节点监听函数中做了一个判断:- 源码中没有重新绑定
require - 且有且仅有一个实参,同时类型为字符串
满足上面两个条件时,才提取实参字符串信息作为被导入的模块
- 源码中没有重新绑定
另外对于 import() 和 require 的形式导入的模块,其属于有条件导入,比如下面的形式:
if (process.env.NODE_ENV === "production") {
module.exports = require("./cjs/react-dom.production.min.js");
} else {
module.exports = require("./cjs/react-dom.development.js");
}上面的代码在构建时,打包工具会根据环境变量 NODE_ENV 的不同值导入不同的模块,因此我们来需要能够识别这样的有条件导入(Conditional imports)
Conditional imports
有条件导入主要涉及下面三种语句或表达式:
- IfStmt,比如上一节中的例子
- BinExpr,比如
process.env.NODE_ENV && require('./a.js') - CondExpr, 比如
process.env.NODE_ENV ? require('./a.js') : null
其他一些使用频率不高,比如 SwitchStmt 也可能会包含有条件导入,可以暂时先不支持
对有条件导入的支持可以分为两步:
- 对条件表达式进行计算
- 根据计算的结果结合节点自身的语义来遍历不同的子节点
以 IfStmt 为例:
if (process.env.NODE_ENV === "production") {
// Cons
module.exports = require("./cjs/react-dom.production.min.js");
} else {
// Alt
module.exports = require("./cjs/react-dom.development.js");
}我们需要:
- 先能够计算其 Test 节点的表达式
process.env.NODE_ENV === 'production'的值 - 然后根据计算结果选择遍历 Cons 节点还是 Alt 节点
Expr Evaluator
表达式求值器的作用是对条件表达式进行计算,我们需要支持下面的运算类型:
- 基本的算数运算,比如 加减乘除
- 基本的逻辑运算,比如 逻辑与、或、取反
我们可以利用 AST Walker 来实现一个简单的求值器:
- 使用 Listener 模式,将操作数压入操作数栈
- 在对应的运算节点中弹出操作数,根据节点的操作符对操作数进行计算,并将结果压入操作数栈
下面我们以表达式 1 + 2 的计算为例进行解释
首先我们需要监听数字字面量的节点信息,然后在回调中将代表数值的字符串转换成对于的数值并压入操作数栈:
ee.addListener(walk.NodeAfterEvent(parser.N_LIT_NUM),
func(node parser.Node, key string, ctx *walk.VisitorCtx) {
n := node.(*parser.NumLit)
i := parser.NodeToFloat(n, ee.p.Source())
ee.push(i)
})因为 Listener 模式的遍历是深度优先的,所以会优先遍历数字字面量节点 1 和 2,使得操作数栈中的内容变为:
栈底 -> 栈顶
1, 2然后会遍历到 BinExpr 中,我们在对应的回调中讲操作数弹出,并根据操作符对操作数进行计算,并将结果压入操作数栈:
ee.addListener(walk.NodeAfterEvent(parser.N_EXPR_BIN),
func(node parser.Node, key string, ctx *walk.VisitorCtx) {
n := node.(*parser.BinExpr)
rhs := ee.pop() // 2
lhs := ee.pop() // 1
switch n.Op() {
case parser.T_EQ, parser.T_EQ_S:
// ...
case parser.T_NE, parser.T_NE_S:
// ...
case parser.T_ADD:
ee.push(Add(lhs, rhs)) // 1 + 2
case parser.T_SUB:
// ...
case parser.T_MUL:
// ...
case parser.T_DIV:
// ...
}
})计算结束后,操作数栈中停留的 3 即为表达式的计算结果
我们再以 process.env.NODE_ENV 为例,其 AST 的形式为:
memExpr_1
/ \
memExpr_2 ident
/ \ |
ident ident NODE_ENV
| |
process env我们会监听 memExpr 和 ident 的事件,同样因为深度优先的遍历方式,节点的遍历顺序将为:
process -> env -> memExpr_2 -> NODE_ENV -> memExpr类似 process 这样的变量定义,由求值器的调用方传入。在 ident 的回调中,我们会取得变量 process 的值压入操作数栈:
valueOfProcess在 ident 的回调中,如果满足下面的条件:
- 其父节点为 memExpr
- 且节点自身为作为 memExpr 的 prop 属性
- 且不是计算属性
则将 ident 对应的字符串压入操作数栈:
valueOfProcess, 'env'在 memExpr_2 的回调中,我们只需将代表对象和属性名的操作数弹出,并将属性值 valueOfProcess['env'] 重新压入操作数栈即可。memExpr_1 的计算也是类似的步骤,我们就不赘述了
SwitchBranch
有了表达式求值器之后,下一步我们将需要根据求值结果选择遍历的节点。我们有三种需要处理的节点类型:
- IfStmt
- BinExpr
- CondExpr
由于这三种类型的节点结构不尽相同,我们可以先将它们统一转换成一个名为 SwitchBranch 的结构来简化后续的操作:
type SwitchBranch struct {
negative bool
test parser.Node
body parser.Node
}其中的字段含义为:
test表示条件表达式body表示条件成立时需要继续遍历的节点negative表示是否需要对test的结果进行取反
那么对于 IfStmt 来说:
if (Test) Cons else Alt则可以表示成两个 SwitchBranch:
SwitchBranch(false, Test, Cons)SwitchBranch(true, Test, Alt)
我们可以在 Visitor 模式下自顶向下遍历节点,在节点回调中通过 SwitchBranch 结构来筛选需要继续遍历的下一层节点:
func CollectNodesInTrueBranches(node parser.Node, typ []parser.NodeType, vars map[string]interface{}, p *parser.Parser) []parser.Node {
ret := []parser.Node{}
wc := walk.NewWalkCtx(node, nil)
walkTrueBranches := func(node parser.Node, key string, ctx *walk.VisitorCtx) {
// 节点筛选:
// 1. 统一成 SwitchBranch
// 2. 条件表达式求值
// 3. 删选出命中的节点
subs := SelectTrueBranches(node, vars, p)
for _, sub := range subs { // 继续遍历命中的节点
walk.VisitNode(sub, key, ctx)
}
}
// 订阅节点事件,在回调中通过 walkTrueBranches 过滤待继续遍历的节点
walk.SetVisitor(&wc.Visitors, parser.N_STMT_IF, walkTrueBranches)
walk.SetVisitor(&wc.Visitors, parser.N_EXPR_BIN, walkTrueBranches)
walk.SetVisitor(&wc.Visitors, parser.N_EXPR_COND, walkTrueBranches)
for _, t := range typ {
walk.AddNodeAfterListener(&wc.Listeners, t, &walk.Listener{
Id: "CollectNodesInTrueBranches",
Handle: func(node parser.Node, key string, ctx *walk.VisitorCtx) {
ret = append(ret, node)
},
})
}
walk.VisitNode(node, "", wc.VisitorCtx())
return ret
}Module resolution
在依赖图的构建步骤的描述中,提到了 $module\_resolve_\_algo$ 用于定位模块的路径,我们将实现几种常见的算法:
- CJS - CommonJS
- ESM - ES modules,在 CJS 的基础上做了调整
- Browser,在 CJS 的基础上做了调整
上面的链接点击后可以看到完整的算法描述,以 CommonJS 的节选为例:
require(X) from module at path Y
1. If X is a core module,
a. return the core module
b. STOP
2. If X begins with '/'
a. set Y to be the filesystem root
3. If X begins with './' or '/' or '../'
a. LOAD_AS_FILE(Y + X)
b. LOAD_AS_DIRECTORY(Y + X)
c. THROW "not found"
4. If X begins with '#'
a. LOAD_PACKAGE_IMPORTS(X, dirname(Y))
5. LOAD_PACKAGE_SELF(X, dirname(Y))
6. LOAD_NODE_MODULES(X, dirname(Y))
7. THROW "not found"
LOAD_AS_FILE(X)
1. If X is a file, load X as its file extension format. STOP
2. If X.js is a file, load X.js as JavaScript text. STOP
3. If X.json is a file, parse X.json to a JavaScript Object. STOP
4. If X.node is a file, load X.node as binary addon. STOP
...
...实现时我们只需要复刻算法描述中的步骤即可
因为 ESM 和 Browser 都是在 CJS 的基础上做的调整,我们可以先复刻 CJS 的算法逻辑,然后增加上 ESM 和 Browser 的调整即可
ESM 的一个显著的调整是增加了 URLs 的支持:
// file: URLs
import "./foo.mjs?query=1"; // loads ./foo.mjs with query of "?query=1"
import "./foo.mjs?query=2"; // loads ./foo.mjs with query of "?query=2"
// data: imports
import 'data:text/javascript,console.log("hello!");';
import _ from 'data:application/json,"world!"' assert { type: "json" };
// node: imports
import fs from "node:fs/promises";import 语句中的字符串称之为 specifier,那么对于 URLs 的支持来说:
file: URLs的 specifier 只需要在 CJS 的基础上增加对 URL 的解析即可data: imports的 specifier 只需在 CJS 的基础上增加对 MIME 的识别即可,因为其是内联的方式,只需校验格式即可node: imports的 specifier 只需在 CJS 的内置模块集合中增加它们的 ESM 版本即可
ESM 和 CJS 并不是完全兼容的,比如 ESM 不会扫描目录下面的 index 文件,并且尚不支持省略文件后缀。为了和大家实际代码中的使用方式相贴合,我们的 ESM 实现将是一个宽松的版本使之尽量和 CJS 兼容
另外一些 ESM 中实现性的功能,比如 HTTPS and HTTP imports 和 loaders 就先不支持了
Browser 的实现相对 CJS 的调整主要是在 package.json 中增加了一个 browser 字段,方便包作者指定一些用于浏览器环境下的包产物。Browser 已经可以被 CJS 和 ESM 共有的 Conditional exports 所替代,但为了兼容一些旧的包,我们还是会支持下 Browser 算法
最后在 Resolve 时,我们可以采用并行的方式,比如:
import "./a.js";
import "b";当我们解析了上面的代码后,可以并行的继续模块 ./a.js 和 b 的路径计算
tsconfig
除了上面的算法外,tsconfig(jsconfig) 中的 Path mapping 也会影响模块路径的选择,比如我们常会在 Path mapping 中做一些路径 Alias:
{
"compilerOptions": {
"baseUrl": "./",
"paths": {
"@utils/*": ["./src/utils/*"],
"@components/*": ["./src/components/*"],
"@hooks/*": ["./src/hooks/*"]
}
}
}除了对 Path mapping 的支持外,我们还需要支持 extends 也就是配置文件的继承
在对 tsconfig 中的解析中,我们并不需要实现对 Files、Include 和 Exclude 的支持,因为这几个选项的由来是用于和 tsc 交互的。tsc 选择输入文件的模式是,全量的扫描工程目录下的文件,然后编译它们,这也是为什么 tsc 不做额外设定的话,会为每个 x.ts 文件都生成同级目录下的 x.js 文件,通过这几个选项就可以在调整全量扫描的行为,比如可以通过 Exclude 将一些文件排除在全量扫描的范围之外
Files 和 Include 可以让 tsc 不做全量的扫描,而 Exclude 仅影响 Include 的内容,这里的「仅影响」很重要,并且通常会被错误理解,对比下面两个例子:
- Exclude 中标记了 b.ts 要剔除在外,但是 Include 中包含了 a.ts,而 a.ts 中引入了 b.ts,那么 b.ts 依然会被编译
- Include 中同时包含了 a.ts(这次 a.ts 未引入 b.ts)和 b.ts,而 Exclude 中标记了 b.ts,那么这次 b.ts 会被剔除在外
我们的应用体积分析工具的工作形式和打包工具类似 - 用户指定一个或者多个 entry points,我们会以这些 entry points 为起点,分析文件的依赖,仅对涉及到的文件进行处理,因此就无需考虑 Files、Include 和 Exclude 了
对于 paths 的处理,我们可以简单将它们通过字符串替换转换成合法的正则表达式,然后利用 Go 的正则包进行处理即可,比如:
$utils/*$ 在正则中有自己的语义,我们需要进行转移,经过处理后变成:
\$utils/(.*?)转换成正则后,我们就可以通过正则来匹配输入的 specifier,如果满足增加我们将 (.*?) 匹配到的内容替换掉路径中的 * 即可
builtin modules
我们需要将内置模块的名称都收集起来,然后在匹配 specifier 的时候判断其是否为内置模块,以免在遇到使用了内置模块时抛出找不到模块的错误
node 的内置模块的收集可以查看 @types/node 包中的内容
react-native 内置模块可以参考 metro - lazy-imports.js
Tree-shaking
Tree-shaking 又称为 DCE(Dead code elimination),下面简称 DCE。因为打包工具有对 DCE 的支持,我们的分析工具也需要支持这样的功能,以使得分析的结果更加的准确
在进行 DCE 之前,我们需要先收集模块间的引用关系,下图为其一般形式:

图中包含的信息为:
- Entry 表示入口文件,M1 和 M2 分别表示两个不同的模块。这里的一个模块可以通俗地理解为一个 JS 文件
- 模块中大写字母表示模块导出的内容,小写字母表示模块私有内容(外部无法使用)
- Entry 中使用了 M1 导出的 A
- M1 中的 A 使用了 M2 导出的 C,以及内部的 d
- M2 中的 D 使用了其内部的 e
确定了模块引用关系后,第二遍我们就可以以 Entry 为入口,标记触达的内容:

我们通过绿色表示从 Entry 开始可以触达的内容,通过灰色表示可以被 DCE 的内容。有个例外就是红色标记的 D,它不可以被 DCE,因为我们不确定 e 是否有副作用(side-effects)
副作用就是除了计算以外还做了其他的事情,在 JS 中,出现副作用的可能性非常多,比如:
- e 内部可能设置了全局变量,而设置的内容可能会被其他模块使用
const a = b + c,虽然看起来是计算,但 b 可能是一个全局对象上的 Getter
这样的动态性,导致很难在静态阶段分析语句是否包含副作用。从打包工具的角度,它的优化行为必须是保守式的(Conservative),也就是「拿不准的就不干」,因为干了就可能出错,出错就很难调试排查,反而降低了效率
针对 D 这样的问题,现在的打包工具要求开发者通过注释 /*#__PURE__*/ 手动标记表达式无副作用:
export const D = /*#__PURE__*/ e();我们可以进一步将 DCE 的执行步骤整理为:
假设模块内部最顶层语句的定义为:
$TopmostStmt = \{ VarDecStmt, FunDecStmt, ImportDec, ExportDec, ExprStmt \}$
这也是我们当前执行 DCE 的最小颗粒度(函数内部的 dead-code 暂不考虑)
每个模块都有函数 $OwnedOf$:
$OwnedOf: f(x) = TopmostStmt_{x},\ x \in TopmostStmt$
$x$ 为模块内的 TopmostStmt,运用 $OwnedOf$ 后可以得到给定 $x$ 所持有的 $TopmostStmt_{x}$ 元素
比如上面例子中的 M1 运用 $OwnedOf(A) = \{C, d\}$
- 以 $Entry$ 为起点,遇到的模块导入记为 $Import(x, M)$ 进入下一步
- 调用模块的 $OwnedOf(x)$ 方法,得到 $x$ 持有的 $TopmostStmt$,记为 $TopmostStmt'$,
对于 $TopmostStmt'$ 中的每个元素 $x'$,标记其为 $Alive$ 并继续调用 $OwnedOf$ 方法:
$\forall x' \in TopmostStmt', MarkAlive(x'), TopmostStmt^{\prime\prime}=OwnedOf(x')$
如果 $TopmostStmt^{\prime\prime}$ 不为空集合 $\emptyset$ 则对其中的元素继续第 4 步,否则进入下一步
- 如果导入的模块 $M$ 中还包含其他导入,则继续第 4 步,否则进入下一步
对所有模块的标记完成后,重新计算标记为 $Alive$ 的元素体积(源码字符大小):
$A = \{isAlive(TopmostStmt_0),isAlive(TopmostStmt_1),...,isAlive(TopmostStmt_{|A|}) \}$
$Size_{DCE} = \sum_{x=0}^{|A|} Sizeof(x)$
side-effect-free
在 Webpack 没有支持 side-effect-free 之前,有一些包会使用自定义的包路径改写插件,比如 babel-plugin-import,它的功能演示为:
import { Button } from 'antd';
ReactDOM.render();
↓ ↓ ↓ ↓ ↓ ↓
var _button = require('antd/lib/button');
ReactDOM.render(<_button>xxxx);当打包工具支持了 side-effect-free 后,包自身只需 标记 那些没有副作用的文件即可,用户就不再需要使用路径改写插件了
对于那些不支持 DCE 的打包工具,比如 metro,上面的自定义包路径改写仍然是有需要的,那么我们的分析工具是否需要支持自定义的包路径改写呢
对于 import { Button } from 'antd'; 来说,导入的是模块内的 antd/index.js 文件,假设这个文件是 ESM 的:
// antd/index.js
export Button from "./button";
export Icon from "./icon";那么如果打包工具成功执行了 DCE 后,icon 自然会被排除在外,效果和经过自定义路径改写是一样的
但是当 antd/index.js 文件为 CJS 时:
// antd/index.js
module.exports.Button = require("./button");
module.exports.Icon = require("./icon");由于导入语句的副作用,使得打包工具无法进行 DCE,这时自定义的路径改写就会发挥作用
而实际场景中多数为第一种情况,因此我们不必支持自定义的路径改写,只需注意的是在不支持 DCE 的场景(ReactNative)下给出 CJS 的包体积而不是 ESM 的
因此我们在计算包体积的时候,会同时计算两份,即 CjsSize 和 EsmSize:
- 在支持 DCE 的场景下,我们会根据包是否正确配置了 side-effect-free 来展示 CjsSize 或者 EsmSize,并且 EsmSize 可以作为正确配置后的体积进行展示
在不支持 DCE 的场景下,我们可以提供配置,让一些使用了自定义路径改写的模块展示 EsmSize
{ "target": "react-native", "entries": ["./index.ios.js"], "extensions": [], "sideEffectsFreeModules": [ "@music/dolphin-core", "@music/dolphin-core-biz", "@music/dolphin-icons" ] }
效果演示
我们已经实现了信息收集的功能,后面基于信息的处理,比如识别出重复的包因为比较简单就不赘述了,直接看一下效果
我们需要先在待分析应用中通过 molecast.json 文件进行简单的配置:
{
"depGraph": {
"entries": [
"./src/page/*/index.jsx"
]
}
}比如上面的配置中指定了入口文件的位置,我们也可以指定更多的配置:
{
"depGraph": {
"target": "react-native", /* 应用的类型:web, node, react-native */
"entries": [
"./index.ios.js"
],
// 带尝试的文件后缀列表
// JS 应用默认为 ".js", ".jsx", ".mjs", ".cjs", ".json"
// 标记了 TS 后默认为 ".ts", ".tsx", ".js", ".jsx", ".mjs", ".d.ts", ".json", ".node"
"extensions": [],
// 是否为使用了 ts 的应用,默认会根据是否存在 tsconfig.json 来识别
"ts": true,
// 预定义的变量
"definedVars": {
"process": {
"env": {
"NODE_ENV": "production"
}
}
},
// 显式地标记 side-effect-free 的模块
"sideEffectsFreeModules": [
"@music/sth-core"
]
}
}然后在应用根目录中运行:
npx molecast -ana -pkgsize我们当前只支持 *nix 平台,Windows 则可以尝试在 WSL 下运行
运气好的话会看到文件名类似 mole-pkg-analysis-1663478942.json 的分析结果文件,内容为:
{
// 分析时使用的配置项
"options": {},
// 分析花费的时间
"elapsed": 238,
// 重复依赖的模块
"dupModules": [
{
"name": "@music/sth",
"size": 80409,
"versions": [
{
"id": 78, // 模块的 id,可以在 modules 检索出模块的具体信息
"version": "2.2.8", // 模块的版本
"size": 33948 // 模块的体积
},
{
"id": 334,
"version": "1.3.24",
"size": 46461
}
]
}
],
// 重复依赖的导入路径
"importInfo": {},
// 模块信息
"modules": {
"101": {
"id": 101,
"name": "", // 模块的名称,如果是 umbrella 模块的话会展示 package.json 中的 name
"version": "", // 模块的版本,如果是 umbrella 模块的话会展示 package.json 中的 version
"file": "/app/client/components/order-pay-layer/QRCode.js", // 模块磁盘路径
"size": 1125, // 模块的体积 bytes
"dceSize": 865, // DCE 后的体积
"strict": false, // 是否使用了 strict mode
"entry": false, // 是否是入口文件
"umbrella": 18, // 模块所属 umbrella 模块
"cjs": false, // 是否是 cjs
"cjsList": [], // 使用了 cjs 的子模块列表
"esmList": [], // 使用了 esm 的子模块列表
"sideEffectFree": false, // 是否是 umbrella 模块,且在 package.json 中设置了 sideEffectFree
"inlets": [ // 哪些模块导入了该模块
{
"lhs": 57,
"rhs": 101
}
],
"outlets": [ // 该模块导入了哪些模块
{
"lhs": 101,
"rhs": 22
},
],
"owners": { // 该模块被哪些模块以何种形式依赖,比如这里表示被 import _default from "xxx" 的形式导入
"57": [
"default"
]
},
"extsMap": { // 该模块导入的模块名称到 id 的映射
"@music/mobile-react-toast": 26,
"@utils/fetch": 19,
"react": 22,
"react-dom": 46
},
"topmostStmts": [ // 模块中的顶层的语句的依赖关系
{
"id": 747324309719,
"nodeType": "ImportDec",
"src": "react",
"range": [
174,
215
],
"alive": true,
"sideEffect": false,
"owners": [
1425929143395
],
"owned": []
}
],
"parseTime": 215559, // 模块解析耗时,单位 Nanoseconds
"walkDepTime": 67877, // 模块 AST walking 耗时,单位 Nanoseconds
"walkTopmostTime": 134729 // 分析顶层语句依赖耗时,单位 Nanoseconds
}
},
// 分析过程中的解析错误
"parserErrors": [],
// 分析过程中的模块路径计算错误
"resolveErrors": [],
// 分析过程中的超时错误
"timeoutErrors": []
}基于上面的分析结果我们可以再做一些可视化的数据展示
为什么选择 Go
程序执行的快慢主要看 CPU 及 内存的利用率,编程语言力不例外。从结果上我们可以通过搜罗网络上各种 benchmark 得出 Go 比 JS 执行快的结论
像编程语言这样包含众多组件的程序,很难通过一些简单的指标去分析出它们为什么快和慢,简单列举下 Go 与 JS 的不同还是可以的:
- Go 直接编译,JS 需要 JIT 热身。得益于在指令生成阶段的优化,在一些小的 benchmark 项目中可能 JS 的表现可能会更好
- Go 对象的 Memory layouts 相比 JS 更加的简单,JS 中存放 JIT 生成的指令所以造成的内存占用也不容小觑
- Go 对多核的支持使用上比 JS 更加的自然,效率上也更高
除了比 JS 快之外,Go 也比较简单
关于 Go 比较简单,我的论据基于 Here We Go Again: Why Is It Difficult for Developers to Learn Another Programming Language?(简称 Why)
Why 文基于 StackOverflow 大数据以及资深开发者问卷调查,试图解释哪些环节导致开发者认为一门语言比较难
我总结出下面几点:
- 开发者习惯对照以往的经验来学习新语言
- 基于上一点,当新语言与过往经验的交集越少时,学习难度越大,比如我们在初识 JS 时遇到
=== var closure - 文档、示例和社区很重要,因为开发者通常会选择一种用到哪学到哪(哪里不会点哪里)的方式学习新语言,所以需要足够多的资料让搜索引擎能呈现更丰富的结果
- 开发环境配置难度(IDE 功能易用、丰富性),很显然代码终究还是要用来写的,如果卡在配置环境阶段体验肯定要打折扣
而在前端开发者的角度:
主要接触的语言就是 JS,Go 与 JS 类似,都是 C 语言风格的且带 GC 的语言,并且 Go 的语法规则更简单
- Go 的文档丰富且集中 go.dev
- 使用 VSCode 简单配置就可以得到一个 IDE,参考 Go in Visual Studio Code
上面就是一点点关于我为什么选择 Go 的解释,仅供参考。希望大家不要陷入到讨论语言好坏的激辩漩涡中,也希望有类似语言疑虑的同学可以从自己对这些语言的真实编程体验中得到自己满意的答案
结尾
我们重新编写了语法解析器,AST Walker,Expr Evaluator,复刻了 Module resolution 算法,实现了顶层语句的 DCE,最终产生了一份分析结果,是名副其实的傻瓜模式
希望本文可以起到抛砖引玉的作用,让大家对打包或者分析工具的内部工作方式有所了解,或者参考文中的方式实现自己的分析工具。受限于自身能力,文中如有不足之处还请大家斧正,欢迎大家一起学习交流
本文发布自网易云音乐技术团队,文章未经授权禁止任何形式的转载。我们常年招收各类技术岗位,如果你准备换工作,又恰好喜欢云音乐,那就加入我们 grp.music-fe(at)corp.netease.com!