Pytorch Dataloader 模块源码分析(一):整体框架与 Dataset 组件
Dataloader 源码分析(一)
- Dataloader 整体架构
-
- Dataloader 使用方法
- Dataloader 架构设计
- Dataloader 常用组件
-
- Dataset 类
Dataloader 整体架构
Dataloader 使用方法
Dataloader 是 Pytorch 中加载数据的主要方式,以图像分类训练为例,一般训练时的脚本如下:
# 定义 dataset
dataset = torchvision.ImageFolder("path/to/imagenet_root")
# 定义 dataloader 及其参数
train_loader = torch.utils.data.Dataloader(dataset, ...)
for input, target in train_loader:
# 前向计算
output = model(input)
# 计算损失
loss = loss_fn(output, target)
# 反向传播
optimizer.zero_grad()
loss.backward()
# 梯度更新
optimizer.step()
这里我们可以看出 Dataloader 对象实际上是一个可迭代对象,因此 Dataloader 需要定义一个 __iter__和 __next__函数(python 中的魔法函数)来实现迭代器的功能。Dataloader 的完整参数如下:
DataLoader(dataset, batch_size=1, shuffle=False, sampler=None,
batch_sampler=None, num_workers=0, collate_fn=None,
pin_memory=False, drop_last=False, timeout=0,
worker_init_fn=None, *, prefetch_factor=2,
persistent_workers=False)
这里面的参数是可以指定:
- 批处理大小
- 数据集是 map 风格还是 iterable 风格
- 自定义数据加载顺序、是否打乱
- 是否启用多进程进行数据加载工作
- 是否开启自动锁页内存
这里简单介绍一下 map 风格和 iterable 风格是什么意思:map 风格指的是该 Dataset 对象可以通过传入一个下标(键)来访问具体的值,也就是内部实现是一个哈希表(python 中就是字典),而 Iterable 数据集则是前文提到的可迭代对象,可以通过 for 循环遍历内部的数据。
接下来我会从源码角度分析 Dataloader 工作原理和其使用到的一些关键组件/类。
Dataloader 架构设计
正如前文所述,Dataloader 对象内部定义为可迭代对象,可迭代对象在被 for 循环遍历时,会走一下流程:
- 调用__iter__方法获得一个迭代器对象
- 调用__next__方法遍历对象中定义的数据
- 循环步骤 2,直到抛出 StopIteration 异常,循环结束
为了更好得从全局角度理解 Dataloader,我们还需要先认识一下 Dataloader 中使用到得组件,具体是:
- Dataset 类
- Sampler 类
- Fetcher 类
下图所示是 Dataloader 的工作流程,这里以使用 map 风格的 Dataset 对象为例:
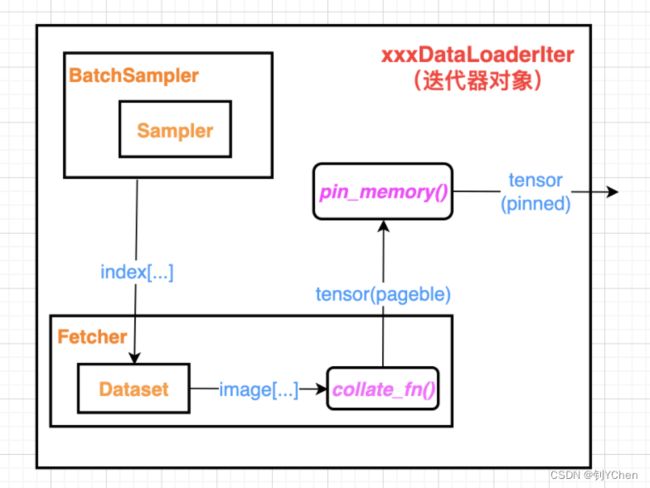
具体来说,在 Dataloader 的一次迭代过程中,BatchSampler 生成一堆 index 下标(或者 Sampler 生成一个下标),Fetcher 根据下标将数据从 Dataset 中取出来,然后通过 collate_fn 转换为 Pytorch 中的标准数据结构 Tensor,之后如果 Dataloader 处的 pin_memory 为 True,还会将 Tensor 从 pageable_memory 转换为 pinned_memory。
同时,在这个过程中如果 Dataloader 设置了多线程,会在 Fetcher 取数据处设置多个子线程并发地从磁盘加载数据,以减少 I/O 时间。
接下来具体讲解各个组件的源码。
Dataloader 常用组件
Dataset 类
前文提到 Dataset 类支持两种风格,map 和 iterable,map 风格指的是该 Dataset 对象可以通过传入一个下标(键)来访问具体的值,也就是内部实现是一个哈希表(python 中就是字典),而 Iterable 数据集则是前文提到的可迭代对象,可以通过 for 循环遍历内部的数据。
因此,map 风格的 Dataset 需要实现__getitem__方法而 iterable 风格的 Dataset 需要实现__iter__和__next__方法。
本章节分析 map 风格的 Dataset,因为这是实际场景中最常使用到的类型。当我们需要做训练时,数据需要有对应的 label,那么 Dataset 就应该建立数据到 label 的映射,也就是哈希表,这正是 map 风格数据集。以上文提到的 ImageFolder 为例,ImageFolder 是torchvision 内置的 Dataset,它继承了 Pytorch 中原生的 Dataset 并定义了__getitem__方法。这是 Dataset 中最核心的一个函数,因为这个函数提供的索引访问功能可以为 Dataloader 取数据发挥作用:Dataloader 在调用__iter__时就会使用到 Dataset 的索引接口。自定义的 Dataset 通常继承自 torch.utils.data.Dataset 类,并且需要重写其中的__getitem__方法和__len__方法因为在基类中他们是会 raise NotImplemtedError。
首先我们看 ImageFolder 中函数的定义:
class ImageFolder(DatasetFolder):
def __init__(
self,
root: str,
transform: Optional[Callable] = None,
target_transform: Optional[Callable] = None,
loader: Callable[[str], Any] = default_loader,
is_valid_file: Optional[Callable[[str], bool]] = None,
):
super().__init__(
root,
loader,
IMG_EXTENSIONS if is_valid_file is None else None,
transform=transform,
target_transform=target_transform,
is_valid_file=is_valid_file,
)
self.imgs = self.samples
注意到 ImageFolder 继承自 DatasetFolder,其中的一些其他参数会在后续介绍。所以 __getitem__方法得去 DatasetFolder 中找,我们再找到 DatasetFolder 类定义,这里为了简洁起见,省去了其他的函数,主要关注__getitem__函数:
class DatasetFolder(VisionDataset):
def __init__(
self,
root: str,
...
transform: Optional[Callable] = None,
...
) -> None:
super().__init__(root, transform=transform, target_transform=target_transform)
...
# 调用 make_dataset 生成 samples
samples = self.make_dataset(self.root, class_to_idx, extensions, is_valid_file)
...
def make_dataset(
directory: str,
class_to_idx: Dict[str, int],
extensions: Optional[Tuple[str, ...]] = None,
is_valid_file: Optional[Callable[[str], bool]] = None,
) -> List[Tuple[str, int]]:
...
# 调用全局中定义的 make_dataset 生成 samples
return make_dataset(directory, class_to_idx, extensions=extensions, is_valid_file=is_valid_file)
def __getitem__(self, index: int) -> Tuple[Any, Any]:
# 传入一个 index,用这个 index 访问定义在 init 中的 samples
path, target = self.samples[index]
# loader 做解码工作,loader 定义在 ImageFolder 中
sample = self.loader(path)
...
return sample, target
def __len__(self) -> int:
return len(self.samples)
其中,make_dataset 和 find_classes 定义在同文件下的全局空间,定义如下:
def make_dataset(
directory: str,
class_to_idx: Optional[Dict[str, int]] = None,
extensions: Optional[Union[str, Tuple[str, ...]]] = None,
is_valid_file: Optional[Callable[[str], bool]] = None,
) -> List[Tuple[str, int]]:
# 生成一个 list 的 samples,其中的元素形式是:Tuple (路径,label)
directory = os.path.expanduser(directory)
# 通常 class_to_idx 是 None,所以会调用 find_classes,定义在该函数后
if class_to_idx is None:
_, class_to_idx = find_classes(directory)
elif not class_to_idx:
raise ValueError("'class_to_index' must have at least one entry to collect any samples.")
...
instances = []
available_classes = set()
for target_class in sorted(class_to_idx.keys()):
# 从 class_to_idx 中读出类型和其对应的 index
class_index = class_to_idx[target_class]
target_dir = os.path.join(directory, target_class)
...
# walk(dir) 返回这个 dir 路径下的所有文件,也就是一个 class 下的所有 png 文件
for root, _, fnames in sorted(os.walk(target_dir, followlinks=True)):
for fname in sorted(fnames):
# 生成路径
path = os.path.join(root, fname)
# is_valid 会检查文件后缀是否合法,常见的由 jpg 和 png
if is_valid_file(path):
# 生成一张图的路径以及它对应的 class index 并添加到 instances
item = path, class_index
instances.append(item)
...
...
return instances
def find_classes(directory: str) -> Tuple[List[str], Dict[str, int]]:
# 将类别文件的路径存在 classes 数组中并排序
classes = sorted(entry.name for entry in os.scandir(directory) if entry.is_dir())
...
# 定义一个字典,key 是类型名称,value 是 index
class_to_idx = {cls_name: i for i, cls_name in enumerate(classes)}
return classes, class_to_idx
假设我的数据集格式是:
- bird (dir)
- - bird1.png
- - bird2.png
- - littlebird (dir)
- - - littlebird1.png
- - - littlebird2.png
- dog
- - dog1.png
- - dog2.png
- turtle
- - turtle1.png
那么 find_classes 返回值为
['bird', 'dog', 'turtle'], {'bird': 0, 'dog': 1, 'turtle': 2}
于是 make_dataset 中的 _, class_to_idx 就接收了这两个返回值,并且做处理,最后 make_dataset 返回的 instances 是:
[('path/to/imagenet_root/bird/bird1.png', 0), ('path/to/imagenet_root/bird/bird2.png', 0), ('path/to/imagenet_root/bird/littlebird/littlebird1.png', 0), ...]
具体实现请参考我在源码中的注释。于是该 instances 也就是 DatasetFolder 中的 samples,于是 ImageFolder 中的__getitem__方法可以根据传入的 index 去获取 samples 中的键值对(path: class index),获得了路径之后,会调用 self.loader 进行解码,将 jpg 文件或 png 文件解码为 RGB 格式,如果我们在调用 ImageFolder 时没有传入 loader,ImageFolder 会调用 default_loader,default_loader 源码如下:
def default_loader(path: str) -> Any:
from torchvision import get_image_backend
if get_image_backend() == "accimage":
return accimage_loader(path)
else:
return pil_loader(path)
其中,我们常用的 pil_loader,pil_loader :
def pil_loader(path: str) -> Image.Image:
with open(path, "rb") as f:
img = Image.open(f)
return img.convert("RGB")
也就是将该路径下的图片转换为了 RGB 格式用于后续的处理。
因此,Dataset 的__getitem__方法最终返回的是一个 RGB 格式的图像和这个图像对应的 class index。至此,Dataset 组件已经全部讲解完毕。
由于篇幅较长,后面的部分将放在后半篇。之后将接着分析 Dataloader 中的 Sampler 组件和 Fetcher 组件,以及 Dataloader 中的__iter__和__next__方法。