Positional Encodings in ViTs 近期各视觉Transformer中的位置编码方法总结及代码解析 1
Positional Encodings in ViTs 近期各视觉Transformer中的位置编码方法总结及代码解析
最近CV领域的Vision Transformer将在NLP领域的Transormer结果借鉴过来,屠杀了各大CV榜单。对其做各种改进的顶会论文也是层出不穷,本文将聚焦于各种最新的视觉transformer的位置编码PE(positional encoding)部分的设计思想及代码实现做一些总结。
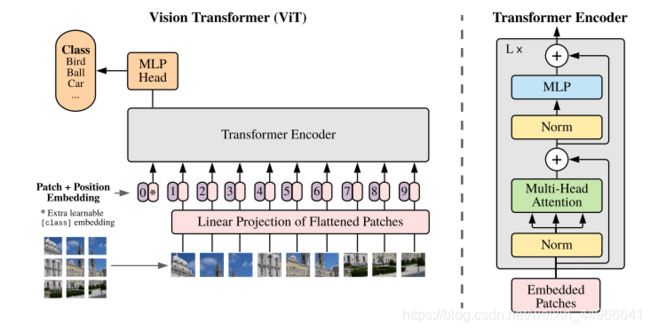
ViT
[2021-ICLR] AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
论文:https://arxiv.org/abs/2010.11929
代码:https://github.com/lucidrains/vit-pytorch/blob/main/vit_pytorch
对于原始的ViT,笔者曾做过一份较为全面的代码解析及图解:Vision Transformer(ViT)PyTorch代码全解析(附图解),有兴趣的读者可以参考。
论文中的位置编码方法
PE的设计
在ViT中,并没有对位置编码做过多的设计,只是使用一组可学习的参数来学习位置编码,注意这样的位置编码如果在面对测试时的高分辨率图像时是无法处理的。
ViT原文是这么说的:
When feeding images of higher resolution, we keep the patch size the same, which results in a larger effective sequence length. The Vision Transformer can handle arbitrary sequence lengths (up to memory constraints), however, the pre-trained position embeddings may no longer be meaningful. We therefore perform 2D interpolation of the pre-trained position embeddings, according to their location in the original image. Note that this resolution adjustment and patch extraction are the only points at which an inductive bias about the 2D structure of the images is manually injected into the Vision Transformer.
大概意思就是:当输入高分图像时,会导致序列的长度变长,ViT是可以处理任意长度的,但此时训练得到的位置编码就不再有意义了,并且只能通过2D插值实现。
z = [ x c l a s s ; x p 1 E , x p 2 E , … ; x p N E ] + E p o s , E ∈ R ( P 2 ⋅ C ) × D , E p o s ∈ R ( N + 1 ) × D ( 1 ) \mathbf{z}=[\mathbf{x}_{class};\mathbf{x}^1_p\mathbf{E},\mathbf{x}^2_p\mathbf{E},\dots;\mathbf{x}^N_p\mathbf{E}]+\mathbf{E}_{pos},\ \ \ \mathbf{E}\in\mathbb{R}^{(P^2\cdot C)\times D},\mathbf{E}_{pos}\in \mathbb{R}^{(N+1)\times D} \ \ \ \ \ \ \ \ \ \ \ \ \ (1) z=[xclass;xp1E,xp2E,…;xpNE]+Epos, E∈R(P2⋅C)×D,Epos∈R(N+1)×D (1)
根据原文公式(即上式),ViT中位置编码的维度应该为 ( N + 1 ) × D (N+1)\times D (N+1)×D ,这里 N N N 是图块的个数,+1是加上class token, D D D 是映射后的每个token的维度,因为要直接相加,所以要保持一致。下面会用代码来验证查看。
关于PE的消融实验
原文附录中的实验也显示肯定是有位置编码比没有效果要好,但是看起来比较有设计的二维位置编码和相对位置编码相较于简单的一维位置编码性能反而更差。
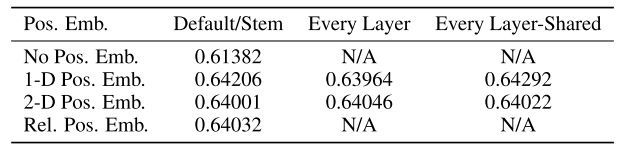
第一行是完全没有位置编码,即没有提供位置信息,相当于将一堆patch直接输入进去;第二行是一维位置编码,即将输入patch看作是序列;第三行是二维位置编码,将输入看作是二维的patch网格;第四行是相对位置编码,考虑到patch之间的相对距离,将空间信息编码为而不是其绝对位置。
注意:如果要使用相对位置编码,一定要考虑好自己的任务需不需要绝对位置信息,如目标检测,由于要输出预测的边界框的坐标,因此绝对位置信息是必须的,这时使用相对位置编码就不合适了。
关于PE的可视化实验
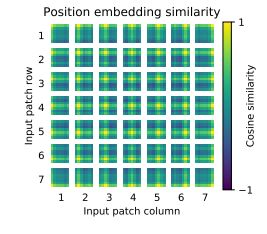
ViT原文对位置编码做的可视化实验如下图所示,热力图的含义是某个位置的图块的位置编码与全图其他位置图块的位置编码的余弦相似度。我们可以看到,当然与自己相似度最高,然后就是同行同列也比较高,其他的位置就低一些,这也基本符合我们对位置编码的基本期望,因为所谓的位置编码要的就是图像块在原图中的位置信息,更通俗点说就是行列信息,即某个图像块是在原图中的哪行哪列。
代码分析
ViT代码中的位置编码:
self.pos_embedding = nn.Parameter(torch.randn(1, num_patches+1, dim))
# ...
x += self.pos_embedding[:, :(n+1)]
直接用可学习的参数torch.Parameter()作为位置编码直接加到token序列中,跟随整个训练过程一起学习。(关于torch.Parameter()的介绍可见博客:PyTorch中的torch.nn.Parameter() 详解)
另外,我们再用代码来检查一下ViT中的位置编码的维度形状,这里我们直接借用timm库中的实现:
import timm
model = timm.create_model('vit_base_patch16_224', pretrained=True, num_classes=10)
pos_embed = model.state_dict()['pos_embed']
print(pos_embed.shape)
输出:
torch.Size([1, 197, 768])
我们是将224x224的图像分为14x14个图块,共196块,再加上class token 为197,而768则是我们指定的维度,符合我们的预期。
CPVT
Conditional Positional Encodings for Vision Transformers
论文:https://arxiv.org/abs/2102.10882
代码:https://github.com/Meituan-AutoML/Twins (原文中给的链接中没有实做代码,实做代码发布在这个仓库了)
论文中的位置编码方法
CPVT与ViT的位置编码的区别在下图中体现的很明显,ViT的位置编码PE没有过多的设计,直接加到patch token和cls token得到的embedding上,然后就送到后面的多个transformer block(图中encoder)中,注意ViT中的PE必须显示地指定好token序列的长度。而CPVT则是先不加PE,在第一个transformer block之后,仅过PEG(Postional Encoding Generator)来生成位置编码,在加到第一层的输出上,在进行后面的计算,这样长度就不需要显式指定,可以随输入变化而变化,因此被称为隐式的条件位置编码。
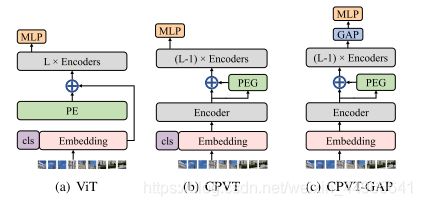
其中的PEG模块是用来产生条件位置编码的模块,其框架如下图所示:
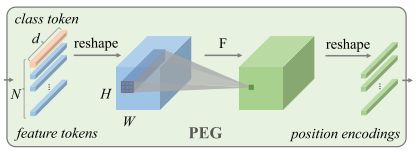
在 PEG 中,将上一层 Encoder 的 1D 输出变形成 2D,再使用 F 学习其位置信息,最后重新变形到 1D 空间,与之前的 1D 输出相加之后作为下一个 Encoder 的输入。
具体来说,在上图中,为了根据局部领域,我们首先将DeiT flatten过的输入序列 X ∈ R B × N × C X\in \mathbb{R}^{B\times N\times C} X∈RB×N×C reshape回二维图像空间 X ′ ∈ R B × H × W × C X'\in\mathbb{R}^{B\times H\times W\times C} X′∈RB×H×W×C 。然后某个函数 F \mathcal{F} F 会反复作用于 X ′ X' X′ 中的局部图块来生成条件位置编码 E B × H × W × C E^{B\times H\times W\times C} EB×H×W×C ,PEG可以由二维卷积高效地实现,其卷积核 k > = 3 k>=3 k>=3,并且有零填充 k − 1 2 \frac{k-1}{2} 2k−1 。注意这里的零填充是很重要的,它可以使模型感知到绝对位置, F \mathcal{F} F 可以是多种形式,比如可分离卷积。
代码分析
在CPVT的代码实现中,我们主要来看PEG部分:
class PosCNN(nn.Module):
def __init__(self, in_chans, embed_dim=768, s=1):
super(PosCNN, self).__init__()
self.proj = nn.Sequential(nn.Conv2d(in_chans, embed_dim, 3, s, 1, bias=True, groups=embed_dim), )
self.s = s
def forward(self, x, H, W):
B, N, C = x.shape
feat_token = x
cnn_feat = feat_token.transpose(1, 2).view(B, C, H, W)
if self.s == 1:
x = self.proj(cnn_feat) + cnn_feat
else:
x = self.proj(cnn_feat)
x = x.flatten(2).transpose(1, 2)
return x
def no_weight_decay(self):
return ['proj.%d.weight' % i for i in range(4)]
可以看到,与原文中对PEG的介绍一致:将第一层Encoder 的1D 输出变形成 2D,再使用F学习其位置信息,最后重新变形到 1D 空间,与之前的 1D 输出相加之后作为下一个 Encoder 的输入。
这里的self.proj就是文中的转换函数 F。
我们再来看PEG模块在整个CPVT中的使用:
class CPVTV2(PyramidVisionTransformer):
def __init__(self, ...)
# ...
self.pos_block = nn.ModuleList( # 实例化一个PEG模块
[PosCNN(embed_dim, embed_dim) for embed_dim in embed_dims]
)
# ...
def forward_features(self, x):
B = x.shape[0]
for i in range(len(self.depths)):
x, (H, W) = self.patch_embeds[i](x)
x = self.pos_drops[i](x)
for j, blk in enumerate(self.blocks[i]):
x = blk(x, H, W)
if j == 0:
x = self.pos_block[i](x, H, W) # PEG模块 在这里使用
if i < len(self.depths) - 1:
x = x.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous()
x = self.norm(x)
return x.mean(dim=1)
可以看到,只有在第一个encoder之后(for循环中j=0时),使用PEG模块计算位置编码,后面正常进行其他的其他Encoder的计算,与论文原文一致。
本文将保持持续更新,读者如果遇到有趣的Vision Transformer的改进方法,也欢迎分享讨论。