TensorRT ubuntu18.04 安装过程记录
需要先安装CUDA和对应的cudnn,如果没有安装可以参考以下文章:
CUDA安装:https://blog.csdn.net/HaoZiHuang/article/details/109308882
CUDNN安装:https://blog.csdn.net/HaoZiHuang/article/details/109310082
当然如果已经安装了cudnn,但是版本与TensorRT不匹配,可以参考这篇,用环境变量添加新的cudnn:
https://blog.csdn.net/HaoZiHuang/article/details/126051132
本文这里不按照官方文档往下走,而是直接下载预编译包,这是官方文档的安装步骤:
https://docs.nvidia.com/deeplearning/tensorrt/install-guide/index.html#installing-debian
1. 下载预编译包
下载链接走起:
https://developer.nvidia.com/nvidia-tensorrt-8x-download
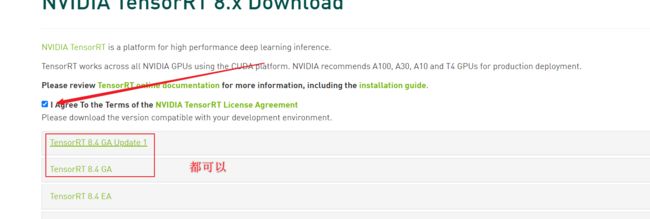
我的CUDA是10.1
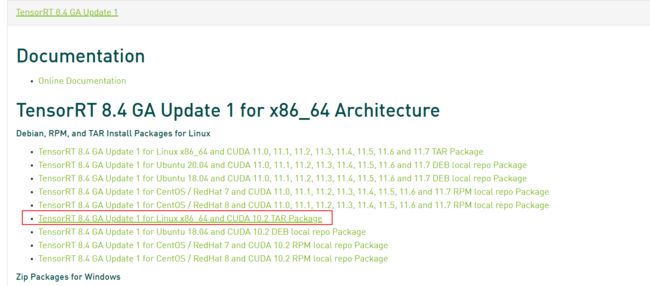
所以选择了这个
TensorRT-8.4.2.4.Linux.x86_64-gnu.cuda-10.2.cudnn8.4.tar.gz
2. 安装pycuda
下载过程中,别闲着,把pycuda安装一下,目前是直接pip安装就行,如果出问题建议编译安装:
pip install pycuda
然后按照这篇文章的步骤,验证一下pycuda是否安装成功:
https://blog.csdn.net/HaoZiHuang/article/details/125797987
3. 解压与安装trt python包
接着解压:
tar -zxvf TensorRT-8.4.2.4.Linux.x86_64-gnu.cuda-10.2.cudnn8.4.tar.gz
直接进入python目录
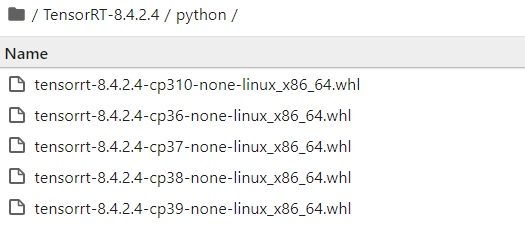
按照Python版本直接pip安装:
pip install tensorrt-8.4.2.4-cp3xx-none-linux_x86_64.whl
安装之后,如果运行:
>>> import tensorrt as trt
会报错:
ImportError: libnvinfer.so.8: cannot open shared object file: No such file or directory
这是因为TensorRT还并未添加到 LD_LIBRARY_PATH 中
4. 将 trt 添加到环境变量中
接下来进入刚才的trt路径:
cd TensorRT-8.4.2.4
export TENSORRT_DIR=$(pwd) # 给这个路径起个名字
echo $TENSORRT_DIR # 验证一下是否正确
echo "export TENSORRT_DIR=$(pwd)" >> /etc/profile # 添加到配置文件中
echo "export LD_LIBRARY_PATH=$TENSORRT_DIR/lib:$LD_LIBRARY_PATH" >> /etc/profile
source /etc/profile # 刷新环境变量
然后再验证一下:
echo $LD_LIBRARY_PATH

有第一个就OK
5. 关于 trtexec
顺便把TensorRT-8.4.2.4/bin添加到 PATH 中,这样就可以任意使用工具 trtexec 了
cd TensorRT-8.4.2.4/bin
echo "export PATH=$(pwd):$PATH" >> /etc/profile
source /etc/profile
接下来在命令行输入 trtexec,如果命令行运行 trtexec 报这个错:
trtexec: error while loading shared libraries: libcudart.so.10.2:
cannot open shared object file: No such file or directory
那就是 CUDA 版本问题,我现在的工作环境是 CUDA10.1 都2202年了,还tm CUDA10.1…
那么需要安装CUDA10.2,安装完毕后,需要将 /usr/local/cuda/lib64 添加到 LD_LIBRARY_PATH
如果出现这个结果,那就是 trtexec 可以用了,而且环境十有八九也配置好了:
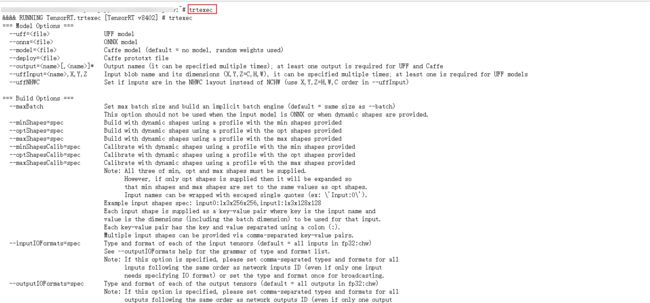
6. trtexec 转换 onnx 模型到 trt 模型
这里给一个onnx模型demo, 我用来做分割的,放心不需要CSDN积分和C币,供诸位用来验证环境是否正确
https://download.csdn.net/download/HaoZiHuang/86265944
然后执行:
trtexec --onnx=output.onnx --saveEngine=outfpbest.engine --workspace=2048 --minShapes=x:1x3x224x224 --optShapes=x:1x3x224x224 --maxShapes=x:1x3x224x224 --best
如果报错Error Code 2: Internal Error (Assertion cublasStatus == CUBLAS_STATUS_SUCCESS failed. ):
......
[07/29/2022-16:05:48] [W] [TRT] - Subnormal FP16 values detected.
[07/29/2022-16:05:48] [W] [TRT] - Values less than smallest positive FP16 Subnormal value detected. Converting to FP16 minimum subnormalized value.
[07/29/2022-16:05:48] [W] [TRT] If this is not the desired behavior, please modify the weights or retrain with regularization to reduce the magnitude of the weights.
[07/29/2022-16:05:48] [W] [TRT] Weights [name=Conv_44 + BatchNormalization_44 + Relu_42.weight] had the following issues when converted to FP16:
[07/29/2022-16:05:48] [W] [TRT] - Subnormal FP16 values detected.
[07/29/2022-16:05:48] [W] [TRT] - Values less than smallest positive FP16 Subnormal value detected. Converting to FP16 minimum subnormalized value.
[07/29/2022-16:05:48] [W] [TRT] If this is not the desired behavior, please modify the weights or retrain with regularization to reduce the magnitude of the weights.
[07/29/2022-16:05:55] [E] Error[2]: [ltWrapper.cpp::setupHeuristic::349] Error Code 2: Internal Error (Assertion cublasStatus == CUBLAS_STATUS_SUCCESS failed. )
[07/29/2022-16:05:55] [E] Error[2]: [builder.cpp::buildSerializedNetwork::636] Error Code 2: Internal Error (Assertion engine != nullptr failed. )
[07/29/2022-16:05:55] [E] Engine could not be created from network
[07/29/2022-16:05:55] [E] Building engine failed
[07/29/2022-16:05:55] [E] Failed to create engine from model or file.
[07/29/2022-16:05:55] [E] Engine set up failed
&&&& FAILED TensorRT.trtexec [TensorRT v8402] # trtexec --onnx=output.onnx --saveEngine=outfpbest.engine --workspace=2048 --minShapes=x:1x3x224x224 --optShapes=x:1x3x224x224 --maxShapes=x:1x3x224x224 --best
参考github Issue:
https://github.com/NVIDIA/TensorRT/issues/866
就加上--tacticSources=-cublasLt,+cublas
trtexec --onnx=output.onnx --saveEngine=outfpbest.engine --workspace=2048 --minShapes=x:1x3x224x224 --optShapes=x:1x3x224x224 --maxShapes=x:1x3x224x224 --best --tacticSources=-cublasLt,+cublas
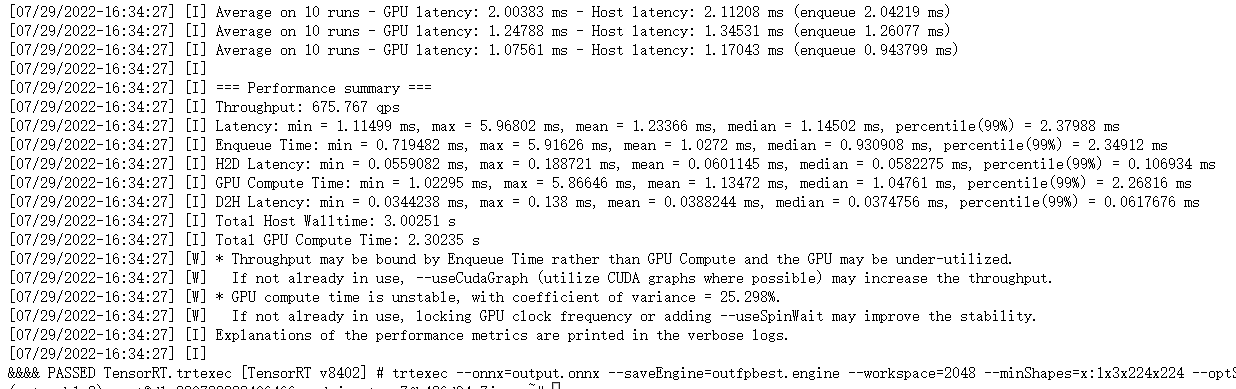
这是最终的输出,没有[E]应该就是OK的
.......
[07/29/2022-15:09:25] [I] === Performance summary ===
[07/29/2022-15:09:25] [I] Throughput: 621.747 qps
[07/29/2022-15:09:25] [I] Latency: min = 1.15918 ms, max = 4.95288 ms, mean = 1.31576 ms, median = 1.19141 ms, percentile(99%) = 2.75317 ms
[07/29/2022-15:09:25] [I] Enqueue Time: min = 0.774078 ms, max = 5.40161 ms, mean = 1.08616 ms, median = 0.94162 ms, percentile(99%) = 2.66064 ms
[07/29/2022-15:09:25] [I] H2D Latency: min = 0.0557861 ms, max = 0.116455 ms, mean = 0.0599288 ms, median = 0.0583496 ms, percentile(99%) = 0.0915527 ms
[07/29/2022-15:09:25] [I] GPU Compute Time: min = 1.06787 ms, max = 4.85571 ms, mean = 1.21764 ms, median = 1.09375 ms, percentile(99%) = 2.63379 ms
[07/29/2022-15:09:25] [I] D2H Latency: min = 0.0344238 ms, max = 0.067627 ms, mean = 0.0381936 ms, median = 0.0374756 ms, percentile(99%) = 0.0523682 ms
[07/29/2022-15:09:25] [I] Total Host Walltime: 2.99961 s
[07/29/2022-15:09:25] [I] Total GPU Compute Time: 2.27089 s
[07/29/2022-15:09:25] [W] * Throughput may be bound by Enqueue Time rather than GPU Compute and the GPU may be under-utilized.
[07/29/2022-15:09:25] [W] If not already in use, --useCudaGraph (utilize CUDA graphs where possible) may increase the throughput.
[07/29/2022-15:09:25] [W] * GPU compute time is unstable, with coefficient of variance = 27.4128%.
[07/29/2022-15:09:25] [W] If not already in use, locking GPU clock frequency or adding --useSpinWait may improve the stability.
[07/29/2022-15:09:25] [I] Explanations of the performance metrics are printed in the verbose logs.
[07/29/2022-15:09:25] [I]
&&&& PASSED TensorRT.trtexec [TensorRT v8402] # trtexec --onnx=output.onnx --saveEngine=outfpbest.engine --workspace=2048 --minShapes=x:1x3x224x224 --optShapes=x:1x3x224x224 --maxShapes=x:1x3x224x224 --best --tacticSources=-cublasLt,+cublas
可以看出在工作目录生成文件 outfpbest.engine
上边儿那个Error的原因可能是:
https://github.com/NVIDIA/TensorRT/issues/1865
6.1 关于上边的Error
有老铁说CUDA10.2需要打两个补丁就OK了,参考自:
https://blog.csdn.net/loovelj/article/details/117162523
但是也有老铁说,没啥用:

CUDA10.2 的补丁从这里下载:
https://developer.nvidia.com/cuda-10.2-download-archive?target_os=Linux&target_arch=x86_64&target_distro=Ubuntu&target_version=1804&target_type=runfilelocal
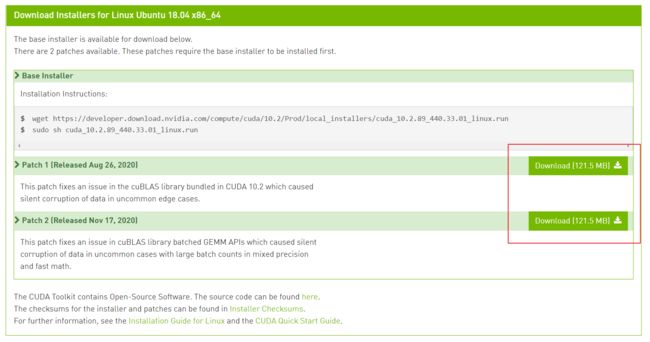
下载完毕,依次执行就OK了
sh cuda_10.2.1_linux.run
sh cuda_10.2.2_linux.run
在我这个环境安装那俩个补丁确实解决了问题
注意:
据说CUDA11+没有这个问题,或者说CUDA10.2的用户重装为CUDA11问题就可解决
注意:
如果已经安装的cudnn,与TensorRT版本和CUDA版本不匹配,则需要下载新的CUDNN,可以参考这篇,用环境变量添加新的cudnn:
https://blog.csdn.net/HaoZiHuang/article/details/126051132
7. trt 环境验证
这是实验图片 dasima.jpeg :

最后验证一下环境,从这篇
https://blog.csdn.net/HaoZiHuang/article/details/125795230
的第五部分 5. 验证TRT环境 撸个代码:
import tensorrt as trt
import numpy as np
import os
import pycuda.driver as cuda
import pycuda.autoinit
import cv2
import matplotlib.pyplot as plt
class HostDeviceMem(object):
def __init__(self, host_mem, device_mem):
self.host = host_mem
self.device = device_mem
def __str__(self):
return "Host:\n" + str(self.host) + "\nDevice:\n" + str(self.device)
def __repr__(self):
return self.__str__()
class TrtModel:
def __init__(self,engine_path, max_batch_size=1, dtype=np.float32):
self.engine_path = engine_path
self.dtype = dtype
self.logger = trt.Logger(trt.Logger.WARNING)
self.runtime = trt.Runtime(self.logger)
self.engine = self.load_engine(self.runtime, self.engine_path)
self.max_batch_size = max_batch_size
self.inputs, self.outputs, self.bindings, self.stream = self.allocate_buffers()
self.context = self.engine.create_execution_context()
@staticmethod
def load_engine(trt_runtime, engine_path):
trt.init_libnvinfer_plugins(None, "")
with open(engine_path, 'rb') as f:
engine_data = f.read()
engine = trt_runtime.deserialize_cuda_engine(engine_data)
return engine
def allocate_buffers(self):
inputs = []
outputs = []
bindings = []
stream = cuda.Stream()
for binding in self.engine:
size = trt.volume(self.engine.get_binding_shape(binding)) * self.max_batch_size
host_mem = cuda.pagelocked_empty(size, self.dtype)
device_mem = cuda.mem_alloc(host_mem.nbytes)
bindings.append(int(device_mem))
if self.engine.binding_is_input(binding):
inputs.append(HostDeviceMem(host_mem, device_mem))
else:
outputs.append(HostDeviceMem(host_mem, device_mem))
return inputs, outputs, bindings, stream
def __call__(self,x:np.ndarray,batch_size=2):
x = x.astype(self.dtype)
np.copyto(self.inputs[0].host,x.ravel())
for inp in self.inputs:
cuda.memcpy_htod_async(inp.device, inp.host, self.stream)
self.context.execute_async(batch_size=batch_size, bindings=self.bindings, stream_handle=self.stream.handle)
for out in self.outputs:
cuda.memcpy_dtoh_async(out.host, out.device, self.stream)
self.stream.synchronize()
return [out.host.reshape(batch_size,-1) for out in self.outputs]
if __name__ == "__main__":
batch_size = 1
trt_engine_path = os.path.join("outfpbest.engine") # 这里是 Trt 模型的位置
model = TrtModel(trt_engine_path)
shape = model.engine.get_binding_shape(0)
img_path = "dasima.jpeg" # <--------------- 这里传入照片
# 以下是图片预处理
data = cv2.imread(img_path)
ori_shape = data.shape[:-1]
data = cv2.resize(data, (224, 224)) / 255 # 224 可能也需要改,我模型的输入是224
data = data.transpose(2, 0, 1)
data = data[None]
# 前向传播
result = model(data, batch_size)[0]
# 进行后处理,因为其返回是一个一维的张量
result = result.reshape(2, 224, 224).argmax(axis=0).astype(np.uint8)
result = cv2.resize(result, ori_shape[::-1], cv2.INTER_LINEAR)
plt.imshow(result)
plt.savefig('res.jpg')
plt.show()
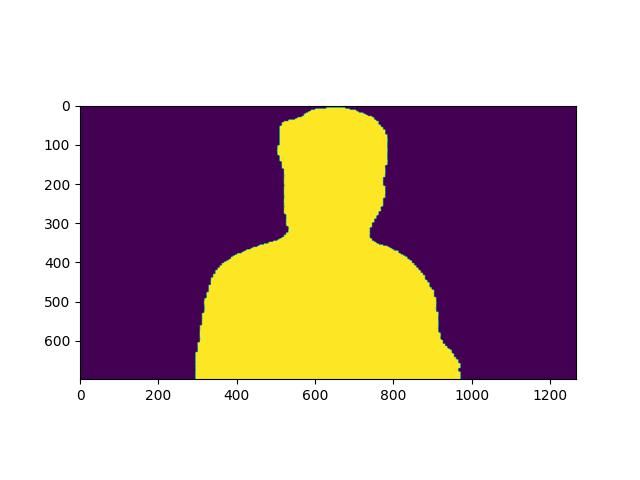
这是最后的结果图片
7.1 小插曲

尽管执行成功,但是依旧有个小问题,会报一个Error:
Error Code 1: Cuda Runtime (invalid argument)
无伤大雅,原因可能是:
The problem is that the engine outlives the CUDA context created by PyCUDA. One solution would be to scope the engine’s lifetime.
def main(): engine = build_engine_from_onnx(args.onnx) serialize_engine_to_file(engine, args.savepth) if __name__ == '__main__': main()
参考自:
https://github.com/NVIDIA/TensorRT/issues/2052