Learning Temporal Consistency for Low Light Video Enhancement from Single Images
Learning Temporal Consistency for Low Light Video Enhancement from Single Images
- 论文链接:CVPR链接
- 期刊/会议:CVPR 2021
- 是否有code: Code
关键词
暗光视频增强,解问题,”半监督“;
问题简述
Motiviation
笔者认为,这篇文章属于”解问题“的范畴。作者认为,暗光视频增强这个任务最难的地方在于质量较好的训练视频对(暗光视频和对应的亮光视频)太难以获取了。因此,本文所提出的方法,其最大亮点就在于可以不使用视频作为训练数据,仅用单帧图对作为训练数据来训练出几乎没有帧间闪烁(flicker)问题的视频增强方法。
Abstract
从本文的motiviation入手,本文的核心放在以下两点:
- 单帧图像对中没有动态场景,那么缺失的运动信息该怎么弥补回来;
- 单帧模型在处理视频时,往往出现十分严重的闪烁问题,本文所提出的方法该如何避免;
针对第一点,作者给出的答案是利用光流来模拟运动信息,使得单帧图像”动“起来。不过值得注意的是,这里提到的光流模型不能计算多帧之间的差异,只能依赖单帧图像来进行预测。
针对第二点问题,作者使用了consistency-loss来约束网络的训练过程,缓解帧间闪烁问题。不过在光流的帮助下,作者能用更加”科学“地使用consistency-loss。
两个核心问题下面会更加详细的说明,先来看看本文的流程框图,化的还是非常的清晰易懂的:

可以看到,在训练和测试阶段,为了搭配consistency-loss,本文使用了简单的Siamese网络架构。同时,这样简单的结构也能保证本文所提出的方法的实时性。
方法介绍
Instance Aware Optical Flow
只依赖单帧图像能预测光流吗?答案是可以!其实已经有一些工作开始聚焦于只依赖单张图片来预测未来的运动信息,而光流作为一种代表运动信息的方式,自然也会有单帧出光流的方法。CVPR2019年提出的自监督光流预测方法(Conditional Motion Propagation, arxiv地址)就是这样一种方法。从CMP的demo可以看出来,输入一张静态的图片,再加上对图像中的前景物体的“运动指令”,CMP就能自动预测出该前景物体接下来的运动信息(光流)。
在本文中,对于输入的静态图片,作者先使用一个在COCO上预训练好的FPN网络(调用了Detectron2工具箱,Backbone是ResNet50)做前景分割,然后保留所有置信度高于85%的物体区域。有了“待运动”的物体,作者生成“运动指令”的方式也非常暴力:每个待运动物体都随机生成10个guidance motion vector。将直接调用CMP,生成光流信息,然后再将原图根据光流进行Warp,得到临近帧,完成数据的增广。作者发现,只要这样生成的光流,与真实的光流信息非常接近,参考下面的对比:

回看图1中的Siamese训练过程,输入和真值 x 2 , y 2 x_2,y_2 x2,y2就是原始数据 x 1 , y 1 x_1,y_1 x1,y1根据光流信息进行Warp得到的。
需要注意的一点是,前面说到“运动指令”的生成方式是随机的,那会不会产生非常不科学的Warp结果呢?作者在文章中大大方方承认了,但同时也表示:“即使Warp失败的case,作者认为对于训练依然是益的”。
得到光流信息之后如何进行Warp的细节待补充
Consistency Loss
之前就有一些工作利用consistency-loss来缓解帧间闪烁问题(文献1,文献2),其用法与本文所使用的方法基本一致。本文所使用的consistency-loss公式如下:
L c = ∣ ∣ W ( g ( x 1 ) , f ) − g ( x 2 ) ∣ ∣ \mathit{L}_c =||W(g(x_1),f)-g(x_2)|| Lc=∣∣W(g(x1),f)−g(x2)∣∣
式中的 x 2 x_2 x2就是 x 1 x_1 x1根据某些“变换”得到的, g ( x ) g(x) g(x)代表将 x x x送入CNN得到的输出, f f f是光流信息, W W W代表Warp变换。而之前的文献的做法,没有使用 f f f, 而 W W W也往往是简单的翻转、平移等操作。作者认为本文这样的使用方法更加多样化,也更加合理。
最终总loss是L1重建loss L e \mathit{L}_e Le( x 1 , y 1 x_1,y_1 x1,y1与 x 2 , y 2 x_2,y_2 x2,y2两对重建loss,比较常规,在此就不单独介绍了)与consistency-loss L c \mathit{L}_c Lc的加权求和:
L = L e + λ L c \mathit{L}=\mathit{L}_e+\lambda\mathit{L}_c L=Le+λLc
实验结果
评价指标
本文所使用的评价指标分成两类:
- 评价单帧图像质量的指标:PSNR和SSIM;
- 评价视频Temporal-Consistency的指标:AB(var)(Average Brightness(Variance),出自BMVC2018的MBLLEN),MABD(Mean Absolute Brightness Difference,出自ICCV2019的Learning to See Moving Objects in the Dark) 和 WE(Warping Error,出自ECCV2018的Learning Blind Video Temporal Consistency);
PSNR和SSIM大家都比较熟悉,在此就不赘述了。在这分别介绍一下三个评价Temporal-Consistency的指标:
AB(var)
MBLLEN的作者,为了评估MBLLEN的视频版MBLLVEN的temporal-consistency,在Average Brightness的基础上,提出了AB(var),其原文是这么写的:
We also introduce the AB(var) metric to measure the difference of the average brightness variance between the enhanced video and the ground truth. This metric reflects whether the video has unexpected brightness changes or flickers.
从这句话中可以看出,AB(var)的计算方式应该就是先计算增强后的视频与原始视频每帧图像的AB值差异,然后所有帧的AB值差异在求取一个方差,方差越小,则可以侧面说明算法生成的结果帧间一致性越好。
MABD
在《Learning to See Moving Objects in the Dark》这篇文章中,作者将MABD定义如下:

可以看出来,对于一个视频来说,MABD可以近似地堪称对时间(帧)的导数,其计算结果应该是一条如下图所示的曲线:

但是MABD的提出者觉得曲线并不好进行量化的比较,于是直接对增强后视频和原始视频的MABD"向量"计算了MSE,将曲线之间的比较转化为了标量之间的比较(越小越好),方便进行量化比较。
WE
在《Learning Blind Video Temporal Consistency》这篇文章中,作者将Warping Error定义如下:

这里面有两个点需要说明一下:
- 上标 ( i ) ^{(i)} (i)代表像素点的位置,相当于遍历一张图的所有像素;
- 为什么要有代表非遮挡位置的掩码的 M M M呢?是因为在《Learning Blind Video Temporal Consistency》这篇文章中,光流信息使用FlowNetv2生成的,而遮挡会严重影响生成光流的质量,因此需要有这个掩码。但是对于本文来说,笔者觉得应该不需要这个掩码。
对比实验
实验的对比部分主要分为三个部分:
- 在合成数据的无噪数据上进行定量/定性对比;
- 在合成数据的带噪数据(高斯+泊松)上进行定量/定性对比;
- 在真实的暗光视频上(No References),进行定性对比;
如何进行数据的合成呢?作者从视频数据集DAVIS中挑选出相对比较暗的那些视频,然后在一起用linear+gramma调暗这些视频中的每帧,来生成暗光视频:
x = β × ( α × y ) γ x = \beta \times (\alpha \times y)^{\gamma} x=β×(α×y)γ
式中的超参数 γ ∼ U ( 2 , 3.5 ) \gamma \sim U(2,3.5) γ∼U(2,3.5), α ∼ U ( 0.9 , 1 ) \alpha \sim U(0.9,1) α∼U(0.9,1), β ∼ U ( 0.5 , 1 ) \beta \sim U(0.5,1) β∼U(0.5,1).
对比实验比较常规,简单看看结果就好:




烧蚀实验
本文的烧蚀实验只做了:
- 探索重建loss和一致性loss之间的权重 λ \lambda λ值的变化的影响;
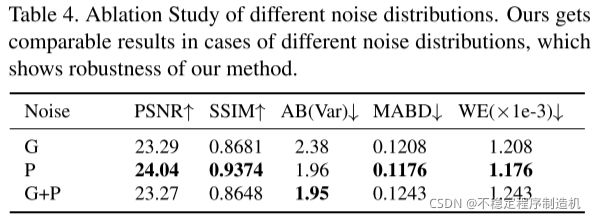
- 合成的不同噪声种类对于最终结果的影响;
也算是比较常规,看看结果就好:

User Study

总结
这篇paper解决的问题非常有意义,虽然使用的方法创新性相对不是很突出,不过仍不失为一篇很值得了解的paper;
优点:
- 提出了一种只依赖单帧图像对作为训练数据的视频增强方法,同时设计了配套的解决方案,大幅度缓解了帧间闪烁的问题;
- 对于网络结构基本没有要求,有高实时性的潜力;
缺点:
- Instance Aware Optical Flow以及Consistency Loss这两个核心部分都是直接调用现成算法或者微创新的结果,创新型相对没有特别突出。
参考文献
本文基本均为原创