Hadoop大数据技术课程总结2021-2022学年第1学期
文章目录
- Hadoop大数据技术课程总结
-
- 1.大数据概述
-
- 1.1大数据时代的4V
- 1.2大数据时代的三次浪潮
- 1.3大数据时代的技术支撑
- 1.4谷歌的3篇论文
- 1.5Hadoop集群规模
- 1.6Hadoop安装过程
- 2.HDFS专题
-
- 2.1 HDFS简介及作用
- 2.2 HDFS架构
- 2.3HDFS服务角色
- 2.4 HDFS 如何读取文件
- 2.5 HDFS 如何写文件
- 2.6HDFS 副本存放策略
- 2.7HDFS基本命令
- 3.MapReduce专题
-
- 3.1.三个层面上的基本构思
- 3.2.一个MapReduce的完整过程
- 3.3.MR的shuffle环节
- 3.4.MR的编程
- 4.Yarn专题
-
- 4.1.yarn简介
- 4.2.yarn架构与服务角色
- 4.3.Scheduler调度器
- 4.4.YARN 作业执行流程
- 5.HIVE专题
-
- 5.1HIVE简介
- 5.2HIVE如何执行一条HQL语句
- 5.3HIVE数据存储
- 5.4HIVE常用语句
- 6.Zookeeper专题
-
- 6.1 Zookeeper概念
- 6.2 Zookeeper应用场景
- 6.3 Zookeeper原理
- 6.4 Zookeeper实现服务动态上下线通知原理
- 6.5 Zookeeper实现分布式锁原理
- 6.6 Zookeeper常用命令
- 7 Flume专题
-
- 7.1Flume简介
- 7.2 Sources,Channels,Sinks配置
- 7.3 可靠性
- 7.4 可恢复性
- 7.5 Flume配置文件与用法举例
Hadoop大数据技术课程总结
1.大数据概述
1.1大数据时代的4V
数据量大Volume
第一个特征是数据量大。大数据的起始计量单位可以达到P(1000个T)、E(100万个T)或Z(10亿个T)级别。
类型繁多(Variety)
第二个特征是数据类型繁多。包括网络日志、音频、视频、图片、地理位置信息等等,多类型的数据对数据的处理能力提出了更高的要求。
价值密度低(Value)
第三个特征是数据价值密度相对较低。如随着物联网的广泛应用,信息感知无处不在,信息海量,但价值密度较低,如何通过强大的机器算法更迅速地完成数据的价值"提纯",是大数据时代亟待解决的难题。
速度快、时效高(Velocity)
第四个特征是处理速度快,时效性要求高。这是大数据区分于传统数据挖掘最显著的特征。既有的技术架构和路线,已经无法高效处理如此海量的数据,而对于相关组织来说,如果投入巨大采集的信息无法通过及时处理反馈有效信息,那将是得不偿失的。可以说,大数据时代对人类的数据驾驭能力提出了新的挑战,也为人们获得更为深刻、全面的洞察能力提供了前所未有的空间与潜力。
1.2大数据时代的三次浪潮
第一波浪潮
第一波浪潮起源于90年代,当时从计算机到软件大多还是企业级的,而数据分析就已经开始,这个时代也还是集中式软件时代,存储数据的成本也非常昂贵,所以大部分企业以KPI角度,抽取少量结构化数据,采取特定数据。代表企业如MicroStrategy、Microsoft、Oracle,代表产品诸如Sybase、Congos。这个时代能产生的数据有限,能处理数据的能力有限。
第二波浪潮
发展到2000年左右,互联网的兴起,带动了计算机和软件从工具型走向消费级,由于互联网基础设施的发展,以下三点带来了数据的爆发式增长。1) 网络带宽的升级优化,从2g到4g,从拨号上网到光纤入户。2) 围绕互联网信息化带来大量的数据产生,如门户网站,社交平台,内容和视频平台等。3) 科技发展,从PC到移动设备到各种智能设备,都可以采集传输数据。数据的存储成本越来越低,数据的产生速度越来越快,数据量越来越大,第一波浪潮时的技术体系无法满足需求,并且由于摩尔定律基础硬件设备和条件也在优化,处理数据的能力越来越强,此时带来了大数据平台第二波浪潮的发展:
第三波浪潮
发展到2010左右,互联网发展从信息化走向了服务化,创业方向也从之前的“门户时代”、“社交时代”,“垂直化门户时代”,“内容视频时代”走向了电商、 出行、外卖、O2O等本地服务。如果说面向信息化的时代更多的是基于流量广告等商业模式,面向服务化时代更多的是直接面对客户价值的变现商业模式,或者说 消费者服务,所以从行业发展来看,服务类对分析的需求也要旺盛很多。我们可以用破木桶蓄水过程来类比,到处都是水源的时候,并且外部水源流入率大于自身流失率的时候,更多的思考的是抓紧圈水源而不是找短板。从2000年到2014年,流量势头猛进,到处都是用户,对于企业而言更多的思考是如何圈用户,而不是如何留住用户并去分析流失原因。当外部没有更多水源进入并且四处水源有限的时候,我们需要的是尽可能修复木桶,并且找到木桶的短板。在2014到2015年之间,互联网流量红利也初现消退 之势,国内的经济下行压力也逐渐增大,就好比水源有限一样,企业更多的需要分析自身原因了,去提高各种转化率,增加用户的忠诚度和黏性,减少用户的流失。 因此分析需求开始逐步提升,各个业务部门也都需要自我分析优化成本,提高产出和利润。过去企业更多面临的是由上而下的KPI中心化式分析,形成了分析中心化体系,基本上整个公司有统一关注的指标和数据看板,但是各业务部门的分析需要单独处理。数据分析从行业、角色、部门和场景而言,都是差异化的。比如行业上,电商关注的是购买相关指标,内容关注的是阅读相关指标,社交关注的是参与度相关指标,工 具关注的是功能使用情况。角色上,CEO关注的是整体、财务各部门的KPI;市场VP关注的是营销相关的子项目KPI;销售VP关注的是销售阶段状态和结果相关的指标;如部门上,市场关注的是投放转化率等指标;产品关注的是功能留存率等指标。如果要更充分的满足分析需求,需要从KPI中心化分析转向分析去 中心化,也就面临着又一次大数据平台的技术革新,也因此推动了大数据平台第三波浪潮的变革。
1.3大数据时代的技术支撑
虚拟化和云计算技术
美国国家标准技术研究所认为,云计算是通过网络使得一组可配置的计算资源(例如网 络、计算机、存储、应用程序、服务等)能够在任何地点进行访问的模型,资源的提供和 释放可以快速完成,管理开销低,与提供商的交互简便易行。
云计算的关键技术有三大点:⑴虚拟化技术:云计算的虚拟化技术不同于传统的单一虚拟化,它是涵盖整个IT架构的,包括资 源、网络、应用和桌面在内的全系统虚拟化。⑵分布式资源管理技术:信息系统仿真系统在大多数情况下会处在多节点并发执行环境中,要保证 系统状态的正确性,必须保证分布数据的一致性。⑶并行编程技术:云计算采用并行编程模式。在并行编程模式下,并发处理、容错、数据分布、负 载均衡等细节都被抽象到一个函数库中,通过统一接口,用户大尺度的计算任务被自动并发和分布 执行,即将一个任务自动分成多个子任务,并行地处理海量数据。
基于分布式的Hadoop生态系统
分布式计算的产生:单台计算机的能力是有限的,而需要处理的问题规模在不断地增长。为此,人们开始探索用多台计 算机组成一个系统进行协同处理。因此遇到很多新问题: 网络带宽有限 当部分机器出现故障时,我们希望多机系统作为一个整体还能正常工作用户编写的程序要同时在不同的机器上运行,还要确保能够容易使用分布式计算就是为了解决这些问题而出现的。Hadoop生态系统:主流的开源分布式大数据处理软件,主要用Java语言编写,具有较好的平台移植性。关于Hadoop有几个概念需要理解清楚: HDFS 是Hadoop的分布式文件系统 MapReduce是Hadoop的一代计算资源管理和调度系统。YARN是Hadoop的二代计算资源管理和调度系统,接受任务请求,并根据请求的需要来分配 资源,调度任务的执行。除了可以执行MapReduce外,还可以执行MPI等传统并行程序。HBase是一个开源的非关系型分布式数据库(NoSQL),它参考了谷歌的BigTable建模,实 现的编程语言为 Java。它是Hadoop项目的一部分,运行于HDFS文件系统之上。Hive和Pig能让用户用较为简便的方式来查询保存在HDFS或HBase中的数据。 Mahout是用Hadoop实现的机器学习算法库,包括聚类、分类、推荐,以及线性代数中的一 些常用算法。 Spark是比MapReduce更丰富灵活的计算框架,由Scala语言编写。设计核心是一种叫做可靠 分布式数据集。
NoSQL
NoSQL数据库比SQL更满足Web应用对数据规模和读写性能的要求。 常见的NoSQL数据库大致可分为以下几类:基于列的存储,例如HBase、Cassandra等等 基于文档的存储,例如MongoDB、CouchDB等 键值对存储,分三种类型:
1.4谷歌的3篇论文
GFS :分布式文件系统
MapReduce :分布式计算引擎
BigTable :分布式列族数据库
1.5Hadoop集群规模
注意:本部分数据来源于网络,数据时间较久,但也足以说明问题。
1.百度
百度在2006年就开始关注Hadoop并开始调研和使用,在2012年其总的集群规模达到近十个。单集群超过2800台机器节点,Hadoop机器总数有上万台机器,总的存储容量超过100PB,已经使用的超过74PB,每天提交的作业数目有数千个之多,每天的输入数据量已经超过7500TB,输出超过1700TB。
百度的Hadoop集群为整个公司的数据团队、大搜索团队、社区产品团队、广告团队,以及LBS团体提供统一的计算和存储服务,主要应用包括:
数据挖掘与分析
日志分析平台
数据仓库系统
推荐引擎系统
用户行为分析系统
同时百度在Hadoop的基础上还开发了自己的日志分析平台、数据仓库系统,以及统一的C++编程接口,并对Hadoop进行深度改造,开发了HadoopC++扩展HCE系统。
2.阿里巴巴(旧的数据,现在已转而使用阿里云了)
阿里巴巴的Hadoop集群截至2012年大约有3200台服务器,大约30?000物理CPU核心,总内存100TB,总的存储容量超过60PB,每天的作业数目超过150?000个,每天hivequery查询大于6000个,每天扫描数据量约为7.5PB,每天扫描文件数约为4亿,存储利用率大约为80%,CPU利用率平均为65%,峰值可以达到80%。阿里巴巴的Hadoop集群拥有150个用户组、4500个集群用户,为淘宝、天猫、一淘、聚划算、CBU、支付宝提供底层的基础计算和存储服务,主要应用包括:
数据平台系统
搜索支撑
广告系统
数据魔方
量子统计
淘数据
推荐引擎系统
搜索排行榜
为了便于开发,其还开发了WebIDE继承开发环境,使用的相关系统包括:Hive、Pig、Mahout、Hbase等。
3.腾讯
腾讯也是使用Hadoop最早的中国互联网公司之一,截至2012年年底,腾讯的Hadoop集群机器总量超过5000台,最大单集群约为2000个节点,并利用Hadoop-Hive构建了自己的数据仓库系统TDW,同时还开发了自己的TDW-IDE基础开发环境。腾讯的Hadoop为腾讯各个产品线提供基础云计算和云存储服务,其支持以下产品:
腾讯社交广告平台。
搜搜(SOSO)。
拍拍网。
腾讯微博。
腾讯罗盘。
QQ会员。
腾讯游戏支撑。
QQ空间。
朋友网。
腾讯开放平台。
财付通。
手机QQ。
QQ音乐。
4.奇虎360
奇虎360主要使用Hadoop-HBase作为其搜索引擎so.com的底层网页存储架构系统,360搜索的网页可到千亿记录,数据量在PB级别。截至2012年年底,其HBase集群规模超过300节点,region个数大于10万个,使用的平台版本如下。
HBase版本:facebook0.89-fb。
HDFS版本:facebookHadoop-20。
奇虎360在Hadoop-HBase方面的工作主要为了优化减少HBase集群的启停时间,并优化减少RS异常退出后的恢复时间。
5.华为
华为公司也是Hadoop主要做出贡献的公司之一,排在Google和Cisco的前面,华为对Hadoop的HA方案,以及HBase领域有深入研究,并已经向业界推出了自己的基于Hadoop的大数据解决方案。
6.中国移动
中国移动于2010年5月正式推出大云BigCloud1.0,集群节点达到了1024。中国移动的大云基于Hadoop的MapReduce实现了分布式计算,并利用了HDFS来实现分布式存储,并开发了基于Hadoop的数据仓库系统HugeTable,并行数据挖掘工具集BC-PDM,以及并行数据抽取转化BC-ETL,对象存储系统BC-ONestd等系统,并开源了自己的BC-Hadoop版本。
中国移动主要在电信领域应用Hadoop,其规划的应用领域包括:
经分KPI集中运算。
经分系统ETL/DM。
结算系统。
信令系统。
云计算资源池系统。
物联网应用系统。
E-mail。
IDC服务等。
7.Facebook
Facebook使用Hadoop存储内部日志与多维数据,并以此作为报告、分析和机器学习的数据源。目前Hadoop集群的机器节点超过1400台,共计11200个核心CPU,超过15PB原始存储容量,每个商用机器节点配置了8核CPU,12TB数据存储,主要使用StreamingAPI和JavaAPI编程接口。Facebook同时在Hadoop基础上建立了一个名为Hive的高级数据仓库框架,Hive已经正式成为基于Hadoop的Apache一级项目。此外,还开发了HDFS上的FUSE实现。
1.6Hadoop安装过程
1)安装centos7或ubuntu16.04系统
2)修改 IP
3)修改 host 主机名
4)配置 SSH 免密码登录
5)关闭防火墙
6)安装 JDK
7)解压 hadoop 安装包
8)配置 hadoop 的核心文件 hadoop-env.sh,core-site.xml,mapred-site.xml,hdfs-site.xml
9)配置 hadoop 环境变量
10)格式化 hadoop namenode-format
11)启动节点 start-all.sh
2.HDFS专题
参考:
https://blog.csdn.net/weixin_38750084/article/details/82963235
https://www.cnblogs.com/codeOfLife/p/5375120.html
2.1 HDFS简介及作用
HDFS(Hadoop Distributed File System,Hadoop分布式文件系统),它是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,适合那些有着超大数据集(large data set)的应用程序。
HDFS的设计特点是:
1、大数据文件,非常适合上T级别的大文件或者一堆大数据文件的存储,如果文件只有几个G甚至更小就没啥意思了。
2、文件分块存储,HDFS会将一个完整的大文件平均分块存储到不同计算器上,它的意义在于读取文件时可以同时从多个主机取不同区块的文件,多主机读取比单主机读取效率要高得多得多。
3、流式数据访问,一次写入多次读写,这种模式跟传统文件不同,它不支持动态改变文件内容,而是要求让文件一次写入就不做变化,要变化也只能在文件末添加内容。
4、廉价硬件,HDFS可以应用在普通PC机上,这种机制能够让给一些公司用几十台廉价的计算机就可以撑起一个大数据集群。
5、硬件故障,HDFS认为所有计算机都可能会出问题,为了防止某个主机失效读取不到该主机的块文件,它将同一个文件块副本分配到其它某几个主机上,如果其中一台主机失效,可以迅速找另一块副本取文件。
重要特性:
1.HDFS中的文件在物理上是分块存储(block),块的大小可以通过配置参数( dfs.blocksize)来规定,默认大小在hadoop2.x版本中是128M,老版本中是64M
2.HDFS文件系统会给客户端提供一个统一的抽象目录树,客户端通过路径来访问文件
3.目录结构及文件分块信息(元数据)的管理由namenode节点承担——namenode是HDFS集群主节点,负责维护整个hdfs文件系统的目录树,以及每一个路径(文件)所对应的block块信息(block的id,及所在的datanode服务器)
4.文件的各个block的存储管理由datanode节点承担----datanode是HDFS集群从节点,每一个block都可以在多个datanode上存储多个副本(副本数量也可以通过参数设置dfs.replication)
5.HDFS是设计成适应一次写入,多次读出的场景,且不支持文件的修改
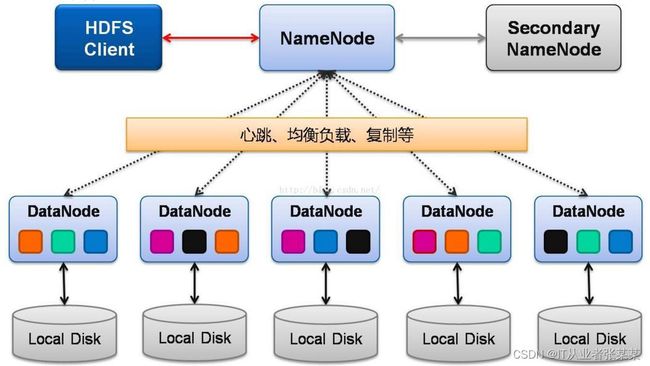
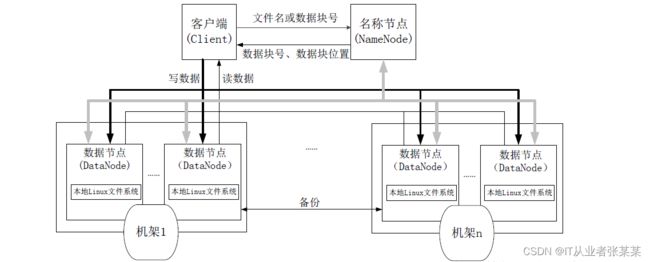
2.2 HDFS架构
先放上2张图:
2.3HDFS服务角色
Namenode
namenode又称为名称节点,是负责管理分布式文件系统的命名空间(Namespace),保存了两个核心的数据结构,即FsImage和EditLog。 你可以把它理解成大管家,它不负责存储具体的数据。
FsImage用于维护文件系统树以及文件树中所有的文件和文件夹的元数据
操作日志文件EditLog中记录了所有针对文件的创建、删除、重命名等操作
注意,这个两个都是文件,也会加载解析到内存中。
为啥会拆成两个呢? 主要是因为fsimage这个文件会很大的,多了之后就不好操作了,就拆分成两个。把后续增量的修改放到EditLog中, 一个FsImage和一个Editlog 进行合并会得到一个新的FsImage.FsImage就相当于你系统的引导区,如果FsImage坏了,那文件系统就崩溃了。 所以,这个重要的东西,需要备份。备份的功能就交给SecondaryNameNode实现
SecondaryNameNode
SecondaryNameNode工作过程
- SecondaryNameNode会定期和NameNode通信,请求其停止使用EditLog文件,暂时将新的写操作写到一个新的文件edit.new上来,这个操作是瞬间完成,上层写日志的函数完全感觉不到差别;
- SecondaryNameNode通过HTTP GET方式从NameNode上获取到FsImage和EditLog文件,并下载到本地的相应目录下;
- SecondaryNameNode将下载下来的FsImage载入到内存,然后一条一条地执行EditLog文件中的各项更新操作,使得内存中的FsImage保持最新;这个过程就是EditLog和FsImage文件合并;
- SecondaryNameNode执行完(3)操作之后,会通过post方式将新的FsImage文件发送到NameNode节点上
- NameNode将从SecondaryNameNode接收到的新的FsImage替换旧的FsImage文件,同时将edit.new替换EditLog文件,通过这个过程EditLog就变小了
 DataNode
DataNode
datanode数据节点,用来具体的存储文件,维护了blockId 与 datanode本地文件的映射。 需要不断的与namenode节点通信,来告知其自己的信息,方便nameode来管控整个系统。
这里还提到一个块的概念,就想linux本地文件系统中也有块的概念一样,这里也有块的概念。这里的块会默认是128m 每个块都会默认储存三份。
2.4 HDFS 如何读取文件
HDFS的文件读取原理,主要包括以下几个步骤:
- 首先调用FileSystem对象的open方法,其实获取的是一个DistributedFileSystem的实例。
- DistributedFileSystem通过RPC(远程过程调用)获得文件的第一批block的locations,同一block按照重复数会返回多个locations,这些locations按照hadoop拓扑结构排序,距离客户端近的排在前面。
- 前两步会返回一个FSDataInputStream对象,该对象会被封装成 DFSInputStream对象,DFSInputStream可以方便的管理datanode和namenode数据流。客户端调用read方法,DFSInputStream就会找出离客户端最近的datanode并连接datanode。
- 数据从datanode源源不断的流向客户端。
- 如果第一个block块的数据读完了,就会关闭指向第一个block块的datanode连接,接着读取下一个block块。这些操作对客户端来说是透明的,从客户端的角度来看只是读一个持续不断的流。
- 如果第一批block都读完了,DFSInputStream就会去namenode拿下一批blocks的location,然后继续读,如果所有的block块都读完,这时就会关闭掉所有的流。

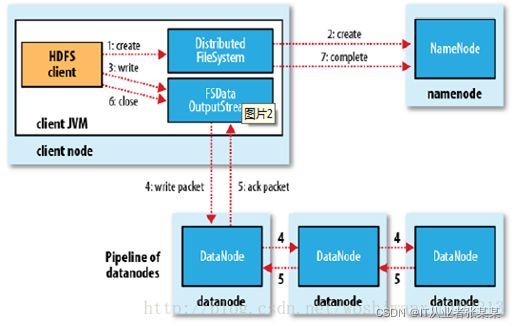
2.5 HDFS 如何写文件
HDFS的文件写入原理,主要包括以下几个步骤:
- 客户端通过调用 DistributedFileSystem 的create方法,创建一个新的文件。
- DistributedFileSystem 通过 RPC(远程过程调用)调用 NameNode,去创建一个没有blocks关联的新文件。创建前,NameNode 会做各种校验,比如文件是否存在,客户端有无权限去创建等。如果校验通过,NameNode 就会记录下新文件,否则就会抛出IO异常。
- 前两步结束后会返回 FSDataOutputStream 的对象,和读文件的时候相似,FSDataOutputStream 被封装成 DFSOutputStream,DFSOutputStream 可以协调 NameNode和 DataNode。客户端开始写数据到DFSOutputStream,DFSOutputStream会把数据切成一个个小packet,然后排成队列 data queue。
- DataStreamer 会去处理接受 data queue,它先问询 NameNode 这个新的 block 最适合存储的在哪几个DataNode里,比如重复数是3,那么就找到3个最适合的 DataNode,把它们排成一个 pipeline。DataStreamer 把 packet 按队列输出到管道的第一个 DataNode 中,第一个 DataNode又把 packet 输出到第二个 DataNode 中,以此类推。
- DFSOutputStream 还有一个队列叫 ack queue,也是由 packet 组成,等待DataNode的收到响应,当pipeline中的所有DataNode都表示已经收到的时候,这时akc queue才会把对应的packet包移除掉。
- 客户端完成写数据后,调用close方法关闭写入流。
- DataStreamer 把剩余的包都刷到 pipeline 里,然后等待 ack 信息,收到最后一个 ack 后,通知 DataNode 把文件标示为已完成。
2.6HDFS 副本存放策略
namenode如何选择在哪个datanode 存储副本(replication)?
这里需要对可靠性、写入带宽和读取带宽进行权衡。Hadoop对datanode存储副本有自己的副本策略,在其发展过程中一共有两个版本的副本策略,分别如下所示

2.7HDFS基本命令
查看文件常用命令
hdfs dfs -ls path #查看文件列表
hdfs dfs -ls -R path #递归查看文件列表
hdfs dfs -du path #查看path下的磁盘情况,单位字节
创建文件夹
hdfs dfs -mkdir path
创建文件
hdfs dfs -touchz path
hdfs dfs -touchz /user/iron/iron.txt #该命令不可递归创建文件,即当该文件的上级目录不存在时无法创建该文件,如果重复创建会覆盖原有的内容
复制文件和目录
hdfs dfs -cp 源目录 目标目录
hdfs dfs -cp /user/iron /user/iron01 #该命令会将源目录的整个目录结构都复制到目标目录中
hdfs dfs -cp /user/iron/* /user/iron01 #该命令只会将源目录中的文件及其文件夹都复制到目标目录中
移动文件和目录
hdfs dfs -mv 源目录 目标目录
hdfs dfs -mv /user/iron /user/iron01
hdfs dfs -mv /user/aa.txt /user/bb.txt #将/user/aa.txt文件重命名为/user/bb.txt
赋予权限
hdfs dfs -chmod [权限参数][拥有者][:[组]] path
hdfs dfs -chmod 777 /user/* #该命令是将user目录下的所用文件及其文件夹(不包含子文件夹中的文件)赋予最高权限:读,写,执行 777表示该用户,该用户的同组用户,其他用户都具有最高权限
上传文件
hdfs dfs -put 源文件夹 目标文件夹
hdfs dfs -put /home/hadoop01/iron /user/iron01 #该命令上传Linux文件系统中iron整个文件夹
hdfs dfs -put /home/hadoop01/iron/* /user/iron01 #该命令上传Linux文件系统中iron文件夹中的所有文件(不包括文件夹)
下载文件
hdfs dfs -get 源文件夹 目标文件夹
hdfs dfs -get /user/iron01 /home/hadoop01/iron #该命令下载hdfs文件系统中的iron01整个文件夹到Linux文件系统中
hdfs dfs -get /user/iron01/* /home/hadoop01/iron #该命令下载hdfs文件系统中的iron01整个文件夹到Linux文件系统中(不包含文件夹)
查看文件内容
hadoop fs -cat path #从头查看这个文件
hadoop fs -tail path #从尾部查看最后1K
hadoop fs -cat /userjzl/home/book/aa.txt #查看/userjzl/home/book目录下文件aa.txt的内容(将-cat 换成-text效果一样)
hadoop fs -tail /userjzl/home/book/aa.txt
删除文件
hdfs dfs -rm 目标文件 #rm不可以删除文件夹
hdfs dfs -rm -R 目标文件 #递归删除(慎用)
hdfs dfs -rm /user/test.txt #删除test.txt文件
hdfs dfs -rm -R /user/testdir #递归删除testdir文件夹
3.MapReduce专题
参考:
https://blog.csdn.net/fanxin_i/article/details/80388221
https://www.cnblogs.com/cjsblog/p/8168642.html
https://www.cnblogs.com/cheng5350/p/11872221.html
MapReduce的基本模型和处理思想:
3.1.三个层面上的基本构思
1.如果对付大数据处理:分而治之
对相互之间不具有计算依赖关系的大数据,实现并行最自然的办法就是采取分而治之的策略。
2.上升到抽象模型:Mapper与Reduce
MPI等并行计算方法缺少高层并行编程模型,程序员需要自行指定存储,计算,分发等任务,为了克服这一缺陷,MapReduce借鉴了Lisp函数式语言中的思想,用Map和Reduce两个函数提供了高层的并发编程模型抽象。
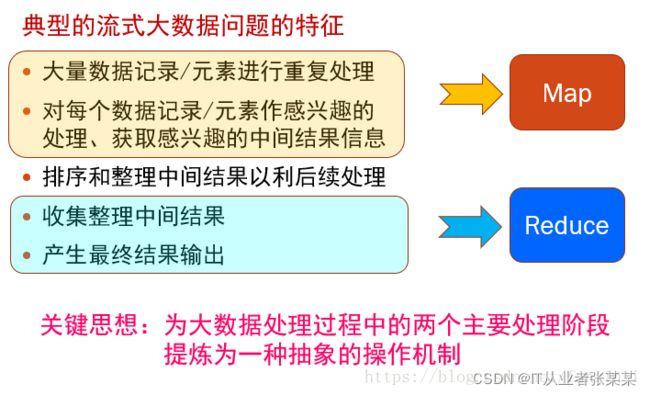
3.上升到架构:统一架构,为程序员隐藏系统层细节
MPI等并行计算方法缺少统一的计算框架支持,程序员需要考虑数据存储、划分、分发、结果收集、错误恢复等诸多细节;为此,MapReduce设计并提供了同意的计算框架,为程序员隐藏了绝大多数系统层面的处理系统。

3.2.一个MapReduce的完整过程
在MapReduce整个过程可以概括为以下过程:
输入 --> map --> shuffle --> reduce -->输出
输入文件会被切分成多个块,每一块都有一个map task
map阶段的输出结果会先写到内存缓冲区,然后由缓冲区写到磁盘上。默认的缓冲区大小是100M,溢出的百分比是0.8,也就是说当缓冲区中达到80M的时候就会往磁盘上写。如果map计算完成后的中间结果没有达到80M,最终也是要写到磁盘上的,因为它最终还是要形成文件。那么,在往磁盘上写的时候会进行分区和排序。一个map的输出可能有多个这个的文件,这些文件最终会合并成一个,这就是这个map的输出文件。
 流程说明如下:
流程说明如下:
1、输入文件分片,每一片都由一个MapTask来处理
2、Map输出的中间结果会先放在内存缓冲区中,这个缓冲区的大小默认是100M,当缓冲区中的内容达到80%时(80M)会将缓冲区的内容写到磁盘上。也就是说,一个map会输出一个或者多个这样的文件,如果一个map输出的全部内容没有超过限制,那么最终也会发生这个写磁盘的操作,只不过是写几次的问题。
3、从缓冲区写到磁盘的时候,会进行分区并排序,分区指的是某个key应该进入到哪个分区,同一分区中的key会进行排序,如果定义了Combiner的话,也会进行combine操作
4、如果一个map产生的中间结果存放到多个文件,那么这些文件最终会合并成一个文件,这个合并过程不会改变分区数量,只会减少文件数量。例如,假设分了3个区,4个文件,那么最终会合并成1个文件,3个区
5、以上只是一个map的输出,接下来进入reduce阶段
6、每个reducer对应一个ReduceTask,在真正开始reduce之前,先要从分区中抓取数据
7、相同的分区的数据会进入同一个reduce。这一步中会从所有map输出中抓取某一分区的数据,在抓取的过程中伴随着排序、合并。
8、reduce输出
3.3.MR的shuffle环节
在Map端的shuffle过程是对Map的结果进行分区、排序、分割,然后将属于同一划分(分区)的输出合并在一起并写在磁盘上,最终得到一个分区有序的文件,分区有序的含义是map输出的键值对按分区进行排列,具有相同partition值的键值对存储在一起,每个分区里面的键值对又按key值进行升序排列(默认),其流程大致如下:
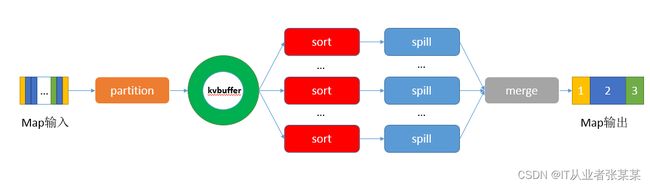
Map的输出给进入Shuffle环节:Shuffle环节如下:

3.4.MR的编程
编程分析:
map任务处理:
读取输入文件内容,解析成key、value对。对输入文件的每一行,解析成key、value对。每一个键值对调用一次map函数。
写自己的逻辑,对输入的key、value处理,转换成新的key、value输出。
对输出的key、value进行分区。
对不同分区的数据,按照key进行排序、分组。相同key的value放到一个集合中。
(可选)分组后的数据进行归约。
reduce任务处理:
对多个map任务的输出,按照不同的分区,通过网络copy到不同的reduce节点。
对多个map任务的输出进行合并、排序。写reduce函数自己的逻辑,对输入的key、value处理,转换成新的key、value输出。
把reduce的输出保存到文件中。
编程代码:
public class WordCount {
//继承mapper接口,设置map的输入类型为计算value的和
for(IntWritable val:values){
sum += val.get();
}
//将频数设置到result
result.set(sum);
//收集结果
context.write(key, result);
}
}
/**
* @param args
*/
public static void main(String[] args) throws Exception{
// TODO Auto-generated method stub
Configuration conf = new Configuration();
conf.set("mapred.job.tracker", "localhost:9001");
args = new String[]{"hdfs://localhost:9000/user/hadoop/input/count_in","hdfs://localhost:9000/user/hadoop/output/count_out"};
//检查运行命令
String[] otherArgs = new GenericOptionsParser(conf,args).getRemainingArgs();
if(otherArgs.length != 2){
System.err.println("Usage WordCount " );
System.exit(2);
}
//配置作业名
Job job = new Job(conf,"word count");
//配置作业各个类
job.setJarByClass(WordCount.class);
job.setMapperClass(Map.class);
job.setCombinerClass(Reduce.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
4.Yarn专题
参考:
https://blog.csdn.net/weixin_43930865/article/details/115708202
4.1.yarn简介
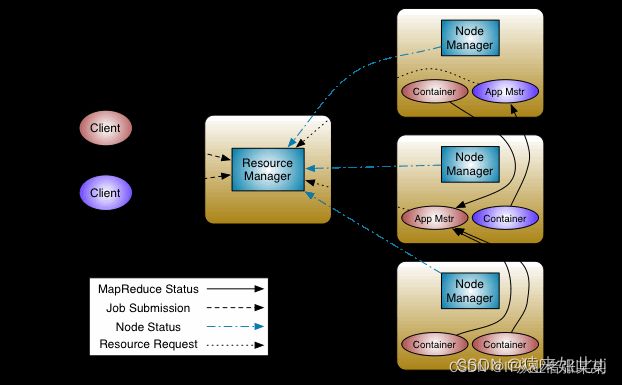
YARN 是一个资源调度平台,负责为运算程序提供服务器运算资源,相当于一个分布式的操作系统平台。Spark、Storm 等运算框架都可以整合在 YARN 上运行,只要他们各自的框架中有符合 YARN 规范的资源请求机制即可
设计思想
YARN 的基本思想是将资源管理和作业调度/监控的功能拆分为单独的守护进程。这个想法是有一个全局 ResourceManager ( RM ) 和每个应用程序 ApplicationMaster ( AM )。应用程序是单个作业或作业的 DAG。
ResourceManager 和 NodeManager 构成了数据计算框架。ResourceManager 是在系统中的所有应用程序之间仲裁资源的最终权威。NodeManager 是每台机器的框架代理,负责容器、监控它们的资源使用情况(cpu、内存、磁盘、网络)并将其报告给 ResourceManager/Scheduler。
每个应用程序的 ApplicationMaster 实际上是一个特定于框架的库,其任务是协商来自 ResourceManager 的资源并与 NodeManager 一起执行和监视任务。
4.2.yarn架构与服务角色
架构图如下:
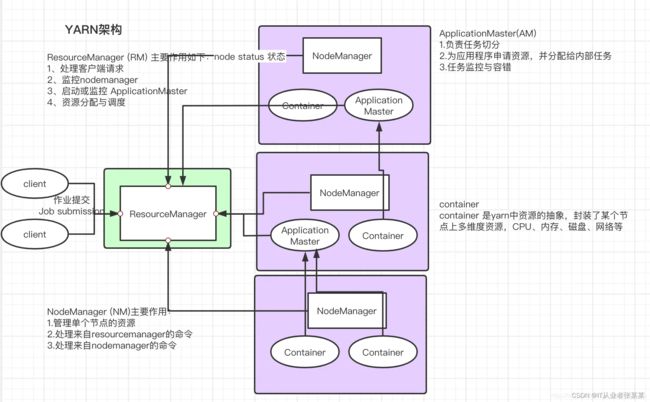
2.1ResourceManager
RM(ResourceManager)是 YARN 集群主控节点,负责协调和管理整个集群(所有 NodeManager)的资源。ResourceManager 会为每一个 Application 启动一个 AppMaster,并且 AppMaster 分散在各个 NodeManager 节点。
ResourceManager 的职责:
1、处理客户端请求,比如程序提交
2、启动或监控 MRAppMaster
3、监控 NodeManager健康状态
4、资源的分配与调度
ResourceManager 有两个主要组件:Scheduler 和 ApplicationsManager。
Scheduler 调度器负责根据熟悉的容量、队列等约束将资源分配给各种正在运行的应用程序。调度器是纯粹的调度器,因为它不执行应用程序的状态监控或跟踪。此外,它不保证由于应用程序故障或硬件故障而重新启动失败的任务。调度器根据应用程序的资源需求执行其调度功能;它是基于资源容器的抽象概念来实现的,该容器包含内存、CPU、磁盘、网络等元素。
2.2NodeManager
NodeManager 是 YARN 集群当中真正资源的提供者,是真正执行应用程序的容器的提供者,监控应用程序的资源使用情况(CPU,内存,硬盘,网络),并通过心跳向集群资源调度器ResourceManager 进行汇报以更新自己的健康状态。同时其也会监督 Container 的生命周期管理,监控每个 Container 的资源使用(内存、CPU 等)情况,追踪节点健康状况,管理日志和不同应用程序用到的附属服务(auxiliary service)。
2.3AppMaster
AppMaster对应一个应用程序,职责是:向YARN资源调度器申请执行任务的资源容器,运行任务,监控整个任务的执行,跟踪整个任务的状态,处理任务失败以异常情况
2.4Container容器
Container 容器是一个抽象出来的逻辑资源单位。容器是由 ResourceManager Scheduler 服务动态分配的资源构成,它包括了一个节点上的一定量 CPU,内存,磁盘,网络等信息,容器的大小是可以动态调整的,其最大大小就是一个nodemanger的资源,一个container只能在一个容器上。
4.3.Scheduler调度器
调度器根据应用程序的资源需求进行资源分配,不参与应用程序具体的执行和监控等工作,调度器会将总资源分为不同的队列供共享资源进行分配。资源分配的单位就是 Container,YARN 本身为我们提供了多种直接可用的调度器,比如 FIFO队列调度器,Fair 公平调度器和 Capacity 容量调度器等,可以在conf/yarn-site.xml 中配置调度器。
1.CapacityScheduler容量调度器
其中心思想是 Hadoop 集群中的可用资源在多个组织之间共享,这些组织根据其计算需求共同资助集群,为了保证集群总资源的安全和稳定性,CapacityScheduler提供了一组严格的限制,以确保单个应用程序或用户或队列不能在集群中消耗的资源的量不成比例。此外,CapacityScheduler对来自单个用户和队列的初始化和挂起的应用程序提供限制,以确保集群的公平性和稳定性。简单说就是当目前使用队列资源不够时,动态分配其他队列资源进行使用。参数配置指定调度器:yarn.resourcemanager.scheduler.class=指定挂起和运行最大程序个数:默认是10000:maximum-applications集群中程序最大可占用的运行资源:maximum-am-resource-percent默认是1-10%=90%的最大资源使用率,留10%给系统指定某用户的最大运行程序数:yarn.scheduler.capacity.user..max-parallel-apps 可以设置单个队列的资源占比,运行app任务数等。
2.Fair 公平调度器公平调度
是一种将资源分配给应用程序的方法,以便所有应用程序在一段时间内平均获得相等的资源份额。默认情况下,Fair Scheduler 仅基于内存进行调度公平性决策。简单来说就是对于两个程序抢夺同一资源时进行均分资源,保证都能得到一半。
3.FIFO Scheduler(先进先出调度器)
FIFO Scheduler把应用按提交的顺序排成一个队列,这是一个先进先出队列,在进行资源分配的时候,先给队列中最头上的应用进行分配资源,待最头上的应用需求满足后再给下一个分配,以此类推。FIFO Scheduler是最简单也是最容易理解的调度器,也不需要任何配置,但它并不适用于共享集群。大的应用可能会占用所有集群资源,这就导致其它应用被阻塞。在共享集群中,更适合采用Capacity Scheduler或Fair Scheduler,这两个调度器都允许大任务和小任务在提交的同时获得一定的系统资源。
4.4.YARN 作业执行流程
利用yarn进行资源调度的程序,基本流程都和下面一致,包括spark,MR等数据处理组件

1.client向yarn提交job,首先找ResourceManager分配资源,
2.ResourceManager开启一个Container,在Container中运行一个Application manager
3.Application manager找一台nodemanager启动Application master,计算任务所需的计算
4.Application master向Application manager(Yarn)申请运行任务所需的资源
5.Resource scheduler将资源封装发给Application master
6.Application master将获取到的资源分配给各个nodemanager
7.各个nodemanager得到任务和资源开始执行map task
8.map task执行结束后,开始执行reduce task
9.map task和 reduce task将执行结果反馈给Application master
10.Application master将任务执行的结果反馈pplication manager
5.HIVE专题
参考:
https://blog.csdn.net/qq_32727095/article/details/120512994
5.1HIVE简介
Hive是一个数据仓库基础工具在Hadoop中用来处理结构化数据。它架构在Hadoop之上,总归为大数据,并使得查询和分析方便。并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。
最初,Hive是由Facebook开发,后来由Apache软件基金会开发,并作为进一步将它作为名义下Apache Hive为一个开源项目。Hive 没有专门的数据格式。 Hive 可以很好的工作在 Thrift 之上,控制分隔符,也允许用户指定数据格式。Hive不适用于在线事务处理。 它最适用于传统的数据仓库任务。
Hive 构建在基于静态批处理的Hadoop 之上,Hadoop 通常都有较高的延迟并且在作业提交和调度的时候需要大量的开销。因此,Hive 并不能够在大规模数据集上实现低延迟快速的查询,例如,Hive 在几百MB 的数据集上执行查询一般有分钟级的时间延迟。因此,
Hive 并不适合那些需要低延迟的应用,例如,联机事务处理(OLTP)。Hive 查询操作过程严格遵守Hadoop MapReduce 的作业执行模型,Hive 将用户的HiveQL 语句通过解释器转换为MapReduce 作业提交到Hadoop 集群上,Hadoop 监控作业执行过程,然后返回作业执行结果给用户。Hive 并非为联机事务处理而设计,Hive 并不提供实时的查询和基于行级的数据更新操作。Hive 的最佳使用场合是大数据集的批处理作业,例如,网络日志分析。
直接使用hadoop所面临的问题:
人员学习成本太高
项目周期要求太短
MapReduce实现复杂查询逻辑开发难度太大
使用HIVE可解决的问题:
操作接口采用类SQL语法,提供快速开发的能力。
避免了去写MapReduce,减少开发人员的学习成本。
扩展功能很方便。
HIVE架构
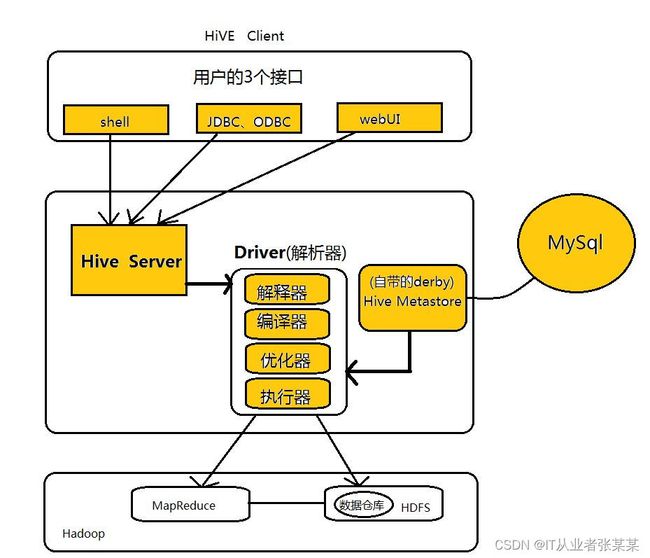
5.2HIVE如何执行一条HQL语句
概述:
第一步:输入一条HQL查询语句(select * from tab)
第二步:解析器对这条Hql语句进行语法分析。
第三步:编译器对这条Hql语句生成HQL的执行计划。
第四步:优化器生成最佳的Hql的执行计划。
第五步:执行这条最佳Hql语句。
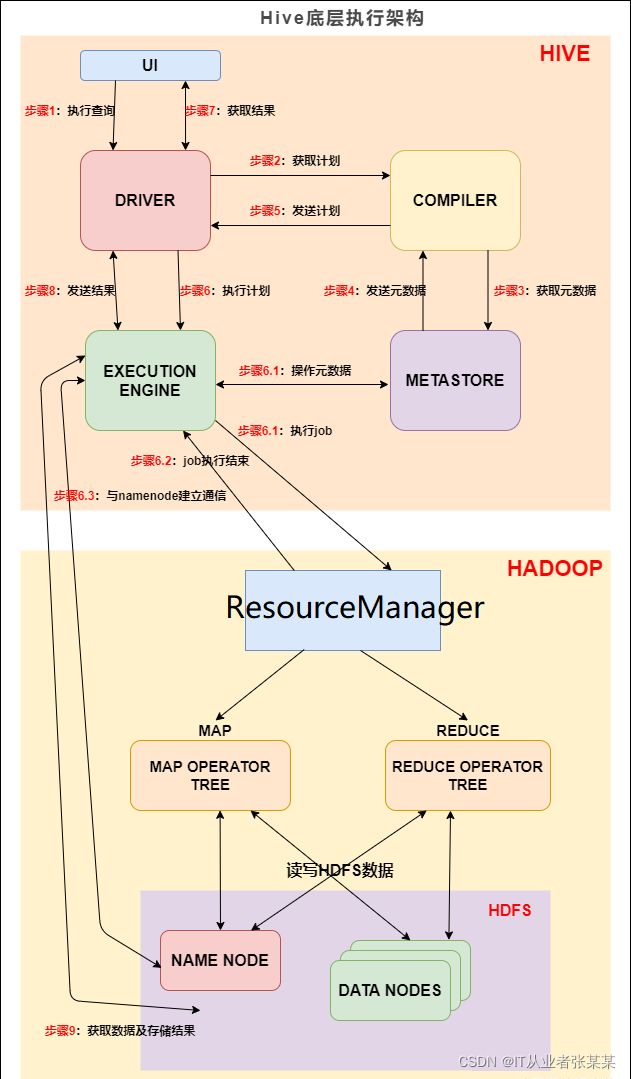
比如如下HQL语句:
select dept, sum(salary) from emp group by dept;
考虑下这个东西你自己写会怎么计算:你有一张表在hdfs上,这个表是一张员工表,有几个字段:
id:integer,name:varchar,dept:varchar,memo: string,salary:Integer
1,张三,总裁办,暂缺,1000
2,李四,总裁办,暂缺,1000
3,王五,外联部,无,2000
上面数据采样的第一列是ID,后面是名字,接着是DEPT(部门),最后是备注和工资。然后SQL是用来统计每个部门工资支出的。GROUP BY DEPT就是按照DEPT分组,把相同的放在一起,然后各自算出工资总额。单机做的话就是先按照部门排个序,然后一个大循环单独统计每个部门的总额。最后一个部门输出一条结果。
如果是Hive呢,大致上也类似,只是搬到分布式环境下了。
Hive基本上会遵循AST->逻辑执行计划->优化的逻辑执行计划->物理执行计划->打包提交->分布式执行,这样的顺序来开展计算。
现在详细的说明开始,从SQL字符串输入开始。
SQL输入是个字符串,Hive需要先把字符串分解成自己能明白的结构。Hive的解析不是徒手撸的,用的是ANTLR,一个解析器生成器,可以用类似BNF的范式定义语法然后产生对应的解析代码。BNF是大学编译原理必学的东西,另外Hive的语法定义是一种后缀是.g的特殊文件,可以自己去Hive的代码里搜一下。
ANTLR生成的代码会返回给你ASTNode。AST是抽象语法树的简写。比如上面的SELECT,会转化为一个以TOK_SELECT标记为根节点的树,树的叶子节点需要包含Projection List子树(dept,count(*)),FROM子树,Filter子树(上面的例子空缺了)等等。也就是说,AST会把一个长字符串转化成树结构,树本身的结构设计取决于你的语法定义,ANTLR会按照你的定义把树排列好,Hive自身的代码而言,也要根据树结构定义去遍历整个树,把需要的信息抽取出来。AST的好处是,你不再纠结于Token的解析和排列问题,你只需要在一个固定结构的树上抽取信息,比如SELECT根节点以下你必然能找到SELECT_EXPR子节点(就是Projection部分的信息),很适合做这件事情。
遍历完整个AST,Hive把它关心的信息分类组织排列到一个结构中,但是还没有进行元信息绑定和检查整理,而这个绑定整理的过程叫Semantics Analyze(语义分析)。对应上面的例子,Hive会分别抽取:
Projection列表,上述例子就是DEPT,sum(salary)。这里拿到的信息表示,用户希望结果是什么表达式;
FROM列表,表示数据源;
GROUP BY,表示如何分组。
然后要做的是元数据绑定。这里首先需要从Hive元数据库中查询到相关的元信息。对上面的查询,Hive知道了用户希望从emp表中查询数据,那么Hive调用MetastoreClient接口,从Metadata Service中抽取了emp表的元信息,所谓元信息最基本地包含了表的schema,比如id是Integer类型,dept是string类型,这些信息都会注入本次之行Hive的符号解析空间,同时被注入的符号还有内建函数(比如我们用的sum)和UDF等等。然后Hive对Projection列表中的表达式进行解析,首先是dept,Hive会去搜索刚才提到的符号解析空间,找到了DEPT代表源表中的一个字段,类型是String。因为这里就是一个简单的字段引用,因此不涉及类型检查之类的;但是如果你写DEPT+1,这里就会有类型检查和隐式转换等,比如是强类型的设计,看到string+integer的组合就会抛出异常结束执行,而弱类型的系统会偷偷插入一个CAST,把1转换成字符串“1”。第二列是sum(salary),这里Hive看到一个函数调用,于是它搜索了函数表,找到了sum函数,并看到它是一个聚合函数(sum不是简单的一行数据能独立计算的函数,需要整个组一起算),这里就先标记起来,后面还有相关的语义检查。而继续遍历sum的子树又发现了一个salary列引用表达式,一样做一次解析找到salary列定义是Integer。
最后是Group By检查,根据SQL语义,出现在聚合函数外的字段引用必须出现在Group By中,于是Hive开始检查sum(SALARY)之外的列引用,发现了DEPT,然后遍历Group By的列表进行匹配,发现所有非聚合列都已经在GROUP BY中定义了,于是Hive很满意,继续执行下去了。
到这里为止Hive得到了一个语义正确的SQL查询信息结构。接下去需要的是,产生逻辑执行计划。
逻辑执行计划可以简单地认为就是,按照顺序在单机上跑是能跑出结果的一个计算计划。
按照最初我们分析的算法,首先你需要扫描整个表,因此Hive先产生一个TableScanOperator;接下去,需要做的是抽取DEPT字段和SALARY(sum的输入参数需要比sum先计算完),因此这两个操作在一起生成一个ProjectionOperator;然后是AggregationOperator,就是sum本身的计算,当然这个计算还需要携带DEPT的部分;最后是输出,就是SinkOperator,需要把结果写到HDFS上。
接下去Hive会对执行计划进行优化,最常见的优化可能是PartitionPrune,比如你在Hive中定义了分区表,那么如果有Where条件中出现了分区字段,比如WHERE date = ‘2016-08-25’,而且分区就是date,那么我需要在TableScanOperator中加入分区信息,指定Scan的时候只扫描2016-8-25的信息;或者如果你有子查询,Hive会将内层的查询条件推送到外层,这样需要计算的数据就会减少;再或者如果底层存储支持列裁剪,那么刚才那张表其实我只用到了DEPT和SALARY两个字段,ID和名字以及备注我都不关心,那么Scan的时候可以少读一些信息。更复杂的还有比如CBO相关优化,可以交换Join顺序,让多次Join产生的中间数据尽可能小,或者选择不同的JOIN策略等等。
优化完毕之后,Hive接着生成物理执行计划。所谓物理执行计划才是真正映射底层计算引擎的计算策略。根据底层引擎不同(现在Hive支持Spark,Tez和MapReduce),Hive会生成不同的物理对应。拿MapReduce来说,刚才的SQL到这个阶段,需要拆解成Mapper和Reducer不同的步骤。TableScan,Projection计算以及Sum的前半段都是需要塞到Mapper做的。比较特殊的是Sum,因为Sum在MapReduce环境下需要在Mapper中计算Sum括号内的表达式(这里就是简单的提取SALARY),并且在每个Mapper中进行本地累加(Combiner中根据分组进行本地加和),然后分发到Reducer进行最终累加。因此AggregationOperator在物理执行计划产生的时候会拆解成两部分,一部分是PartialAggregation对应Mapper端的Sum,一部分是FinalAggregation对应Reducer端的最终Sum。这样我们的执行计划就变成:
Stage1:
Mapper -
Reducer -
写到这里发现选取的例子并没有复杂表达式,比如我其实要计算大家统一加薪10%之后的成本,那我其实会写Salary * 1.1。如果是这样的话,Salary * 1.1这样的表达式会被封装成一个可以求值的求值器。很多类似Hive的SQL On Hadoop系统选择进行代码生成,比如Spark,Impala或者Presto(其实基本Hive之后的都进行了代码生成,而Hive应该还没有进行代码生成,这个我并不确定)。
不管Hive现在有没有代码生成,就算有,也和很多人想象中的代码生成并不同。Hive并不会直接产生一个MapReduce作业的全部代码。Hive会将刚才说的Operator信息进行封装,产生一个可以序列化传输的包,这个包里包涵了各个Operator求值所需的信息,然后提交作业分发给Mapper和Reducer。Hive使用的Mapper和Reducer是两个特定的Hive类,它们的一部分初始化信息来自于Job阶段根据Operator的信息进行设定(比如TableScan相关的信息一部分在Job生成的时候就已经设置好),另一部分会在每个Task启动的时候装载刚才序列化的Operator信息并产生一个可以求值的求值器,当map和reduce函数被调用的时候,求值器也被调用,每个输入数据都被求值一遍。
这样一次Mapper和Reducer走完,SQL就计算完毕了。
具体Hive使用的MapReduce类是
org.apache.hadoop.hive.ql.exec.mr.ExecMapper,ExecReducer
好奇的同学可以去翻翻看,到底逻辑是如何的。
实际上上面的SQL基本上可以说是最最简单的场景了,如果有诸如Join,窗口函数,子查询等,整个执行计划会一下子变的复杂。另外元数据管理,权限,HiveServer2和JDBC等等,就没有那么令人感兴趣了,在此略过不提,用过Hive的人多少可以自己想得出这几个部分如何工作。
5.3HIVE数据存储
Hive的数据存储
1、Hive中所有的数据都存储在 HDFS 中,没有专门的数据存储格式(可支持Text,SequenceFile,ParquetFile,RCFILE等)
2、只需要在创建表的时候告诉 Hive 数据中的列分隔符和行分隔符,Hive 就可以解析数据。
3、Hive 中包含以下数据模型:DB、Table,External Table,Partition,Bucket。
db:在hdfs中表现为${hive.metastore.warehouse.dir}目录下一个文件夹
table:在hdfs中表现所属db目录下一个文件夹
external table:外部表, 与table类似,不过其数据存放位置可以在任意指定路径
普通表: 删除表后, hdfs上的文件都删了
External外部表删除后, hdfs上的文件没有删除, 只是把文件删除了
partition:在hdfs中表现为table目录下的子目录
bucket:桶, 在hdfs中表现为同一个表目录下根据hash散列之后的多个文件, 会根据不同的文件把数据放到不同的文件中
5.4HIVE常用语句
常用语句
创建数据库
>create database db_name;
>create database if not exists db_name;//创建一个不存在的数据库final
查看数据库
>show databases;
选择性查看数据库
>show databases like 'f.*';
查看某一个数据库的详细信息
>describe database db_name;
删除非空数据库
>drop database db_name CASCADE;
创建数据库时,指定数据库位置
>create database db_name location '/home/database/'
创建数据库的时候希望能够给数据库增加一些描述性东西
>create database db_name comment 'helloworld';
创建数据库的时候,需要为数据库增加属性信息,可以使用with dbproperties信息
>create database db_name with dbproperties<'createor'='hello','date'='2018-3-3');
如果要使用自己已经存在的数据库
>use db_name;
修改数据库的属性信息
>alter database db_name set dbproperties('edited-by'='hello');
创建表
>create table tab_name(id int,name string) row format delimited fields terminated by '\t';
创建一个表,该表和已有的某一个表的结构一样(复制表结构)
>create table if not exists emp like employeel;
查看当前数据库下的所有表
>show tables;
删除一个已经存在的表
>drop table employee;
修改一个表明,重命名
>alter table old_name rename to new_name;
将hdfs上面的文件信息导入到hive表中(/home/bigdata代表文件在在HDFS上位置)使用改命令时一定要注意数据与数据之间在txt文件编辑的时候一定要Tab间隔
>load data local inpath '/home/bigdata' into table hive.dep;
修改某一个表的某一列的信息
>alter table tab_name change column key key_1 int comment 'h' after value;
给某一个表增加某一列的信息
>alter table tab_name add columns(value1 string,value2 string);
如果想替换表中的某一个列
>alter table tab_name replace columns(values string,value11 string);
修改表中某一列的属性
>alter table tab_name set tblproperties('value'='hello');
hive成批向某一表插入数据
>insert overwrite table tab_name select * from tab_name2;
将 查询结果保留到一个新表中去
>create table tab_name as select * from t_name2;
将查询结果保存到指定的文件目录(可以是本地,也可以HDFS)
>insert overwrite local directory '/home/hadoop/test' select *from t_name;
>insert overwrite directory '/aaa/bbb/' select *from t_p;
两表内连
>select *from dual a join dual b on a.key=b.key;
将hive查询结果输出到本地特定目录
insert overwrite local directory '/home/bigdata1/mydir' select *from test;
将hive查询结果输出到HDFS特定目录
insert overwrite directory '/home/mydir' select *from test;
案例:EMP DEPT表
(1)命令行窗口通过输入hive,连接到hive,查看数据库
hive
show databases;
通过location指定数据库路径,本例中数据库路径为当前用户桌面上目录
create database hadoop_hive location '/home/ubuntu/Desktop/hadoop_hive';
使用创建好的数据库
use hadoop_hive;
(2)创建员工表(emp+学号,如:emp001)
create table emp001(empno int,ename string,job string,mgr int,hiredate string,sal int,comm int,deptno int) row format delimited fields terminated by ',';
(3)创建部门表(dept+学号,如:dept001)
create table dept001(deptno int,dname string,loc string) row format delimited fields terminated by ',';
(4)导入数据
load data inpath '/001/hive/emp.csv' into table emp001;
load data inpath '/001/hive/dept.csv' into table dept001;
(5)根据员工的部门号创建分区,表名emp_part+学号,如:emp_part001
create table emp_part001(empno int,ename string,job string,mgr int,hiredate string,sal int,comm int)partitioned by (deptno int)row format delimited fields terminated by ',';
往分区表中插入数据:指明导入的数据的分区(通过子查询导入数据)
insert into table emp_part001 partition(deptno=10) select empno,ename,job,mgr,hiredate,sal,comm from emp001 where deptno=10;
insert into table emp_part001 partition(deptno=20) select empno,ename,job,mgr,hiredate,sal,comm from emp001 where deptno=20;
insert into table emp_part001 partition(deptno=30) select empno,ename,job,mgr,hiredate,sal,comm from emp001 where deptno=30;
select * from emp_part001;
(6)创建一个桶表,表名emp_bucket+学号,如:emp_bucket001,根据员工的职位(job)进行分桶:
create table emp_bucket001(empno int,ename string,job string,mgr int,hiredate string,sal int,comm int,deptno int)clustered by (job) into 4 buckets row format delimited fields terminated by ',';
(7)通过子查询插入数据:
insert into emp_bucket001 select * from emp001;
(8)查询员工信息:员工号 姓名 薪水
select empno,ename,sal from emp001;
(9)多表查询
select dept001.dname,emp001.ename from emp001,dept001 where emp001.deptno=dept001.deptno;
(10)做报表,根据职位给员工涨工资,把涨前、涨后的薪水显示出来
select empno,ename,job,sal,case job when 'PRESIDENT' then sal+1000 when 'MANAGER' then sal+800 else sal+400 end from emp001;
6.Zookeeper专题
6.1 Zookeeper概念
1.Zookeeper作用:
Zookeeper是针对大型分布式系统的高可靠的协调系统。
由这个定义我们知道 zookeeper是个协调系统,作用的对象是分布式系统。
zookeeper主要是文件系统和通知机制
文件系统主要是用来存储数据
通知机制主要是服务器或者客户端进行通知,并且监督
2.Zookeeper文件系统节点类型
有4种类型的znode
1、PERSISTENT--持久化目录节点
客户端与zookeeper断开连接后,该节点依旧存在
2、PERSISTENT_SEQUENTIAL-持久化顺序编号目录节点
客户端与zookeeper断开连接后,该节点依旧存在,只是Zookeeper给该节点名称进行顺序编号
3、EPHEMERAL-临时目录节点
客户端与zookeeper断开连接后,该节点被删除
4、EPHEMERAL_SEQUENTIAL-临时顺序编号目录节点
客户端与zookeeper断开连接后,该节点被删除,只是Zookeeper给该节点名称进行顺序编号
3.Zookeeper特点
一个leader,多个follower的集群
集群只要有半数以上包括半数就可正常服务,一般安装奇数台服务器
全局数据一致,每个服务器都保存同样的数据,实时更新
更新的请求顺序保持顺序(来自同一个服务器)
数据更新的原子性,数据要么成功要么失败
数据实时更新性很快
6.2 Zookeeper应用场景
1.服务动态上下线通知
2.分布式锁
3.数据配置
4.集群管理
6.3 Zookeeper原理
PAXOS算法:
参考:https://www.cnblogs.com/linbingdong/p/6253479.html
ZAB算法:
参考:https://blog.csdn.net/liuchang19950703/article/details/111406622
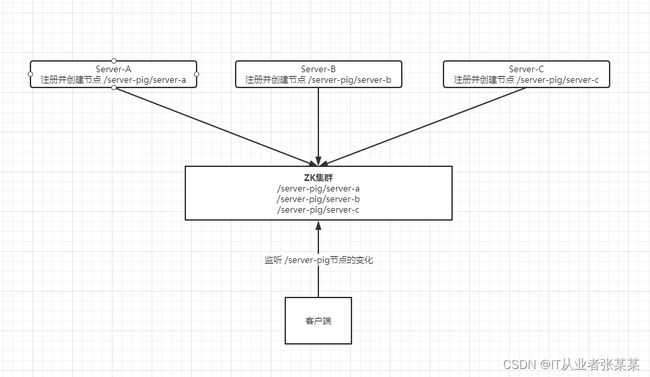
6.4 Zookeeper实现服务动态上下线通知原理
如图:
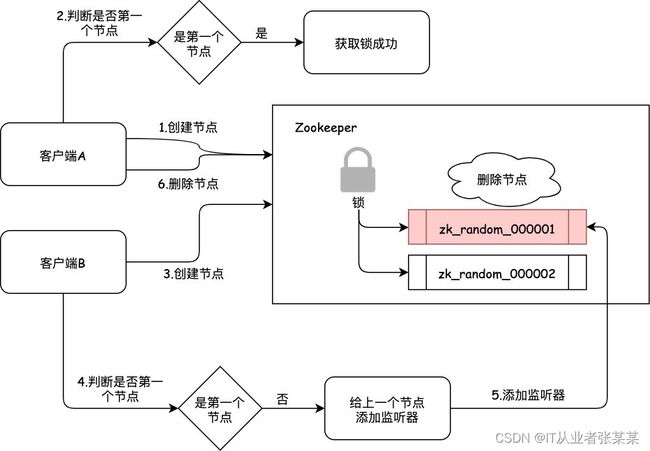
6.5 Zookeeper实现分布式锁原理
如图:
6.6 Zookeeper常用命令
1、zk服务命令
- 启动ZK服务: bin/zkServer.sh start
- 查看ZK服务状态: bin/zkServer.sh status
- 停止ZK服务: bin/zkServer.sh stop
- 重启ZK服务: bin/zkServer.sh restart
- 连接服务器: zkCli.sh -server 127.0.0.1:2181
2、连接zk
启动ZooKeeper服务之后,我们可以使用如下命令连接到 ZooKeeper 服务:
eg、zookeeper-3.4.8\bin>zkCli.cmd -server 127.0.0.1:2181
Linux环境下:
eg、zkCli.sh -server 127.0.0.1:2181
连接成功后,系统会输出 ZooKeeper 的相关环境以及配置信息,如下:
3、zk客户端命令
我们可以使用 help命令来查看帮助:
命令行工具的一些常用操作命令如下:
1.ls – 查看某个目录包含的所有文件,例如:
[zk: 127.0.0.1:2181(CONNECTED) 1] ls /
2.ls2 – 查看某个目录包含的所有文件,与ls不同的是它查看到time、version等信息,例如:
[zk: 127.0.0.1:2181(CONNECTED) 1] ls2 /
3.create – 创建znode,并设置初始内容,例如:
[zk: 127.0.0.1:2181(CONNECTED) 1] create /test “test”
Created /test
创建一个新的 znode节点“ test ”以及与它关联的字符串
4.get – 获取znode的数据,如下:
[zk: 127.0.0.1:2181(CONNECTED) 1] get /test
5.set – 修改znode内容,例如:
[zk: 127.0.0.1:2181(CONNECTED) 1] set /test “ricky”
6.delete – 删除znode,例如:
[zk: 127.0.0.1:2181(CONNECTED) 1] delete /test
7.quit – 退出客户端
8.help – 帮助命令
7 Flume专题
7.1Flume简介
Flume是一种分布式的、可靠的、可用的服务,用于高效地收集、聚合和移动大量的日志数据。它具有基于流数据流的简单而灵活的架构。它具有可调的可靠性机制和许多故障转移和恢复机制,具有健壮性和容错能力。它使用一个简单的可扩展数据模型,允许在线分析应用程序。
Flume中的数据传递被称为event事件,event就是数据流单元。Flume中的agent被称为代理,agent的本质是一个(JVM)进程,每个agent中包含了source,channel,sink这几个组件,这些组件会把数据从一个地方(source)采集到目的地(sink)中(被称为一个hop,跳)。
7.2 Sources,Channels,Sinks配置
Flume的source配置,见
http://flume.apache.org/releases/content/1.9.0/FlumeUserGuide.html#flume-sources
Flume的channel配置,见
http://flume.apache.org/releases/content/1.9.0/FlumeUserGuide.html#flume-channels
Flume的sink配置,见
http://flume.apache.org/releases/content/1.9.0/FlumeUserGuide.html#flume-sinks
7.3 可靠性
在每个agent中,event都会暂存在channel中。然后将event传递给下一个agent或是终端存储库中(如sink的类型为HDFS时)。这些event在存储到下一个agent的channel中或是存储到终端存储中(如HDFS)中后,才会在当前agent的channel中将event删除。这样只有在将事件存储到下一个代理的通道或终端存储库中之后,它们才会从通道中删除。这种方式提供了Flume在消息传递时的端到端可靠性。
7.4 可恢复性
当消息传递失败时,event由于已经暂存在channel中,可以从channel中恢复。Flume支持持久化channel(比如采用本地文件系统作为channel),如果追求性能,也可采用memory作为channel,但这样有可能存在数据丢失无法恢复的情况。
7.5 Flume配置文件与用法举例
# example.conf: A single-node Flume configuration
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 6666
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
上面的配置文件定义了一个agent的name为a1,a1的source监听6666端口,并且读取6666端口传过来的数据, a1的channel 采用内存作为缓存,a1的sink 类型为logs,具体含义可以参考官网,或是留言。
在flume的安装目录下执行如下命令,即可使用flume采集数据:
$ bin/flume-ng agent -n a1 -c conf -f conf/netcat2logger.conf -Dflume.root.logger=INFO,console
flume-ng agent :表示flume的启动一个agent,ng是表示这是new的版本命令
-n a1:-n 表示name ,a1表示agent的名字为a1 对应配置文件中的a1
-c conf :表示flume的配置文件目录所在位置
-f conf/netcat2logger.conf: 表示自定义的数据采集配置文件位置。
-Dflume.root.logger=INFO,console:表示我们制定flume的日志格式,并且输出到控制台。