CS50.3 人工智能导论笔记
参考资料
- CS50.3 人工智能导论 · 2020
- 发现自己能够听懂,并做笔记了,大一的时候想看但很吃力,涉及离散数学、数据结构、概率论等知识
Search
- DFS
- 路径不一定是最优的
- BFS
- 多走了很多路,但是路径一定是最优的
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-n18JA2rN-1658380796070)(https://s2.loli.net/2022/03/28/osNHd8Yu5nMWxXf.png)]
class Node():
def _init_(self,state,parent,action):
self.state = state
self.parent = parent
self.action = action
class StackFrontier():
def _init_(self):
self.frontier = []
def add(self,node):
self.frontier.append(node)
def contains_state(self,state):
return any(node.state == state for node in self.frontier)
def empty(self):
return len(self.frontier) == 0
def remove(self):
if self.empty():
raise Exception("empty frontier")
else:
node = self.frontier[-1]
self.frontier = self.frontier[:-1]
return node
class QueueFrontier(StackFrontier):
def remoe(self):
if self.empty():
raise Exception("empty frontier")
else:
node = self.frontier[0]
self.frontier = self.frontier[1:]
return node
class Maze():
def _init_(self,filename):
with open(filename) as f:
#部分代码.....
注意到
__init__方法的第一个参数永远是self,表示创建的实例本身,因此,在__init__方法内部,就可以把各种属性绑定到self,因为self就指向创建的实例本身。
-
对于人类会怎么做,需要更聪明的算法
- 不知情搜素
- DFS、BFS
- 知情搜素 informed search
- 不知情搜素
-
贪婪最佳优先搜素 greedy best-first search
通过一个启发式函数估算我们离目标有多近,并且注意启发式函数并不代表实际到达的步数,有墙可能会更远。
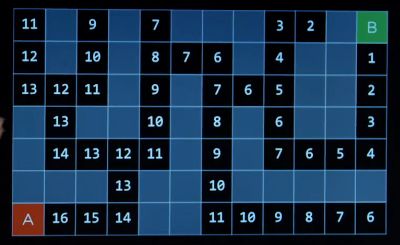
启发函数的好坏直接影响了结果好坏
-
A*搜索
如何改进?判断权值是否再选择一个较小的结果后,又发现回升。
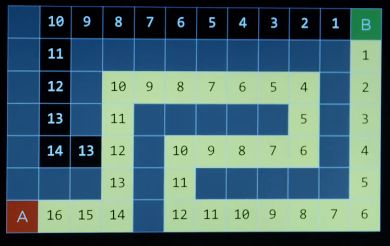
A*搜索不仅考虑启发式函数,还考虑多长时间达到特定状态。
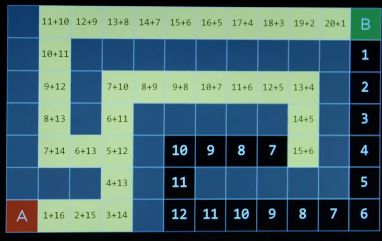
如果启发式函数不高估实际成本,那么它是可接受的,每个节点的结果或者与实际相同,或者小于实际值,但是不能认为我离目标比实际更远。这里不理解没关系,视频说这背后的数学比较深奥,缺失不好理解。选择启发式函数,是挑战,启发式函数越好越容易解决问题。A*通常需要大量内存。
-
Adversarial Search(对抗性搜索)
Minimax 极大极小算法
an agent trying to make intelligent decisions,and there is someone else who is fighting against me,so to speak.

MAX(X) aims to maximize score,MIN(O) aims to minimize score.
-
So:初始状态
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CrlgjxkB-1658380796074)(https://s2.loli.net/2022/03/28/I1HAbqycRPrspzJ.png)]
-
Player(s): 返回哪一个玩家移动到状态s
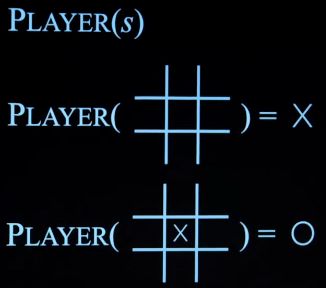
-
Actions(s): 返回所有状态中合法的移动
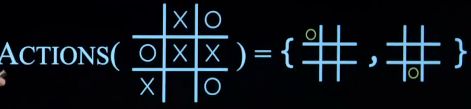
-
Result(s,a): 在动作a达到状态s之后返回状态
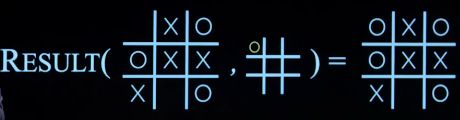
-
Terminal(s):检查是否状态s,是否是终止状态
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qK5EK4KL-1658380796076)(https://s2.loli.net/2022/03/28/ZWQcNkDzgfwX2Rq.png)]
-
Utility(s):计算终止状态的分数
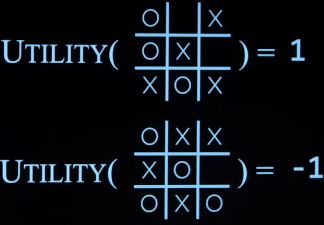
-
MIN一直选择值较小的状态,MAX一直选择值较大的状态,下图为两者的博弈树
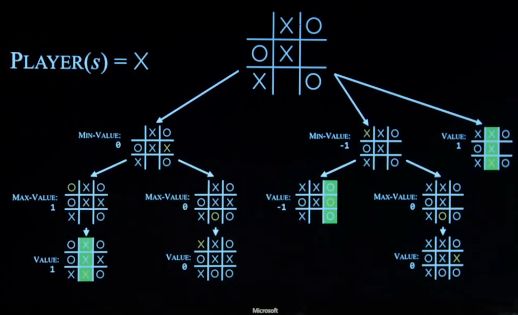
-
可以进行哪些优化
有些状态不需要查看,只需在我能选择最优时,选择的那个结果,即对不许查看的结果进行剪枝(alpha-beta pruning)。

-
由于计算机所能查看到的深度有限,因此我们要做一些限制,即深度限制的极小极大算法(depth-limited Minimax)
-
评估函数来判断胜率,https://xkcd.com/832/ 网站中的对抗性测率游戏的所有可能
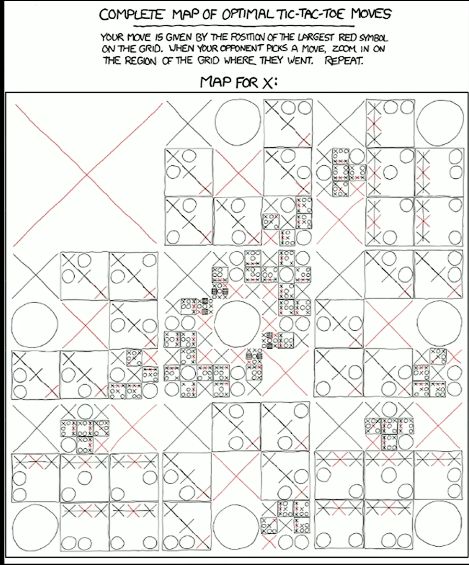
-
Knowledge
-
基于知识的代理 knowledge-based agents
- 基于知识得出结论
- 用已有的信息,分析得出其他信息,举了一个Hagrid的例子
- 逻辑推理
-
sentence
-
知识表示语言
-
命题逻辑、命名符号
- 每一个符号表示一个事实(联想到离散数学),真假命题,逻辑联结词
- 非、与、或、推出、互推
-
not
-
真值表(确实和离散数学对应)
P -p false true true false
-
-
介绍了与^、或v
-
implication(->)只有条件为真时,才能推出结果为真,条件为假,不能推出结果为真或者假。
-
biconditional (<->)同为真,不同为假,(同或)
-
-
真实情况
-
建立模型model
- 用符号代表事件的真假
-
存储knowledge base 即已知的结论、知识
-
得出entailment 后果,理解为结论
- A为真,B也必须为真
-
-
实列
-
P:it is a Tuesday
-
Q: it is raining.
-
R: Harry will go for a run.
-
KB(knowledge base): (P^非Q)->R
-
inference : R为真
-
KB能否得出A结论
-
-
Model Checking 模型跟踪算法
-
to determine if KB|= a:
-
Enumerate all possible models.
-
if in every model where KB is true, a is true ,then KB entails a.
form logic import * rain = Symbol("rain") #it is raining. hagrid = Symbol("hagrid") #Harry visited Hagrid. dumbledore = Symbol("dumbledore") #Harry visited Dumbledore knowledge = And(Implication(Not(rain),hagrid), Or(hagrid,dumbledore), Not(And(hagrid,dumbledore)), dumbledore ) print(knowledge.formula())
- 增加model_check
- 检查model中的知识是否是正确的
- 我们不在乎它不为真,我们只在乎为真的那一个**(这里有点疑问?没懂)**
-
-
Knowledge Engineering 知识工程
-
Clue 线索
-
propositional Symbols 命题符号
-
使用命题符号创建句子
-
命题逻辑转化为结论
-
-
Logic puzzles 逻辑谜题
- 编辑语句代表约束
-
Mastermind 策略规划
- 可能性比较多,需要更好的方法
-
-
inference Rules 推理规则
-
Modus Ponens 惯性法
-
double negation elimination 双重否定消除
-
implication elimination 隐含消除
-
Biconditional elimination 双条件删除
-
De Morgan’s Law 德摩根律
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ixULRryh-1658380796079)(https://s2.loli.net/2022/03/29/pQ7r9bzqclwhLFH.png)]
-
Distributive Property 分配律
-
theorem proving 定理证明方法
- 和搜索的问题联系在一起

-
clause
- a disjunction of literals
-
-
conjunctive normal form 合取范式(CNF)
-
conversion to CNF 将推理规则和CNF结合
-
p和非p同真,结论为假
-
inference by resolution
这里有点吃力,我理解为离散数学中用反证法去解命题
-
-
First-Order Logic 一阶谓词逻辑
-
两种类型的符号
-
常量符号
-
universal quantification 普遍量词
-
existential quantification 存在量词
-
-
二阶逻辑
-
等等
Uncertainty
-
通常计算机获取信息带有不确定性
-
估计事件发生的可能性
-
Probability
- possible worlds 所有可能性,举了骰子的例子
- 0 ≤ P(w) ≤ 1
- 所有可能性的概率之和为 1
- P(sum to 12) = 1/36 两个骰子数字之和的概率
-
unconditional probability 无条件概率
-
conditional probability 条件概率
-
P(a|b) = 条件概率公式
-
random variable 随机变量,举了一些例子
-
independence 独立事件
- 独立公式
-
-
Bayes’ Rule 贝叶斯公式
-
例子,已知如下
- 早上有云,下午下雨的概率
- 上午有云,下午有0.8的概率下雨
- 有0.4日子是早上有云
- 有0.1日子是下午有雨
得:

-
-
joint probability 联合分布
- 联合概率表
-
Rules 逻辑关系对应到概率论的规则
- Negation
- inclusion- Exclusion
- Marginalization 边缘化
- Conditioning
-
Bayesian network 贝叶斯网络
-
inference
- 信息变量
- 证据变量
- 隐藏变量
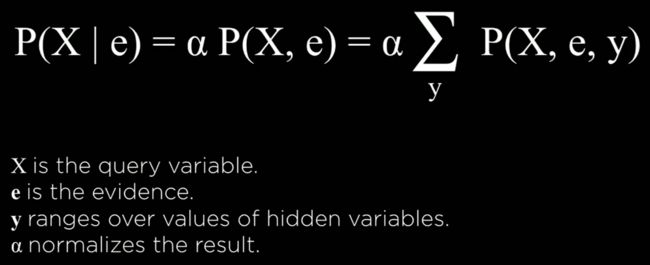
-
pomegranate 石榴库
pomegranate 是基于 Python 的图模型和概率模型工具包,它使用 Cython 实现以加快反应速度。它源于 YAHMM,可实现快速、高效和极度灵活的概率模型,如概率分布、贝叶斯网络、混合隐马尔可夫模型等。概率建模最基础的级别是简单的概率分布。以语言建模为例,概率分布就是是一个人所说的每个单词出现频率的分布。
原文链接:https://blog.csdn.net/Uwr44UOuQcNsUQb60zk2/article/details/79029870form model import model probability = model.probability([["none","no","no time","miss"]]) print(probability) -
Approximate Inference
- Sampling
-
Likelihood weighting 似然加权
-
Markov assumption 马尔科夫假设
- the assumption that the current state depends on only finite fixed number of previous states.假设当前状态只依赖于有限且固定数量的先前状态。
-
Markov chain 马尔科夫链
-
a sequence of random variables where the distribution of each variable follows the Markov assumption.一个随机变量序列,其中每个变量的分布遵循马尔可夫假设。

-
-
Transition Model 过渡模型
-
隐马尔可夫模型
- 隐藏状态的信息世界
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AfrXYnrS-1658380796081)(C:/Users/71041/AppData/Roaming/Typora/typora-user-images/image-20220330142457952.png)]
-
Sensor Model (or emission probabilities)
-
Sensor Markov assumption 传感器马尔可夫假设
-
the assumption that the evidence variable depends only the corresponding state.
证据变量只依赖于相应状态的假设。
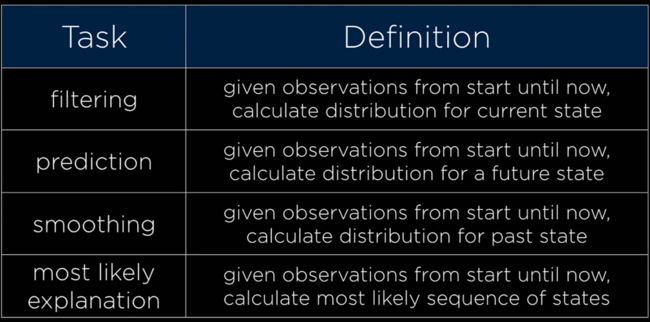
-
概率论的部分听英语讲有点吃力
Optimization
-
选择最好的选项
-
local search
-
search algorithms that maintain a single node and searches by moving to a neighboring node.
-
医院放在哪里使得代价尽可能的小
-
state-space landscape
- global maximum 全域最大值
- objective function 评估函数,判断我当前的结果的好坏
- global minimum 全域最小值
- cost function 花费函数,判断我当前的花费
- neighbors 相邻的状态
-
-
Hill climbing 爬山算法
-
找到最高点,找到最低点
-
伪代码

-
local maxima 局部最大
-
local minima 局部最小
-
爬山算法通常只能找到局部的最优
-
算法容易陷入flat local maximum和shoulder
-
Hill Climbing variants 爬山算法变形
- steepest-ascent,choose the highest-valued neighbor
- stochastic, choose randomly from higher-valued
- first-choice, choose the first higher-valued neighbor
- random-restart , conduct hill climbing multiple times
- local beam search chooses the k highest-valued neighbors
-
代码演示了算法
-
个人要加强一下python的编程了,一直没有重视。
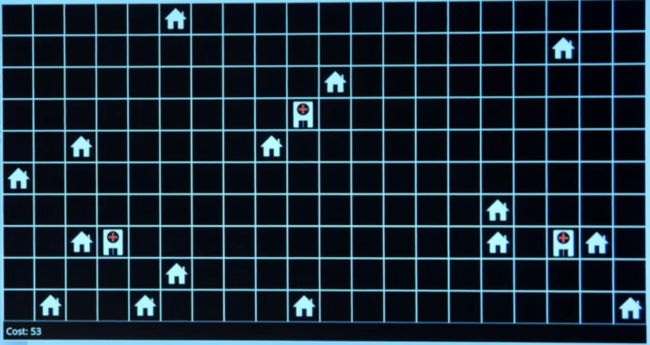
-
-
-
Simulated Annealing 模拟退火算法
-
为什么名字这么奇怪,因为这是一个由金属退火启发的算法。参考
-
加热一个物理系统后剧烈变换到慢慢冷却的过程,最后稳定到一个位置
-
Early on , higher “temperature”:more likely to accept neighbors that are worse than current state.
-
Later on, lower “temperature”:less likely to accept neighbors that are worse than current state.
-
伪代码

-
-
Traveling Salesman Problem(TSP) 商旅问题
- NP完全问题,找到最优
-
linear Programming (线性规划)
-
Minimize a cost function c1x1+c2x2+…+ cnxn
-
with constraints (约束)of form a1x1+a2x2+ … + anxn ≤ b
or of form a1x1 + a2x2+ … + anxn = b
-
with bounds for each variable li ≤ xi ≤ ui
-
Simplex 单纯形
-
interior-Point 内点算法
- 关键不是知道这些算法的过程,但是要意识到这些算法可以找到有效的解决方案
- 编程演示
-
Constraint Satisfaction
-
-
Constraint Satisfaction Problem
-
举了数独的例子
-
变量是方格,用坐标代表
-
变量的域
-
约束
-
下图为排课的例子

-
Hard constraints
-
soft constraints
-
single constraint
-
binary constraint
-
node consistency 节点一致性
所有节点满足一元约束
-
-
Arc consistency电弧一致性算法 AC-3
- CSP as Search Problems
-
Backtracking Search 回朔搜索

-
这部分没有太理解
-
miantaining arc-consistency
- algorithm for enforcing arc-consistency every time we make a new assignment.
- 通过inference和arc consistency 达到不需要回朔就可以得到所有的结果
-
Domain-Values

Learning
-
Supervised Learning
given a data set of input-output pairs,learn a function to map inputs to outputs.
输入数据,使得计算机映射出一些结果
-
classification 分类
有很多数据,数据通常为一个表,然后预测新的特征是否为某个值
函数(数据,数据)= right or not
- 提出一个假设函数h
- 找到h函数
- 计算机能考虑多维
-
nearest-neighbor classification 邻近算法
algorithm that,given an input ,chooses the class of the nearest data point to that input. 输入的数据根据附近的点来判断新输入点所代表的值。
- 缺点是在边界邻居增多且值不稳定、不易区分
-
k-nearest-neighbor classification K邻近算法
- k 表示邻居的个数,查看k中最常见的类别作为我新输入的点的类别
- 缺点
-
尝试多个不同算法,来找到最好的
-
线性回归
-
给数据加权
-
通常用适量数值表示
-
weight vector 学的权重向量
-
input vector 特定的输入,需要判断的
-
两个向量的点积,所以长度必须相同
-
-
perceptron learning rule 感知学习
-
我们可以从随机权重开始,然后从数据中学习,去改变权值
-
y是实际输出,x是输入
-
实际值大于估计值,就需要增加权重
-
实际值小于估计值,就需要减少权重
-
alpha 表示学习率,a越大表示变化越大
-
-
阈值函数
-
hard threshold
-
soft threshold

-
Support Vector Machine 支持向量机
仅仅画一条线通常并不能很好的处理分类问题,取决于线的位置
- 找到Maximum margin separator 最大分隔符
- 在更高维度工作
-
处理的信息是离散的
-
-
regression 回归问题
广告费转化为销售额
-
需要找到信息之间的关系
-
loss function 损失函数
function that express how poorly our hypothesis performs
函数表示我们的假设执行得有多差 ,损失了准确性,因为预测该函数的输出不是实际的输出。
-
0-1损失函数
-
L1 loss function
不仅考虑损失,还考虑距离真实的值有多远
-
L2 loss function
增加了错误预测的惩罚,使用的是平方的差异
-
-
-
overfitting 过拟合
a model that fits too closely to a particular data set and therefore may fail to generalize to future data.
-
regularization 正则化,规格化
在损失函数和复杂性之间做权衡
penalizing hypothesis that are more complex to favor simler,more general hypotheses.
- 避免过拟合
-
holdout cross-validation 交叉验证
-
training set and test set 分为训练集和测试集
-
k-fold cross-validation K折交叉验证
splitting data into k sets,and experimenting k times,using each set as a test set once,and using remaining data as training set.
不仅仅是划分事物,我们将事物分为k个不同的组
-
-
scikit-learn
快速使用机器学习的设置
-
演示
-
使用支持向量机SVC、K邻近算法对事物进行分类
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RxibkVyT-1658380796084)(https://s2.loli.net/2022/04/01/TmzMsDr8CuAS5xd.png)]
-
-
reinforcement learning 强化学习
given a set of rewards or punishments,learning what actions to take in the future.给予一套奖励或惩罚,学习将来采取什么行动。
-
Markov Decision Process 马尔可夫决策过程
model for decision-making,representing states, actions,and their rewards.
决策模型,代表状态,行动和他们的回报。
- set of states S
- set of action Actions(s)
- Transition model P(s’|s,a)
- Reward function R(s,a,s’)
-
-
Q- learning Q学习
method for learning a function Q(s,a), estimate of value of performing action a in state s.学习函数Q(s,a)的方法,在状态s中估计执行动作a的值。
- alpha 是学习率,为1表示只在乎新的信息的影响
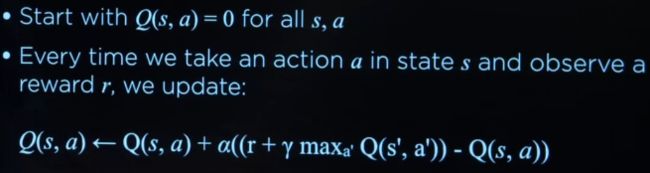
-
Greedy Decision-Making
-
缺点是没有尝试过的路径是不会尝试的,从而错过更好的路
-
Explore vs Exploit
-
如何解决
-
ε- greedy

- 这里演示了组合游戏Nim,关于组合游戏可以了解https://zhuanlan.zhihu.com/p/52931007
- agent即理解为一个下棋机器,做出各种选择和判断
- Function approximation
-
unsupervised learning 无监督学习
given input data without any additional feedback,learn patterns.
-
Clustering 聚类
-
k-均值聚类
algorithm for clustering data based on repeatedly assigning points to clusters and updating those clusters’s centers;
它将把我们所有的数据点分为k个不同的簇
-
根据数据不断的调整数据中心
-
-
Neural Networks
-
启发于神经元
-
Artificial Neural Networks
Model mathematical function from inputs to outputs based on the structure and parameters of the network. 根据网络的结构和参数建立从输入到输出的数学函数模型。
Allows for learning the network’s parameters based on data.允许学习基于数据的网络参数。
-
如何建立这个函数
-
联想到之前将的h函数,其中对于函数中的系数有变量的称为权重,没有变量的成为”偏见“。
h ( x 1 , x 2 ) = w 0 + w 1 x 1 + w 2 x 2 \begin{align}h(x_1,x_2)= w_0+w_1x_1+w_2x_2 \end{align} h(x1,x2)=w0+w1x1+w2x2
-
step function
- 激活函数
-
logistic sigmoid
g ( x ) = e x e x + 1 \begin{align}g(x)= \frac{e^x}{e^x+1} \end{align} g(x)=ex+1ex
-
rectified linear unit (RelU)
h ( x 1 , x 2 ) = g ( w 0 + w 1 x 1 + w 2 x 2 ) \begin{align}h(x_1,x_2)= g(w_0+w_1x_1+w_2x_2) \end{align} h(x1,x2)=g(w0+w1x1+w2x2)
-
Or 与And函数
- 都类似这样的模型,可以对应生活中的很多例子
-
可以让神经网络更复杂
-
多个输入,多个权值,多个和
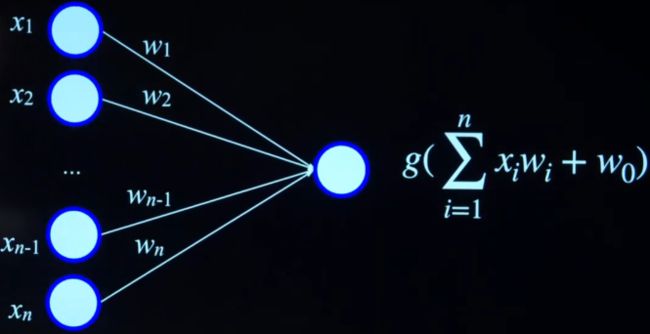
-
-
-
如何训练这些函数
- gradient descent 梯度下降法
- 类似损失函数
- 从随机权值开始
- 输入数据,需要输入all data points
- 计算所有点的,找到下降的方向,通过改变权重,走向更佳的地方
- 不断重复
- stochastic gradient descent 随机梯度下降
- 每次仅用一个数据点来计算梯度 one data points
- 计算移动法方向
- 计算的更快
- Mini-Batch Gradient Descent Mini-Batch梯度下降
- 上述两者的折中
- gradient descent 梯度下降法
-
关心多个,多个输出,需要多个权重
-
Perceptron 感知器
- 局限性,输入是线性的,二进制的感知器无法将复杂的图形分类
-
multilayer neural network 多层神经网络
- 每个决策边界都会有不同的属性,通过不同的决策边界来得出想要的结果
- 数据不能确定隐藏层的值
-
backpropagation 反向传播算法
- 结果反向调整权重
- 关键算法
-
Deep neural network 深度神经网络

-
Overfitting 过拟合
-
Dropout
- 防止过度依赖某些单元,暂时的移除某些单元
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FB6RsAen-1658380796086)(https://s2.loli.net/2022/04/02/sRWyr5EZ6V8CK7k.png)]
-
TensorFlow
- tensorflow playground
- 这可能是最详尽的 Tensorflow Playground 讲解
-
图像识别
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dAgDM6iq-1658380796086)(https://s2.loli.net/2022/04/02/aW48f19MXDd6uns.png)]
-
image convolution 图像卷积
applying a filter that adds each pixel value of an image to its neighbors weighted according to a kernel matrix.
应用一种过滤器,根据核矩阵加权将图像的每个像素值与相邻的像素值相加。
-
过滤图像
-
从图像中提取
-
内核矩阵
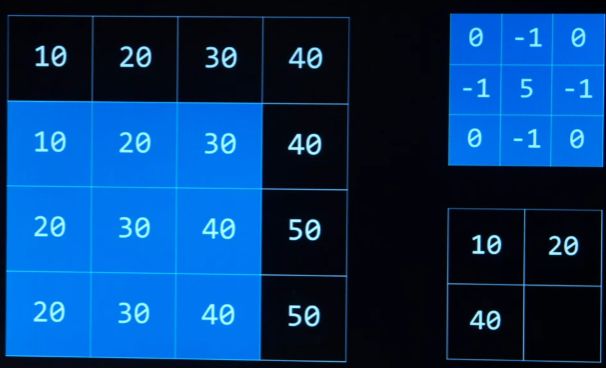
-
常用于边界检测的
-
-
pooling 池化
reducing the size of an input by sampling from regions in the input .
通过对输入区域进行采样来减小输入的大小。
-
max-pooling 最大池化
pooling by choosing the maximum value in each region.
通过在每个区域中选择最大值来实现池化
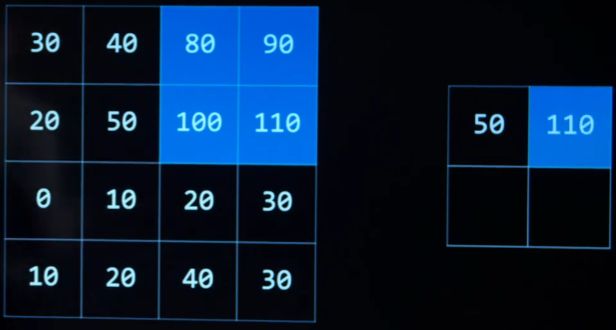
-
-
convolutional neural network (CNN) 卷积神经网络
neural networks that use convolution usually for analyzing images.
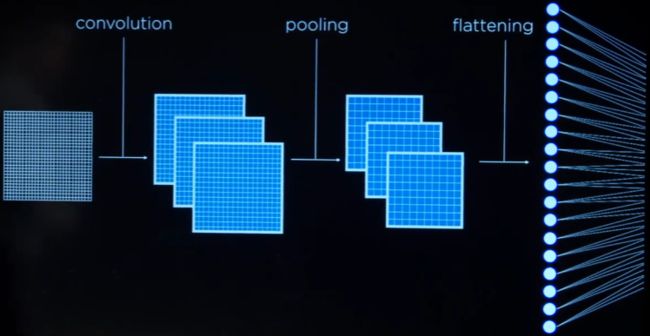
-
卷积和池化的次数通常有很多次
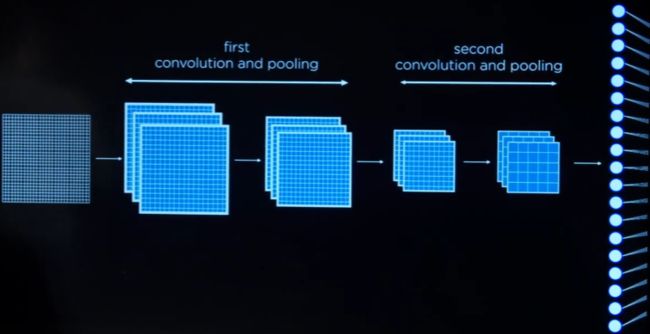
-
import tensorflow as tf
minst = tf.keras.datasets.mnist
(x_train,y_train),(x_test,y_test) = mnist.load_data()
x_train,x_test = x_train /255.0,x_test/255.0
y_train = tf.keras.utils.to_categorical(y_train)
y_test = tf.keras.ytils.to_categorical(y_test)
x_train = x_train.reshape(
x_train.shape[0],x_train.shape[1],x_train.shape[2],1
)
x_test = x_test.reshape(
x_test.shape[0],x_test.shape[1],x_test.shape[2],1
)
#这里是创建CNN的地方
model = tf.keras.models.Sequential([
#第一层是卷积层,模型通过32不同的过滤器,每个过滤器是(3,3)的内核,指定激活函数为activation ="relu",表示输入的形状input_shape=(28,28,1),对于手写数据集是表示28x28像素的网格,只有1个通道值,即黑白的
tf.keras.layers.Conv2D(
32,(3,3),activation ="relu",input_shape=(28,28,1)
),
#最大池化层,使用2x2大小的pool,有助于减少输入的大小
tf.keras.layers.MaxPooling2D(pool_size = (2,2)),
#平整所有单元,进入所有单元?
tf.keras.layers,Flatten(),
#用128向我的神经网络添加一个隐藏层
tf.keras.layers.Dense(128,activation="relu"),
#防止过拟合添加,在训练时,随机从隐藏层中删除一半
tf.keras.layers.Dropout(0.5),
#输出层,有10个输出单元,激活函数为softmax,将输出变为概率分布
tf.keras.layers.Dense(10,activation="softmax")
])
#编译模型
model.compile(
optimizer="adam",
loss ="categorical_carossentroypy",
metrics["accuracy"]
)
#适合所有的训练数据
model.fit(x_train,y_train,epochs=10)
#评估神经网络的性能
model.evaluate(x_test,y_test,verbose=2)
#保存到文件,保存模型到一个文件中,以便之后使用
if len(sys.argv) ==2:
filename = sys.argc[1]
model.save(filename)
print(f"Model saved to {filename}.")
-
feed-forward neural network
neural network that has connections only in one direction.
只有一个方向连接的神经网络。
- 输出的形状是固定的
-
CaptionBot 微软开发的应用,理解图片

-
递归神经网络
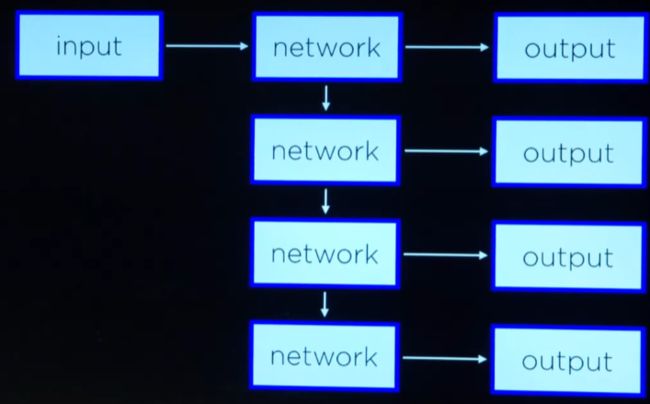
Language
-
Natural Language Processing
-
机器翻译
-
寻找特定的命名
-
语言有歧义,ai要理解有困难
-
Syntax语法
- Just before nine o’clock Sherlock Holmes stepped briskly into the room.
- Just before Sherlock Holmes nine o’clock stepped briskly into the room.
- AI需要知道它们的区别
-
Semantics
- Just before nine o’clock Sherlock Holmes stepped briskly into the room.
- Sherlock Holmes stepped briskly into the room just before nine o’clock.
- 句子结构不同,但是意思相同AI如何去识别
- 语言也可能是没有意义的,无意义的话机器如何去判断
-
formal grammar
a system of rules for generating sentences in a language.
-
Context-Free Grammar
-
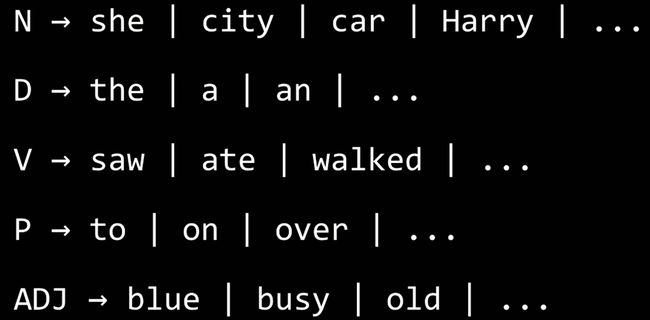
一个简单的句子,希望AI能看出句子的结构,
这里感觉跟编译原理对上了
-
she saw the city
-
N V D N 转换为非终结符
-
重写规则
-
NP(非终结符) -> N(终结符) | DN
-
动词也可以解释为这样的
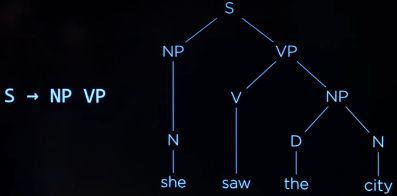
-
-
nltk
import nltk grammar = nltk.CFG.fromstring(""" S-> NP VP NP-> D N | N VP->V|V NP D->"the"|"a" N->"she"|"city"|"car" V->"saw"|"walked" """) parser = nltk.ChartParser(gramar) sentence = input("Sentence:").split() try: for tree in parser.parse(sentence): tree.pretty_print() tree.draw() except ValueError: print("No parse tree possible.") -
n-gram
a contiguous sequence of n items from a sample of text
-
character n-gram
a contiguous sequence of n characters from a sample of text
-
word n-gram
a contiguous sequence of n words from a sample of text
-
unigram
-
bigram
-
trigrams
-
tokenization标记化
- word tokenization
- split
-
通过语义进行预测
-
Markov model
-
Text Categiruzation
- 垃圾邮件和正常邮件
- 评论的情绪是好还是坏
-
bag of words model
model that represents text as an unordered collection of words.
-
Naive Bayes
-
Bayes’ rule
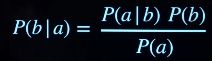

-
-
additive smoothing
adding a value alpha to each value in our distribution to smooth the data
-
Laplace smoothing
adding 1 to each value in our distribution: pretending we ‘ve seen each value one more time than we actually have 给分布中的每个值加1:假装我们看到每个值的次数比实际多一次
-
-
information retrieval
the task of finding relevant documents in response to a user query.
-
topic modeling
models for discovering the topics for a set of documents.
-
term frequency
number of times a term appears in a document.
-
function words 功能词,is ,and 等
-
content words 需要关心的词
-
inverse document frequency
measure of how common or rare a word is across documents

-
tf-idf
ranking of what words are important in a document by multiplying term frequency(TF) by inverse document frequency(IDF)
-
information extraction
the task of extracting knowledge from documents
-
看起来像模板才可用
-
WordNet
- 接受一个单词,显示相关联的信息
-
Word Representation
-
one hot Representation
representation of meaning as a vector with a single 1,and with other values as 0.
-
distribution representation
representation of meaning distributed across multiple values.
you shall know a word by the company it keeps. J.R.Firth
-
word 2 vec
model for generating word vectors
-
skip-gram architecture
neural network architecture for predicting context words given a target word.
-
单词矢量
基于信息语料库,收录语义更相似的地方。