模型实践 | 高精地图构建模型HDMapNet助力更精准的自动驾驶
实验 | Freja 算力支持 | 幻方AIHPC
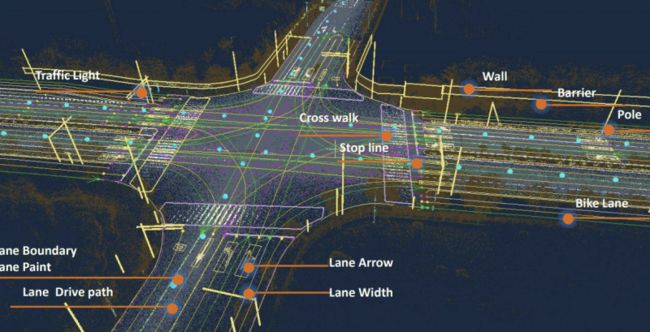
高精地图是自动驾驶系统的关键模块,可以有效提升自动驾驶汽车的行驶安全度,强化自动驾驶系统的整体感知能力和决策能力。然而传统的高精地图构建流程复杂,需要消耗大量的资源和人力,导致其扩展性和实时性无法满足自动驾驶的使用需求。
CVPR 2021 Workshop 最佳论文提名的一篇文章 HDMapNet,来自清华大学交叉信息院 MARS Lab,提出了一个使用深度神经网络实时构建局部高精地图的思路,该方法是从传统的高精地图构建流程转向端到端方法的关键工作。
幻方AI最近对这项工作进行了整理和优化,在幻方萤火二号上复现了实验。通过幻方自研的 3FS、hfreduce、算子,对模型训练进行提速,整合代码、简化接口,融入hfai数据仓库和模型仓库中,帮助研究者和开发者们降低使用门槛。本期文章将为大家详细描述。
模型介绍
1 高精地图
高精地图分为影像地图和语义地图,自动驾驶使用的通常是高精地图的语义地图部分,因此本文的高精地图特指高精语义地图。高精地图是车道级别、厘米精度的道路网络和交通信息地图,包括且不限于如下标注信息:
-
厘米级车道边线和中心线几何信息
-
车道线类型(白虚线/白实线/黄虚线/黄实线)
-
车道线类(高速/城市道路/自行车道)
-
交通信息(红绿灯/限速)
高精地图作为自动驾驶汽车的高精度“记忆”模块,是自动驾驶决策的关键依据,离开了“记忆”,无论眼睛(摄像头和雷达)和思考(控制决策系统)有多么发达,都无法对事件有全局的把控。高精地图为自动驾驶系统提供了:
-
厘米精度的定位
-
超过相机视野的地图记忆
-
反应当前路况的实时信息
2 传统高精地图构建流程

构建传统的高精地图需要经过一系列流程:
-
使用车辆到道路上采集信息,需要大量的人力和车辆资源。
-
将收集到的数据进行处理,包括点云拼接、地图生产等。
-
对点云中的信息进行识别,例如道路、车速牌等。
-
人工验证识别结果的准确性,确定最终的标注。
构建完成后还需要定时进行更新维护,以适应不断变化的路况信息,这样繁杂的流程需要消耗大量的资源和人力,导致其扩展性和实时性无法满足自动驾驶系统的使用需求。
3 HDMapNet
HDMapNet 提出了一种使用车载传感器(相机、雷达)来动态构建局部高精地图的方法,主要创新点如下:
-
将高精地图使用向量化的方法进行表示,包括:
▲语义分割向量化:使用三个类别表示道路边缘、道路分割线、斑马线三类线段
▲实例分割向量化:使用不同的编号标识不同的线段
▲方向识别向量化:使用 36 个集合表示 360 度的道路方向
-
使用深度神经网络学习从相机前视图到鸟瞰视图的转换
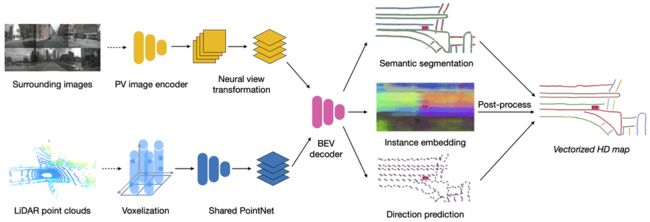
HDMapNet 的整体网络结构如上,输入为 RGB 图片或者雷达点云,两种输入可以单独使用,也可以同时使用,实验结果表示,RGB 图片和雷达点云同时使用时能达到最佳性能。
RGB 图片通过基于 EfficientNet 的图像编码器进行编码,如下面图中所示,本车周围六个方向均匀放置了六个相机,在每一个时刻,将六个相机获得的 RGB 图片编码成六个前视图的隐含表征。视角变换步骤(Neural view transformation)利用相机外参,将前视图的隐含表征转换到鸟瞰图的隐含表征,如下面图片的中间步骤到右边步骤的对应关系。最后使用鸟瞰图解码器从鸟瞰图的隐含表征中解码得到最终的鸟瞰图表示。

雷达点云先进行像素化,再通过点云网络得到鸟瞰图的隐含表征,最后通过鸟瞰图解码器解码得到最终的鸟瞰图表示。
将 RGB 输入和雷达点云输入处理得到鸟瞰图表示后,HDMapNet 使用三个分支:
-
语义分割预测:预测鸟瞰视角下,道路边缘、道路分割线、斑马线三个类别,使用二元交叉熵作为损失函数。
-
实例分割预测:用不同编号标识不同线段,使用 DiscriminativeLoss 作为损失函数。
-
道路方向预测:用 36 类分别代表 360 度的道路方向,使用二元交叉熵作为损失函数。
模型实践
幻方 AI 基于 lift-splat-shoot 复现了 HDMapNet,再基于 HDMapNet 开源代码 进行修正,采用幻方一系列优化工具进行提速升级,包括 hfreduce 并行训练、hfai 数据集接入、hfai 集群训练断点挂起等功能。
1 数据集
HDMapNet 使用 NuScenes 数据集进行试验,NuScenes 数据集是第一个提供自动汽车全套传感器数据的大型数据集,包括了6个相机、1个激光雷达、5个毫米波雷达、以及GPS 和 IMU。与另一个常用的自动驾驶领域 KITTI 数据集相比,其包含的对象注释多了7倍多。
这里幻方 AI 将 NuScenes 数据集进行处理,将原始数据集转换成 ffrecord 的格式,用户调用简单的接口便可以加载高性能的 dataloader 进行模型训练。具体如下示例:
from hfai.datasets import NuScenes dataset = NuScenes(split='train') loader = dataset.loader(batch_size=64, num_workers=4)for data_dict in loader: # training model ...
仅仅需要上述 4 行代码,我们便可以获得如下格式的 NuScenes 数据集:

2 模型训练
萤火二号提供了统一的训练管理平台,可以将大量的训练任务依据优先级负载均衡到不同的GPU上执行,充分利用起计算算力。我们只需加入如下几行代码,便可以提交训练任务。
1. 登录幻方萤火二号,引入hfai
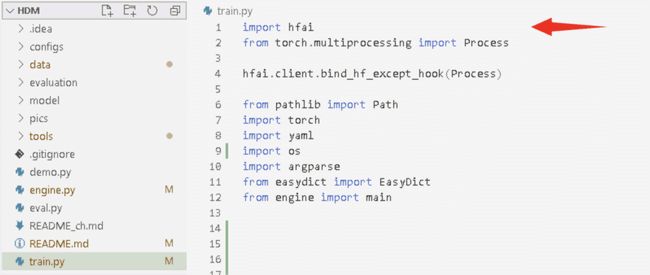
2. 初始化 hfreduce 分布式参数

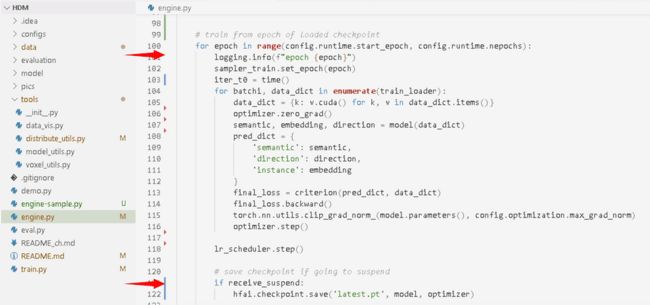
3. 对于每一轮训练,加入接收集群调度的逻辑代码,并做好模型 checkpoint 的保存
3 训练结果
我们申请 4 个节点,32 张显卡进行并行训练。通过hfai命令行工具提交任务,训练效果如下图所示:

在萤火二号上训练 HDMapNet,每个 Epoch 耗时仅 5 分钟左右,相比单卡性能提升了 32 倍以上。GPU 利用率在 95% 左右,充分利用其了 A100 的计算性能。模型在第 24 轮基本达到了收敛状态。
训练效果可视化如下:
▲可视化效果1:

▲可视化效果2:

体验总结
HDMapNet 新颖地提出了使用深度神经网络构建局部高精地图的方法,减少了传统构建方法耗费大量人力和资源的问题、增加了高精地图的可扩展性和实时性,有助于构建更加智能的自动驾驶系统。幻方 AI 对 HDMapNet 的实验进行了复现,借助萤火二号对 HDMapNet 的训练进行了优化,最终达到了超过单卡 32 倍的训练速度。
体验打分总结如下:
01 研究指数 ★★★★
该模型以低成本、端到端的方法实时构建局部高精地图,是自动驾驶领域的重要课题。
02 开源指数 ★★★★★
数据处理和代码都已经开源,代码逻辑清晰、可读性高。
03 门槛指数 ★★★
数据量、模型大小中等,普通高性能单卡即可运行。
04 通用指数 ★★
该方法是基于神经网络构建高精地图方法的早期工作,地图丰富度、定位精度、预测性能有待提升。
05 适配指数 ★★★★★
依赖简单,很容易与幻方AI的训练优化工具结合,提效明显。
附录
论文标题:
HDMapNet: An Online HD Map Construction and Evaluation Framework
原文地址:
https://arxiv.org/abs/2107.06307
项目主页:
https://tsinghua-mars-lab.github.io/HDMapNet
模型仓库:
https://github.com/HFAiLab/hdmapnet
点击下方链接,幻方AI BLOG更多干货奉上
幻方 | 技术博客