深度学习代码实践(三)5行代码创建手写数字体识别的Tensorflow模型
场景:对包含单个数字的图片进行识别,识别出图片中的数字
训练数据: 采用 mnist 数据集中的 60000张灰度图像(每个像素值范围:0-255),每张图像用一个 28x28 像素的矩阵表示,以及每张图像表示的是 0-9 中的哪一个数字。
输入:一个 28x28 像素的灰度图像 (目标:对输入的这个图片进行数字识别)
输出:0-9 的数字 (识别出来的数字)
模型训练的代码实现:
以下代码先加载 mnist 的图片数据集,然后构建模型进行训练,评估模型,图形化展示训练集和测试集的损失和准确度。最后保存模型到文件。
train.py 代码
#### train.py 训练手写数字体图片识别的模型
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3' # or any {'0', '1', '2'}
import tensorflow as tf
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
#载入 MNIST 数据集,并将整型转换为浮点型,除以 255 是为了归一化。
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
#使用 tf.keras.Sequential 建立模型,并且选择优化器和损失函数
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy', metrics=['accuracy'])
#训练模型
history = model.fit(x_train, y_train, epochs=5,validation_data=(x_test,y_test))
#模型评估
model.evaluate(x_test, y_test, verbose=2)
#查看训练集与测试集的均方误差和准确率变化情况
history.history.keys()
#查看 training set, validation set 的损失和准确率
plt.plot(history.epoch,history.history.get('loss'),label='Loss')
plt.plot(history.epoch,history.history.get('val_loss'),label='Validation Loss')
plt.legend()
plt.show()
plt.plot(history.epoch,history.history.get('accuracy'),label='Accuracy')
plt.plot(history.epoch,history.history.get('val_accuracy'),label='Validation Accuracy')
plt.legend()
plt.show()
# 保存全模型
model.save('tf_model.h5')
在 Mac M1 上运行代码
python3 train.py代码运行报错, 如下
Epoch 1/5
2021-10-28 00:47:57.991 python3[17544:2291672] -[MPSGraph adamUpdateWithLearningRateTensor:beta1Tensor:beta2Tensor:epsilonTensor:beta1PowerTensor:beta2PowerTensor:valuesTensor:momentumTensor:velocityTensor:maximumVelocityTensor:gradientTensor:name:]: unrecognized selector sent to instance 0x12e992940
2021-10-28 00:47:58.013 python3[17544:2291672] *** Terminating app due to uncaught exception 'NSInvalidArgumentException', reason: '-[MPSGraph adamUpdateWithLearningRateTensor:beta1Tensor:beta2Tensor:epsilonTensor:beta1PowerTensor:beta2PowerTensor:valuesTensor:momentumTensor:velocityTensor:maximumVelocityTensor:gradientTensor:name:]: unrecognized selector sent to instance 0x12e992940'
*** First throw call stack:
(
0 CoreFoundation 0x0000000191a9f838 __exceptionPreprocess + 240
1 libobjc.A.dylib 0x00000001917c90a8 objc_exception_throw + 60
2 CoreFoundation 0x0000000191b30694 -[NSObject(NSObject) __retain_OA] + 0
3 CoreFoundation 0x0000000191a00cd4 ___forwarding___ + 1444
4 CoreFoundation 0x0000000191a00670 _CF_forwarding_prep_0 + 96
5 libmetal_plugin.dylib 0x000000011f89a290 _ZN12metal_plugin14MPSApplyAdamOpIfEC2EPNS_20OpKernelConstructionE + 656
6 libmetal_plugin.dylib 0x000000011f899ebc _ZN12metal_pluginL14CreateOpKernelINS_14MPSApplyAdamOpIfEEEEPvP23TF_OpKernelConstruction + 52
7 libtensorflow_framework.2.dylib 0x00000001159d85d4 _ZN10tensorflow12_GLOBAL__N_120KernelBuilderFactory6CreateEPNS_20OpKernelConstructionE + 88
…
30 _pywrap_tfe.so 0x0000000116e6e41c _ZN10tensorflow32TFE_Py_ExecuteCancelable_wrapperERKN8pybind116handleEPKcS5_S3_S3_PNS_19CancellationManagerES3_ + 160
31 _pywrap_tfe.so 0x0000000116e9f208 _ZZN8pybind1112cpp_function10initializeIZL25pybind11_init__pywrap_tfeRNS_7module_EE4$_44NS_6objectEJRKNS_6handleEPKcSA_S8_S8_S8_EJNS_4nameENS_5scopeENS_7siblingEEEEvOT_PFT0_DpT1_EDpRKT2_ENUlRNS_6detail13function_callEE_8__invokeESR_ + 184
32 _pywrap_tfe.so 0x0000000116e810e0 _ZN8pybind1112cpp_function10dispatcherEP7_objectS2_S2_ + 3216
33 python3 0x0000000100d07398 cfunction_call + 80
34 python3 0x0000000100cb31e8 _PyObject_MakeTpCall + 340
35 python3 0x0000000100dc36ac call_function + 724
….
77 python3 0x0000000100e1ad48 PyRun_SimpleFileExFlags + 816
78 python3 0x0000000100e3de84 Py_RunMain + 2916
79 python3 0x0000000100e3f018 pymain_main + 1272
80 python3 0x0000000100c59ddc main + 56
81 libdyld.dylib 0x0000000191941430 start + 4
)
libc++abi: terminating with uncaught exception of type NSException运行这个错误是因为 ADAM 的优化函数在执行的时候出错, 把代码中的 adam 换成 sdg在 m1 上可以正常执行。
model.compile(optimizer='sgd',
loss='sparse_categorical_crossentropy', metrics=['accuracy'])很快运行出了结果,随着迭代的不断进行,准确度也越来越高。
Metal device set to: Apple M1
systemMemory: 16.00 GB
maxCacheSize: 5.33 GB
Epoch 1/5
1875/1875 [==============================] - 7s 4ms/step - loss: 0.7205 - accuracy: 0.8033 - val_loss: 0.3633 - val_accuracy: 0.9048
Epoch 2/5
1875/1875 [==============================] - 7s 4ms/step - loss: 0.3846 - accuracy: 0.8904 - val_loss: 0.2933 - val_accuracy: 0.9189
Epoch 3/5
1875/1875 [==============================] - 8s 4ms/step - loss: 0.3211 - accuracy: 0.9083 - val_loss: 0.2533 - val_accuracy: 0.9303
Epoch 4/5
1875/1875 [==============================] - 7s 4ms/step - loss: 0.2833 - accuracy: 0.9200 - val_loss: 0.2282 - val_accuracy: 0.9358
Epoch 5/5
1875/1875 [==============================] - 7s 4ms/step - loss: 0.2560 - accuracy: 0.9271 - val_loss: 0.2074 - val_accuracy: 0.9426
313/313 - 1s - loss: 0.2074 - accuracy: 0.9426前面5行代码具体是什么作用,后面再做详细的讲解。先了解建模的步骤。
接下来,使用前面创建的模型来做预测。 有3个输入的图片, digit-number-3.jpg, digit-number-4.jpg, digit-number-7.jpg,分别对应数字 3, 4, 7。 这3个图片中, 7, 4 是手写的一个数字,3 是从一张图片上截取下来的片段。图片在代码仓库中有。
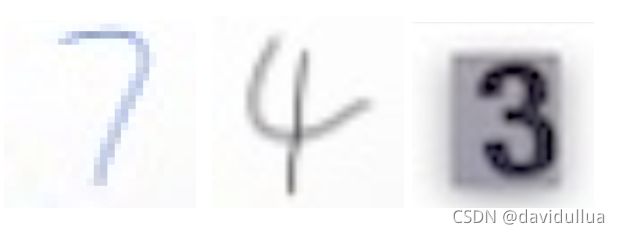
下面加载模型, 实现一个函数, 使用模型 来对图片文件的内容做预测(单个数字的识别):
#### predict.py
import tensorflow as tf
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
from silence_tensorflow import silence_tensorflow
silence_tensorflow()
#调用模型
new_model = tf.keras.models.load_model('tf_model.h5')
#调用模型对输入的图片进行识别,输出一个预测的数字
def predict_digit(filename):
im = Image.open(filename) #读取图片路径
im = im.resize((28,28)) #调整大小和模型输入大小一致
im = np.array(im)
#对图片进行灰度化处理
p3 = im.min(axis = -1)
plt.imshow(p3,cmap = 'gray')
plt.show()
#将白底黑字变成黑底白字 由于训练模型是这种格式
for i in range(28):
for j in range(28):
p3[i][j] = 255-p3[i][j]
#模型输出结果是每个类别的概率,取最大的概率的类别就是预测的结果
ret = new_model.predict((p3/255).reshape((1,28,28)))
number = np.argmax(ret)
return number
input_file = "digit-number-7.jpg"
print("filename: %s predicted:%s" % ( input_file, predict_digit(input_file) ) )
input_file = "digit-number-4.jpg"
print("filename: %s predicted:%s" % ( input_file, predict_digit(input_file) ) )
input_file = "digit-number-3.jpg"
print("filename: %s predicted:%s" % ( input_file, predict_digit(input_file) ) )
下面是预测的结果
Metal device set to: Apple M1
systemMemory: 16.00 GB
maxCacheSize: 5.33 GB
filename: digit-number-7.jpg predicted:7
filename: digit-number-4.jpg predicted:4
filename: digit-number-3.jpg predicted:87, 4 两张图片的数字识别是准确的。 3的识别成了8,识别的是不准确的。 完整的代码参考:
https://github.com/davideuler/beauty-of-math-in-deep-learning.git
这是一个非常简单的构建和使用神经网络的例子。 实际的图片识别中,往往不是识别单个的字符,而是识别连续的字符, 那么还需要使用图片分割的算法对图片进行分割。 同时识别的也不仅仅是数字,可能还有字母,中文,或者其他语言的文字,都可以使用类似的方法来进行训练和识别。
神经网络模型不仅仅用于图像识别, 语音识别,语义理解,图像分割,机器翻译等等领域都可以用到。 神经网络是机器学习的一种, 其处理过程包含两个步骤:
学习:输入的训练集进行学习(从已知结果/打过标签的对象和输入的特征进行学习)
预测/推理:对未知的对象,根据输入特征,自动做推理预测(打标签)
其他的场景都可以类似前面的代码过程来处理。 后面的文章继续介绍如何手写一个神经网络,你会对前面的代码有更多理解。