实战:部署一套完整的企业级高可用K8s集群(成功测试)-2021.10.20

更新时间
2022年10月14日18:17:39
实验环境
实验环境:
1、win10,vmwrokstation虚机;
2、k8s集群:3台centos7.6 1810虚机,2个master节点,1个node节点
k8s version:v1.20
CONTAINER-RUNTIME:docker://20.10.7
1、硬件环境
3台虚机 2c2g,20g。(nat模式,可访问外网)
| 角色 | 主机名 | ip |
|---|---|---|
| master节点 | k8s-master1 | 172.29.9.41 |
| master节点 | k8s-master2 | 172.29.9.42 |
| node节点 | k8s-node1 | 172.29.9.43 |
| VIP | / | 172.29.9.88 |
注意:
本次复用3个k8s node节点来模拟etcd节点;(注意:这里是测试环境,etcd集群就复用了k8s的3个节点,实际工作环境,可以单独使用机器来组成etcd集群;)
2个master节点来做高可用;
1个工作节点来跑负载;
2、软件环境
| 软件 | 版本 |
|---|---|
| 操作系统 | centos7.6_x64 1810 mini(其他centos7.x版本也行) |
| docker | 20.10.7-ce |
| kubernetes | v1.20.0 |
3、架构图
- 理论图:
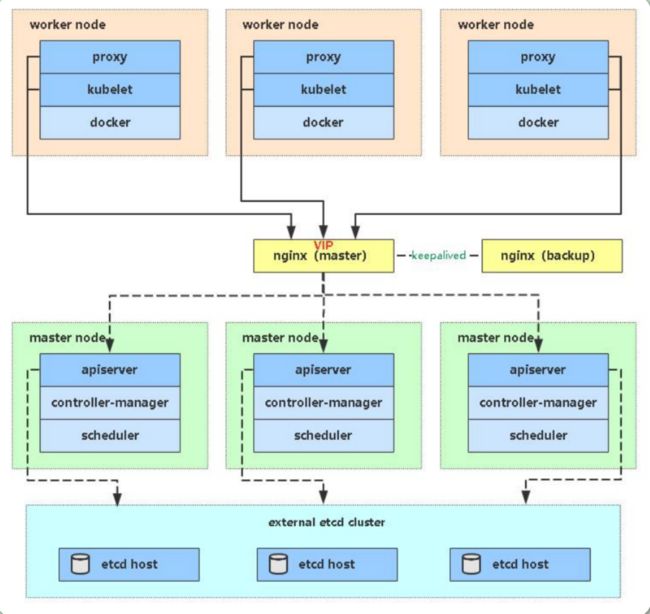
- 实际拓扑图:

实验软件
链接:https://pan.baidu.com/s/1-QDyJBsJizN8SbBHAp-JXQ
提取码:1b25
实验软件:部署一套完整的企业级高可用K8s集群-20211020
1、基础环境配置
all节点均要配置
1.基础信息配置
systemctl stop firewalld && systemctl disable firewalld
systemctl stop NetworkManager && systemctl disable NetworkManager
setenforce 0
sed -i s/SELINUX=enforcing/SELINUX=disabled/ /etc/selinux/config
swapoff -a
sed -ri 's/.*swap.*/#&/' /etc/fstab
cat >> /etc/hosts << EOF
172.29.9.41 k8s-master1
172.29.9.42 k8s-master2
172.29.9.43 k8s-node1
EOF
cat > /etc/sysctl.d/k8s.conf << EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
sysctl --system
yum install ntpdate -y
ntpdate time.windows.com
2.配置3个节点的主机名
hostnamectl --static set-hostname k8s-master1
bash
hostnamectl --static set-hostname k8s-master2
bash
hostnamectl --static set-hostname k8s-node1
bash
3.配置免密
3台机器做一个免密配置:(方便后期从一台机器往剩余机器快速传输文件)
#本次在k8s-master1机器上做操作:
ssh-keygen #连续回车即可
ssh-copy-id -i ~/.ssh/id_rsa.pub [email protected]
ssh-copy-id -i ~/.ssh/id_rsa.pub [email protected]
4.上传本次所需软件
将本次所需软件上传到k8s-master1节点:
做个快照
此时,3个节点的初始化环境配置好了,都记得做一个快照!
2、部署Nginx+Keepalived高可用负载均衡器
(只需在2个master节点配置即可)
1.安装软件包
(master主备节点都要配置)
yum install epel-release -y
yum install nginx keepalived -y
2.Nginx配置文件
(master主,备节点都要配置)
cat > /etc/nginx/nginx.conf << "EOF"
user nginx;
worker_processes auto;
error_log /var/log/nginx/error.log;
pid /run/nginx.pid;
include /usr/share/nginx/modules/*.conf;
events {
worker_connections 1024;
}
# 四层负载均衡,为两台Master apiserver组件提供负载均衡
# 这个strem是为nginx4层负载均衡的一个模块,不使用的https 7层的负载均衡;
stream {
log_format main '$remote_addr $upstream_addr - [$time_local] $status $upstream_bytes_sent';
access_log /var/log/nginx/k8s-access.log main;
upstream k8s-apiserver {
server 172.29.9.41:6443; # Master1 APISERVER IP:PORT,修改为本次master节点的ip即可
server 172.29.9.42:6443; # Master2 APISERVER IP:PORT
}
server {
listen 16443; # 由于nginx与master节点复用,这个监听端口不能是6443,否则会冲突
proxy_pass k8s-apiserver;
}
}
http {
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
sendfile on;
tcp_nopush on;
tcp_nodelay on;
keepalive_timeout 65;
types_hash_max_size 2048;
include /etc/nginx/mime.types;
default_type application/octet-stream;
}
EOF
3.keepalived配置文件
1、Nginx Master上配置
cat > /etc/keepalived/keepalived.conf << EOF
global_defs {
notification_email {
[email protected]
[email protected]
[email protected]
}
notification_email_from [email protected]
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id NGINX_MASTER
}
vrrp_script check_nginx {
script "/etc/keepalived/check_nginx.sh"
}
vrrp_instance VI_1 {
state MASTER
interface ens33 # 修改为实际网卡名
virtual_router_id 51 # VRRP 路由 ID实例,每个实例是唯一的
priority 100 # 优先级,备服务器设置 90
advert_int 1 # 指定VRRP 心跳包通告间隔时间,默认1秒
authentication {
auth_type PASS
auth_pass 1111
}
# 虚拟IP
virtual_ipaddress {
172.29.9.88/16
}
track_script {
check_nginx
}
}
EOF
• vrrp_script:指定检查nginx工作状态脚本(根据nginx状态判断是否故障转移)
• virtual_ipaddress:虚拟IP(VIP)
准备上述配置文件中检查nginx运行状态的脚本:
cat > /etc/keepalived/check_nginx.sh << "EOF"
#!/bin/bash
count=$(ss -antp |grep 16443 |egrep -cv "grep|$$")
if [ "$count" -eq 0 ];then
exit 1
else
exit 0
fi
EOF
chmod +x /etc/keepalived/check_nginx.sh
2、Nginx Backup上配置
cat > /etc/keepalived/keepalived.conf << EOF
global_defs {
notification_email {
[email protected]
[email protected]
[email protected]
}
notification_email_from [email protected]
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id NGINX_BACKUP
}
vrrp_script check_nginx {
script "/etc/keepalived/check_nginx.sh"
}
vrrp_instance VI_1 {
state BACKUP
interface ens33
virtual_router_id 51 # VRRP 路由 ID实例,每个实例是唯一的
priority 90 #backup这里为90
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
172.29.9.88/16 #VIP
}
track_script {
check_nginx
}
}
EOF
- 准备上述配置文件中检查nginx运行状态的脚本:
cat > /etc/keepalived/check_nginx.sh << "EOF"
#!/bin/bash
count=$(ss -antp |grep 16443 |egrep -cv "grep|$$")
if [ "$count" -eq 0 ];then
exit 1
else
exit 0
fi
EOF
chmod +x /etc/keepalived/check_nginx.sh
注意:
注:keepalived根据脚本返回状态码(0为工作正常,非0不正常)判断是否故障转移。
4.启动并设置开机启动
(2个master节点上都要配置)
systemctl daemon-reload
systemctl start nginx
systemctl start keepalived
systemctl enable nginx
systemctl enable keepalived
- 注意:在启动nginx时会报错
我们通过journalctl -u nginx发现ngixn报错原因:是现在的nginx版本里面不包含stream模块了,从而导致报错:
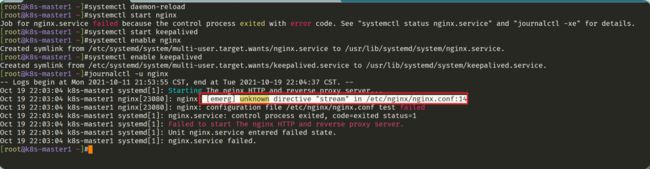
- 可能需要我们单独去装下了:
[root@k8s-master1 ~]#yum search stream|grep nginx
nginx-mod-stream.x86_64 : Nginx stream modules
yum install -y nginx-mod-stream
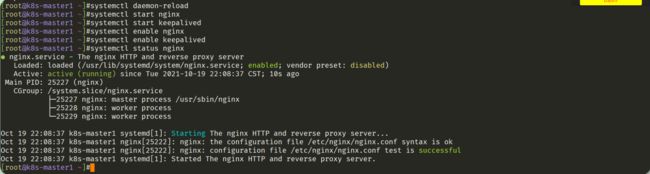
- 再次启动:就ok了,这2个步骤在2个master节点都执行一遍。
systemctl daemon-reload
systemctl start nginx
systemctl start keepalived
systemctl enable nginx
systemctl enable keepalived
5.查看keepalived工作状态
在master节点查看:

可以看到,在ens33网卡绑定了172.29.9…88 虚拟IP,说明工作正常。
6.Nginx+Keepalived高可用测试
- 测试方法:
关闭主节点Nginx,测试VIP是否漂移到备节点服务器。
在Nginx Master执行 pkill nginx
在Nginx Backup,ip addr命令查看已成功绑定VIP。
- 实际测试过程
首先我们在nginx master节点上看下ip情况:
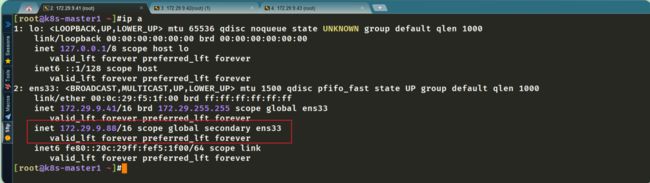
再从winodws上长ping下这个VIP:
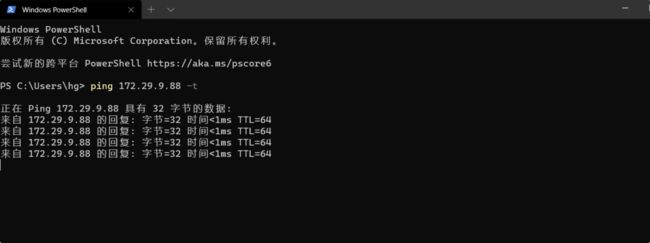
此时,在nginx master节点上查看nginx状态,并执行pkill nginx命令:
[root@k8s-master1 ~]#ss -antup|grep nginx
tcp LISTEN 0 128 *:16443 *:* users:(("nginx",pid=25229,fd=7),("nginx",pid=25228,fd=7),("nginx",pid=25227,fd=7))
[root@k8s-master1 ~]#pkill nginx
[root@k8s-master1 ~]#ss -antup|grep nginx
[root@k8s-master1 ~]#
![]()
再在nginx master节点上确认nginx状态,及看下ping测试情况:此时会丢一个包的。

在Nginx Backup,ip addr命令查看已成功绑定VIP:
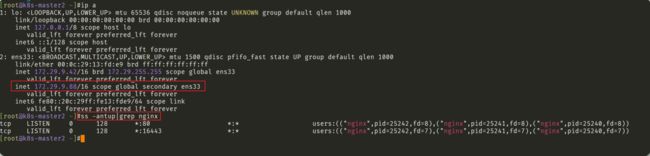
符合预期现象。
此时再启动master节点上的nginx,并再次观察现象:
注意:keepalived在切换VIP时会丢1个包的。

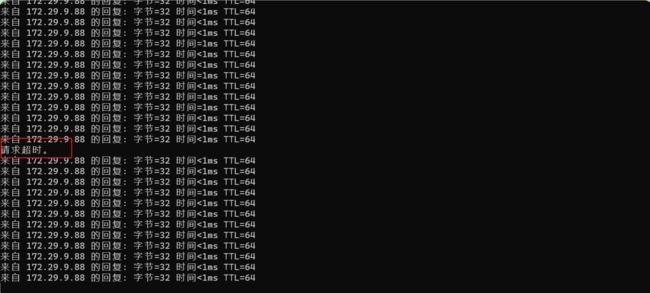

结论
01、master节点和backup节点都是有nginx服务在运行的;
02、keepalived在切换VIP时会丢1个包的; Keepalived是一个主流高可用软件,基于VIP绑定实现服务器双机热备,在上述拓扑中,Keepalived主要根据Nginx运行状态判断是否需要故障转移(偏移VIP),例如当Nginx主节点挂掉,VIP会自动绑定在Nginx备节点,从而保证VIP一直可用,实现Nginx高可用。
03、注意nginx服务;

3、部署Etcd集群
(只需在etcd节点配置即可,但本次复用3个node节点来作为etcd使用,因此三个都需要配置)
1.准备cfssl证书生成工具
cfssl是一个开源的证书管理工具,使用json文件生成证书,相比openssl更方便使用。
找任意一台服务器操作,这里用k8s-master1节点。
1、自己下载软件方法
wget https://pkg.cfssl.org/R1.2/cfssl_linux-amd64
wget https://pkg.cfssl.org/R1.2/cfssljson_linux-amd64
wget https://pkg.cfssl.org/R1.2/cfssl-certinfo_linux-amd64
#注意,以上链接若打不开,直接使用我提供的软件即可!
chmod +x cfssl*
for x in cfssl*; do mv $x ${x%*_linux-amd64}; done
mv cfssl* /usr/bin
2、使用我的软件:
#上传我的软件到机器上
mv cfssl* /usr/bin
2. 生成Etcd证书
1. 自签证书颁发机构(CA)
- 创建工作目录:
mkdir -p ~/etcd_tls
cd ~/etcd_tls
- 自签CA:
cat > ca-config.json << EOF
{
"signing": {
"default": {
"expiry": "87600h"
},
"profiles": {
"www": {
"expiry": "87600h",
"usages": [
"signing",
"key encipherment",
"server auth",
"client auth"
]
}
}
}
}
EOF
cat > ca-csr.json << EOF
{
"CN": "etcd CA",
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "Beijing",
"ST": "Beijing"
}
]
}
EOF
- 生成证书:
cfssl gencert -initca ca-csr.json | cfssljson -bare ca -
会生成ca.pem和ca-key.pem文件。
2. 使用自签CA签发Etcd HTTPS证书
- 创建证书申请文件:
cat > server-csr.json << EOF
{
"CN": "etcd",
"hosts": [
"172.29.9.41",
"172.29.9.42",
"172.29.9.43"
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "BeiJing",
"ST": "BeiJing"
}
]
}
EOF
注意:上述文件hosts字段中IP为所有etcd节点的集群内部通信IP,一个都不能少!为了方便后期扩容可以多写几个预留的IP。多写几个etcd ip可以,但是少写的话,如果后期要扩容,就需要重新生成证书,比较麻烦些;
- 生成证书:
cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=www server-csr.json | cfssljson -bare server
会生成server.pem和server-key.pem文件。
3.从Github下载二进制文件
下载地址:https://github.com/etcd-io/etcd/releases/download/v3.4.9/etcd-v3.4.9-linux-amd64.tar.gz
这里直接使用我提供的软件即可!
- 将etcd软件上传到k8s-master节点上;
[root@k8s-master1 ~]#ll
total 18044
-r--------. 1 root root 545894 May 30 10:57 centos7-init.zip
drwxr-xr-x 2 root root 174 Oct 19 22:28 etcd_tls
-rw-r--r-- 1 root root 17364053 Oct 19 22:31 etcd-v3.4.9-linux-amd64.tar.gz
-rw-r--r--. 1 root root 560272 May 30 10:48 wget-1.14-18.el7_6.1.x86_64.rpm
[root@k8s-master1 ~]#
4.部署Etcd集群
(以下在节点1上操作,为简化操作,待会将节点1生成的所有文件拷贝到节点2和节点3。)
1.创建工作目录并解压二进制包
mkdir /opt/etcd/{bin,cfg,ssl} -p
cd /root/
tar zxvf etcd-v3.4.9-linux-amd64.tar.gz
mv etcd-v3.4.9-linux-amd64/{etcd,etcdctl} /opt/etcd/bin/
2. 创建etcd配置文件
注释版:
cat > /opt/etcd/cfg/etcd.conf << EOF
#[Member]
ETCD_NAME="etcd-1"
ETCD_DATA_DIR="/var/lib/etcd/default.etcd"
ETCD_LISTEN_PEER_URLS="https://172.29.9.41:2380" #2380是 集群通信的端口;
ETCD_LISTEN_CLIENT_URLS="https://172.29.9.41:2379" #2379是指它的数据端口,其他客户端要访问etcd数据库的读写都走的是这个端口;
#[Clustering]
ETCD_INITIAL_ADVERTISE_PEER_URLS="https://172.29.9.41:2380"
ETCD_ADVERTISE_CLIENT_URLS="https://172.29.9.41:2379"
ETCD_INITIAL_CLUSTER="etcd-1=https://172.29.9.41:2380,etcd-2=https://172.29.9.42:2380,etcd-3=https://172.29.9.43:2380"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster" #一种简单的认证机制,网络里可能配置了多套k8s集群,防止误同步;
ETCD_INITIAL_CLUSTER_STATE="new"
EOF
•ETCD_NAME:节点名称,集群中唯一
•ETCD_DATADIR:数据目录
•ETCD_LISTEN_PEER_URLS:集群通信监听地址
•ETCD_LISTEN_CLIENT_URLS:客户端访问监听地址
•ETCD_INITIAL_ADVERTISE_PEER_URLS:集群通告地址
•ETCD_ADVERTISE_CLIENT_URLS:客户端通告地址
•ETCD_INITIAL_CLUSTER:集群节点地址
•ETCD_INITIAL_CLUSTER_TOKEN:集群Token
•ETCD_INITIAL_CLUSTER_STATE:加入集群的当前状态,new是新集群,existing表示加入已有集群
最终配置版:
cat > /opt/etcd/cfg/etcd.conf << EOF
#[Member]
ETCD_NAME="etcd-1"
ETCD_DATA_DIR="/var/lib/etcd/default.etcd"
ETCD_LISTEN_PEER_URLS="https://172.29.9.41:2380"
ETCD_LISTEN_CLIENT_URLS="https://172.29.9.41:2379"
#[Clustering]
ETCD_INITIAL_ADVERTISE_PEER_URLS="https://172.29.9.41:2380"
ETCD_ADVERTISE_CLIENT_URLS="https://172.29.9.41:2379"
ETCD_INITIAL_CLUSTER="etcd-1=https://172.29.9.41:2380,etcd-2=https://172.29.9.42:2380,etcd-3=https://172.29.9.43:2380"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_INITIAL_CLUSTER_STATE="new"
EOF
3.systemd管理etcd
cat > /usr/lib/systemd/system/etcd.service << EOF
[Unit]
Description=Etcd Server
After=network.target
After=network-online.target
Wants=network-online.target
[Service]
Type=notify
EnvironmentFile=/opt/etcd/cfg/etcd.conf
ExecStart=/opt/etcd/bin/etcd \
--cert-file=/opt/etcd/ssl/server.pem \
--key-file=/opt/etcd/ssl/server-key.pem \
--trusted-ca-file=/opt/etcd/ssl/ca.pem \
--peer-cert-file=/opt/etcd/ssl/server.pem \
--peer-key-file=/opt/etcd/ssl/server-key.pem \
--peer-trusted-ca-file=/opt/etcd/ssl/ca.pem \
--logger=zap
Restart=on-failure
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
EOF
4.拷贝刚才生成的证书
把刚才生成的证书拷贝到配置文件中的路径:
cp ~/etcd_tls/ca*pem ~/etcd_tls/server*pem /opt/etcd/ssl/
5.启动并设置开机启动
systemctl daemon-reload
systemctl start etcd
systemctl enable etcd
注意:第一个etcd服务启动很定会很慢,肯定会失败的;
为什么呢?
journalctl -u etcd -f #查看日志
dial tcp 172.29.9.43:2380: conet: connection refused
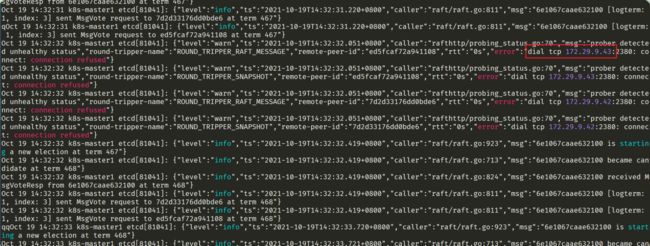
注意:
通过查看日志可以看到,链接etcd另外2个节点报错,因此另外2个etcd节点的服务也需要起起来才行。
6.将上面节点1所有生成的文件拷贝到节点2和节点3
scp -r /opt/etcd/ [email protected]:/opt/
scp /usr/lib/systemd/system/etcd.service [email protected]:/usr/lib/systemd/system/
scp -r /opt/etcd/ [email protected]:/opt/
scp /usr/lib/systemd/system/etcd.service [email protected]:/usr/lib/systemd/system/
然后在节点2和节点3分别修改etcd.conf配置文件中的节点名称和当前服务器IP:
vi /opt/etcd/cfg/etcd.conf
#[Member]
ETCD_NAME="etcd-1" # 修改此处,节点2改为etcd-2,节点3改为etcd-3
ETCD_DATA_DIR="/var/lib/etcd/default.etcd"
ETCD_LISTEN_PEER_URLS="https://192.168.31.71:2380" # 修改此处为当前服务器IP
ETCD_LISTEN_CLIENT_URLS="https://192.168.31.71:2379" # 修改此处为当前服务器IP
#[Clustering]
ETCD_INITIAL_ADVERTISE_PEER_URLS="https://192.168.31.71:2380" # 修改此处为当前服务器IP
ETCD_ADVERTISE_CLIENT_URLS="https://192.168.31.71:2379" # 修改此处为当前服务器IP
ETCD_INITIAL_CLUSTER="etcd-1=https://192.168.31.71:2380,etcd-2=https://192.168.31.72:2380,etcd-3=https://192.168.31.73:2380"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_INITIAL_CLUSTER_STATE="new"
- 最终配置:
#k8s-node1-172.29.9.42上配置
cat > /opt/etcd/cfg/etcd.conf << EOF
#[Member]
ETCD_NAME="etcd-2"
ETCD_DATA_DIR="/var/lib/etcd/default.etcd"
ETCD_LISTEN_PEER_URLS="https://172.29.9.42:2380"
ETCD_LISTEN_CLIENT_URLS="https://172.29.9.42:2379"
#[Clustering]
ETCD_INITIAL_ADVERTISE_PEER_URLS="https://172.29.9.42:2380"
ETCD_ADVERTISE_CLIENT_URLS="https://172.29.9.42:2379"
ETCD_INITIAL_CLUSTER="etcd-1=https://172.29.9.41:2380,etcd-2=https://172.29.9.42:2380,etcd-3=https://172.29.9.43:2380"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_INITIAL_CLUSTER_STATE="new"
EOF
#k8s-node1-172.29.9.43上配置
cat > /opt/etcd/cfg/etcd.conf << EOF
#[Member]
ETCD_NAME="etcd-3"
ETCD_DATA_DIR="/var/lib/etcd/default.etcd"
ETCD_LISTEN_PEER_URLS="https://172.29.9.43:2380"
ETCD_LISTEN_CLIENT_URLS="https://172.29.9.43:2379"
#[Clustering]
ETCD_INITIAL_ADVERTISE_PEER_URLS="https://172.29.9.43:2380"
ETCD_ADVERTISE_CLIENT_URLS="https://172.29.9.43:2379"
ETCD_INITIAL_CLUSTER="etcd-1=https://172.29.9.41:2380,etcd-2=https://172.29.9.42:2380,etcd-3=https://172.29.9.43:2380"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_INITIAL_CLUSTER_STATE="new"
EOF
- 最后启动etcd并设置开机启动,同上。
systemctl daemon-reload
systemctl start etcd
systemctl enable etcd
7. 查看集群状态
[root@k8s-master1 ~]#ETCDCTL_API=3 /opt/etcd/bin/etcdctl --cacert=/opt/etcd/ssl/ca.pem --cert=/opt/etcd/ssl/server.pem --key=/opt/etcd/ssl/server-key.pem --endpoints="https://172.29.9.41:2379,https://172.29.9.42:2379,https://172.29.9.43:2379" endpoint health --write-out=table

如果输出上面信息,就说明集群部署成功。
如果有问题第一步先看日志:/var/log/message 或 journalctl -u etcd
4、安装Docker/kubeadm/kubelet
1.安装Docker
yum install -y yum-utils device-mapper-persistent-data lvm2
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
yum install -y yum install docker-ce-20.10.7 docker-ce-cli-20.10.7 containerd.io
systemctl start docker && systemctl enable docker
mkdir -p /etc/docker
tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors":["https://dockerhub.azk8s.cn","http://hub-mirror.c.163.com","http://qtid6917.mirror.aliyuncs.com"]
}
EOF
echo "net.ipv4.ip_forward = 1" >> /etc/sysctl.conf
sysctl -p
systemctl daemon-reload
systemctl restart docker
2.添加阿里云YUM软件源
cat > /etc/yum.repos.d/kubernetes.repo << EOF
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
3.安装kubeadm,kubelet和kubectl
由于版本更新频繁,这里指定版本号部署:
yum install -y kubelet-1.20.0 kubeadm-1.20.0 kubectl-1.20.0
systemctl enable kubelet
5、部署Kubernetes Master
1.初始化Master1
(在k8s-master1上操作)
- 生成初始化配置文件:
cat > kubeadm-config.yaml << EOF
apiVersion: kubeadm.k8s.io/v1beta2
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: 9037x2.tcaqnpaqkra9vsbw
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 172.29.9.41
bindPort: 6443
nodeRegistration:
criSocket: /var/run/dockershim.sock
name: k8s-master1
taints:
- effect: NoSchedule
key: node-role.kubernetes.io/master
---
apiServer:
certSANs: # 包含所有Master/LB/VIP IP,一个都不能少!为了方便后期扩容可以多写几个预留的IP。
- k8s-master1
- k8s-master2
- 172.29.9.41
- 172.29.9.42
- 172.29.9.88
- 127.0.0.1
extraArgs:
authorization-mode: Node,RBAC
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta2
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controlPlaneEndpoint: 172.29.9.88:16443 # 负载均衡虚拟IP(VIP)和端口
controllerManager: {}
dns:
type: CoreDNS
etcd:
external: # 使用外部etcd
endpoints:
- https://172.29.9.41:2379 # etcd集群3个节点
- https://172.29.9.42:2379
- https://172.29.9.43:2379
caFile: /opt/etcd/ssl/ca.pem # 连接etcd所需证书
certFile: /opt/etcd/ssl/server.pem
keyFile: /opt/etcd/ssl/server-key.pem
imageRepository: registry.aliyuncs.com/google_containers # 由于默认拉取镜像地址k8s.gcr.io国内无法访问,这里指定阿里云镜像仓库地址
kind: ClusterConfiguration
kubernetesVersion: v1.20.0 # K8s版本,与上面安装的一致
networking:
dnsDomain: cluster.local
podSubnet: 10.244.0.0/16 # Pod网络,与下面部署的CNI网络组件yaml中保持一致
serviceSubnet: 10.96.0.0/12 # 集群内部虚拟网络,Pod统一访问入口
scheduler: {}
EOF
- 使用配置文件引导:
[root@k8s-master1 ~]#kubeadm init --config kubeadm-config.yaml
[init] Using Kubernetes version: v1.20.0
[preflight] Running pre-flight checks
[WARNING IsDockerSystemdCheck]: detected "cgroupfs" as the Docker cgroup driver. The recommended driver is "systemd". Please follow the guide at https://kubernetes.io/docs/setup/cri/
[WARNING SystemVerification]: this Docker version is not on the list of validated versions: 20.10.9. Latest validated version: 19.03
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[certs] Generating "ca" certificate and key
[certs] Generating "apiserver" certificate and key
[certs] apiserver serving cert is signed for DNS names [k8s-master1 k8s-master2 kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local] and IPs [10.96.0.1 172.29.9.41 172.29.9.88 172.29.9.42 127.0.0.1]
[certs] Generating "apiserver-kubelet-client" certificate and key
[certs] Generating "front-proxy-ca" certificate and key
[certs] Generating "front-proxy-client" certificate and key
[certs] External etcd mode: Skipping etcd/ca certificate authority generation
[certs] External etcd mode: Skipping etcd/server certificate generation
[certs] External etcd mode: Skipping etcd/peer certificate generation
[certs] External etcd mode: Skipping etcd/healthcheck-client certificate generation
[certs] External etcd mode: Skipping apiserver-etcd-client certificate generation
[certs] Generating "sa" key and public key
[kubeconfig] Using kubeconfig folder "/etc/kubernetes"
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[kubeconfig] Writing "admin.conf" kubeconfig file
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[kubeconfig] Writing "kubelet.conf" kubeconfig file
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[kubeconfig] Writing "controller-manager.conf" kubeconfig file
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[kubeconfig] Writing "scheduler.conf" kubeconfig file
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Starting the kubelet
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
[control-plane] Creating static Pod manifest for "kube-scheduler"
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s
[apiclient] All control plane components are healthy after 17.036041 seconds
[upload-config] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace
[kubelet] Creating a ConfigMap "kubelet-config-1.20" in namespace kube-system with the configuration for the kubelets in the cluster
[upload-certs] Skipping phase. Please see --upload-certs
[mark-control-plane] Marking the node k8s-master1 as control-plane by adding the labels "node-role.kubernetes.io/master=''" and "node-role.kubernetes.io/control-plane='' (deprecated)"
[mark-control-plane] Marking the node k8s-master1 as control-plane by adding the taints [node-role.kubernetes.io/master:NoSchedule]
[bootstrap-token] Using token: 9037x2.tcaqnpaqkra9vsbw
[bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles
[bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to get nodes
[bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials
[bootstrap-token] configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token
[bootstrap-token] configured RBAC rules to allow certificate rotation for all node client certificates in the cluster
[bootstrap-token] Creating the "cluster-info" ConfigMap in the "kube-public" namespace
[kubelet-finalize] Updating "/etc/kubernetes/kubelet.conf" to point to a rotatable kubelet client certificate and key
[addons] Applied essential addon: CoreDNS
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[addons] Applied essential addon: kube-proxy
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of control-plane nodes by copying certificate authorities
and service account keys on each node and then running the following as root:
kubeadm join 172.29.9.88:16443 --token 9037x2.tcaqnpaqkra9vsbw \
--discovery-token-ca-cert-hash sha256:b83d62021daef2cd62c0c19ee0f45adf574c2eaf1de28f0e6caafdabdf95951d \
--control-plane
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 172.29.9.88:16443 --token 9037x2.tcaqnpaqkra9vsbw \
--discovery-token-ca-cert-hash sha256:b83d62021daef2cd62c0c19ee0f45adf574c2eaf1de28f0e6caafdabdf95951d
初始化完成后,会有两个join的命令,带有 --control-plane 是用于加入组建多master集群的,不带的是加入节点的。
拷贝kubectl使用的连接k8s认证文件到默认路径:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
[root@k8s-master1 ~]#kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-master1 NotReady control-plane,master 7m34s v1.20.0
[root@k8s-master1 ~]#
2.初始化Master2
此时,若我们直接在k8s-master2节点上使用提示的命令join时会报错:

注意:我们再加入master2,执行这条命令的时候,实际上只是初始化生成了一些配置文件而已,但是他那个证书,它没有再给你重新初始化了,因为你作为第二个控制面板加入集群了,它证书不再给你重新初始化,这主要是因为你是同一个集群,因为它再重新给你初始化根证书等证书,会导致你集群里的证书不一致现象,那么就会带来后面很多关于证书方面的问题。所以我们要部署第二个节点的时候,我们要把第一个节点的证书拷贝过来,就不能再重新生成一套独立的证书了,包括后面的授权等都是基于这1套证书去实现的。
- 将Master1节点生成的证书拷贝到Master2:
scp -r /etc/kubernetes/pki/ 172.29.9.42:/etc/kubernetes/
- 复制加入master join命令在master2执行:
kubeadm join 172.29.9.88:16443 --token 9037x2.tcaqnpaqkra9vsbw \
--discovery-token-ca-cert-hash sha256:b83d62021daef2cd62c0c19ee0f45adf574c2eaf1de28f0e6caafdabdf95951d \
--control-plane
此时观看,发现加入成功!
拷贝kubectl使用的连接k8s认证文件到默认路径:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
[root@k8s-master2 ~]#kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-master1 NotReady control-plane,master 14m v1.20.0
k8s-master2 NotReady control-plane,master 30s v1.20.0
[root@k8s-master2 ~]#
注:由于网络插件还没有部署,还没有准备就绪 NotReady。
3.访问负载均衡器测试
找K8s集群中任意一个节点,使用curl查看K8s版本测试,使用VIP访问:
本次使用k8s-master2节点跑这个测试命令:多执行几次。
[root@k8s-master2 ~]#curl -k https://172.29.9.88:16443/version
{
"major": "1",
"minor": "20",
"gitVersion": "v1.20.0",
"gitCommit": "af46c47ce925f4c4ad5cc8d1fca46c7b77d13b38",
"gitTreeState": "clean",
"buildDate": "2020-12-08T17:51:19Z",
"goVersion": "go1.15.5",
"compiler": "gc",
"platform": "linux/amd64"
}[root@k8s-master2 ~]#
可以正确获取到K8s版本信息,说明负载均衡器搭建正常。该请求数据流程:curl -> vip(nginx) -> apiserver
- 通过查看Nginx日志也可以看到转发apiserver IP:这个在k8s-master1节点上测试
tail /var/log/nginx/k8s-access.log -f

测试成功。
6、加入Kubernetes Node
在172.29.9.43(Node1)执行。
- 向集群添加新节点,执行在kubeadm init输出的kubeadm join命令:
[root@k8s-master1 ~]#kubeadm token create --print-join-command
kubeadm join 172.29.9.88:16443 --token vh0mrh.9s60jligjkrduacj --discovery-token-ca-cert-hash sha256:b83d62021daef2cd62c0c19ee0f45adf574c2eaf1de28f0e6caafdabdf95951d
[root@k8s-master1 ~]#
后续其他节点也是这样加入。
注:默认token有效期为24小时,当过期之后,该token就不可用了。这时就需要重新创建token,可以直接在master节点直接使用命令快捷生成:kubeadm token create --print-join-command
7、部署网络组件
Calico是一个纯三层的数据中心网络方案,是目前Kubernetes主流的网络方案。
- 部署Calico:
kubectl apply -f calico.yaml
kubectl get pod -A

- 等Calico Pod都Running,节点也会准备就绪:
[root@k8s-master1 ~]#kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-master1 Ready control-plane,master 29m v1.20.0
k8s-master2 Ready control-plane,master 24m v1.20.0
k8s-node1 Ready <none> 16m v1.20.0
[root@k8s-master1 ~]#
8、部署 Dashboard
Dashboard是官方提供的一个UI,可用于基本管理K8s资源。
kubectl apply -f kubernetes-dashboard.yaml
查看部署
kubectl get pods -n kubernetes-dashboard
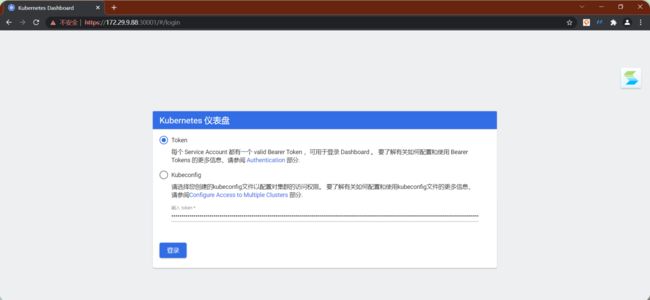
访问地址:https://NodeIP:30001
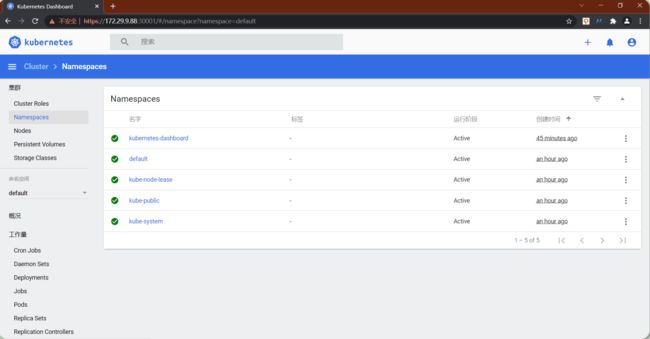
创建service account并绑定默认cluster-admin管理员集群角色:
kubectl create serviceaccount dashboard-admin -n kube-system
kubectl create clusterrolebinding dashboard-admin --clusterrole=cluster-admin --serviceaccount=kube-system:dashboard-admin
kubectl describe secrets -n kube-system $(kubectl -n kube-system get secret | awk '/dashboard-admin/{print $1}')
- 使用输出的token登录Dashboard。
以上步骤都做完后,记得为这3个节点做一个快照,方便后面集群损坏,从而快速恢复集群。
引用
感谢阿良老师的分享。
关于我
我的博客主旨:
- 排版美观,语言精炼;
- 文档即手册,步骤明细,拒绝埋坑,提供源码;
- 本人实战文档都是亲测成功的,各位小伙伴在实际操作过程中如有什么疑问,可随时联系本人帮您解决问题,让我们一起进步!
微信二维码
x2675263825 (舍得), qq:2675263825。

微信公众号
《云原生架构师实战》

语雀
https://www.yuque.com/xyy-onlyone

博客
www.onlyyou520.com

csdn
https://blog.csdn.net/weixin_39246554?spm=1010.2135.3001.5421
知乎
https://www.zhihu.com/people/foryouone
最后
好了,关于本次就到这里了,感谢大家阅读,最后祝大家生活快乐,每天都过的有意义哦,我们下期见!
nt并绑定默认cluster-admin管理员集群角色:
kubectl create serviceaccount dashboard-admin -n kube-system
kubectl create clusterrolebinding dashboard-admin --clusterrole=cluster-admin --serviceaccount=kube-system:dashboard-admin
kubectl describe secrets -n kube-system $(kubectl -n kube-system get secret | awk '/dashboard-admin/{print $1}')
- 使用输出的token登录Dashboard。
[外链图片转存中…(img-3jOCsbLY-1665820529257)]
[外链图片转存中…(img-q7ZXbAQV-1665820529257)]
以上步骤都做完后,记得为这3个节点做一个快照,方便后面集群损坏,从而快速恢复集群。
引用
感谢阿良老师的分享。
关于我
我的博客主旨:
- 排版美观,语言精炼;
- 文档即手册,步骤明细,拒绝埋坑,提供源码;
- 本人实战文档都是亲测成功的,各位小伙伴在实际操作过程中如有什么疑问,可随时联系本人帮您解决问题,让我们一起进步!
微信二维码
x2675263825 (舍得), qq:2675263825。
[外链图片转存中…(img-6ejvRoXy-1665820529258)]
微信公众号
《云原生架构师实战》
[外链图片转存中…(img-VoegvemB-1665820529258)]
语雀
https://www.yuque.com/xyy-onlyone
[外链图片转存中…(img-xW6opgtv-1665820529258)]
博客
www.onlyyou520.com
[外链图片转存中…(img-lGymbKlv-1665820529258)]
[外链图片转存中…(img-weXSRuYZ-1665820529259)]
csdn
https://blog.csdn.net/weixin_39246554?spm=1010.2135.3001.5421
[外链图片转存中…(img-bpM7EbZK-1665820529259)]
知乎
https://www.zhihu.com/people/foryouone
[外链图片转存中…(img-A1RVi2RR-1665820529259)]
最后
好了,关于本次就到这里了,感谢大家阅读,最后祝大家生活快乐,每天都过的有意义哦,我们下期见!
