Pytorch框架学习个人笔记3---梯度下降
提示:本博客是依托B站【刘二大人】的讲解视频并结合个人实践学习总结而成,仅用作记录本人学习巩固,请勿做商用。
文章目录
- 前言
- 一、算法原理回顾
- 二、代码实现
-
- 2.1代码示例
- 2.2 结果展示
- 三、算法改进(SGD)
-
- 3.1 改进原因
- 3.2 SGD
- 3.3 改进后的代码实现
- 总结
前言
这一讲是关于梯度下降算法及其改进的讲解,在NLP课程的往期博客中,我们已经提到过这个算法的原理,现在进行具体代码实现。
一、算法原理回顾
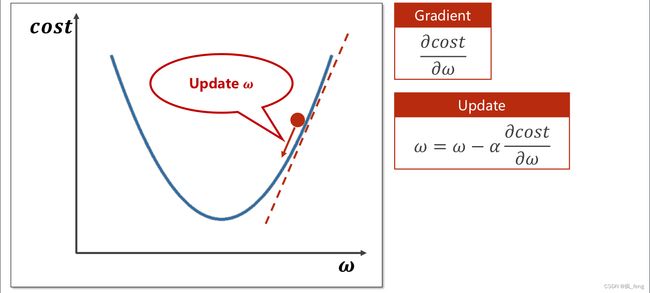
- 计算损失函数,求其梯度。
- 设置学习率,更新w。
- 根据设定的轮数重复上述过程。
二、代码实现
2.1代码示例
import matplotlib.pyplot as plt
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]#随便举个没有噪声的栗子
w = 1.0 #初始权重设置
def forward(x):#预期函数求解
return x * w
def cost(xs, ys):#MSE计算
cost = 0
for x, y in zip(xs, ys):
y_pred = forward(x)
cost += (y_pred - y) ** 2
return cost / len(xs)
def gradient(xs, ys):#求算损失函数的梯度
grad = 0
for x, y in zip(xs, ys):
grad += 2 * x * (x * w - y)
return grad / len(xs)
epoch_list = []
cost_list = []
print('predict (before training)', 4, forward(4))
for epoch in range(100):#轮数设置
cost_val = cost(x_data, y_data)
grad_val = gradient(x_data, y_data)
w -= 0.01 * grad_val # 0.01 学习率
print('epoch:', epoch, 'w=', w, 'loss=', cost_val)
epoch_list.append(epoch)
cost_list.append(cost_val)
print('predict (after training)', 4, forward(4))
plt.plot(epoch_list, cost_list)
plt.ylabel('cost')
plt.xlabel('epoch')
plt.show()
2.2 结果展示
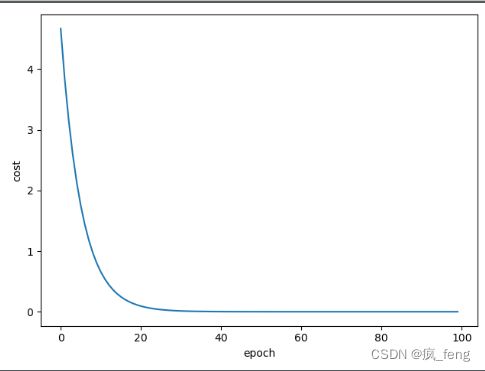
可以直观的看出来随着轮数的增加,损失函数值逐渐趋于0,权重趋于2。
但在实际的训练中,由于所给数据是有噪声的,曲线并非如此平滑。我们可以利用求指数加权平均的方法去量化收敛程度的界定。
三、算法改进(SGD)
3.1 改进原因
-
非凸函数导致的错把局部最优当成全局最优。
-
鞍点(G=0)导致的无法更新推进。
3.2 SGD
- 损失函数由cost( )更改为loss( )。
- 梯度函数gradient( )由计算所有训练数据的梯度更改为计算一个训练数据的梯度。
- 不能并行计算。

在实际的训练应用中,随机梯度下降算法不需要历遍所有数据集,但也并非只选择一个数据,而是选取批量数据(Mini-Batch)进行运算,有助于跨越鞍点,但不能像GD一样并行进行。我们要学会择取平衡点,又想马儿跑又想马儿不吃草是痴人说梦,算法之中也蕴含哲理哈。
3.3 改进后的代码实现
import matplotlib.pyplot as plt
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
w = 1.0
def forward(x):
return x*w
def loss(x, y):
y_pred = forward(x)
return (y_pred - y)**2
def gradient(x, y):
return 2*x*(x*w - y)
epoch_list = []
loss_list = []
print('predict (before training)', 4, forward(4))
for epoch in range(100):
for x,y in zip(x_data, y_data):
grad = gradient(x,y)
w = w - 0.01*grad
print("\tgrad:", x, y,grad)
l = loss(x,y)
print("progress:",epoch,"w=",w,"loss=",l)
epoch_list.append(epoch)
loss_list.append(l)
print('predict (after training)', 4, forward(4))
plt.plot(epoch_list,loss_list)
plt.ylabel('loss')
plt.xlabel('epoch')
plt.show()
总结
在训练轮数相同的条件下,SGD所得的结果收敛性更好。