python处理ECG二进制文件(.dat文件)和.db文件
python处理ECG二进制文件(.dat文件)和.db文件
最近拿到了一批ECG原数据文件(包括.dat和.db文件),需要自己解析,记录一下解析结果。
1、.dat 文件是病人的心电数据,以二进制形式读取和解析。
数据文件的说明:
数据文件记录的是8通道数据(I,II,V1,V2,V3,V4,V5,V6),读取后通过下列计算公式得出12通道的数据(I,II,III,aVR,aVF,aVL,V1,V2,V3,V4,V5,V6)。
# 8通道换算12导联计算公式
III = II - I
aVR = -(I+II)/2
aVL = I - II/2
aVF = II - I/2
数据存储规则:数值采用 16 位有符号整型表示,数值范围-32768~32767,电极电压 1mV 对应数值 81.92。(这个解析方式只适合本数据,不同数据的存储规则可能不一样!)
数据的存储顺序:每一块包括8个导联,每一导联256个数据点(512个字节)。

# 需要用到的库
import numpy as np
import matplotlib.pyplot as plt
import os
import sqlite3
# .dat文件的读取
path = r'D:\data\yxd\2021\01\c85f6b13-b57a-4f7e-91ad-5b51906c4cef.dat' # 路径
with open(file=path_dat, mode='rb') as f:
data = f.read()
print(len(data))
print(data[0:100]) # 查看前100个数据
这里输出内容为字节,按照十六进制计算,两个字节为一个数据点。
# 初始化要输出的字典,字典的键为导联名称,值为列表 保存导联对应的数值。
lead_name = ['I', 'II', 'V1', 'V2', 'V3', 'V4', 'V5', 'V6']
output = {}
for name in lead_name:
output[name] = []
因为不确定是大端还是小端存取数据,所以两种存取方式都试了一下。这里也包括对补码的处理(如果符号位为1,将补码除符号位外所有位取反,加1 ,最后加上符号位为负)。
# 小端 表示先读取的低地址存储低位数据,后读取的高地址存储高位数据
index = 40960 #从data[40960]开始,因为前边一段时间的心电记录可能会不稳定或噪音比较多
for k in range(10): # 读取数据块数,这里时间原因只读取10块
for i in range(8): # 导联数
for j in range(256): #每一导联的数据点数
byte_high = bin(data[index]) #这里读取两个字节
byte_low = bin(data[index+1])
index+=2 #每读取两个字节,对data的索引加2
data_plot = str(byte_low[3:]+byte_high[2:]) #两个字节以二进制拼接,并且要祛除符号位
if byte_low[2] == '0': # 符号位为正,直接按照原码读取
value = int(data_plot, 2) * 0.0122 #二进制转化为十进制,并且按照规则将单位转化为mv
elif byte_low[2] == '1': #符号位为负,按照补码的规则转化为原码
negative = ''
for m in range(len(data_plot)): #对除符号位以外的取反
if data_plot[m] == '0':
negative += '1'
elif data_plot[m] == '1':
negative += '0'
else:
print("data_plot is not 0 or 1!")
value = -1 * (int(negative, 2)+1) * 0.0122
else:
print("data符号出错!")
# print(value)
output1[lead_name[i]].append(value)
print(len(output['I'])) #输出为2560 表示每导联正确读取了2560个数据点
# 大端 表示先读取的低地址存储高位数据,后读取的高地址存储低位数据
index = 40960 #从data[40960]开始,因为前边一段时间的心电记录可能会不稳定或噪音比较多
for k in range(10): # 读取数据块数,这里时间原因只读取10块
for i in range(8): # 导联数
for j in range(256): #每一导联的数据点数
byte_low = bin(data[index]) #这里读取两个字节
byte_high = bin(data[index+1])
index+=2 #每读取两个字节,对data的索引加2
data_plot = str(byte_high[3:]+byte_low[2:]) #两个字节以二进制拼接,并且要祛除符号位
if byte_high[2] == '0': # 符号位为正,直接按照原码读取
value = int(data_plot, 2) * 0.0122 #二进制转化为十进制,并且按照规则将单位转化为mv
elif byte_high[2] == '1': #符号位为负,按照补码的规则转化为原码
negative = ''
for m in range(len(data_plot)): #对除符号位以外的取反
if data_plot[m] == '0':
negative += '1'
elif data_plot[m] == '1':
negative += '0'
else:
print("data_plot is not 0 or 1!")
value = -1 * (int(negative, 2)+1) * 0.0122
else:
print("data符号出错!")
# print(value)
output1[lead_name[i]].append(value)
print(len(output['I'])) #输出为2560 表示每导联正确读取了2560个数据点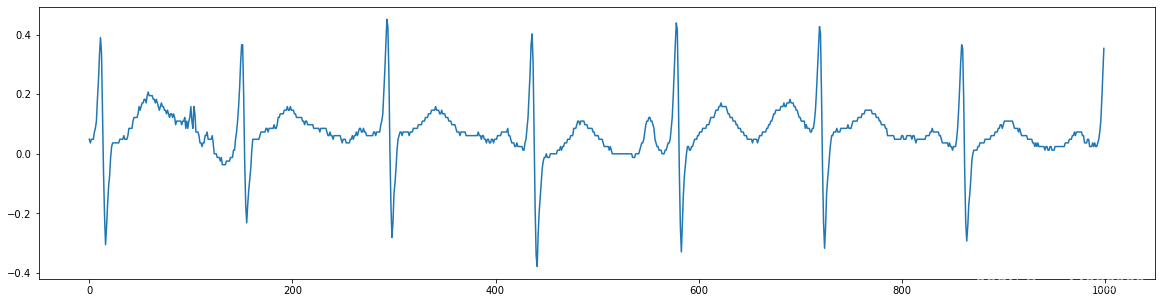
大端读取,描绘的波形明显是错误的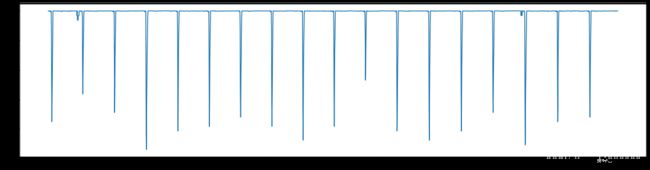 小端读取,描绘的ECG波形大致正确,所以确实是小端存取
小端读取,描绘的ECG波形大致正确,所以确实是小端存取
2、读取.db文件
path_ann = r'D:\data\yxd\2021\01\2cd05e3c-d599-4bb5-9905-a6faa00a1ece.db' # 路径
mydb = sqlite3.connect(path_ann) #连接数据库
cursor = mydb.cursor()
cursor.execute("select * from HeartBeat") # 执行SQL语句,查找HeartBeat表
col_name = [tuple[0] for tuple in cursor.description] # 读取表HeartBeat的列名
print(col_name)

# 将表内对应的列名设置为字典的键,列的值设置为字典的值。
annotation = {}
for name in col_name:
annotation[name] = []
Tables = cursor.fetchall()
for item in Tables:
for i in range(len(col_name)):
annotation[col_name[i]].append(item[i])
# print(annotation.keys())
此时可以读取字典annotation中对应的字段。
以上全部代码写入.py文件如下
import numpy as np
import matplotlib.pyplot as plt
import os
import sqlite3
def load_data(path_dat):
# 读取dat文件
with open(file=path_dat, mode='rb') as f:
data = f.read()
block_num = int(os.path.getsize(path_dat)/512/8)
lead_name = ['I', 'II', 'V1', 'V2', 'V3', 'V4', 'V5', 'V6']
output = {}
for name in lead_name:
output[name] = []
index = 0
for k in range(block_num):
for i in range(8):
for j in range(256):
byte_high = bin(data[index])
byte_low = bin(data[index + 1])
index += 2
data_plot = str(byte_low[3:] + byte_high[2:])
if byte_low[2] == '0':
value = int(data_plot, 2) * 0.0122
elif byte_low[2] == '1':
negative = ''
for m in range(len(data_plot)):
if data_plot[m] == '0':
negative += '1'
elif data_plot[m] == '1':
negative += '0'
else:
print("data_plot is not 0 or 1!")
value = -1 * (int(negative, 2) + 1) * 0.0122
else:
print("data符号出错!")
# print(value)
output[lead_name[i]].append(value)
for name_add in ['III', 'aVR', 'aVL', 'aVF']:
output[name_add] = []
for i in range(len(output['I'])):
output['III'].append(output['II'][i] - output['I'][i])
output['aVR'].append(output['II'][i] - output['I'][i] * 0.5)
output['aVL'].append(output['I'][i] - output['II'][i] * 0.5)
output['aVF'].append((output['II'][i] + output['I'][i]) * 0.5)
return output
def load_ann(path_ann):
mydb = sqlite3.connect(path_ann)
cursor = mydb.cursor()
cursor.execute("select * from HeartBeat")
col_name = [tuple[0] for tuple in cursor.description] #列名
# print(col_name)
annotation = {}
for name in col_name:
annotation[name] = []
Tables = cursor.fetchall()
for item in Tables:
for i in range(len(col_name)):
annotation[col_name[i]].append(item[i])
return annotation
if __name__ == '__main__':
path_dat = r'D:\data\yxd\2021\01\c85f6b13-b57a-4f7e-91ad-5b51906c4cef.dat'
path_ann = r'D:\data\yxd\2021\01\2cd05e3c-d599-4bb5-9905-a6faa00a1ece.db'
data = load_data(path_dat) # 返回一个字典
ann = load_ann(path_ann) # 返回一个字典
print(data.keys())
# plt.figure(figsize = (20,5))
# plt.plot(data['I'][0:2500])
# plt.figure(figsize = (20,5))
# plt.plot(data['II'][0:2500])
# plt.show()