基于WordNet的英文同义词、近义词相似度评估及代码实现
1.确定要解决的问题及意义
在基于代码片段的分类过程中,由于程序员对数据变量名的选取可能具有一定的规范性,在某一特定业务处理逻辑代码中,可能多个变量名之间具有关联性或相似性(如“trade”(商品交易)类中,可能存在“business”,“transaction”,“deal”等同义词),在某些情况下,它们以不同的词语表达了相同的含义。因此,为了能够对代码片段做出更加科学的类别判断,更好地识别这些同义词,我们有必要寻找一种能够解决避免由于同义词的存在而导致误分类的方法。说白了,就是要去判断词语之间的相似度(即确定是否为近义词),并找出代码段中出现次数最多的一组语义。
2.要达到的效果
即在给定的代码段中,能够发现哪些词是属于同义词,并且能够实现分类。
Eg.public static void function(){
String trade=”money”;
Int deal=5;
Long long business=0xfffffff;
Boolen transaction=TRUE;
……
}
Output:同义词有:trade,deal,business,transaction
这段代码很可能与trade有关
3.初识WordNet
问题确定了之后,通过网上的搜索,发现了WordNet和word2vec这两个相关的词汇。(后知后觉,这本身就是一个找近义词的过程)
3.1 WordNet是什么
首先,来看WordNet。搜了一下相关介绍:
WordNet是一个由普林斯顿大学认识科学实验室在心理学教授乔治·A·米勒的指导下建立和维护的英语字典。开发工作从1985年开始,从此以后该项目接受了超过300万美元的资助(主要来源于对机器翻译有兴趣的政府机构)。
由于它包含了语义信息,所以有别于通常意义上的字典。WordNet根据词条的意义将它们分组,每一个具有相同意义的字条组称为一个synset(同义词集合)。WordNet为每一个synset提供了简短,概要的定义,并记录不同synset之间的语义关系。
WordNet的开发有两个目的:
它既是一个字典,又是一个辞典,它比单纯的辞典或词典都更加易于使用。
支持自动的文本分析以及人工智能应用。
WordNet内部结构
在WordNet中,名词,动词,形容词和副词各自被组织成一个同义词的网络,每个同义词集合都代表一个基本的语义概念,并且这些集合之间也由各种关系连接。(一个多义词将出现在它的每个意思的同义词集合中)。在WordNet的第一版中(标记为1.x),四种不同词性的网络之间并无连接。WordNet的名词网络是第一个发展起来的。
名词网络的主干是蕴涵关系的层次(上位/下位关系),它占据了关系中的将近80%。层次中的最顶层是11个抽象概念,称为基本类别始点(unique beginners),例如实体(entity,“有生命的或无生命的具体存在”),心理特征(psychological feature,“生命有机体的精神上的特征)。名词层次中最深的层次是16个节点。
(wikipedia)
通俗地来说,WordNet是一个结构化很好的知识库,它不但包括一般的词典功能,另外还有词的分类信息。目前,基于WordNet的方法相对来说比较成熟,比如路径方法 (lch)、基于信息论方法(res)等。(详见参考文献)
3.2 WordNet的安装与配置
有了WordNet ,也就等于是有了我们所要的单词库。所以,暂时先不考虑相似度的计算,把WordNet下载下来再说。
参考http://hi.baidu.com/buptyoyo/item/f13dfe463c061e3afb896028。顺利地下载,安装以及跑demo。
之后,一起来看一下WordNet的文件结构:

bin目录下,有可执行文件WordNet 2.1.exe:
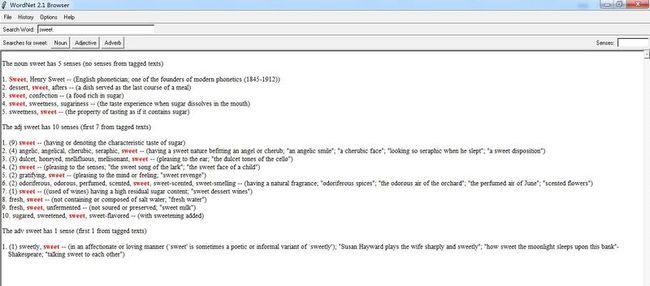

可以看到,WordNet对所有的英文单词都进行的分类,并且形成了一棵语义树。在本例中,entity——>abstract entity——>abstraction——>attribute——>state——>feeling——> emotion——>love;
从叶子节点到根节点
WordNet名次分类中的25个基本类:
dict目录里面存放的就是资源库了,可以看到,它以形容词,副词,名词,动词来分类:
doc为WordNet的用户手册文件文件夹
lib为WordNet软件使用Windows资源的函数库
src为源码文件夹
4.解决问题的大致思路
我们首先以 WordNet 的词汇语义分类作为基础,抽取出其中的同义词,然后采用基于向量空间的方法计算出相似度。工作流程如下:

5.基于WordNet的相似度计算
以下摘自:《基于WordNet的英语词语相似度计算》
5.1 特征提取

5.2 意义相似度和词语相似度的计算



6.实现效果
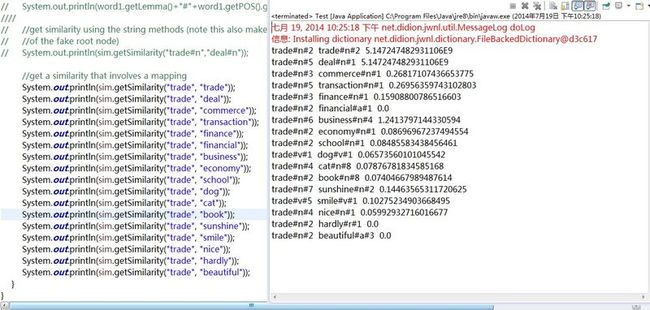
与“trade”的相似度比较:
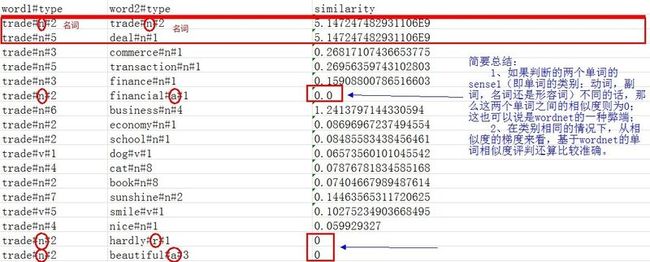 分析:
分析:
先看第一组:trade vs trade
自己和自己当然是相似度100%
再看第二组:trade#n#5 vs deal#n#1
相似度竟然和第一组是一样的!根据结果,trade作为名词时,它的第5种含义和deal作为名词时的第1种含义是完全相似的。让我们去库里看个究竟:
trade#n#5:

deal#n#1:
再来看一组不是很好理解的:
trade#n#7 vs deal#n#2
他们的相似度达到了0.14+,算是比较高的了,这是为什么呢?
trade#n#7:

sunshine#n#2:

相信聪明的你一定明白了为什么。
与“cat”的相似度比较:

7.代码分析
工程结构图:
test.java
1 package JWordNetSim.test; 2 3 import java.io.FileInputStream; 4 import java.util.HashMap; 5 import java.util.Map; 6 7 import net.didion.jwnl.JWNL; 8 import net.didion.jwnl.data.IndexWord; 9 import net.didion.jwnl.data.POS; 10 import net.didion.jwnl.dictionary.Dictionary; 11 import shef.nlp.wordnet.similarity.SimilarityMeasure; 12 13 /** 14 * A simple test of this WordNet similarity library. 15 * @author Mark A. Greenwood 16 */ 17 public class Test 18 { 19 public static void main(String[] args) throws Exception 20 { 21 //在运行代码前,必须在本机上安装wordnet2.0,只能装2.0,装了2.1会出错 22 JWNL.initialize(new FileInputStream("D:\\JAVAProjectWorkSpace\\jwnl\\JWordNetSim\\test\\wordnet.xml")); 23 24 //建议一个映射去配置相关参数 25 Map<String,String> params = new HashMap<String,String>(); 26 27 //the simType parameter is the class name of the measure to use 28 params.put("simType","shef.nlp.wordnet.similarity.JCn"); 29 30 //this param should be the URL to an infocontent file (if required 31 //by the similarity measure being loaded) 32 params.put("infocontent","file:D:\\JAVAProjectWorkSpace\\jwnl\\JWordNetSim\\test\\ic-bnc-resnik-add1.dat"); 33 34 //this param should be the URL to a mapping file if the 35 //user needs to make synset mappings 36 params.put("mapping","file:D:\\JAVAProjectWorkSpace\\jwnl\\JWordNetSim\\test\\domain_independent.txt"); 37 38 //create the similarity measure 39 SimilarityMeasure sim = SimilarityMeasure.newInstance(params); 40 41 //取词 42 // Dictionary dict = Dictionary.getInstance(); 43 // IndexWord word1 = dict.getIndexWord(POS.NOUN, "trade"); //这里把trade和dog完全定义为名词来进行处理 44 // IndexWord word2 = dict.getIndexWord(POS.NOUN,"dog"); // 45 // 46 // //and get the similarity between the first senses of each word 47 // System.out.println(word1.getLemma()+"#"+word1.getPOS().getKey()+"#1 " + word2.getLemma()+"#"+word2.getPOS().getKey()+"#1 " + sim.getSimilarity(word1.getSense(1), word2.getSense(1))); 48 //// 49 // //get similarity using the string methods (note this also makes use 50 // //of the fake root node) 51 // System.out.println(sim.getSimilarity("trade#n","deal#n")); 52 53 //get a similarity that involves a mapping 54 System.out.println(sim.getSimilarity("trade", "trade")); 55 System.out.println(sim.getSimilarity("trade", "deal")); 56 System.out.println(sim.getSimilarity("trade", "commerce")); 57 System.out.println(sim.getSimilarity("trade", "transaction")); 58 System.out.println(sim.getSimilarity("trade", "finance")); 59 System.out.println(sim.getSimilarity("trade", "financial")); 60 System.out.println(sim.getSimilarity("trade", "business")); 61 System.out.println(sim.getSimilarity("trade", "economy")); 62 System.out.println(sim.getSimilarity("trade", "school")); 63 System.out.println(sim.getSimilarity("trade", "dog")); 64 System.out.println(sim.getSimilarity("trade", "cat")); 65 System.out.println(sim.getSimilarity("trade", "book")); 66 System.out.println(sim.getSimilarity("trade", "sunshine")); 67 System.out.println(sim.getSimilarity("trade", "smile")); 68 System.out.println(sim.getSimilarity("trade", "nice")); 69 System.out.println(sim.getSimilarity("trade", "hardly")); 70 System.out.println(sim.getSimilarity("trade", "beautiful")); 71 } 72 }
SimilarityMeasure.java
1 package shef.nlp.wordnet.similarity; 2 3 import java.io.BufferedReader; 4 import java.io.InputStreamReader; 5 import java.net.URL; 6 import java.util.Arrays; 7 import java.util.HashMap; 8 import java.util.HashSet; 9 import java.util.LinkedHashMap; 10 import java.util.Map; 11 import java.util.Set; 12 13 import net.didion.jwnl.JWNLException; 14 import net.didion.jwnl.data.IndexWord; 15 import net.didion.jwnl.data.POS; 16 import net.didion.jwnl.data.Synset; 17 import net.didion.jwnl.dictionary.Dictionary; 18 19 /** 20 * An abstract notion of a similarity measure that all provided 21 * implementations extend. 22 * @author Mark A. Greenwood 23 */ 24 public abstract class SimilarityMeasure 25 { 26 /** 27 * A mapping of terms to specific synsets. Usually used to map domain 28 * terms to a restricted set of synsets but can also be used to map 29 * named entity tags to appropriate synsets. 30 */ 31 private Map<String,Set<Synset>> domainMappings = new HashMap<String,Set<Synset>>(); 32 33 /** 34 * The maximum size the cache can grow to 35 */ 36 private int cacheSize = 5000; 37 38 /** 39 * To speed up computation of the similarity between two synsets 40 * we cache each similarity that is computed so we only have to 41 * do each one once. 42 */ 43 private Map<String,Double> cache = new LinkedHashMap<String,Double>(16,0.75f,true) 44 { 45 public boolean removeEldestEntry(Map.Entry<String,Double> eldest) 46 { 47 //if the size is less than zero then the user is asking us 48 //not to limit the size of the cache so return false 49 if (cacheSize < 0) return false; 50 51 //if the cache has crown bigger than it's max size return true 52 return size() > cacheSize; 53 } 54 }; 55 56 /** 57 * Get a previously computed similarity between two synsets from the cache. 58 * @param s1 the first synset between which we are looking for the similarity. 59 * @param s2 the other synset between which we are looking for the similarity. 60 * @return The similarity between the two sets or null 61 * if it is not in the cache. 62 */ 63 protected final Double getFromCache(Synset s1, Synset s2) 64 { 65 return cache.get(s1.getKey()+"-"+s2.getKey()); 66 } 67 68 /** 69 * Add a computed similarity between two synsets to the cache so that 70 * we don't have to compute it if it is needed in the future. 71 * @param s1 one of the synsets between which we are storring a similarity. 72 * @param s2 the other synset between which we are storring a similarity. 73 * @param sim the similarity between the two supplied synsets. 74 * @return the similarity score just added to the cache. 75 */ 76 protected final double addToCache(Synset s1, Synset s2, double sim) 77 { 78 cache.put(s1.getKey()+"-"+s2.getKey(),sim); 79 80 return sim; 81 } 82 83 /** 84 * Configures the similarity measure using the supplied parameters. 85 * @param params a set of key-value pairs that are used to configure 86 * the similarity measure. See concrete implementations for details 87 * of expected/possible parameters. 88 * @throws Exception if an error occurs while configuring the similarity measure. 89 */ 90 protected abstract void config(Map<String,String> params) throws Exception; 91 92 /** 93 * Create a new instance of a similarity measure. 94 * @param confURL the URL of a configuration file. Parameters are specified 95 * one per line as key:value pairs. 96 * @return a new instance of a similairy measure as defined by the 97 * supplied configuration URL. 98 * @throws Exception if an error occurs while creating the similarity measure. 99 */ 100 public static SimilarityMeasure newInstance(URL confURL) throws Exception 101 { 102 //create map to hold the key-value pairs we are going to read from 103 //the configuration file 104 Map<String,String> params = new HashMap<String,String>(); 105 106 //create a reader for the config file 107 BufferedReader in = null; 108 109 try 110 { 111 //open the config file 112 in = new BufferedReader(new InputStreamReader(confURL.openStream())); 113 114 String line = in.readLine(); 115 while (line != null) 116 { 117 line = line.trim(); 118 119 if (!line.equals("")) 120 { 121 //if the line contains something then 122 123 //split the data so we get the key and value 124 String[] data = line.split("\\s*:\\s*",2); 125 126 if (data.length == 2) 127 { 128 //if the line is valid add the two parts to the map 129 params.put(data[0], data[1]); 130 } 131 else 132 { 133 //if the line isn't valid tell the user but continue on 134 //with the rest of the file 135 System.out.println("Config Line is Malformed: " + line); 136 } 137 } 138 139 //get the next line ready to process 140 line = in.readLine(); 141 } 142 } 143 finally 144 { 145 //close the config file if it got opened 146 if (in != null) in.close(); 147 } 148 149 //create and return a new instance of the similarity measure specified 150 //by the config file 151 return newInstance(params); 152 } 153 154 /** 155 * Creates a new instance of a similarity measure using the supplied parameters. 156 * @param params a set of key-value pairs which define the similarity measure. 157 * @return the newly created similarity measure. 158 * @throws Exception if an error occurs while creating the similarity measure. 159 */ 160 public static SimilarityMeasure newInstance(Map<String,String> params) throws Exception 161 { 162 //get the class name of the implementation we need to load 163 String name = params.remove("simType"); 164 165 //if the name hasn't been specified then throw an exception 166 if (name == null) throw new Exception("Must specifiy the similarity measure to use"); 167 168 //Get hold of the class we need to load 169 @SuppressWarnings("unchecked") Class<SimilarityMeasure> c = (Class<SimilarityMeasure>)Class.forName(name); 170 171 //create a new instance of the similarity measure 172 SimilarityMeasure sim = c.newInstance(); 173 174 //get the cache parameter from the config params 175 String cSize = params.remove("cache"); 176 177 //if a cache size was specified then set it 178 if (cSize != null) sim.cacheSize = Integer.parseInt(cSize); 179 180 //get the url of the domain mapping file 181 String mapURL = params.remove("mapping"); 182 183 if (mapURL != null) 184 { 185 //if a mapping file has been provided then 186 187 //open a reader over the file 188 BufferedReader in = new BufferedReader(new InputStreamReader((new URL(mapURL)).openStream())); 189 190 //get the first line ready for processing 191 String line = in.readLine(); 192 193 while (line != null) 194 { 195 if (!line.startsWith("#")) 196 { 197 //if the line isn't a comment (i.e. it doesn't start with #) then... 198 199 //split the line at the white space 200 String[] data = line.trim().split("\\s+"); 201 202 //create a new set to hold the mapped synsets 203 Set<Synset> mappedTo = new HashSet<Synset>(); 204 205 for (int i = 1 ; i < data.length ; ++i) 206 { 207 //for each synset mapped to get the actual Synsets 208 //and store them in the set 209 mappedTo.addAll(sim.getSynsets(data[i])); 210 } 211 212 //if we have found some actual synsets then 213 //store them in the domain mappings 214 if (mappedTo.size() > 0) sim.domainMappings.put(data[0], mappedTo); 215 } 216 217 //get the next line from the file 218 line = in.readLine(); 219 } 220 221 //we have finished with the mappings file so close it 222 in.close(); 223 } 224 225 //make sure it is configured properly 226 sim.config(params); 227 228 //then return it 229 return sim; 230 } 231 232 /** 233 * This is the method responsible for computing the similarity between two 234 * specific synsets. The method is implemented differently for each 235 * similarity measure so see the subclasses for detailed information. 236 * @param s1 one of the synsets between which we want to know the similarity. 237 * @param s2 the other synset between which we want to know the similarity. 238 * @return the similarity between the two synsets. 239 * @throws JWNLException if an error occurs accessing WordNet. 240 */ 241 public abstract double getSimilarity(Synset s1, Synset s2) throws JWNLException; 242 243 /** 244 * Get the similarity between two words. The words can be specified either 245 * as just the word or in an encoded form including the POS tag and possibly 246 * the sense number, i.e. cat#n#1 would specifiy the 1st sense of the noun cat. 247 * @param w1 one of the words to compute similarity between. 248 * @param w2 the other word to compute similarity between. 249 * @return a SimilarityInfo instance detailing the similarity between the 250 * two words specified. 251 * @throws JWNLException if an error occurs accessing WordNet. 252 */ 253 public final SimilarityInfo getSimilarity(String w1, String w2) throws JWNLException 254 { 255 //Get the (possibly) multiple synsets associated with each word 256 Set<Synset> ss1 = getSynsets(w1); 257 Set<Synset> ss2 = getSynsets(w2); 258 259 //assume the words are not at all similar 260 SimilarityInfo sim = null; 261 262 for (Synset s1 : ss1) 263 { 264 for (Synset s2 : ss2) 265 { 266 //for each pair of synsets get the similarity 267 double score = getSimilarity(s1, s2); 268 269 if (sim == null || score > sim.getSimilarity()) 270 { 271 //if the similarity is better than we have seen before 272 //then create and store an info object describing the 273 //similarity between the two synsets 274 sim = new SimilarityInfo(w1, s1, w2, s2, score); 275 } 276 } 277 } 278 279 //return the maximum similarity we have found 280 return sim; 281 } 282 283 /** 284 * Finds all the synsets associated with a specific word. 285 * @param word the word we are interested. Note that this may be encoded 286 * to include information on POS tag and sense index. 287 * @return a set of synsets that are associated with the supplied word 288 * @throws JWNLException if an error occurs accessing WordNet 289 */ 290 private final Set<Synset> getSynsets(String word) throws JWNLException 291 { 292 //get a handle on the WordNet dictionary 293 Dictionary dict = Dictionary.getInstance(); 294 295 //create an emptuy set to hold any synsets we find 296 Set<Synset> synsets = new HashSet<Synset>(); 297 298 //split the word on the # characters so we can get at the 299 //upto three componets that could be present: word, POS tag, sense index 300 String[] data = word.split("#"); 301 302 //if the word is in the domainMappings then simply return the mappings 303 if (domainMappings.containsKey(data[0])) return domainMappings.get(data[0]); 304 305 if (data.length == 1) 306 { 307 //if there is just the word 308 309 for (IndexWord iw : dict.lookupAllIndexWords(data[0]).getIndexWordArray()) 310 { 311 //for each matching word in WordNet add all it's senses to 312 //the set we are building up 313 synsets.addAll(Arrays.asList(iw.getSenses())); 314 } 315 316 //we have finihsed so return the synsets we found 317 return synsets; 318 } 319 320 //the calling method specified a POS tag as well so get that 321 POS pos = POS.getPOSForKey(data[1]); 322 323 //if the POS tag isn't valid throw an exception 324 if (pos == null) throw new JWNLException("Invalid POS Tag: " + data[1]); 325 326 //get the word with the specified POS tag from WordNet 327 IndexWord iw = dict.getIndexWord(pos, data[0]); 328 329 if (data.length > 2) 330 { 331 //if the calling method specified a sense index then 332 //add just that sysnet to the set we are creating 333 synsets.add(iw.getSense(Integer.parseInt(data[2]))); 334 } 335 else 336 { 337 //no sense index was specified so add all the senses of 338 //the word to the set we are creating 339 synsets.addAll(Arrays.asList(iw.getSenses())); 340 } 341 342 //return the set of synsets we found for the specified word 343 return synsets; 344 } 345 }
每个函数都有详细注解,大家应该都看的明白。
262~277的循环过程如下:
JCN.java
1 /************************************************************************ 2 * Copyright (C) 2006-2007 The University of Sheffield * 3 * Developed by Mark A. Greenwood <[email protected]> * 4 * * 5 * This program is free software; you can redistribute it and/or modify * 6 * it under the terms of the GNU General Public License as published by * 7 * the Free Software Foundation; either version 2 of the License, or * 8 * (at your option) any later version. * 9 * * 10 * This program is distributed in the hope that it will be useful, * 11 * but WITHOUT ANY WARRANTY; without even the implied warranty of * 12 * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the * 13 * GNU General Public License for more details. * 14 * * 15 * You should have received a copy of the GNU General Public License * 16 * along with this program; if not, write to the Free Software * 17 * Foundation, Inc., 675 Mass Ave, Cambridge, MA 02139, USA. * 18 ************************************************************************/ 19 20 package shef.nlp.wordnet.similarity; 21 22 import net.didion.jwnl.JWNLException; 23 import net.didion.jwnl.data.Synset; 24 25 /** 26 * An implementation of the WordNet similarity measure developed by Jiang and 27 * Conrath. For full details of the measure see: 28 * <blockquote>Jiang J. and Conrath D. 1997. Semantic similarity based on corpus 29 * statistics and lexical taxonomy. In Proceedings of International 30 * Conference on Research in Computational Linguistics, Taiwan.</blockquote> 31 * @author Mark A. Greenwood 32 */ 33 public class JCn extends ICMeasure 34 { 35 /** 36 * Instances of this similarity measure should be generated using the 37 * factory methods of {@link SimilarityMeasure}. 38 */ 39 protected JCn() 40 { 41 //A protected constructor to force the use of the newInstance method 42 } 43 44 @Override public double getSimilarity(Synset s1, Synset s2) throws JWNLException 45 { 46 //if the POS tags are not the same then return 0 as this measure 47 //only works with 2 nouns or 2 verbs. 48 if (!s1.getPOS().equals(s2.getPOS())) return 0; 49 50 //see if the similarity is already cached and... 51 Double cached = getFromCache(s1, s2); 52 53 //if it is then simply return it 54 if (cached != null) return cached.doubleValue(); 55 56 //Get the Information Content (IC) values for the two supplied synsets 57 double ic1 = getIC(s1); 58 double ic2 = getIC(s2); 59 60 //if either IC value is zero then cache and return a sim of 0 61 if (ic1 == 0 || ic2 == 0) return addToCache(s1,s2,0); 62 63 //Get the Lowest Common Subsumer (LCS) of the two synsets 64 Synset lcs = getLCSbyIC(s1,s2); 65 66 //if there isn't an LCS then cache and return a sim of 0 67 if (lcs == null) return addToCache(s1,s2,0); 68 69 //get the IC valueof the LCS 70 double icLCS = getIC(lcs); 71 72 //compute the distance between the two synsets 73 //NOTE: This is the original JCN measure 74 double distance = ic1 + ic2 - (2 * icLCS); 75 76 //assume the similarity between the synsets is 0 77 double sim = 0; 78 79 if (distance == 0) 80 { 81 //if the distance is 0 (i.e. ic1 + ic2 = 2 * icLCS) then... 82 83 //get the root frequency for this POS tag 84 double rootFreq = getFrequency(s1.getPOS()); 85 86 if (rootFreq > 0.01) 87 { 88 //if the root frequency has a value then use it to generate a 89 //very large sim value 90 sim = 1/-Math.log((rootFreq - 0.01) / rootFreq); 91 } 92 } 93 else 94 { 95 //this is the normal case so just convert the distance 96 //to a similarity by taking the multiplicative inverse 97 sim = 1/distance; 98 } 99 100 //cache and return the calculated similarity 101 return addToCache(s1,s2,sim); 102 } 103 }
LIN.java
1 package shef.nlp.wordnet.similarity; 2 3 import net.didion.jwnl.JWNLException; 4 import net.didion.jwnl.data.Synset; 5 6 /** 7 * An implementation of the WordNet similarity measure developed by Lin. For 8 * full details of the measure see: 9 * <blockquote>Lin D. 1998. An information-theoretic definition of similarity. In 10 * Proceedings of the 15th International Conference on Machine 11 * Learning, Madison, WI.</blockquote> 12 * @author Mark A. Greenwood 13 */ 14 public class Lin extends ICMeasure 15 { 16 /** 17 * Instances of this similarity measure should be generated using the 18 * factory methods of {@link SimilarityMeasure}. 19 */ 20 protected Lin() 21 { 22 //A protected constructor to force the use of the newInstance method 23 } 24 25 @Override public double getSimilarity(Synset s1, Synset s2) throws JWNLException 26 { 27 //if the POS tags are not the same then return 0 as this measure 28 //only works with 2 nouns or 2 verbs. 29 if (!s1.getPOS().equals(s2.getPOS())) return 0; 30 31 //see if the similarity is already cached and... 32 Double cached = getFromCache(s1, s2); 33 34 //if it is then simply return it 35 if (cached != null) return cached.doubleValue(); 36 37 //Get the Information Content (IC) values for the two supplied synsets 38 double ic1 = getIC(s1); 39 double ic2 = getIC(s2); 40 41 //if either IC value is zero then cache and return a sim of 0 42 if (ic1 == 0 || ic2 == 0) return addToCache(s1,s2,0); 43 44 //Get the Lowest Common Subsumer (LCS) of the two synsets 45 Synset lcs = getLCSbyIC(s1,s2); 46 47 //if there isn't an LCS then cache and return a sim of 0 48 if (lcs == null) return addToCache(s1,s2,0); 49 50 //get the IC valueof the LCS 51 double icLCS = getIC(lcs); 52 53 //caluclaue the similarity score 54 double sim = (2*icLCS)/(ic1+ic2); 55 56 //cache and return the calculated similarity 57 return addToCache(s1,s2,sim); 58 } 59 }
参考文献:
《基于维基百科的语义相似度计算》盛志超,陶晓鹏(复旦大学计算机科学技术学院);
《基于WordNet的英语词语相似度计算》颜伟,荀恩东(北京语言大学 语言信息处理研究所)
WordNet中的名词:http://ccl.pku.edu.cn/doubtfire/semantics/wordnet/c-wordnet/nouns-in-wordnet.htm
MIT的JWI(Java WordNet Interface)和JWNL(Java WordNet Library)比较
http://jxr19830617.blog.163.com/blog/static/163573067201301985219857/
http://jxr19830617.blog.163.com/blog/static/1635730672013019105255295/