1. Resnet网络详解
一、ResNet网络介绍
ResNet是2015年有微软实验室提出的,题目:

作者是何凯明等,这四个都是华人。
当年ResNet斩获了当年各种第一名。基本上只要它参加的比赛,全都是第一名。

我们来看一下ResNet 34层网络的结构图(34-layer residual):
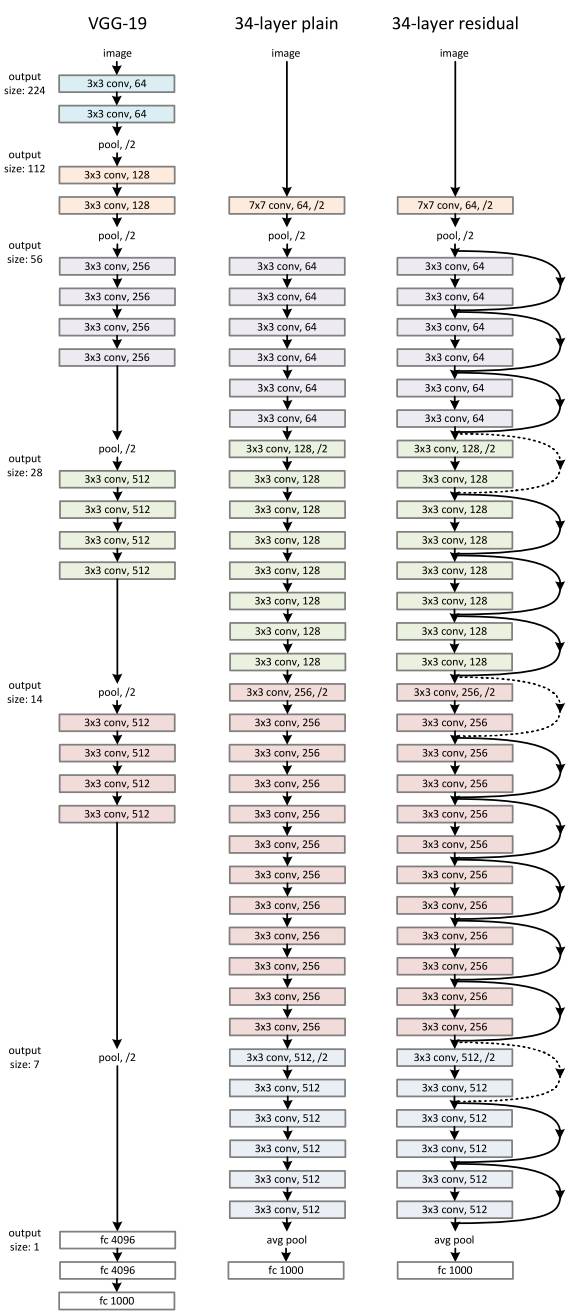
首先是一个卷积层,然后是一个池化层,然后由一系列的残差结构,最后再通过一个平均池化下采样以及一个全连接层得到最终输出。其实这个网络结构看起来很简单,基本上都是通过堆叠残差结构得到。
这里我总结了一下ResNet网络的三点:
(1)网络结构特别的深。
在原论文中,作者有尝试搭建1000多层的网络。而之前讲的AlexNet,VGG等,他们的深度也就在十几层到二十几层之间。这里可能有人会说,那我直接将一系列的卷积核池化不断叠加,我也能搭建一个超深的网络呀?
下面我们来看一下这些图。这些图都是从ResNet的原论文中截取出来的:

左边的图,就是将卷积层和池化层进行堆叠,所搭建的网络结构。我们可以看到20层的网络的训练错误大概在1%、2%左右,而56层的网络错误率在7%、8%,这说明层数越深效果越好。是什么原因造成更深的网络效果越差呢?
在ResNet网络中,作者提出了两个问题。
第一个,随着网络加深,梯度消失或者梯度爆炸现象会越来越明显。我们做一个假设,假设每一层的误差梯度是一个小于1的数,那么在反向传播过程中,每向前传播一次,都要乘以一个小于1的误差梯度。当网络越来越深的时候,梯度会越来越小,这就是梯度消失。反过来,每一层的梯度是一个大于1的数,会导致梯度爆炸现象。梯度消失和梯度爆炸现象怎么解决呢?通常是通过数据标准化处理、权重初始化、BN来解决。
第二个问题,作者称为退化问题。也就是说在解决了梯度消失或爆炸问题之后,我们仍然会存在层数深的效果层数少的效果好。该怎么解决呢?论文提出通过残差结构解决。右图是搭建的一系列网络,图中实现代表训练集的错误率,虚线代表验证机的错误率。可以看到,层数越深,错误率越小。与左图对比,看到ResNet确实解决了文中提到的退化问题。
(2)提出residual(残差)结构。
我们来看一下残差结构是什么样子。
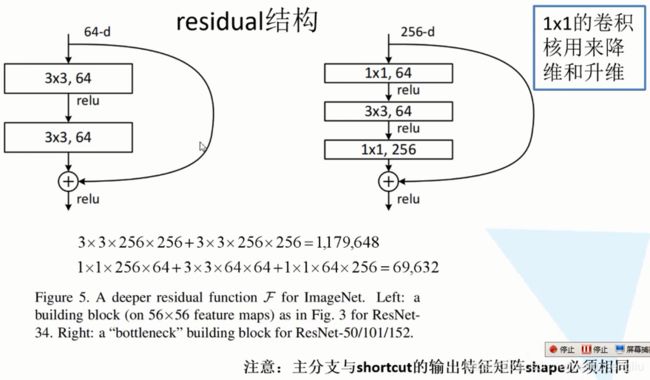
这也是从原文截下来的。左边的结构是针对于网络结构较少的网络使用的,比如34层。而右边是对50层,101层,152层提出来的结构。
看左图。主线是将输入特征矩阵经过两个3*3的的卷积层。右边有一个弧线,直接从输入连接到输出。注分支上得到的特征矩阵再与输入特征矩阵相加,相加之后再通过ReLU函数。既然是相加,需要注意,主分支与shortcut的输出特征矩阵shape(w、h、c)必须是相同的。
右图。依次通过1*1的卷积层,3*3的卷积层,1*1的卷积层。右图比左图比起来,到底节省了多少参数呢?假设左图也是输入256维的向量,第一个卷积层是3*3*256,第二个卷积层也是3*3*256,那么第一个卷积层需要3*3*256(注:输入图像通道数)*256(注:卷积核个数) ;第二个卷积层也需要3*3*256*256个参数。共需要1,179,648个参数。而右图需要:1*1*256*64+3*3*64*64+1*1*64*256 = 69632个参数。一个118万,一个7万。明显少了很多。而且,在网络搭建的过程中可不止一个残差结构,而是十几个、几十个残差结构。
(3)使用BN处理。
使用了这个方法之后,就不需要使用dropout方法了。
二、ResNet网络参数详解
下面这张表格就是原论文所给出来的参数列表。对应的18层的网络、34层的网络、50层的网络、101层的网络、152层的网络。

我们可以看到这几个网络的整个网络框架是类似的。同样是经过7*7的池化层,然后经过3*3的最大下采样。再经过一系列的残差结构。最后平均下采样、全连接层、输出层。
1. resnet18/34
下面我们再结合34层的网络,对整个表格进行讲解。



输入图片224*224*3
(1) 经过7*7,64,卷积
stride=2,padding=3。输出尺寸为(224-7+6)/2 + 1 = 112.5下取整 = 112。 所以输出112*112*64。
(2)max pooling
卷积核大小3*3,stride=2,padding=1。输出尺寸为(112-3+2)/2 + 1 = 56.5下取整=56。所以输出56*56*64。
(3)conv2_x。经过3个残差结构。
第一个残差结构:
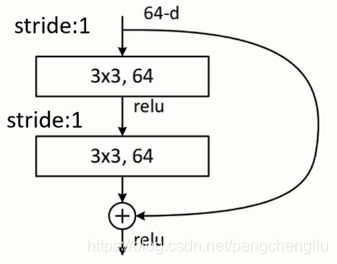
主分支上,首先 经过3*3*64的卷积层。stride=1,padding=1。输出尺寸(56+2-3)/1 + 1 = 56。所以输出56*56*64。经过第二个卷积层完全一样,输出还是56*56*64。
主分支与捷径上都是56*56*64,进行相加操作。
第二、三个残差结构与第一个残差结构完全一样。
所以经过conv2_x之后,输出为56*56*64。
(4)conv3_x。经过4个残差结构。其中第一个残差结构是虚线,二三四个残差结构是实线。为什么会不一样呢?因为要保证主分支和shortcut的输出特征shape相同,还用实现的话不能保证这一点。
第一个残差结构:

输入是56*56*64的特征图。
主分支:首先经过3*3*128的卷积层。stride=2,padding =1。输出尺寸(56+2-3)/2 +1 = 28.5下取整=28。所以输出尺寸28*28*128。然后经过3*3*128的卷积层。stride=1,padding=1。输出尺寸(28+2-3)/1+1 = 28。所以输出28*28*128。
捷径:经过1*1*128的卷积层。stride=2,padding=0。输出尺寸(56-1)/2 +1 = 28。输出为28*28*128。
主分支和捷径的结果shape相同,所以可以相加。结果为28*28*128。
第二个残差结构:
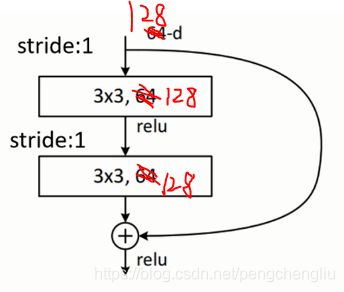
输入是28*28*128。经过经过3*3*128的卷积层。stride=1,padding=1。输出尺寸(28+2-3)/1 + 1 = 28。所以输出28*28*128。经过第二个卷积层完全一样,输出还是28*28*128。
主分支与捷径上都是28*28*128,进行相加操作。
第三、四个残差结构与第二个残差结构完全一样。
(5)conv4_x。经过6个残差结构。其中第一个是虚线;后五个相同,是实线。原理跟conv3_x相同。
(6)con5_x。经过3个残差结构。其中第一个是虚线。后2个相同,是实现。原理跟conv3_x相同。
(7)avg-pooling。
(8)fc
2. ResNet50/101/152
对于深的网络,如ResNet 50/101/152,跟resnet34一样。只不过他们使用的残差结构为:

其中,虚线的结构为conv3_x,conv4_x, conv5_x的第一个残差结构。