PaddlePaddle领航团 OpenCV基础知识点总结
PaddlePaddle领航团 OpenCV基础知识点总结
1.OpenCV基础
- 加载图片,显示图片,保存图片
- OpenCV函数:
cv2.imread(),cv2.imshow(),cv2.imwrite()
说明
-
OpenCV中彩色图是以B-G-R通道顺序存储的,灰度图只有一个通道。
-
OpenCV默认使用BGR格式,而RGB和BGR的颜色转换不同,即使转换为灰度也是如此。一些开发人员认为R+G+B/3对于灰度是正确的,但最佳灰度值称为亮度(luminosity),并且具有公式:0.21R+0.72G+0.07*B
-
图像坐标的起始点是在左上角,所以行对应的是y,列对应的是x。
加载图片
使用cv2.imread()来读入一张图片:
- 参数1:图片的文件名
- 如果图片放在当前文件夹下,直接写文件名就行了,如’lena.jpg’;否则需要给出绝对路径,如’D:\OpenCVSamples\lena.jpg’
- 参数2:读入方式,省略即采用默认值
- cv2.IMREAD_COLOR:彩色图,默认值(1)
- cv2.IMREAD_GRAYSCALE:灰度图(0)
- cv2.IMREAD_UNCHANGED:包含透明通道的彩色图(-1)
经验之谈:路径中不能有中文噢,并且没有加载成功的话是不会报错的,print(img)的结果为None,后面处理才会报错,算是个小坑。
#查看安装包版本
!pip list
Package Version
---------------------- -------------------------------
absl-py 0.8.1
aspy.yaml 1.3.0
astor 0.8.1
astroid 2.4.1
attrs 19.2.0
audioread 2.1.8
autopep8 1.5.3
Babel 2.8.0
backcall 0.1.0
bce-python-sdk 0.8.53
blackhole 0.3.1+5.g4015d80.dirty
bleach 3.1.0
cachetools 4.0.0
certifi 2019.9.11
cffi 1.14.0
cfgv 2.0.1
chardet 3.0.4
Click 7.0
cloudpickle 1.6.0
cma 2.7.0
colorama 0.4.4
colorlog 4.1.0
cycler 0.10.0
Cython 0.29
datatable 1.0.0a0+build.1606902301.jarvis
decorator 4.4.0
entrypoints 0.3
et-xmlfile 1.0.1
flake8 3.8.2
Flask 1.1.1
Flask-Babel 1.0.0
Flask-Cors 3.0.8
forbiddenfruit 0.1.3
funcsigs 1.0.2
future 0.18.0
gast 0.3.3
google-auth 1.10.0
google-auth-oauthlib 0.4.1
graphviz 0.13
grpcio 1.35.0
gunicorn 20.0.4
gym 0.12.1
h2o 3.29.0.99999
h5py 2.9.0
identify 1.4.10
idna 2.8
imageio 2.6.1
imageio-ffmpeg 0.3.0
importlib-metadata 0.23
ipykernel 5.1.0
ipython 7.8.0
ipython-genutils 0.2.0
isort 4.3.21
itsdangerous 1.1.0
jdcal 1.4.1
jedi 0.17.0
jieba 0.42.1
Jinja2 2.10.3
joblib 0.14.1
JPype1 0.7.2
json5 0.9.5
jsonschema 3.1.1
jupyter-client 5.3.4
jupyter-core 4.6.0
jupyter-lsp 0.8.0
jupyterlab 2.1.3
jupyterlab-server 1.1.5
kiwisolver 1.1.0
lazy-object-proxy 1.4.3
librosa 0.7.2
llvmlite 0.31.0
Markdown 3.1.1
MarkupSafe 1.1.1
matplotlib 2.2.3
mccabe 0.6.1
mistune 0.8.4
more-itertools 7.2.0
moviepy 1.0.1
nbconvert 5.3.1
nbformat 4.4.0
netifaces 0.10.9
networkx 2.4
nltk 3.4.5
nodeenv 1.3.4
notebook 5.7.8
numba 0.48.0
numpy 1.16.4
oauthlib 3.1.0
objgraph 3.4.1
opencv-python 4.1.1.26
openpyxl 3.0.5
paddlehub 1.6.0
paddlepaddle 2.0.0
pandas 0.23.4
pandocfilters 1.4.2
parl 1.4.1
parso 0.7.0
pathlib 1.0.1
pexpect 4.7.0
pickleshare 0.7.5
Pillow 7.1.2
pip 19.2.3
pluggy 0.13.1
pre-commit 1.21.0
prettytable 0.7.2
proglog 0.1.9
prometheus-client 0.5.0
prompt-toolkit 2.0.10
protobuf 3.14.0
psutil 5.7.2
ptyprocess 0.6.0
pyarrow 2.0.0
pyasn1 0.4.8
pyasn1-modules 0.2.7
pycodestyle 2.6.0
pycparser 2.19
pycryptodome 3.9.9
pydocstyle 5.0.2
pyflakes 2.2.0
pyglet 1.4.5
Pygments 2.4.2
pylint 2.5.2
pynvml 8.0.4
pyparsing 2.4.2
pyrsistent 0.15.4
python-dateutil 2.8.0
python-jsonrpc-server 0.3.4
python-language-server 0.33.0
pytz 2019.3
PyYAML 5.1.2
pyzmq 18.1.1
rarfile 3.1
recordio 0.1.7
requests 2.22.0
requests-oauthlib 1.3.0
resampy 0.2.2
rope 0.17.0
rsa 4.0
scikit-learn 0.22.1
scipy 1.3.0
seaborn 0.10.0
Send2Trash 1.5.0
sentencepiece 0.1.85
setuptools 41.4.0
shellcheck-py 0.7.1.1
six 1.15.0
sklearn 0.0
snowballstemmer 2.0.0
SoundFile 0.10.3.post1
tabulate 0.8.3
tb-nightly 1.15.0a20190801
tb-paddle 0.3.6
tensorboard 2.1.0
tensorboardX 1.8
termcolor 1.1.0
terminado 0.8.2
testpath 0.4.2
toml 0.10.0
tornado 6.0.3
tqdm 4.36.1
traitlets 4.3.3
typed-ast 1.4.1
ujson 1.35
urllib3 1.25.6
virtualenv 16.7.9
visualdl 2.1.1
wcwidth 0.1.7
webencodings 0.5.1
Werkzeug 0.16.0
wheel 0.33.6
wrapt 1.12.1
xarray 0.16.2
xgboost 1.1.0
xlrd 1.2.0
yapf 0.26.0
zipp 0.6.0
#导入包
%matplotlib inline
import numpy as np
import cv2
import matplotlib.pyplot as plt
加载图片、显示图片
# 加载彩色图
img = cv2.imread('lena.jpg', 1)
# 将彩色图的BGR通道顺序转成RGB
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 显示图片
plt.imshow(img)
# 打印图片的形状
print(img.shape)
# 形状中包括行数、列数和通道数
height, width, channels = img.shape
# img是灰度图的话:height, width = img.shape
img.shape
(350, 350, 3)
(350, 350, 3)
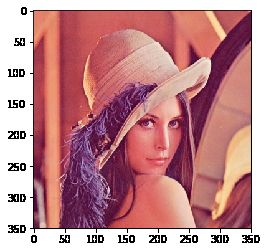
# 加载灰度图
img = cv2.imread('lena.jpg', 0)
# 将彩色图的BGR通道顺序转成RGB
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
plt.imshow(img)

# 加载灰度图
img = cv2.imread('lena.jpg', 0)
# 显示这张灰度图
plt.imshow(img,'gray')
img.shape
(350, 350)

通道变化
# 加载彩色图
img = cv2.imread('lena.jpg', 1)
# 将彩色图的BGR通道直接转为灰度图
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
plt.imshow(img,'gray')

# 查看一下plt.imshow的用法
?plt.imshow
#查看cv2.imshow
?cv2.imshow
# 加载四通道图片
img1 = cv2.imread('cat.png',-1)
# 将彩色图的BGR通道顺序转成RGB,注意,在这一步直接丢掉了alpha通道
img1 = cv2.cvtColor(img1, cv2.COLOR_BGR2RGB)
plt.imshow(img1)

# 加载彩色图
img1 = cv2.imread('cat.png',1)
# 不转颜色通道
plt.imshow(img1)

img1 = cv2.imread('cat.png', 1)
# 转颜色通道为RGB
img1 = cv2.cvtColor(img1, cv2.COLOR_BGR2RGB)
plt.imshow(img1)

保存图片
#保存图片
cv2.imwrite('lena-grey.jpg',img)
True
2.OpenCV进阶
import math
import random
import numpy as np
%matplotlib inline
import cv2
import matplotlib.pyplot as plt
# 创建一副图片
img = cv2.imread('cat.png')
# 转换颜色通道
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
plt.imshow(img)
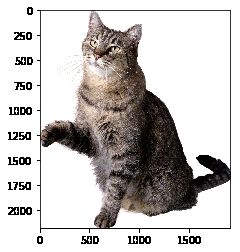
# 截取猫脸ROI
face = img[0:740, 400:1000]
plt.imshow(face)

说明
- ROI:Region of Interest,感兴趣区域。
- 截取ROI非常简单,指定图片的范围即可
通道分割与合并
彩色图的BGR三个通道是可以分开单独访问的,也可以将单独的三个通道合并成一副图像。分别使用cv2.split()和cv2.merge():
# 创建一副图片
img2 = cv2.imread('lena.jpg')
# 通道分割
b, g, r = cv2.split(img2)
# 通道合并
img2 = cv2.merge((r, g, b))
说明
上述操作相当于完成了一次通道转换
plt.imshow(img2)

RGB_Image=cv2.merge([b,g,r])
RGB_Image = cv2.cvtColor(RGB_Image, cv2.COLOR_BGR2RGB)
plt.figure(figsize=(12,12))
#显示各通道信息
plt.subplot(141)
plt.imshow(RGB_Image,'gray')
plt.title('RGB_Image')
plt.subplot(142)
plt.imshow(r,'gray')
plt.title('R_Channel')
plt.subplot(143)
plt.imshow(g,'gray')
plt.title('G_Channel')
plt.subplot(144)
plt.imshow(b,'gray')
plt.title('B_Channel')
Text(0.5,1,'B_Channel')

颜色空间转换
最常用的颜色空间转换如下:
- RGB或BGR到灰度(COLOR_RGB2GRAY,COLOR_BGR2GRAY)
- RGB或BGR到YcrCb(或YCC)(COLOR_RGB2YCrCb,COLOR_BGR2YCrCb)
- RGB或BGR到HSV(COLOR_RGB2HSV,COLOR_BGR2HSV)
- RGB或BGR到Luv(COLOR_RGB2Luv,COLOR_BGR2Luv)
- 灰度到RGB或BGR(COLOR_GRAY2RGB,COLOR_GRAY2BGR)
经验之谈:颜色转换其实是数学运算,如灰度化最常用的是: g r a y = R ∗ 0.299 + G ∗ 0.587 + B ∗ 0.114 gray=R*0.299+G*0.587+B*0.114 gray=R∗0.299+G∗0.587+B∗0.114
特定颜色物体追踪
例子:实现一个使用HSV来只显示图片中蓝色物体
HSV是一个常用于颜色识别的模型,相比BGR更易区分颜色,转换模式用COLOR_BGR2HSV表示。
经验之谈:OpenCV中色调H范围为[0,179],饱和度S是[0,255],明度V是[0,255]。虽然H的理论数值是0°~360°,但8位图像像素点的最大值是255,所以OpenCV中除以了2,某些软件可能使用不同的尺度表示,所以同其他软件混用时,记得归一化。
# 加载一张有天空的图片
sky = cv2.imread('sky.jpg')
sk1 = cv2.cvtColor(sky, cv2.COLOR_BGR2RGB)
plt.imshow(sk1)

# 蓝色的范围,不同光照条件下不一样,可灵活调整
lower_blue = np.array([15, 60, 60])
upper_blue = np.array([130, 255, 255])
# 从BGR转换到HSV
hsv = cv2.cvtColor(sky, cv2.COLOR_BGR2HSV)
# inRange():介于lower/upper之间的为白色,其余黑色
mask = cv2.inRange(sky, lower_blue, upper_blue)
# 只保留原图中的蓝色部分
res = cv2.bitwise_and(sky, sky, mask=mask)
# 保存颜色分割结果
cv2.imwrite('res.jpg', res)
True
res = cv2.imread('res.jpg')
res = cv2.cvtColor(res, cv2.COLOR_BGR2RGB)
plt.imshow(res)

其中,bitwise_and()函数暂时不用管,后面会讲到。那蓝色的HSV值的上下限lower和upper范围是怎么得到的呢?其实很简单,我们先把标准蓝色的BGR值用cvtColor()转换下:
blue = np.uint8([[[255, 0, 0]]])
hsv_blue = cv2.cvtColor(blue, cv2.COLOR_BGR2HSV)
print(hsv_blue)
[[[120 255 255]]]
结果是[120, 255, 255],所以,我们把蓝色的范围调整成了上面代码那样。
经验之谈:Lab颜色空间也经常用来做颜色识别,有兴趣的同学可以了解下。
阈值分割
- 使用固定阈值、自适应阈值和Otsu阈值法"二值化"图像
- OpenCV函数:
cv2.threshold(),cv2.adaptiveThreshold()
固定阈值分割
固定阈值分割很直接,一句话说就是像素点值大于阈值变成一类值,小于阈值变成另一类值。
cv2.threshold()用来实现阈值分割,ret是return value缩写,代表当前的阈值。函数有4个参数:
- 参数1:要处理的原图,一般是灰度图
- 参数2:设定的阈值
- 参数3:最大阈值,一般为255
- 参数4:阈值的方式,主要有5种,详情:ThresholdTypes
- 0: THRESH_BINARY 当前点值大于阈值时,取Maxval,也就是第四个参数,否则设置为0
- 1: THRESH_BINARY_INV 当前点值大于阈值时,设置为0,否则设置为Maxval
- 2: THRESH_TRUNC 当前点值大于阈值时,设置为阈值,否则不改变
- 3: THRESH_TOZERO 当前点值大于阈值时,不改变,否则设置为0
- 4:THRESH_TOZERO_INV 当前点值大于阈值时,设置为0,否则不改变
import cv2
# 灰度图读入
img = cv2.imread('lena.jpg', 0)
# 颜色通道转换
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 阈值分割
ret, th = cv2.threshold(img, 127, 255, cv2.THRESH_BINARY)
plt.imshow(th)

th[100]
array([[ 0, 0, 0],
[ 0, 0, 0],
[ 0, 0, 0],
...,
[255, 255, 255],
[255, 255, 255],
[255, 255, 255]], dtype=uint8)
# 应用5种不同的阈值方法
# THRESH_BINARY 当前点值大于阈值时,取Maxval,否则设置为0
ret, th1 = cv2.threshold(img, 127, 255, cv2.THRESH_BINARY)
# THRESH_BINARY_INV 当前点值大于阈值时,设置为0,否则设置为Maxval
ret, th2 = cv2.threshold(img, 127, 255, cv2.THRESH_BINARY_INV)
# THRESH_TRUNC 当前点值大于阈值时,设置为阈值,否则不改变
ret, th3 = cv2.threshold(img, 127, 255, cv2.THRESH_TRUNC)
# THRESH_TOZERO 当前点值大于阈值时,不改变,否则设置为0
ret, th4 = cv2.threshold(img, 127, 255, cv2.THRESH_TOZERO)
# THRESH_TOZERO_INV 当前点值大于阈值时,设置为0,否则不改变
ret, th5 = cv2.threshold(img, 127, 255, cv2.THRESH_TOZERO_INV)
titles = ['Original', 'BINARY', 'BINARY_INV', 'TRUNC', 'TOZERO', 'TOZERO_INV']
images = [img, th1, th2, th3, th4, th5]
plt.figure(figsize=(12,12))
for i in range(6):
plt.subplot(2, 3, i + 1)
plt.imshow(images[i], 'gray')
plt.title(titles[i], fontsize=8)
plt.xticks([]), plt.yticks([])

自适应阈值
看得出来固定阈值是在整幅图片上应用一个阈值进行分割,它并不适用于明暗分布不均的图片。 cv2.adaptiveThreshold()自适应阈值会每次取图片的一小部分计算阈值,这样图片不同区域的阈值就不尽相同。它有5个参数,其实很好理解,先看下效果:
- 参数1:要处理的原图
- 参数2:最大阈值,一般为255
- 参数3:小区域阈值的计算方式
ADAPTIVE_THRESH_MEAN_C:小区域内取均值ADAPTIVE_THRESH_GAUSSIAN_C:小区域内加权求和,权重是个高斯核
- 参数4:阈值方式(跟前面讲的那5种相同)
- 参数5:小区域的面积,如11就是11*11的小块
- 参数6:最终阈值等于小区域计算出的阈值再减去此值
建议读者调整下参数看看不同的结果。
# 自适应阈值对比固定阈值
img = cv2.imread('lena.jpg', 0)
# 固定阈值
ret, th1 = cv2.threshold(img, 127, 255, cv2.THRESH_BINARY)
# 自适应阈值, ADAPTIVE_THRESH_MEAN_C:小区域内取均值
th2 = cv2.adaptiveThreshold(
img, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 11, 4)
# 自适应阈值, ADAPTIVE_THRESH_GAUSSIAN_C:小区域内加权求和,权重是个高斯核
th3 = cv2.adaptiveThreshold(
img, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 17, 6)
titles = ['Original', 'Global(v = 127)', 'Adaptive Mean', 'Adaptive Gaussian']
images = [img, th1, th2, th3]
plt.figure(figsize=(12,12))
for i in range(4):
plt.subplot(2, 2, i + 1), plt.imshow(images[i], 'gray')
plt.title(titles[i], fontsize=8)
plt.xticks([]), plt.yticks([])

Otsu阈值
在前面固定阈值中,我们是随便选了一个阈值如127,那如何知道我们选的这个阈值效果好不好呢?答案是:不断尝试,所以这种方法在很多文献中都被称为经验阈值。Otsu阈值法就提供了一种自动高效的二值化方法。
小结
cv2.threshold()用来进行固定阈值分割。固定阈值不适用于光线不均匀的图片,所以用cv2.adaptiveThreshold()进行自适应阈值分割。- 二值化跟阈值分割并不等同。针对不同的图片,可以采用不同的阈值方法。
图像几何变换
- 实现旋转、平移和缩放图片
- OpenCV函数:
cv2.resize(),cv2.flip(),cv2.warpAffine()
缩放图片
缩放就是调整图片的大小,使用cv2.resize()函数实现缩放。可以按照比例缩放,也可以按照指定的大小缩放:
我们也可以指定缩放方法interpolation,更专业点叫插值方法,默认是INTER_LINEAR,全部可以参考:InterpolationFlags
缩放过程中有五种插值方式:
- cv2.INTER_NEAREST 最近邻插值
- cv2.INTER_LINEAR 线性插值
- cv2.INTER_AREA 基于局部像素的重采样,区域插值
- cv2.INTER_CUBIC 基于邻域4x4像素的三次插值
- cv2.INTER_LANCZOS4 基于8x8像素邻域的Lanczos插值
img = cv2.imread('cat.png')
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 按照指定的宽度、高度缩放图片
res = cv2.resize(img, (400, 500))
# 按照比例缩放,如x,y轴均放大一倍
res2 = cv2.resize(img, None, fx=2, fy=2, interpolation=cv2.INTER_LINEAR)
plt.imshow(res)

翻转图片
镜像翻转图片,可以用cv2.flip()函数:
其中,参数2 = 0:垂直翻转(沿x轴),参数2 > 0: 水平翻转(沿y轴),参数2 < 0: 水平垂直翻转。
dst = cv2.flip(img, 1)
plt.imshow(dst)
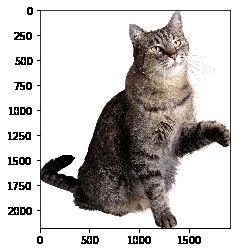
平移图片
要平移图片,我们需要定义下面这样一个矩阵,tx,ty是向x和y方向平移的距离:
M = [ 1 0 t x 0 1 t y ] M = \left[ \begin{matrix} 1 & 0 & t_x \newline 0 & 1 & t_y \end{matrix} \right] M=[10tx01ty]
平移是用仿射变换函数cv2.warpAffine()实现的:
# 平移图片
import numpy as np
# 获得图片的高、宽
rows, cols = img.shape[:2]
# 定义平移矩阵,需要是numpy的float32类型
# x轴平移100,y轴平移500
M = np.float32([[1, 0, 100], [0, 1, 500]])
# 用仿射变换实现平移
dst = cv2.warpAffine(img, M, (cols, rows))
plt.imshow(dst)

绘图功能
- 绘制各种几何形状、添加文字
- OpenCV函数:
cv2.line(),cv2.circle(),cv2.rectangle(),cv2.ellipse(),cv2.putText()
绘制形状的函数有一些共同的参数,提前在此说明一下:
- img:要绘制形状的图片
- color:绘制的颜色
- 彩色图就传入BGR的一组值,如蓝色就是(255,0,0)
- 灰度图,传入一个灰度值就行
- thickness:线宽,默认为1;对于矩形/圆之类的封闭形状而言,传入-1表示填充形状
- lineType:线的类型。默认情况下,它是8连接的。cv2.LINE_AA 是适合曲线的抗锯齿线。
画线
画直线只需指定起点和终点的坐标就行:
img = cv2.imread('lena.jpg')
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 画一条线宽为5的红色直线,参数2:起点,参数3:终点
cv2.line(img, (0, 0), (800, 512), (255, 0, 0), 5)
plt.imshow(img)
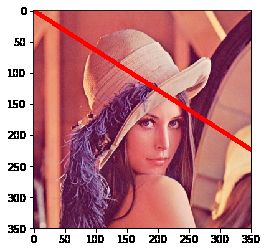
画矩形
画矩形需要知道左上角和右下角的坐标:
# 画一个矩形,左上角坐标(40, 40),右下角坐标(80, 80),框颜色为绿色
img = cv2.rectangle(img, (40, 40), (80, 80), (0, 255, 0),2)
plt.imshow(img)
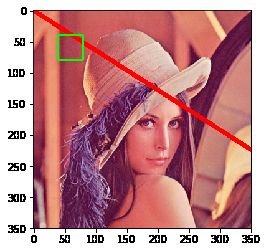
# 画一个矩形,左上角坐标(40, 40),右下角坐标(80, 80),框颜色为绿色,填充这个矩形
img = cv2.rectangle(img, (40, 40), (80, 80), (0, 255, 0),-1)
plt.imshow(img)
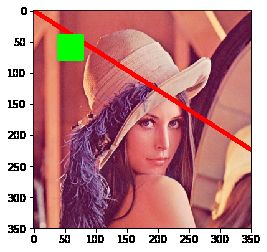
添加文字
使用cv2.putText()添加文字,它的参数也比较多,同样请对照后面的代码理解这几个参数:
- 参数2:要添加的文本
- 参数3:文字的起始坐标(左下角为起点)
- 参数4:字体
- 参数5:文字大小(缩放比例)
# 添加文字,加载字体
font = cv2.FONT_HERSHEY_SIMPLEX
# 添加文字hello
cv2.putText(img, 'hello', (10, 200), font,
4, (255, 255, 255), 2, lineType=cv2.LINE_AA)
plt.imshow(img)

# 参考资料 https://blog.csdn.net/qq_41895190/article/details/90301459
# 引入PIL的相关包
from PIL import Image, ImageFont,ImageDraw
from numpy import unicode
def paint_chinese_opencv(im,chinese,pos,color):
img_PIL = Image.fromarray(cv2.cvtColor(im,cv2.COLOR_BGR2RGB))
# 加载中文字体
font = ImageFont.truetype('NotoSansCJKsc-Medium.otf',25)
# 设置颜色
fillColor = color
# 定义左上角坐标
position = pos
# 判断是否中文字符
if not isinstance(chinese,unicode):
# 解析中文字符
chinese = chinese.decode('utf-8')
# 画图
draw = ImageDraw.Draw(img_PIL)
# 画文字
draw.text(position,chinese,font=font,fill=fillColor)
# 颜色通道转换
img = cv2.cvtColor(np.asarray(img_PIL),cv2.COLOR_RGB2BGR)
return img
plt.imshow(paint_chinese_opencv(img,'中文',(100,100),(255,255,0)))

小结
cv2.line()画直线,cv2.circle()画圆,cv2.rectangle()画矩形,cv2.ellipse()画椭圆,cv2.polylines()画多边形,cv2.putText()添加文字。- 画多条直线时,
cv2.polylines()要比cv2.line()高效很多。 - 要在图像中打上中文,可以用PIL库结合OpenCV实现。
图像间数学运算
- 图片间的数学运算,如相加、按位运算等
- OpenCV函数:
cv2.add(),cv2.addWeighted(),cv2.bitwise_and()
图片相加
要叠加两张图片,可以用cv2.add()函数,相加两幅图片的形状(高度/宽度/通道数)必须相同。numpy中可以直接用res = img + img1相加,但这两者的结果并不相同:
x = np.uint8([250])
y = np.uint8([10])
print(cv2.add(x, y)) # 250+10 = 260 => 255
print(x + y) # 250+10 = 260 % 256 = 4
[[255]]
[4]
如果是二值化图片(只有0和255两种值),两者结果是一样的(用numpy的方式更简便一些)。
图像混合
图像混合cv2.addWeighted()也是一种图片相加的操作,只不过两幅图片的权重不一样,γ相当于一个修正值:
d s t = α × i m g 1 + β × i m g 2 + γ dst = \alpha\times img1+\beta\times img2 + \gamma dst=α×img1+β×img2+γ
img1 = cv2.imread('lena.jpg')
img1 = cv2.cvtColor(img1, cv2.COLOR_BGR2RGB)
img2 = cv2.imread('cat.png')
img2 = cv2.cvtColor(img2, cv2.COLOR_BGR2RGB)
img2 = cv2.resize(img2, (350, 350))
# 两张图片相加
res = cv2.addWeighted(img1, 0.6, img2, 0.4, 0)
plt.imshow(res)

img1 = cv2.imread('lena.jpg')
img2 = cv2.imread('logo.jpg')
img2 = cv2.resize(img2, (350, 350))
# 把logo放在左上角,所以我们只关心这一块区域
rows, cols = img2.shape[:2]
roi = img1[:rows, :cols]
# 创建掩膜
img2gray = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)
ret, mask = cv2.threshold(img2gray, 10, 255, cv2.THRESH_BINARY)
mask_inv = cv2.bitwise_not(mask)
# 保留除logo外的背景
img1_bg = cv2.bitwise_and(roi, roi, mask=mask_inv)
dst = cv2.add(img1_bg, img2) # 进行融合
img1[:rows, :cols] = dst # 融合后放在原图上
plt.imshow(dst)

小结
cv2.add()用来叠加两幅图片,cv2.addWeighted()也是叠加两幅图片,但两幅图片的权重不一样。cv2.bitwise_and(),cv2.bitwise_not(),cv2.bitwise_or(),cv2.bitwise_xor()分别执行按位与/或/非/异或运算。掩膜就是用来对图片进行全局或局部的遮挡。
平滑图像
- 模糊/平滑图片来消除图片噪声
- OpenCV函数:
cv2.blur(),cv2.GaussianBlur(),cv2.medianBlur(),cv2.bilateralFilter()
滤波与模糊
关于滤波和模糊:
- 它们都属于卷积,不同滤波方法之间只是卷积核不同(对线性滤波而言)
- 低通滤波器是模糊,高通滤波器是锐化
低通滤波器就是允许低频信号通过,在图像中边缘和噪点都相当于高频部分,所以低通滤波器用于去除噪点、平滑和模糊图像。高通滤波器则反之,用来增强图像边缘,进行锐化处理。
常见噪声有椒盐噪声和高斯噪声,椒盐噪声可以理解为斑点,随机出现在图像中的黑点或白点;高斯噪声可以理解为拍摄图片时由于光照等原因造成的噪声。
均值滤波
均值滤波是一种最简单的滤波处理,它取的是卷积核区域内元素的均值,用cv2.blur()实现,如3×3的卷积核:
k e r n e l = 1 9 [ 1 1 1 1 1 1 1 1 1 ] kernel = \frac{1}{9}\left[ \begin{matrix} 1 & 1 & 1 \newline 1 & 1 & 1 \newline 1 & 1 & 1 \end{matrix} \right] kernel=91[111111111]
img = cv2.imread('lena.jpg')
blur = cv2.blur(img, (3, 3)) # 均值模糊
img = cv2.imread('lena.jpg')
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
blur = cv2.blur(img, (9, 9)) # 均值模糊
plt.imshow(blur)

方框滤波
方框滤波跟均值滤波很像,如3×3的滤波核如下:
k = a [ 1 1 1 1 1 1 1 1 1 ] k = a\left[ \begin{matrix} 1 & 1 & 1 \newline 1 & 1 & 1 \newline 1 & 1 & 1 \end{matrix} \right] k=a[111111111]
用cv2.boxFilter()函数实现,当可选参数normalize为True的时候,方框滤波就是均值滤波,上式中的a就等于1/9;normalize为False的时候,a=1,相当于求区域内的像素和。
# 前面的均值滤波也可以用方框滤波实现:normalize=True
blur = cv2.boxFilter(img, -1, (9, 9), normalize=True)
plt.imshow(blur)

高斯滤波
前面两种滤波方式,卷积核内的每个值都一样,也就是说图像区域中每个像素的权重也就一样。高斯滤波的卷积核权重并不相同:中间像素点权重最高,越远离中心的像素权重越小。
显然这种处理元素间权值的方式更加合理一些。图像是2维的,所以我们需要使用2维的高斯函数,比如OpenCV中默认的3×3的高斯卷积核:
k = [ 0.0625 0.125 0.0625 0.125 0.25 0.125 0.0625 0.125 0.0625 ] k = \left[ \begin{matrix} 0.0625 & 0.125 & 0.0625 \newline 0.125 & 0.25 & 0.125 \newline 0.0625 & 0.125 & 0.0625 \end{matrix} \right] k=[0.06250.1250.06250.1250.250.1250.06250.1250.0625]
OpenCV中对应函数为cv2.GaussianBlur(src,ksize,sigmaX):
参数3 σx值越大,模糊效果越明显。高斯滤波相比均值滤波效率要慢,但可以有效消除高斯噪声,能保留更多的图像细节,所以经常被称为最有用的滤波器。均值滤波与高斯滤波的对比结果如下(均值滤波丢失的细节更多)
# 均值滤波vs高斯滤波
gaussian = cv2.GaussianBlur(img, (9, 9), 1) # 高斯滤波
plt.imshow(gaussian)

中值滤波
中值又叫中位数,是所有数排序后取中间的值。中值滤波就是用区域内的中值来代替本像素值,所以那种孤立的斑点,如0或255很容易消除掉,适用于去除椒盐噪声和斑点噪声。中值是一种非线性操作,效率相比前面几种线性滤波要慢。
median = cv2.medianBlur(img, 9) # 中值滤波
plt.imshow(median)

双边滤波
模糊操作基本都会损失掉图像细节信息,尤其前面介绍的线性滤波器,图像的边缘信息很难保留下来。然而,边缘(edge)信息是图像中很重要的一个特征,所以这才有了双边滤波。用cv2.bilateralFilter()函数实现:可以看到,双边滤波明显保留了更多边缘信息。
blur = cv2.bilateralFilter(img, 9, 75, 75) # 双边滤波
plt.imshow(blur)
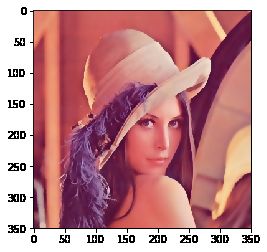
图像锐化
kernel = np.array([[0, -1, 0], [-1, 5, -1], [0, -1, 0]], np.float32) #定义一个核
dst = cv2.filter2D(img, -1, kernel=kernel)
plt.imshow(dst)

边缘检测
Canny J . A Computational Approach To Edge Detection[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1986, PAMI-8(6):679-698.
- Canny边缘检测的简单概念
- OpenCV函数:
cv2.Canny()
Canny边缘检测方法常被誉为边缘检测的最优方法:
cv2.Canny()进行边缘检测,参数2、3表示最低、高阈值,下面来解释下具体原理。
经验之谈:之前我们用低通滤波的方式模糊了图片,那反过来,想得到物体的边缘,就需要用到高通滤波。
Canny边缘检测
Canny边缘提取的具体步骤如下:
- 使用5×5高斯滤波消除噪声:
边缘检测本身属于锐化操作,对噪点比较敏感,所以需要进行平滑处理。
K = 1 256 [ 1 4 6 4 1 4 16 24 16 4 6 24 36 24 6 4 16 24 16 4 1 4 6 4 1 ] K=\frac{1}{256}\left[ \begin{matrix} 1 & 4 & 6 & 4 & 1 \newline 4 & 16 & 24 & 16 & 4 \newline 6 & 24 & 36 & 24 & 6 \newline 4 & 16 & 24 & 16 & 4 \newline 1 & 4 & 6 & 4 & 1 \end{matrix} \right] K=2561[1464141624164624362464162416414641]
2. 计算图像梯度的方向:
首先使用Sobel算子计算两个方向上的梯度$ G_x 和 和 和 G_y $,然后算出梯度的方向:
θ = arctan ( G y G x ) \theta=\arctan(\frac{G_y}{G_x}) θ=arctan(GxGy)
保留这四个方向的梯度:0°/45°/90°/135°,有什么用呢?我们接着看。
- 取局部极大值:
梯度其实已经表示了轮廓,但为了进一步筛选,可以在上面的四个角度方向上再取局部极大值
- 滞后阈值:
经过前面三步,就只剩下0和可能的边缘梯度值了,为了最终确定下来,需要设定高低阈值:
- 像素点的值大于最高阈值,那肯定是边缘
- 同理像素值小于最低阈值,那肯定不是边缘
- 像素值介于两者之间,如果与高于最高阈值的点连接,也算边缘,所以上图中C算,B不算
Canny推荐的高低阈值比在2:1到3:1之间。
img = cv2.imread('lena.jpg')
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
edges = cv2.Canny(img, 30, 70) # canny边缘检测
plt.imshow(edges)

先阈值分割后检测
其实很多情况下,阈值分割后再检测边缘,效果会更好。
_, thresh = cv2.threshold(img, 124, 255, cv2.THRESH_BINARY)
edges = cv2.Canny(thresh, 30, 70)
plt.imshow(edges)

小结
- Canny是用的最多的边缘检测算法,用
cv2.Canny()实现。
腐蚀与膨胀
- 了解形态学操作的概念
- 学习膨胀、腐蚀、开运算和闭运算等形态学操作
- OpenCV函数:
cv2.erode(),cv2.dilate(),cv2.morphologyEx()
啥叫形态学操作
形态学操作其实就是改变物体的形状,比如腐蚀就是"变瘦",膨胀就是"变胖"。
经验之谈:形态学操作一般作用于二值化图,来连接相邻的元素或分离成独立的元素。腐蚀和膨胀是针对图片中的白色部分!
腐蚀
腐蚀的效果是把图片"变瘦",其原理是在原图的小区域内取局部最小值。因为是二值化图,只有0和255,所以小区域内有一个是0该像素点就为0。
这样原图中边缘地方就会变成0,达到了瘦身目的
OpenCV中用cv2.erode()函数进行腐蚀,只需要指定核的大小就行:
img = cv2.imread('lena.jpg')
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
kernel = np.ones((5, 5), np.uint8)
erosion = cv2.erode(img, kernel) # 腐蚀
plt.imshow(erosion)

这个核也叫结构元素,因为形态学操作其实也是应用卷积来实现的。结构元素可以是矩形/椭圆/十字形,可以用
cv2.getStructuringElement()来生成不同形状的结构元素,比如:
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (5, 5)) # 矩形结构
kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (5, 5)) # 椭圆结构
kernel = cv2.getStructuringElement(cv2.MORPH_CROSS, (5, 5)) # 十字形结构
dilation = cv2.dilate(img, kernel) # 膨胀
plt.imshow(dilation)

膨胀
膨胀与腐蚀相反,取的是局部最大值,效果是把图片"变胖":
开/闭运算
先腐蚀后膨胀叫开运算(因为先腐蚀会分开物体,这样容易记住),其作用是:分离物体,消除小区域。这类形态学操作用cv2.morphologyEx()函数实现:
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (5, 5)) # 定义结构元素
opening = cv2.morphologyEx(img, cv2.MORPH_OPEN, kernel) # 开运算
plt.imshow(opening)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XzAnZjTr-1615201560444)(output_101_1.png)]
闭运算则相反:先膨胀后腐蚀(先膨胀会使白色的部分扩张,以至于消除/"闭合"物体里面的小黑洞,所以叫闭运算)
closing = cv2.morphologyEx(img, cv2.MORPH_CLOSE, kernel) # 闭运算
plt.imshow(closing)
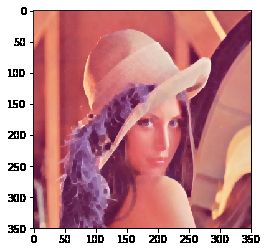
使用OpenCV摄像头与加载视频
学习打开摄像头捕获照片、播放本地视频、录制视频等。
- 打开摄像头并捕获照片
- 播放本地视频,录制视频
- OpenCV函数:
cv2.VideoCapture(),cv2.VideoWriter()
打开摄像头
要使用摄像头,需要使用cv2.VideoCapture(0)创建VideoCapture对象,参数0指的是摄像头的编号,如果你电脑上有两个摄像头的话,访问第2个摄像头就可以传入1,依此类推。
# 打开摄像头并灰度化显示
import cv2
capture = cv2.VideoCapture(0)
while(True):
# 获取一帧
ret, frame = capture.read()
# 将这帧转换为灰度图
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
cv2.imshow('frame', gray)
if cv2.waitKey(1) == ord('q'):
break
capture.read()函数返回的第1个参数ret(return value缩写)是一个布尔值,表示当前这一帧是否获取正确。cv2.cvtColor()用来转换颜色,这里将彩色图转成灰度图。
另外,通过cap.get(propId)可以获取摄像头的一些属性,比如捕获的分辨率,亮度和对比度等。propId是从0~18的数字,代表不同的属性,完整的属性列表可以参考:VideoCaptureProperties。也可以使用cap.set(propId,value)来修改属性值。比如说,我们在while之前添加下面的代码:
# 获取捕获的分辨率
# propId可以直接写数字,也可以用OpenCV的符号表示
width, height = capture.get(3), capture.get(4)
print(width, height)
# 以原分辨率的一倍来捕获
capture.set(cv2.CAP_PROP_FRAME_WIDTH, width * 2)
capture.set(cv2.CAP_PROP_FRAME_HEIGHT, height * 2)
经验之谈:某些摄像头设定分辨率等参数时会无效,因为它有固定的分辨率大小支持,一般可在摄像头的资料页中找到。
播放本地视频
跟打开摄像头一样,如果把摄像头的编号换成视频的路径就可以播放本地视频了。回想一下cv2.waitKey(),它的参数表示暂停时间,所以这个值越大,视频播放速度越慢,反之,播放速度越快,通常设置为25或30。
# 播放本地视频
capture = cv2.VideoCapture('demo_video.mp4')
while(capture.isOpened()):
ret, frame = capture.read()
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
cv2.imshow('frame', gray)
if cv2.waitKey(30) == ord('q'):
break
录制视频
之前我们保存图片用的是cv2.imwrite(),要保存视频,我们需要创建一个VideoWriter的对象,需要给它传入四个参数:
- 输出的文件名,如’output.avi’
- 编码方式FourCC码
- 帧率FPS
- 要保存的分辨率大小
FourCC是用来指定视频编码方式的四字节码,所有的编码可参考Video Codecs。如MJPG编码可以这样写: cv2.VideoWriter_fourcc(*'MJPG')或cv2.VideoWriter_fourcc('M','J','P','G')
capture = cv2.VideoCapture(0)
# 定义编码方式并创建VideoWriter对象
fourcc = cv2.VideoWriter_fourcc(*'MJPG')
outfile = cv2.VideoWriter('output.avi', fourcc, 25., (640, 480))
while(capture.isOpened()):
ret, frame = capture.read()
if ret:
outfile.write(frame) # 写入文件
cv2.imshow('frame', frame)
if cv2.waitKey(1) == ord('q'):
break
else:
break
小结
- 使用
cv2.VideoCapture()创建视频对象,然后在循环中一帧帧显示图像。参数传入数字时,代表打开摄像头,传入本地视频路径时,表示播放本地视频。 cap.get(propId)获取视频属性,cap.set(propId,value)设置视频属性。cv2.VideoWriter()创建视频写入对象,用来录制/保存视频。
3.总结
函数总结
- 读取图片
cv2.imread() - 展示图片
cv2.imshow() - 保存图片
cv2.imwrite() - 通道转换
cv2.cvtColor() - RGB或BGR到灰度
COLOR_RGB2GRAY,COLOR_BGR2GRAY - RGB或BGR到YcrCb(或YCC)
COLOR_RGB2YCrCb,COLOR_BGR2YCrCb - RGB或BGR到HSV
COLOR_RGB2HSV,COLOR_BGR2HSV - RGB或BGR到Luv
COLOR_RGB2Luv,COLOR_BGR2Luv - 灰度到RGB或BGR
COLOR_GRAY2RGB,COLOR_GRAY2BGR - 阈值分割
cv2.threshold() - 自适应阈值分割
cv2.adaptiveThreshold() - 缩放图片
cv2.resize() - 翻转图片
cv2.flip() - 平移图片
cv2.warpAffine() - 画线
cv2.line() - 画圆
cv2.circle() - 画矩形
cv2.rectangle() - 画椭圆
cv2.ellipse() - 画多边形
cv2.polylines() - 添加文字
cv2.putText() - 叠加图片
cv2.add() - 图像混合
cv2.addWeighted() - 按位与运算
cv2.bitwise_and() - 按位或运算`cv2.bitwise_not()
- 按位非运算
cv2.bitwise_or() - 按位异或运算
cv2.bitwise_xor() - 均值滤波
cv2.blur() - 高斯滤波
cv2.GaussianBlur() - 方框滤波
cv2.boxFilter() - 中值滤波
cv2.medianBlur() - 双边滤波
cv2.bilateralFilter() - 图像锐化
cv2.filter2D() - 边缘检测
cv2.Canny() - 腐蚀
cv2.erode() - 膨胀
cv2.dilate() - 开/闭运算
cv2.morphologyEx() - 打开摄像头
cv2.VideoCapture(0) - 读帧`capture.read()
- 获取摄像头属性
cap.get(propId) - 设置摄像头属性
cap.set(propId,value) - 播放视频
cv2.waitKey() - 保存视频
cv2.VideoWriter()
4.图像分类OpenCV作业
import cv2
import numpy as np
from matplotlib import pyplot as plt
%matplotlib inline
filename = '1.jpg'
## [Load an image from a file]
img = cv2.imread(filename)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
plt.imshow(img)

图片缩放
class Resize:
def __init__(self, size):
self.size=size
def __call__(self, img):
# 此处插入代码
return cv2.resize(img, self.size)
resize=Resize( (600, 600))
img2=resize(img)
plt.imshow(img2)

图片翻转
class Flip:
def __init__(self, mode):
self.mode=mode
def __call__(self, img):
# 此处插入代码
return cv2.flip(img, self.mode)
flip=Flip(mode=0)
img2=flip(img)
plt.imshow(img2)

图片旋转
class Rotate:
def __init__(self, degree,size):
self.degree=degree
self.size=size
def __call__(self, img):
# 此处插入代码
rows, cols = img.shape[:2]
M = cv2.getRotationMatrix2D((cols / 2, rows / 2), self.degree, self.size)
return cv2.warpAffine(img, M, (cols, rows))
rotate=Rotate( 45, 0.7)
img2=rotate(img)
plt.imshow(img2)

图片亮度调节
class Brightness:
def __init__(self,brightness_factor):
self.brightness_factor=brightness_factor
def __call__(self, img):
# 此处插入代码
return np.uint8(np.clip((self.brightness_factor * img), 0, 255))
brightness=Brightness(0.6)
img2=brightness(img)
plt.imshow(img2)
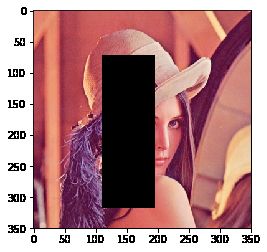
图片随机擦除
import random
import math
class RandomErasing(object):
def __init__(self, EPSILON=0.5, sl=0.02, sh=0.4, r1=0.3,
mean=[0., 0., 0.]):
self.EPSILON = EPSILON
self.mean = mean
self.sl = sl
self.sh = sh
self.r1 = r1
def __call__(self, img):
if random.uniform(0, 1) > self.EPSILON:
return img
for attempt in range(100):
area = img.shape[0] * img.shape[1]
target_area = random.uniform(self.sl, self.sh) * area
aspect_ratio = random.uniform(self.r1, 1 / self.r1)
h = int(round(math.sqrt(target_area * aspect_ratio)))
w = int(round(math.sqrt(target_area / aspect_ratio)))
# 此处插入代码
if w < img.shape[0] and h < img.shape[1]:
x1 = random.randint(0, img.shape[1] - h)
y1 = random.randint(0, img.shape[0] - w)
if img.shape[2] == 3:
img[ x1:x1 + h, y1:y1 + w, 0] = self.mean[0]
img[ x1:x1 + h, y1:y1 + w, 1] = self.mean[1]
img[ x1:x1 + h, y1:y1 + w, 2] = self.mean[2]
else:
img[x1:x1 + h, y1:y1 + w,0] = self.mean[0]
return img
return img
erase = RandomErasing()
img2=erase(img)
.shape[1] - h)
y1 = random.randint(0, img.shape[0] - w)
if img.shape[2] == 3:
img[ x1:x1 + h, y1:y1 + w, 0] = self.mean[0]
img[ x1:x1 + h, y1:y1 + w, 1] = self.mean[1]
img[ x1:x1 + h, y1:y1 + w, 2] = self.mean[2]
else:
img[x1:x1 + h, y1:y1 + w,0] = self.mean[0]
return img
return img
erase = RandomErasing()
img2=erase(img)
plt.imshow(img2)
5. 参考资料
- 面向初学者的OpenCV-Python教程
- OpenCV学习—OpenCV图像处理基本操作
- OpenCV 4计算机视觉项目实战(原书第2版)
- OpenCV中的颜色空间
- 坑姐的项目:图像处理入门基础(一)
- 坑姐的项目:图像处理入门基础(二)
请点击此处查看本环境基本用法.
Please click here for more detailed instructions.