元数据驱动数据存储学习总结笔记
1 背景
日常后台业务开发都会涉及到数据存储问题。每个需求建立新的存储模型并进行开发是常用的手段。随着需求量增多,思考后也会看到一些共性。在数据存储层面。通过有效的抽象,提炼模型,提高系统开发效率。
「元数据驱动的 SaaS 架构技术思考」这篇文章文章讲了通过标准加扩展能力保证数据安全,并支持多租户共性及个性问题构建SaaS产品实现对不同业务模式支持,提供更高效的开发能力。
2 常见业务开发模式
通常基于贫血模型开发,分析完需求,创建数据表,随后开发数据表的CRUD服务。 数据表通常是和需求中的定义完全对应。例如建立一张文章存储表:
CREATE TABLE IF NOT EXISTS `tbl`(
`rid` INT UNSIGNED AUTO_INCREMENT,
`title` VARCHAR(100) NOT NULL,
`author` VARCHAR(40) NOT NULL,
`date` DATE,
PRIMARY KEY ( `runoob_id` )
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
如果需求迭代,通常会遇到表新增字段(修改底层模型),或当前模型不满足要求新建表。随着这种操作变多,我们发现很多操作是类似的。而且这种模型下,经常会对底层数据模型定义修改,复杂点的系统中通常会带来较大的影响。
3 元数据驱动架构概览
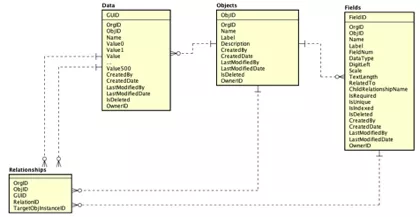
这部分对应学习文章中的4.1。对整体的数据模型进行概述。通过2中的介绍可只,在关系数据库中为了能进行良好的扩展,且不影响系统和底层数据。插入记录是一种好的方式。只要表的抽象能力够好,对底层模型的表更都可以转变为数据库中新增记录的操作。基于此特点引入了下面三个基础模型表(具体定义可以看原文):
- 元数据表
- 数据表
- 功能透视表
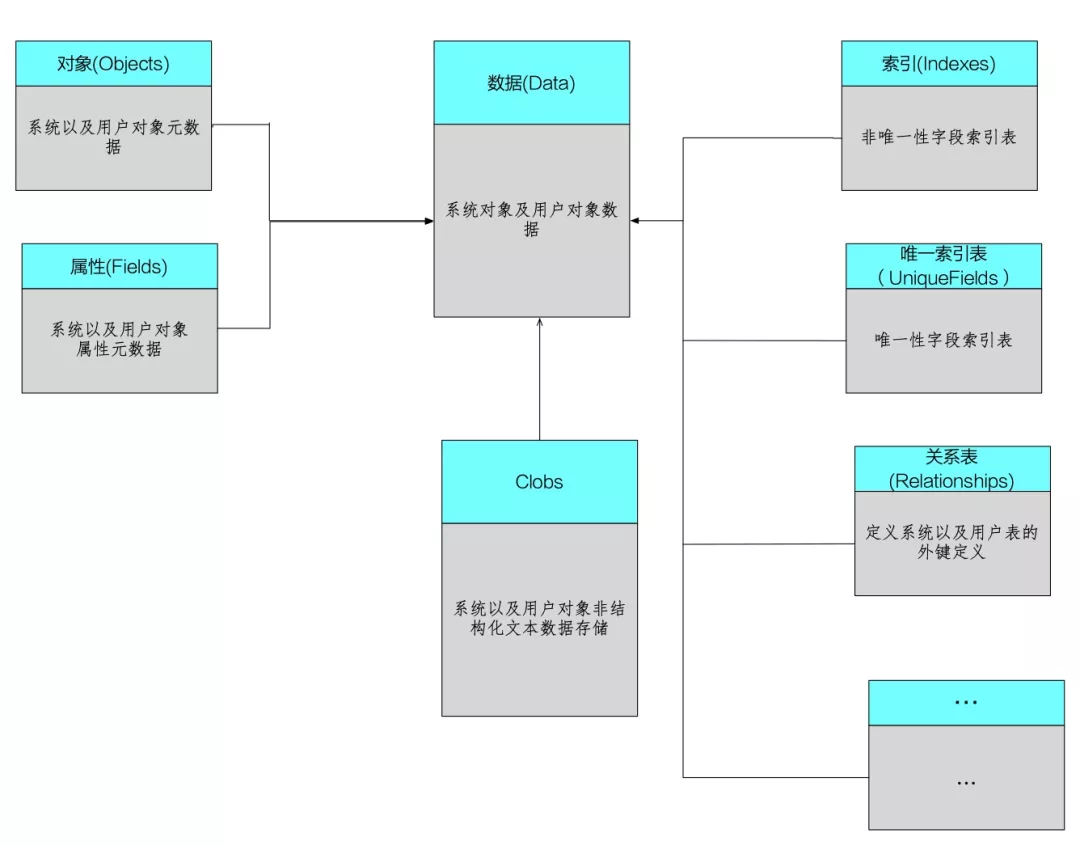
有第二节介绍看,日常开发,表与对象进行映射对应。对象间的关系通过字段进行关联。 因此通过上述模型,将具体的对象通过抽象的对象表描述。此外抽象字段的定义。最终实现对象、属性、数据三者相分离,通过三个抽象对象描述。将传统的表上操作(数据修改、模式修改)转化为抽象表的操作。同理索引及关系的描述也通过相同的方式进行处理。
4 元数据驱动存储详解
本节对应原文4.2。第三节中介绍的数据组织的概览。因此我们实际操作中需求对对象、字段、数据进行描述。
以第二节,文章模型为例。 文章对象对应表需要两个字段。
`title` VARCHAR(100) NOT NULL,
`author` VARCHAR(40) NOT NULL,
在元数据驱动架构下,这个可以抽象看成一个对象、字段、值的描述。
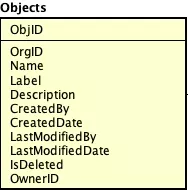
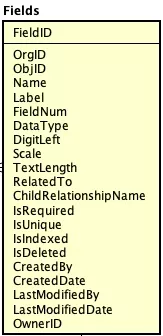
对象就是文章本身,字段是对title、author的抽象,值对应title,author存储的数据。这三个对象可以进行如下定义(详细的字段描述可以参考原文)
对象定义:
字段及所属对象定义:
数据定义: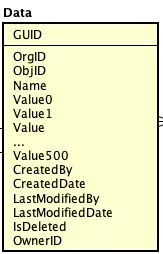
存储针对对象进行,因此抽象数据表将一个对象平铺,增加了500个扩展字段(根据自己的业务特点进行调整,覆盖自己所在业务场景即可)。
同理如果有其它非结构化数据类型,参照同样的思路进行建模扩展。
最终的组织关系如下(详细介绍参考原文):
5 元数据驱动存储示例
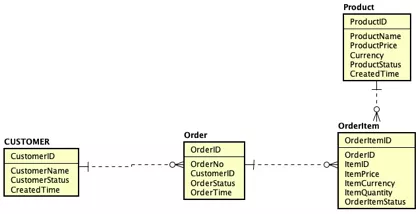
本节对应原文4.6。入前所示,介绍了元数据驱动的基本组织结构。这里通过客户、订单、产品模型对上述问题进行演示。我们要将这个模型转换为由对象、字段、数据、索引构成的模型,实现对具体对象的抽象描述。
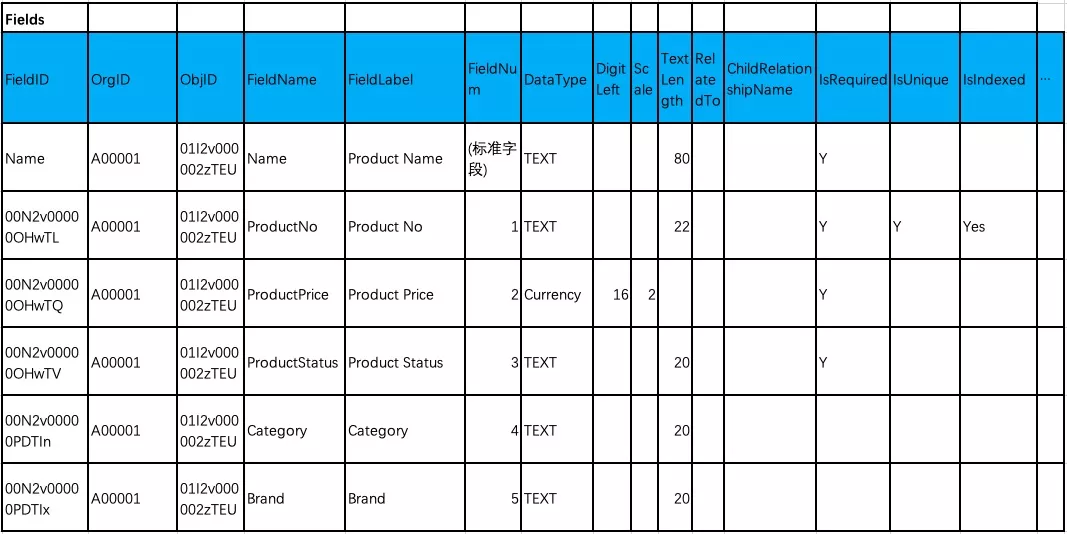
Product的定义:

Product对象字段定义:
同理Customer、Order及OrderItem以同样的方式定义(具体可参考原文)
最后就是对数据表的定义。前面提到数据存储是以对象为维度进行。因此抽象数据表中定义了500个扩展弹性列,用于将一个对象的字段存储于其中。通过读取一个对象的每个字段定义。我们可以找到一个字段具体的存放在哪列。
data表的定义: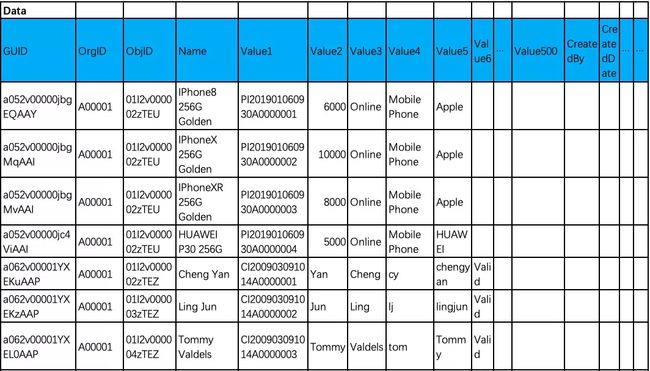
数据表的详细描述可参考原文。 为了保证扩展行,value列均通过变长字符串来描述。具体的解释能力交给上层应用进行解释和验证。可以通过应用层、也可以在关系数据库服务端通过内置函数进行验证转换。
基本的数据模型建立后,查询就成了一个主要问题。查询需要用到索引。而变长字符串列不适合建立索引。因此通过辅助表的思路,建立数据表和辅助索引表的映射实现索引查询的功能。
建立单独的索引透视表,内部维护的字段均未具体的基本类型(数字、日期、字符串),同时建立该表与原表的对应关系。那么查询就转换为先查索引透视表,随后找到数据唯一标识,最终通过标识完成底层数据的查询。
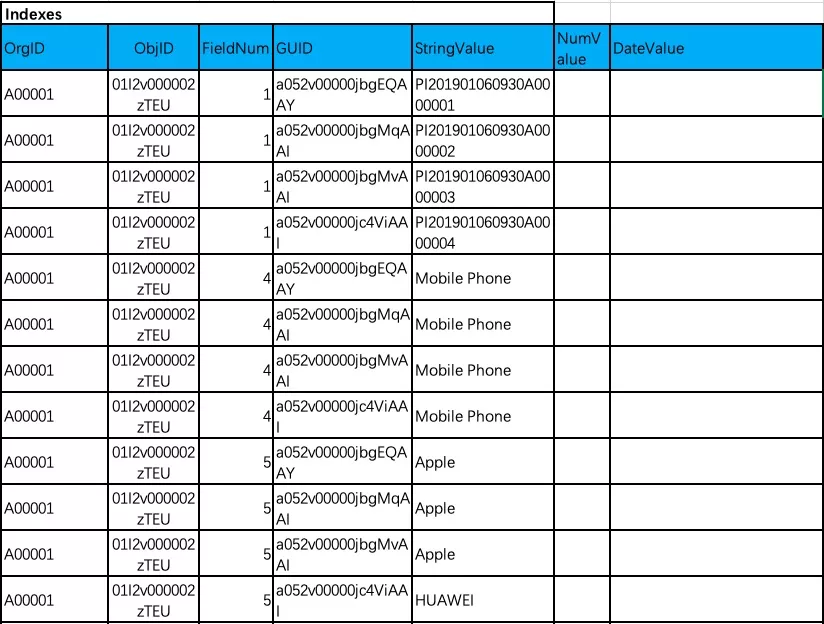
同理唯一索引也采用相似的思路进行。类似的关系表及其它类型的处理都可以采用此思路处理。
这些模型都建立好了,最后就是实现操作的SQL。显然这种模型下,与标准SQL会有不同。我们管这种模型下的查询叫SOQL,与SQL的不同摘录如下:
- 没有 select *
- 没有视图概念
- SOQL 是只读的
- 由于底层元数据驱动的多租户数据模型的限制,索引是受限制的,没有原生数据库物理结构丰富的索引支持。
- 对象到关系的映射 (Object-Relational Mapping) 是自动完成的.
- SObjects 在多租户环境中并不是对应实际的物理数据表
- SObjects 包括 SObjects 之间的关系都是以元数据的方式存储在多租户环境中的。
具体的操作有限制及差异,我们依然通过SQL进行包装变化,实现该目标。
6 大数据量的支持
支撑大数据量依然操作分区思路和传统方式一致。
7 具体业务场景下使用的问题
这篇文章介绍的思路用来构建Saas产品支持大量不同的租户接入。日常我们的业务系统中,租户并不是很多。因此可以考虑简化上述模型。 由于模型是由 对象、字段、数据几大合并部分组成。因此将这些部分特化,适应自己的业务场景即可。
- 对象:如果业务场景下对象稳定,这部分就可以使用固定加扩展模式。例如Key/Value结构列表数据存储。对象就可以具体进行。
- 数据:为了达到较强的普适性,采用了弹性列的机制。显然这样会产生数据空洞。这主要是以对象为维度进行数据存储。如果我们的场景下问题复杂度和数据规模不那么大,再降低到字段维度进行存储,这样减少数据空洞。
- 字段:同数据的场景。规模和复杂度较小可以省略弹性列。
- 索引:如果我们没没有针对值查询的场景,直接采用标识查询,这部分可省略。
- 透视表:方案中引入了透视表,建立辅助索引进行查询。思想类似cqrs。我们也可以采用其它存储系统来完成。如根据业务特点选择或es,hbase
其它部分根据自身业务场景可适当简化。
9 总结
利用当前系统可扩展的能力(关系数据库数据插入不影响结构),通过转化的手段实现系统的扩展和抽象。
参考
[1]元数据驱动的 SaaS 架构与背后的技术思考
,https://mp.weixin.qq.com/s?__biz=MzU4NzU0MDIzOQ==&mid=2247491829&idx=1&sn=733c18107affe153ac3c7a620205ef2a&chksm=fde8d295ca9f5b834d456c63a96048454bafbb060216871c44bea4a6586c338266a5d4f1d602&xtrack=1&scene=0&subscene=93&clicktime=1610705609&enterid=1610705609&ascene=7&devicetype=android-29&version=2700163b&nettype=WIFI&abtest_cookie=AAACAA%3D%3D&lang=zh_CN&exportkey=Ae2LfJwu0cxtSkehmo9qF5w%3D&pass_ticket=6GTIv3711XhoJfOoynxERONuwP5PdJ%2FSdtgpAN4PPYEPb0ZaLMDlEJsd%2FDroRkYp&wx_header=1