12 变分推断(Variational Inference)
12 变分推断(Variational Inference)
- 1 背景
-
- 1.1 优化问题(概率角度)
-
- 1.1.1 回归
- 1.1.2 SVM (Classification)
- 1.1.3 EM 算法
- 1.2 积分问题(贝叶斯角度)
- 1.3 Inference
- 2 公式推导
-
- 2.1 公式化简
- 2.2 模型求解
- 3 回顾
-
- 3.1 数学符号规范化
- 3.2 迭代算法求解
- 3.3 Mean Field Theory 的存在问题
- 4 SGVI:Stochastic Gradient Variational Inference
-
- 4.1 SGVI 参数规范
- 4.2 SGVI 的梯度推导
-
- 4.2.1 关于第二部分的求解
- 4.2.2 关于第一部分的求解
- 4.3 Variance Reduction
- 4.4 小结
假设我们的⽬的是求解分布 p,但是该分布不容易表达,即很难直接求解。此时可以⽤变分推断的⽅法 寻找⼀个容易表达和求解的分区 q ,当 q 和 p 的差距很⼩的时候,q 就可以作为 p 的近似分布了。
1 背景
我们已经知道概率模型可以分为,频率派的优化问题和贝叶斯派的积分问题。
1.1 优化问题(概率角度)
为什么说频率派角度的分析是一个优化问题呢?我们从回归和SVM 两个例子上进行分析。我们将数据集描述为: D = { ( x i , y i ) } i = 1 N , x i ∈ R p , y i ∈ R D=\left\{\left(x_{i}, y_{i}\right)\right\}_{i=1}^{N}, x_{i} \in \mathbf{R}^{p}, y_{i} \in \mathbf{R} D={(xi,yi)}i=1N,xi∈Rp,yi∈R。
1.1.1 回归
回归模型可以被我们定义为: f ( w ) = w T x f(w) = w^T x f(w)=wTx,其中loss function 被定义为: L ( w ) = Σ i = 1 N ∣ ∣ w T x i − y i ∣ ∣ 2 L(w) =Σ_{i=1}^N||w^T x_i -y_i||^2 L(w)=Σi=1N∣∣wTxi−yi∣∣2,优化可以表达为 w ^ = a r g m i n L ( w ) \hat{w} = argmin L(w) w^=argminL(w) 。这是个无约束优化问题。
求解的方法可以分成两种,数值解和解析解。
- 解析解的解法为: ∂ L ( w ) ∂ w = 0 ⇒ w ∗ = ( X T X ) − 1 X T Y \frac{\partial L(w)}{\partial w}=0 \Rightarrow w^{*}=\left(X^{T} X\right)^{-1} X^{T} Y ∂w∂L(w)=0⇒w∗=(XTX)−1XTY其中,X 是一个 nxp 的矩阵。
- 数值解:GD 算法,也就是Gradient Descent,或者Stochastic Gradient descent (SGD)。

1.1.2 SVM (Classification)
SVM 的模型可以被我们表述为: f ( w ) = s i g n ( w T + b ) f(w) = sign(w^T + b) f(w)=sign(wT+b)。loss function 被我们定义为:
{ min 1 2 w T w s.t. y i ( w T x i + b ) ≥ 1 \left\{\begin{array}{ll} \min & \frac{1}{2} w^{T} w \\ \text {s.t.} & y_{i}(w^{T} x_{i}+b) \geq 1\end{array}\right. {mins.t.21wTwyi(wTxi+b)≥1很显然这是一个有约束的Convex 优化问题。常用的解决条件为,QP 方法和Lagrange 对偶。

1.1.3 EM 算法
我们的优化目标为: θ ^ = a r g m a x l o g p ( x ∣ θ ) \hat{\theta} = argmax \ \ log p(x|\theta) θ^=argmax logp(x∣θ)
优化的迭代算法为: θ ( t + 1 ) = argmax θ ∫ z log p ( X , Z ∣ θ ) ⋅ p ( Z ∣ X , θ ( t ) ) d z \theta^{(t+1)}=\operatorname{argmax}_{\theta} \int_{z} \log p(X, Z | \theta) \cdot p\left(Z | X, \theta^{(t)}\right) d z θ(t+1)=argmaxθ∫zlogp(X,Z∣θ)⋅p(Z∣X,θ(t))dz

1.2 积分问题(贝叶斯角度)
从贝叶斯的角度来说,这就是一个积分问题,为什么呢?我们看看Bayes 公式的表达: p ( θ ∣ x ) = p ( x ∣ θ ) p ( θ ) p ( x ) p(\theta | x)=\frac{p(x | \theta) p(\theta)}{p(x)} p(θ∣x)=p(x)p(x∣θ)p(θ)
其中, p ( θ ∣ x ) p(\theta|x) p(θ∣x) 称为后验公式, p ( x ∣ θ ) p(x|\theta) p(x∣θ) 称为似然函数, p ( θ ) p(\theta) p(θ) 称为先验分布,并且 p ( x ) = ∫ θ p ( x ∣ θ ) p ( θ ) d θ p(x) =\int_{\theta} p(x|\theta)p(\theta)d \theta p(x)=∫θp(x∣θ)p(θ)dθ 。什么是推断呢?通俗的说就是求解后验分布 p ( θ ∣ x ) p(\theta|x) p(θ∣x)。而 p ( θ ∣ x ) p(\theta|x) p(θ∣x) 的计算在高维空间的时候非常的复杂,我们通常不能直接精确的求得,这是就需要采用方法来求一个近似的解。而贝叶斯的方法往往需要我们解决一个贝叶斯决策的问题,也就是根据数据集 X X X ( N N N 个样本)。我们用数学的语言来表述也就是, X ~ \tilde{X} X~~为新的样本,求
p ( X ~ ∣ X ) = ∫ θ p ( X ~ , θ ∣ X ) d θ = ∫ θ p ( X ~ ∣ θ ) ⋅ p ( θ ∣ X ) d θ = E θ ∣ X [ p ( X ~ ∣ θ ) ] \begin{aligned} p(\tilde{X} | X) &=\int_{\theta} p(\tilde{X}, \theta | X) d \theta \\ &=\int_{\theta} p(\tilde{X} | \theta) \cdot p(\theta | X) d \theta \\ &=\mathrm{E}_{\theta | X}[p(\tilde{X} | \theta)] \end{aligned} p(X~∣X)=∫θp(X~,θ∣X)dθ=∫θp(X~∣θ)⋅p(θ∣X)dθ=Eθ∣X[p(X~∣θ)]其中 p ( θ ∣ X ) p(\theta|X) p(θ∣X) 为一个后验分布,那么我们关注的重点问题就是求这个积分。

1.3 Inference
我们看到,推断问题的中心是参数后验分布的求解,推断分为:
- 精确推断
- 近似推断——参数空间无法精确求解
a. 确定性近似——如变分推断
b. 随机近似——如 MCMC,MH,Gibbs
2 公式推导
本章主要讲的是 贝叶斯角度 ⇒ \Rightarrow ⇒ 贝叶斯推断 ⇒ \Rightarrow ⇒ 近似推断 ⇒ \Rightarrow ⇒ 确定性近似推断 ⇒ \Rightarrow ⇒ 变分推断
我们将
X:Observed data;
Z:Latent Variable + Parameters。
那么 (X;Z) 为complete data。
根据我们的贝叶斯分布公式,边同时取对数我们可以得到:
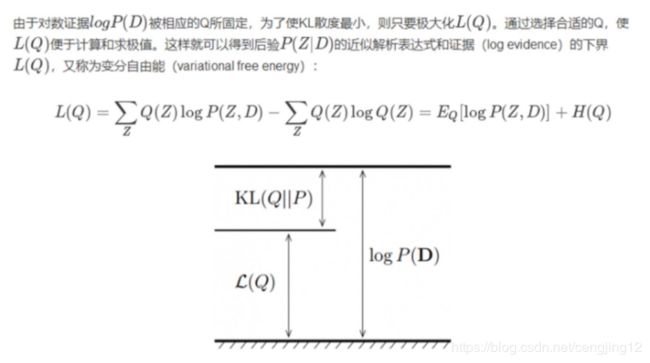
log p ( X ) = log p ( X , Z ) p ( Z ∣ X ) = log p ( X , Z ) − log p ( Z ∣ X ) = log p ( X , Z ) q ( Z ) − log p ( Z ∣ X ) q ( Z ) \begin{aligned} \log p(X) &=\log \frac{p(X, Z)}{p(Z | X)} \\ &=\log p(X, Z)-\log p(Z | X) \\ &=\log \frac{p(X, Z)}{q(Z)}-\log \frac{p(Z | X)}{q(Z)} \end{aligned} logp(X)=logp(Z∣X)p(X,Z)=logp(X,Z)−logp(Z∣X)=logq(Z)p(X,Z)−logq(Z)p(Z∣X)
2.1 公式化简
两边对 p ( Z ) p(Z) p(Z) 求期望
L e f t : ∫ Z q ( Z ) log p ( X ) d Z = log p ( X ) Left:\int_Zq(Z)\log p(X)dZ=\log p(X) Left:∫Zq(Z)logp(X)dZ=logp(X) R i g h t : ∫ Z [ log p ( X , Z ) q ( Z ) − log p ( Z ∣ X ) q ( Z ) ] q ( Z ) d Z = E L B O + K L ( q , p ) Right:\int_Z[\log \frac{p(X,Z)}{q(Z)}-\log \frac{p(Z|X)}{q(Z)}]q(Z)dZ=ELBO+KL(q,p) Right:∫Z[logq(Z)p(X,Z)−logq(Z)p(Z∣X)]q(Z)dZ=ELBO+KL(q,p)
其中, ∫ Z [ log p ( X , Z ) q ( Z ) \int_Z[\log \frac{p(X,Z)}{q(Z)} ∫Z[logq(Z)p(X,Z)被称为Evidence Lower Bound (ELBO),被我们记为 L ( q ) L(q) L(q),也就是变分。
− ∫ Z log p ( Z ∣ X ) q ( Z ) ] q ( Z ) d Z -\int_Z\log \frac{p(Z|X)}{q(Z)}]q(Z)dZ −∫Zlogq(Z)p(Z∣X)]q(Z)dZ被称为 K L ( q , p ) KL(q,p) KL(q,p)。这里的 0 ≤ K L ( q , p ) 0\le KL(q,p) 0≤KL(q,p)。
由于我们求不出 p ( Z ∣ X ) p(Z|X) p(Z∣X),我们的目的是寻找一个 q ( Z ) q(Z) q(Z),使得 p ( Z ∣ X ) p(Z|X) p(Z∣X) 近似于 q ( Z ) q(Z) q(Z),也就是 K L ( q , p ) KL(q,p) KL(q,p) 越小越好。并且, p ( X ) p(X) p(X) 是个定值,那么我们的目标变成了 a r g m a x q ( z ) L ( q ) argmax_{q(z)}L(q) argmaxq(z)L(q)。那么,我们理一下思路,我们想要求得一个 q ~ ( Z ) ≈ p ( Z ∣ X ) \widetilde{q}(Z) \approx {p(Z|X)} q (Z)≈p(Z∣X)。也就是
q ~ ( Z ) = argmax q ( z ) L ( q ) ⇒ q ~ ( Z ) ≈ p ( Z ∣ X ) \tilde{q}(Z)=\operatorname{argmax}_{q(z)} \mathcal{L}(q) \Rightarrow \widetilde{q}(Z) \approx {p(Z|X)} q~(Z)=argmaxq(z)L(q)⇒q (Z)≈p(Z∣X)
求 KL 最小也就是 ELBO 最大。通过上述方法将变分推断转化成优化问题。
- 什么是变分?
通俗理解就是自变量是函数的函数,即 F ( f ) F(f) F(f) 。当 f f f 发生改变时, F ( f ) F(f) F(f) 所发生的改变,称之为变分,当 f f f 退化成一个变量时,所发生的改变就是微分。- 什么是KL Divergence 即KL散度?

2.2 模型求解
那么我们如何来求解这个问题呢?我们使用到统计物理中的一种方法,就是平均场理论(mean field theory)。也就是假设变分后验分式是一种完全可分解的分布:
假设 q ( Z ) q(Z) q(Z) 可以划分为 M M M 个组(平均场近似): q ( z ) = ∏ i = 1 M q i ( z i ) q(z)=\prod_{i=1}^{M} q_{i}\left(z_{i}\right) q(z)=i=1∏Mqi(zi)在假设中, q 1 , q 2 , ⋯ q_1,q_2,\cdots q1,q2,⋯ 相互独立。在这种分解的思想中,我们每次只考虑第 j j j 个分布,那么令其他的 q i q_i qi 固定 i ∈ ( 1 , 2 , ⋯ , j − 1 , j + 1 , ⋯ , M ) i \in (1,2, \cdots, j - 1, j + 1,\cdots,M) i∈(1,2,⋯,j−1,j+1,⋯,M) 。那么很显然:
E L B O = L ( q ) = ∫ Z q ( Z ) log p ( X , Z ) d Z − ∫ Z q ( Z ) log q ( Z ) d Z ELBO=L(q)=\int_Zq(Z)\log p(X,Z)dZ-\int_Zq(Z)\log{q(Z)}dZ ELBO=L(q)=∫Zq(Z)logp(X,Z)dZ−∫Zq(Z)logq(Z)dZ我们先来分析第一项 ∫ Z q ( Z ) log p ( X , Z ) d Z \int_Zq(Z)\log p(X,Z)dZ ∫Zq(Z)logp(X,Z)dZ。
∫ Z q ( Z ) log p ( X , Z ) d Z = ∫ Z ∏ i = 1 M q i ( z i ) log p ( X , Z ) d Z = ∫ z j q j ( z j ) [ ∫ z 1 ∫ z 2 ⋯ ∫ z M ∏ i = 1 , i ≠ j M q i ( z i ) log p ( X , Z ) d z 1 d z 2 ⋯ d z M ] d z j = ∫ z j q j ( z j ) [ ∫ z 1 ∫ z 2 ⋯ ∫ z M log p ( X , Z ) ∏ i = 1 , i ≠ j M q i ( z i ) d z 1 d z 2 ⋯ d z M ] d z j = ∫ z j q j ( z j ) E Π i ≠ j M q i ( x i ) [ log p ( X , Z ) ] d z j = ∫ z j q j ( z j ) log p ^ ( X , z j ) d z j \begin{aligned} \int_{Z} q(Z) \log p(X, Z) d Z &=\int_{Z} \prod_{i=1}^{M} q_{i}\left(z_{i}\right) \log p(X, Z) d Z \\ &=\int_{z_{j}} q_{j}\left(z_{j}\right)\left[\int_{z_{1}} \int_{z_{2}} \cdots \int_{z_{M}} \prod_{i=1,i \neq j}^{M} q_{i}\left(z_{i}\right) \log p(X, Z) d z_{1} d z_{2} \cdots d z_{M}\right] d z_{j} \\ &=\int_{z_{j}} q_{j}\left(z_{j}\right)\left[\int_{z_{1}} \int_{z_{2}} \cdots \int_{z_{M}} \log p(X, Z) \prod_{i=1,i \neq j}^{M} q_{i}\left(z_{i}\right) d z_{1} d z_{2} \cdots d z_{M}\right] d z_{j} \\ &=\int_{z_{j}} q_{j}\left(z_{j}\right) \mathbf{E}_{\Pi_{i \neq j}^{M} q_{i}\left(x_{i}\right)}[\log p(X, Z)] d z_{j} \\ & =\int_{z_{j}} q_{j}\left(z_{j}\right) \log \hat{p}\left(X, z_{j}\right) d z_{j} \end{aligned} ∫Zq(Z)logp(X,Z)dZ=∫Zi=1∏Mqi(zi)logp(X,Z)dZ=∫zjqj(zj)⎣⎡∫z1∫z2⋯∫zMi=1,i=j∏Mqi(zi)logp(X,Z)dz1dz2⋯dzM⎦⎤dzj=∫zjqj(zj)⎣⎡∫z1∫z2⋯∫zMlogp(X,Z)i=1,i=j∏Mqi(zi)dz1dz2⋯dzM⎦⎤dzj=∫zjqj(zj)EΠi=jMqi(xi)[logp(X,Z)]dzj=∫zjqj(zj)logp^(X,zj)dzj
在上式中,我们令 E Π i ≠ j M q i ( x i ) [ log p ( X , Z ) ] = ∫ z j q j ( z j ) log p ^ ( X , z j ) d z j \mathbf{E}_{\Pi_{i \neq j}^{M} q_{i}\left(x_{i}\right)}[\log p(X, Z)]=\int_{z_{j}} q_{j}\left(z_{j}\right) \log \hat{p}\left(X, z_{j}\right) d z_{j} EΠi=jMqi(xi)[logp(X,Z)]=∫zjqj(zj)logp^(X,zj)dzj这里的 p ^ ( X , z j ) \hat{p}\left(X, z_{j}\right) p^(X,zj) 表示为一个相关的函数形式,假设具体参数未知。
然后我们来分析第二项 ∫ Z q ( Z ) log q ( Z ) d Z = ∫ Z ∏ i = 1 M q i ( z i ) log ∏ i = 1 M q i ( z i ) d Z = ∫ Z ∏ i = 1 M q i ( z i ) ∑ i = 1 M log q i ( z i ) d Z = ∫ Z ∏ i = 1 M q i ( z i ) [ log q 1 ( z 1 ) + log q 2 ( z 2 ) + ⋯ + log q M ( z M ) ] d Z \begin{aligned} \int_{Z} q(Z) \log q(Z) d Z &=\int_{Z} \prod_{i=1}^{M} q_{i}\left(z_{i}\right) \log \prod_{i=1}^{M} q_{i}\left(z_{i}\right) d Z \\ &=\int_{Z} \prod_{i=1}^{M} q_{i}\left(z_{i}\right) \sum_{i=1}^{M} \log q_{i}\left(z_{i}\right) d Z \\ &=\int_{Z} \prod_{i=1}^{M} q_{i}\left(z_{i}\right)\left[\log q_{1}\left(z_{1}\right)+\log q_{2}\left(z_{2}\right)+\cdots+\log q_{M}\left(z_{M}\right)\right] d Z \end{aligned} ∫Zq(Z)logq(Z)dZ=∫Zi=1∏Mqi(zi)logi=1∏Mqi(zi)dZ=∫Zi=1∏Mqi(zi)i=1∑Mlogqi(zi)dZ=∫Zi=1∏Mqi(zi)[logq1(z1)+logq2(z2)+⋯+logqM(zM)]dZ这个公式的计算如何进行呢?我们抽出一项来看,就会变得非常的清晰:
∫ Z ∏ i = 1 M q i ( z i ) log q 1 ( z 1 ) d Z = ∫ z 1 z 2 ⋯ z M q 1 q 2 ⋯ q M log q 1 d z 1 d z 2 ⋯ z M = ∫ z 1 q 1 log q 1 d z 1 ⋅ ∫ z 2 q 2 d z 2 ⋅ ∫ z 3 q 3 d z 3 ⋯ ∫ z M q M d z M = ∫ z 1 q 1 log q 1 d z 1 \begin{aligned} \int_{Z} \prod_{i=1}^{M} q_{i}\left(z_{i}\right) \log q_{1}\left(z_{1}\right) d Z &=\int_{z_{1} z_{2} \cdots z_{M}} q_{1} q_{2} \cdots q_{M} \log q_{1} d z_{1} d z_{2} \cdots z_{M} \\ &=\int_{z_{1}} q_{1} \log q_{1} d z_{1} \cdot \int_{z_{2}} q_{2} d z_{2} \cdot \int_{z_{3}} q_{3} d z_{3} \cdots \int_{z_{M}} q_{M} d z_{M} \\ &=\int_{z_{1}} q_{1} \log q_{1} d z_{1} \end{aligned} ∫Zi=1∏Mqi(zi)logq1(z1)dZ=∫z1z2⋯zMq1q2⋯qMlogq1dz1dz2⋯zM=∫z1q1logq1dz1⋅∫z2q2dz2⋅∫z3q3dz3⋯∫zMqMdzM=∫z1q1logq1dz1以此类推。所以第二项可以写为:
∑ i = 1 M ∫ z i q i ( z i ) log q i ( z i ) d z i = ∫ z j q j ( z j ) log q j ( z j ) d z j + C \sum_{i=1}^{M} \int_{z_{i}} q_{i}\left(z_{i}\right) \log q_{i}\left(z_{i}\right) d z_{i}=\int_{z_{j}} q_{j}\left(z_{j}\right) \log q_{j}\left(z_{j}\right) d z_{j}+C i=1∑M∫ziqi(zi)logqi(zi)dzi=∫zjqj(zj)logqj(zj)dzj+C因为每次只求一项,如 q j q_j qj,故其他项可以看成常数C。
根据上面的推导,可得
L ( q ) = ∫ Z q ( Z ) log p ( X , Z ) d Z − ∫ Z q ( Z ) log q ( Z ) = ∫ z j q j ( z j ) log p ^ ( X , z j ) d z j − ∫ z j q j ( z j ) log q j ( z j ) d z j − C = − K L ( q j ∥ p ^ ( x , z j ) ) ≤ 0 \begin{aligned} L(q) & =\int_Zq(Z)\log p(X,Z)dZ-\int_Zq(Z)\log{q(Z)} \\ \\ & =\int_{z_{j}} q_{j}\left(z_{j}\right) \log \hat{p}\left(X, z_{j}\right) d z_{j}-\int_{z_{j}} q_{j}\left(z_{j}\right) \log q_{j}\left(z_{j}\right) d z_{j}-C \\ \\ &=-K L\left(q_{j} \| \hat{p}\left(x, z_{j}\right)\right) \leq 0 \end{aligned} L(q)=∫Zq(Z)logp(X,Z)dZ−∫Zq(Z)logq(Z)=∫zjqj(zj)logp^(X,zj)dzj−∫zjqj(zj)logqj(zj)dzj−C=−KL(qj∥p^(x,zj))≤0 arg max q j ( z j ) − K L ( q j ∥ p ^ ( x , z j ) ) \arg \max _{q_{j}\left(z_{j}\right)}-K L\left(q_{j} \| \hat{p}\left(x, z_{j}\right)\right) argmaxqj(zj)−KL(qj∥p^(x,zj)) 等价于 argmin q j ( z j ) K L ( q j ∥ p ^ ( x , z j ) ) \operatorname{argmin}_{q_{j}\left(z_{j}\right)} K L\left(q_{j} \| \hat{p}\left(x, z_{j}\right)\right) argminqj(zj)KL(qj∥p^(x,zj))。那么这个 K L ( q j ∥ p ^ ( x , z j ) ) K L\left(q_{j} \| \hat{p}\left(x, z_{j}\right)\right) KL(qj∥p^(x,zj))要如何进行优化呢?我们下一节将回归EM 算法,并给出求解的过程。
3 回顾
在上一小节中,我们介绍了Mean Field Theory Variational Inference 的方法。在这里我需要进一步做一些说明, z i z_i zi 表示的不是一个数,而是一个数据维度的集合,它表示的不是一个维度,而是一个类似的最大团,也就是多个维度凑在一起。本节使⽤的符号会与前⾯的略有不同, 说明如下:
x:observed variable : X = { x ( i ) } i = 1 N X=\left\{x^{(i)}\right\}_{i=1}^{N} X={x(i)}i=1N
z:latent variable : Z = { z ( i ) } i = 1 N Z=\left\{z^{(i)}\right\}_{i=1}^{N} Z={z(i)}i=1N
variation 的核心思想是在于用一个分布 q q q 来近似得到 p ( z j , x ) p(z_j,x) p(zj,x)。
-
优化目标为, q ^ = a r g m i n K L ( q ∣ p ) \hat{q} = argmin KL(q|p) q^=argminKL(q∣p)。
-
其中: log p ( X ∣ θ ) = E L B O ( L ( q ) ) + K L ( q ∥ p ) ≥ L ( q ) \log p(X | \theta)=E L B O(\mathcal{L}(q))+K L(q \| p) \geq \mathcal{L}(q) logp(X∣θ)=ELBO(L(q))+KL(q∥p)≥L(q)
在这个求解中,我们主要想求的是 q ( x ) q(x) q(x),那么我们需要弱化 θ \theta θ 的作用。
-
所以,目标函数为: q ^ = argmin q K L ( q ∥ p ) = argmax q L ( q ) \hat{q}=\operatorname{argmin}_{q} K L(q \| p)=\operatorname{argmax}_{q} \mathcal{L}(q) q^=argminqKL(q∥p)=argmaxqL(q)
在上一小节中,这是我们的便于观察的表达方法,但是我们需要严格的使用我们的数学符号。
3.1 数学符号规范化
在这里我们弱化了相关参数 θ \theta θ,也就是求解过程中,不太考虑 θ \theta θ 起到的作用。我们展示一下似然函数, log p θ ( X ) = log ∏ i = 1 N p θ ( x ( i ) ) = ∑ i = 1 N log p θ ( x ( i ) ) \log p_{\theta}(X)=\log \prod_{i=1}^{N} p_{\theta}\left(x^{(i)}\right)=\sum_{i=1}^{N} \log p_{\theta}\left(x^{(i)}\right) logpθ(X)=logi=1∏Npθ(x(i))=i=1∑Nlogpθ(x(i))我们的目标是使每一个 x ( i ) x^{(i)} x(i) 最大,所以将对 E L B O ELBO ELBO 和 K L ( p ∣ ∣ q ) KL(p||q) KL(p∣∣q) 进行规范化表达:
ELBO:
E q ( z ) [ log p θ ( x ( i ) , z ) q ( z ) ] = E q ( z ) [ log p θ ( x ( i ) , z ) ] + H ( q ( z ) ) \mathbf{E}_{q(z)}\left[\log \frac{p_{\theta}\left(x^{(i)}, z\right)}{q(z)}\right]=\mathbf{E}_{q(z)}\left[\log p_{\theta}\left(x^{(i)}, z\right)\right]+H(q(z)) Eq(z)[logq(z)pθ(x(i),z)]=Eq(z)[logpθ(x(i),z)]+H(q(z))
KL:
K L ( q ∥ p ) = ∫ q ( z ) ⋅ log q ( z ) p θ ( z ∣ x ( i ) ) d z K L(q \| p)=\int q(z) \cdot \log \frac{q(z)}{p_{\theta}\left(z | x^{(i)}\right)} d z KL(q∥p)=∫q(z)⋅logpθ(z∣x(i))q(z)dz使用平均场理论进行分解,最终求得:
log q j ( z j ) = E Π i ≠ j q i ( z i ) [ log p θ ( x ( i ) , z ) ] + C = ∫ q 1 ∫ q 2 ⋯ ∫ q j − 1 ∫ q j + 1 ⋯ ∫ q M q 1 q 2 ⋯ q j − 1 q j + 1 ⋯ q M d q 1 d q 2 ⋯ d q j − 1 d q j + 1 ⋯ d q M \begin{aligned} \log q_{j}\left(z_{j}\right) &=\mathbf{E}_{\Pi_{i \neq j} q_{i}\left(z_{i}\right)}\left[\log p_{\theta}\left(x^{(i)}, z\right)\right]+C \\ &=\int_{q_{1}} \int_{q_{2}} \cdots \int_{q_{j-1}} \int_{q_{j+1}} \cdots \int_{q_{M}} q_{1} q_{2} \cdots q_{j-1} q_{j+1} \cdots q_{M} d q_{1} d q_{2} \cdots d q_{j-1} d q_{j+1} \cdots d q_{M} \end{aligned} logqj(zj)=EΠi=jqi(zi)[logpθ(x(i),z)]+C=∫q1∫q2⋯∫qj−1∫qj+1⋯∫qMq1q2⋯qj−1qj+1⋯qMdq1dq2⋯dqj−1dqj+1⋯dqM
3.2 迭代算法求解
在上一步中,我们已经将所有的符号从数据点和划分维度上进行了规范化的表达。在这一步中,我们将使用迭代算法来进行求解:
q ^ 1 ( z 1 ) = ∫ q 2 ⋯ ∫ q M q 2 ⋯ q M [ log p θ ( x ( i ) , z ) ] d q 2 ⋯ d q M q ^ 2 ( z 2 ) = ∫ q ^ 1 ( z 1 ) ∫ q 3 ⋯ ∫ q M q ^ 1 q 3 ⋯ q M [ log p θ ( x ( i ) , z ) ] q ^ 1 d q 2 ⋯ d q M q ^ M ( z M ) = ∫ q ^ 1 ⋯ ∫ q ~ M − 1 q ^ 1 ⋯ q ^ M − 1 [ log p θ ( x ( i ) , z ) ] d q ^ 1 ⋯ d q ^ M − 1 \begin{array}{c} \hat{q}_{1}\left(z_{1}\right)=\int_{q_{2}} \cdots \int_{q_{M}} q_{2} \cdots q_{M}\left[\log p_{\theta}\left(x^{(i)}, z\right)\right] d q_{2} \cdots d q_{M} \\ \\ \hat{q}_{2}\left(z_{2}\right)=\int_{\hat{q}_{1}\left(z_{1}\right)} \int_{q_{3}} \cdots \int_{q_{M}} \hat{q}_{1} q_{3} \cdots q_{M}\left[\log p_{\theta}\left(x^{(i)}, z\right)\right] \hat{q}_{1} d q_{2} \cdots d q_{M} \\ \\ \hat{q}_{M}\left(z_{M}\right)=\int_{\hat{q}_{1}} \cdots \int_{\tilde{q}_{M-1}} \hat{q}_{1} \cdots \hat{q}_{M-1}\left[\log p_{\theta}\left(x^{(i)}, z\right)\right] d \hat{q}_{1} \cdots d \hat{q}_{M-1} \end{array} q^1(z1)=∫q2⋯∫qMq2⋯qM[logpθ(x(i),z)]dq2⋯dqMq^2(z2)=∫q^1(z1)∫q3⋯∫qMq^1q3⋯qM[logpθ(x(i),z)]q^1dq2⋯dqMq^M(zM)=∫q^1⋯∫q~M−1q^1⋯q^M−1[logpθ(x(i),z)]dq^1⋯dq^M−1如果,我们将 q 1 , q 2 , ⋯ , q M q_1, q_2,\cdots,q_M q1,q2,⋯,qM 看成一个个的坐标点,那么我们知道的坐标点越来越多,这实际上就是一种坐标上升的方法(Coordinate Ascend)。
这是一种迭代算法,那我们怎么考虑迭代的停止条件呢?我们设置当 L ( t + 1 ) ≤ L ( t ) L(t+1) \le L(t) L(t+1)≤L(t) 时停止迭代。
3.3 Mean Field Theory 的存在问题
- 首先假设上就有问题,这个假设太强了。在假设中,我们提到,假设变分后验分式是一种完全可分解的分布。实际上,这样的适用条件挺少的。大部分时候都并不会适用。
- Intractable。本来就是因为后验分布 p ( Z ∣ X ) p(Z|X) p(Z∣X) 的计算非常的复杂,所以我们才使用变分推断来进行计算,但是有个很不幸的消息。这个迭代的方法也非常的难以计算,并且 log q j ( z j ) = E ∏ i ≠ j q i ( z i ) [ log p ( X , Z ∣ θ ) ] + C \log q_{j}\left(z_{j}\right)=\mathbf{E}_{\prod_{i \neq j} q_{i}\left(z_{i}\right)}[\log p(X, Z | \theta)]+C logqj(zj)=E∏i=jqi(zi)[logp(X,Z∣θ)]+C 的计算也非常的复杂。所以,我们需要寻找一种更加优秀的方法,比如 Stein Disparency 等等。Stein变分是个非常Fashion 的东西,机器学习理论中非常强大的算法,我们以后会详细的分析。
4 SGVI:Stochastic Gradient Variational Inference
在上一小节中,我们分析了Mean Field Theory Variational Inference,通过平均假设来得到变分推断的理论,是一种classical VI,我们可以将其看成Coordinate Ascend。而另一种方法是Stochastic Gradient Variational Inference (SGVI)。
对于隐变量参数 z z z 和数据集 x x x 。 z → x z \to x z→x 是Generative Model,也就是 p ( x ∣ z ) p(x|z) p(x∣z) 和 p ( x , z ) p(x, z) p(x,z),这个过程也被我们称为Decoder。 x → z x \to z x→z 是Inference Model,这个过程被我们称为Encoder,表达关系也就是 p ( z ∣ x ) p(z|x) p(z∣x) 。
4.1 SGVI 参数规范
我们知道,优化方法除了坐标上升,还有梯度上升的方式,我们希望通过梯度上升来得到变分推断的另一种算法。参数的更新方法为: θ ( t + 1 ) = θ ( t ) + λ ( t ) ∇ L ( q ) \theta^{(t+1)}=\theta^{(t)}+\lambda^{(t)} \nabla \mathcal{L}(q) θ(t+1)=θ(t)+λ(t)∇L(q)
其中, q ( z ∣ x ) q(z|x) q(z∣x) 被我们简化表示为 q ( z ) q(z) q(z),我们令 q ( z ) q(z) q(z) 是一个固定形式的概率分布, ϕ ϕ ϕ 为这个分布的参数,那么我们将把这个概率写成 q ϕ ( z ) q_ϕ(z) qϕ(z) 。
那么,我们需要对原等式中的表达形式进行更新,
E L B O = E q ϕ ( z ) [ log p θ ( x ( i ) , z ) − log q ϕ ( z ) ] = L ( ϕ ) E L B O=\mathbf{E}_{q_{\phi}(z)}\left[\log p_{\theta}\left(x^{(i)}, z\right)-\log q_{\phi}(z)\right]=\mathcal{L}(\phi) ELBO=Eqϕ(z)[logpθ(x(i),z)−logqϕ(z)]=L(ϕ)而, log p θ ( x ( i ) ) = E L B O + K L ( q ∥ p ) ≥ L ( ϕ ) \log p_{\theta}\left(x^{(i)}\right)=E L B O+K L(q \| p) \geq \mathcal{L}(\phi) logpθ(x(i))=ELBO+KL(q∥p)≥L(ϕ)而求解目标也转换成了:
p ^ = argmax ϕ L ( ϕ ) \hat{p}=\operatorname{argmax}_{\phi} \mathcal{L}(\phi) p^=argmaxϕL(ϕ)
4.2 SGVI 的梯度推导
∇ ϕ L ( ϕ ) = ∇ ϕ E q ϕ [ log p θ ( x ( i ) , z ) − log q ϕ ] = ∇ ϕ ∫ q ϕ [ log p θ ( x ( i ) , z ) − log q ϕ ] d z = ∫ ∇ ϕ ( q ϕ [ log p θ ( x ( i ) , z ) − log q ϕ ] ) d z = ∫ ∇ ϕ q ϕ [ log p θ ( x ( i ) , z ) − log q ϕ ] d z + ∫ q ϕ ∇ ϕ [ log p θ ( x ( i ) , z ) − log q ϕ ] d z \begin{aligned} \nabla_{\phi} \mathcal{L}(\phi) &=\nabla_{\phi} \mathbf{E}_{q_{\phi}}\left[\log p_{\theta}\left(x^{(i)}, z\right)-\log q_{\phi}\right] \\ &=\nabla_{\phi} \int q_{\phi}\left[\log p_{\theta}\left(x^{(i)}, z\right)-\log q_{\phi}\right] d z \\ &= \int \nabla_{\phi} \left(q_{\phi}\left[\log p_{\theta}\left(x^{(i)}, z\right)-\log q_{\phi}\right]\right) d z \\ &=\int \nabla_{\phi} q_{\phi}\left[\log p_{\theta}\left(x^{(i)}, z\right)-\log q_{\phi}\right] d z+\int q_{\phi} \nabla_{\phi}\left[\log p_{\theta}\left(x^{(i)}, z\right)-\log q_{\phi}\right] d z \end{aligned} ∇ϕL(ϕ)=∇ϕEqϕ[logpθ(x(i),z)−logqϕ]=∇ϕ∫qϕ[logpθ(x(i),z)−logqϕ]dz=∫∇ϕ(qϕ[logpθ(x(i),z)−logqϕ])dz=∫∇ϕqϕ[logpθ(x(i),z)−logqϕ]dz+∫qϕ∇ϕ[logpθ(x(i),z)−logqϕ]dz我们把这个等式拆成两个部分,其中:
∫ ∇ ϕ q ϕ [ log p θ ( x ( i ) , z ) − log q ϕ ] d z \int \nabla_{\phi} q_{\phi}\left[\log p_{\theta}\left(x^{(i)}, z\right)-\log q_{\phi}\right] d z ∫∇ϕqϕ[logpθ(x(i),z)−logqϕ]dz为第一个部分
∫ q ϕ ∇ ϕ [ log p θ ( x ( i ) , z ) − log q ϕ ] d z \int q_{\phi} \nabla_{\phi}\left[\log p_{\theta}\left(x^{(i)}, z\right)-\log q_{\phi}\right] d z ∫qϕ∇ϕ[logpθ(x(i),z)−logqϕ]dz为第二个部分。
4.2.1 关于第二部分的求解
第二部分比较好求,因为 p θ ( x ( i ) , z ) p_{\theta}\left(x^{(i)}, z\right) pθ(x(i),z) 与 ϕ ϕ ϕ 无关.
2 = ∫ q ϕ ∇ ϕ [ log p θ ( x ( i ) , z ) − log q ϕ ] d z = − ∫ q ϕ ∇ ϕ log q ϕ d z = − ∫ q ϕ 1 q ϕ ∇ ϕ q ϕ d z = − ∫ ∇ ϕ q ϕ d z = − ∇ ϕ ∫ q ϕ d z = − ∇ ϕ 1 = 0 \begin{aligned} 2 &=\int q_{\phi} \nabla_{\phi}\left[\log p_{\theta}\left(x^{(i)}, z\right)-\log q_{\phi}\right] d z \\ &=-\int q_{\phi} \nabla_{\phi} \log q_{\phi} d z \\ &=-\int q_{\phi} \frac{1}{q_{\phi}} \nabla_{\phi} q_{\phi} d z \\ &=-\int \nabla_{\phi} q_{\phi} d z \\ &=-\nabla_{\phi} \int q_{\phi} d z \\ &=-\nabla_{\phi} 1 \\ &=0 \end{aligned} 2=∫qϕ∇ϕ[logpθ(x(i),z)−logqϕ]dz=−∫qϕ∇ϕlogqϕdz=−∫qϕqϕ1∇ϕqϕdz=−∫∇ϕqϕdz=−∇ϕ∫qϕdz=−∇ϕ1=0
4.2.2 关于第一部分的求解
在这里我们用到了一个小trick,那就是 q ϕ ∇ ϕ log q ϕ = q ϕ ⋅ 1 q ϕ ∇ ϕ q ϕ = ∇ ϕ q ϕ q_{\phi} \nabla_{\phi} \log q_{\phi}=q_{\phi} \cdot \frac 1 q_{\phi}\nabla_{\phi} q_{\phi}=\nabla_{\phi} q_{\phi} qϕ∇ϕlogqϕ=qϕ⋅q1ϕ∇ϕqϕ=∇ϕqϕ。所以,我们代入到第一项中可以得到:
1 = ∫ ∇ ϕ q ϕ [ log p θ ( x ( i ) , z ) − log q ϕ ] d z = ∫ q ϕ ∇ ϕ log q ϕ [ log p θ ( x ( i ) , z ) − log q ϕ ] d z = E q ϕ [ ∇ ϕ log q ϕ log p θ ( x ( i ) , z ) − log q ϕ ] \begin{aligned} 1 &=\int \nabla_{\phi} q_{\phi}\left[\log p_{\theta}\left(x^{(i)}, z\right)-\log q_{\phi}\right] d z \\ &=\int q_{\phi} \nabla_{\phi} \log q_{\phi}\left[\log p_{\theta}\left(x^{(i)}, z\right)-\log q_{\phi}\right] d z \\ &=\mathbf{E}_{q_{\phi}}\left[\nabla_{\phi} \log q_{\phi} \log p_{\theta}\left(x^{(i)}, z\right)-\log q_{\phi}\right]\end{aligned} 1=∫∇ϕqϕ[logpθ(x(i),z)−logqϕ]dz=∫qϕ∇ϕlogqϕ[logpθ(x(i),z)−logqϕ]dz=Eqϕ[∇ϕlogqϕlogpθ(x(i),z)−logqϕ]那么,我们可以得到:
∇ ϕ L ( ϕ ) = E q ϕ [ ∇ ϕ log q ϕ log p θ ( x ( i ) , z ) − log q ϕ ] \nabla_{\phi} \mathcal{L}(\phi) =\mathbf{E}_{q_{\phi}}\left[\nabla_{\phi} \log q_{\phi} \log p_{\theta}\left(x^{(i)}, z\right)-\log q_{\phi}\right] ∇ϕL(ϕ)=Eqϕ[∇ϕlogqϕlogpθ(x(i),z)−logqϕ]那么如何求这个期望呢?我们采用的是蒙特卡罗采样法,假设 z l ∼ q ϕ ( z ) l = 1 , 2 , ⋯ z^{l} \sim q_{\phi}(z) l=1,2, \cdots zl∼qϕ(z)l=1,2,⋯,那么有: ∇ ϕ L ( ϕ ) ≈ 1 L ∑ l = 1 L ∇ ϕ log q ϕ ( z ( l ) ) [ log p θ ( x ( i ) , z ) − log q ϕ ( z ( l ) ) ] \nabla_{\phi} \mathcal{L}(\phi) \approx \frac{1}{L} \sum_{l=1}^{L} \nabla_{\phi} \log q_{\phi}\left(z^{(l)}\right)\left[\log p_{\theta}\left(x^{(i)}, z\right)-\log q_{\phi}\left(z^{(l)}\right)\right] ∇ϕL(ϕ)≈L1l=1∑L∇ϕlogqϕ(z(l))[logpθ(x(i),z)−logqϕ(z(l))]由于第二部分的结果为0,所以第一部分的解就是最终的解。但是,这样的求法有什么样的问题呢?因为我们在采样的过程中,很有可能采到 q ϕ ( z ) → 0 q_ϕ(z) \to0 qϕ(z)→0 的点,对于log 函数来说, l i m x → 0 l o g x = ∞ lim_{x\to 0} logx = \infty limx→0logx=∞ ,那么梯度的变化会非常的剧烈,非常的不稳定。对于这样的 High Variance 的问题,根本没有办法求解。实际上,我们可以通过计算得到这个方差的解析解,它确实是一个很大的值。事实上,这里的梯度的方差这么的大,而 ϕ ^ → q ( z ) \hat{ϕ} \to q(z) ϕ^→q(z) 也有误差,误差叠加,直接爆炸,根本没有办法用。也就是不会 work ,那么我们如何解决这个问题?
4.3 Variance Reduction
一种想法:若能使得 E q ϕ \mathbf{E}_{q_{\phi}} Eqϕ 中的 q ϕ q_ϕ qϕ 是一个确定分布,则会免去 ∇ ϕ log q ϕ \nabla_{\phi} \log q_{\phi} ∇ϕlogqϕ
这里采用了一种比较常见的方差缩减方法,称为 Reparameterization Trick(纯参数技巧),也就是对 q ϕ q_ϕ qϕ 做一些简化。
我们怎么可以较好的解决这个问题 ? 如果我们可以得到一个确定的解 p ( ϵ ) p(\epsilon) p(ϵ), 就会变得比较简单。因为 z z z 来自于 q ϕ ( z ∣ x ) q_{\phi}(z | x) qϕ(z∣x), 我们就想办法将 z 中的随机变量给解放出来。也就是使用一个转换 z = g ϕ ( ϵ , x ( i ) ) z=g_{\phi}\left(\epsilon, x^{(i)}\right) z=gϕ(ϵ,x(i)) 其中 ϵ ∼ p ( ϵ ) \epsilon \sim p(\epsilon) ϵ∼p(ϵ)。那么这样做,有什么好处呢 ? 原来的 ∇ ϕ E q ϕ [ ⋅ ] \nabla_{\phi} \mathbf{E}_{q_{\phi}}[\cdot] ∇ϕEqϕ[⋅] 将转换为 E p ( ϵ ) [ ∇ ϕ ( ⋅ ) ] \mathbf{E}_{p(\epsilon)}\left[\nabla_{\phi}(\cdot)\right] Ep(ϵ)[∇ϕ(⋅)] , 那么不再是连续的关于 ϕ \phi ϕ 的采样,这样可以有效的降低方差。并且, z z z 是一个关于 ϵ \epsilon ϵ 的函数,我们将随机性转移到了 ϵ \epsilon ϵ, 那么问题就可以简化为:
z ∼ q ϕ ( z ∣ x ( i ) ) ⟶ ϵ ∼ p ( ϵ ) z \sim q_{\phi}\left(z | x^{(i)}\right) \longrightarrow \epsilon \sim p(\epsilon) z∼qϕ(z∣x(i))⟶ϵ∼p(ϵ)而且,这里还需要引入一个等式,那就是:
∣ q ϕ ( z ∣ x ( i ) ) d z ∣ = ∣ p ( ϵ ) d ϵ ∣ \left|q_{\phi}\left(z | x^{(i)}\right) d z\right|=|p(\epsilon) d \epsilon| ∣∣∣qϕ(z∣x(i))dz∣∣∣=∣p(ϵ)dϵ∣为什么呢?我们直观性的理解一下, ∫ q ϕ ( z ∣ x ( i ) ) d z = ∫ p ( ϵ ) d ϵ = 1 \int q_{\phi}\left(z | x^{(i)}\right) d z=\int p(\epsilon) d \epsilon=1 ∫qϕ(z∣x(i))dz=∫p(ϵ)dϵ=1, 并且 q ϕ ( z ∣ x ( i ) ) q_{\phi}\left(z | x^{(i)}\right) qϕ(z∣x(i)) 和 p ( ϵ ) p(\epsilon) p(ϵ) 之间存在一个变换关系。那么,我们将改写 ∇ ϕ L ( ϕ ) \nabla_{\phi} \mathcal{L}(\phi) ∇ϕL(ϕ)
∇ ϕ L ( ϕ ) = ∇ ϕ E q ϕ [ log p θ ( x ( i ) , z ) − log q ϕ ] = ∇ ϕ ∫ [ log p θ ( x ( i ) , z ) − log q ϕ ] q ϕ d z = ∇ ϕ ∫ [ log p θ ( x ( i ) , z ) − log q ϕ ] p ( ϵ ) d ϵ = ∇ ϕ E p ( ϵ ) [ log p θ ( x ( i ) , z ) − log q ϕ ] = E p ( ϵ ) ∇ ϕ [ ( log p θ ( x ( i ) , z ) − log q ϕ ) ] = E p ( ϵ ) ∇ z [ ( log p θ ( x ( i ) , z ) − log q ϕ ( z ∣ x ( i ) ) ) ∇ ϕ z ] = E p ( ϵ ) ∇ z [ ( log p θ ( x ( i ) , z ) − log q ϕ ( z ∣ x ( i ) ) ) ∇ ϕ z ] = E p ( ϵ ) ∇ z [ ( log p θ ( x ( i ) , z ) − log q ϕ ( z ∣ x ( i ) ) ) ∇ ϕ g ϕ ( ϵ , x ( i ) ) ] \begin{aligned} \nabla_{\phi} \mathcal{L}(\phi) &=\nabla_{\phi} \mathbf{E}_{q_{\phi}}\left[\log p_{\theta}\left(x^{(i)}, z\right)-\log q_{\phi}\right] \\ &=\nabla_{\phi} \int\left[\log p_{\theta}\left(x^{(i)}, z\right)-\log q_{\phi}\right] q_{\phi} d z \\ &=\nabla_{\phi} \int\left[\log p_{\theta}\left(x^{(i)}, z\right)-\log q_{\phi}\right] p(\epsilon) d \epsilon \\ &=\nabla_{\phi} \mathbf{E}_{p(\epsilon)}\left[\log p_{\theta}\left(x^{(i)}, z\right)-\log q_{\phi}\right] \\ &=\mathbf{E}_{p(\epsilon)} \nabla_{\phi}\left[\left(\log p_{\theta}\left(x^{(i)}, z\right)-\log q_{\phi}\right)\right] \\ &=\mathbf{E}_{p(\epsilon)} \nabla_{z}\left[\left(\log p_{\theta}\left(x^{(i)}, z\right)-\log q_{\phi}\left(z | x^{(i)}\right)\right) \nabla_{\phi} z\right] \\ &=\mathbf{E}_{p(\epsilon)} \nabla_{z}\left[\left(\log p_{\theta}\left(x^{(i)}, z\right)-\log q_{\phi}\left(z | x^{(i)}\right)\right) \nabla_{\phi} z\right] \\ &=\mathbf{E}_{p(\epsilon)} \nabla_{z}\left[\left(\log p_{\theta}\left(x^{(i)}, z\right)-\log q_{\phi}\left(z | x^{(i)}\right)\right) \nabla_{\phi} g_{\phi}\left(\epsilon, x^{(i)}\right)\right] \end{aligned} ∇ϕL(ϕ)=∇ϕEqϕ[logpθ(x(i),z)−logqϕ]=∇ϕ∫[logpθ(x(i),z)−logqϕ]qϕdz=∇ϕ∫[logpθ(x(i),z)−logqϕ]p(ϵ)dϵ=∇ϕEp(ϵ)[logpθ(x(i),z)−logqϕ]=Ep(ϵ)∇ϕ[(logpθ(x(i),z)−logqϕ)]=Ep(ϵ)∇z[(logpθ(x(i),z)−logqϕ(z∣x(i)))∇ϕz]=Ep(ϵ)∇z[(logpθ(x(i),z)−logqϕ(z∣x(i)))∇ϕz]=Ep(ϵ)∇z[(logpθ(x(i),z)−logqϕ(z∣x(i)))∇ϕgϕ(ϵ,x(i))]那么我们的问题就这样愉快的解决了, p ( ϵ ) p(\epsilon) p(ϵ) 的采样与 ϕ \phi ϕ 无关,然后对先求关于 z z z 的梯度,然后再求关于 ϕ \phi ϕ 的梯度,那么这三者之间就互相隔离开了。最后,我们再对结果进行采样, l = ϵ ( l ) ∼ p ( ϵ ) , l = \epsilon^{(l)} \sim p(\epsilon), \quad l=ϵ(l)∼p(ϵ),, 1 , 2 , ⋯ , L : 1,2, \cdots, L: 1,2,⋯,L:
∇ ϕ L ( ϕ ) ≈ 1 L ∑ i = 1 L ∇ z [ ( log p θ ( x ( i ) , z ) − log q ϕ ( z ∣ x ( i ) ) ) ∇ ϕ g ϕ ( ϵ , x ( i ) ) ] \nabla_{\phi} \mathcal{L}(\phi) \approx \frac{1}{L} \sum_{i=1}^{L} \nabla_{z}\left[\left(\log p_{\theta}\left(x^{(i)}, z\right)-\log q_{\phi}\left(z | x^{(i)}\right)\right) \nabla_{\phi} g_{\phi}\left(\epsilon, x^{(i)}\right)\right] ∇ϕL(ϕ)≈L1i=1∑L∇z[(logpθ(x(i),z)−logqϕ(z∣x(i)))∇ϕgϕ(ϵ,x(i))]其中 z ⟵ g ϕ ( ϵ ( i ) , x ( i ) ) z \longleftarrow g_{\phi}\left(\epsilon^{(i)}, x^{(i)}\right) z⟵gϕ(ϵ(i),x(i))。而 S G V I \mathrm{SGVI} SGVI 为:
ϕ ( t + 1 ) ⟶ ϕ ( t ) + λ ( t ) ∇ ϕ L ( ϕ ) \phi^{(t+1)} \longrightarrow \phi^{(t)}+\lambda^{(t)} \nabla_{\phi} \mathcal{L}(\phi) ϕ(t+1)⟶ϕ(t)+λ(t)∇ϕL(ϕ)
4.4 小结
那么SGVI,可以简要的表述为:我们定义分布为 q ϕ ( Z j X ) q_ϕ(ZjX) qϕ(ZjX), ϕ ϕ ϕ 为参数,参数的更新方法为: ϕ ( t + 1 ) ⟶ ϕ ( t ) + λ ( t ) ∇ ϕ L ( ϕ ) \phi^{(t+1)} \longrightarrow \phi^{(t)}+\lambda^{(t)} \nabla_{\phi} \mathcal{L}(\phi) ϕ(t+1)⟶ϕ(t)+λ(t)∇ϕL(ϕ) ∇ ϕ L ( ϕ ) \nabla_{\phi} \mathcal{L}(\phi) ∇ϕL(ϕ) 为:
∇ ϕ L ( ϕ ) ≈ 1 L ∑ i = 1 L ∇ z [ log p θ ( x ( i ) , z ) − log q ϕ ( z ∣ x ( i ) ) ) ∇ ϕ g ϕ ( ϵ , x ( i ) ) \nabla_{\phi} \mathcal{L}(\phi) \approx \frac{1}{L} \sum_{i=1}^{L} \nabla_{z}\left[\log p_{\theta}\left(x^{(i)}, z\right)-\log q_{\phi}\left(z | x^{(i)}\right)\right) \nabla_{\phi} g_{\phi}\left(\epsilon, x^{(i)}\right) ∇ϕL(ϕ)≈L1i=1∑L∇z[logpθ(x(i),z)−logqϕ(z∣x(i)))∇ϕgϕ(ϵ,x(i))
版权声明:本文为CSDN博主「AI路上的小白」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/cengjing12/article/details/106574869