Flink JobManager 内存占用大 问题
Flink JobManager 内存占用大问题
问题描述
当在 本地启动一个 flink 简单的 job 时候,发现出现了 heap outMemeory 问题,
然后就不假思索的 调整了 jvm 的 heap -Xms1000m -Xmx16000m 参数,就可以正常的启动了。
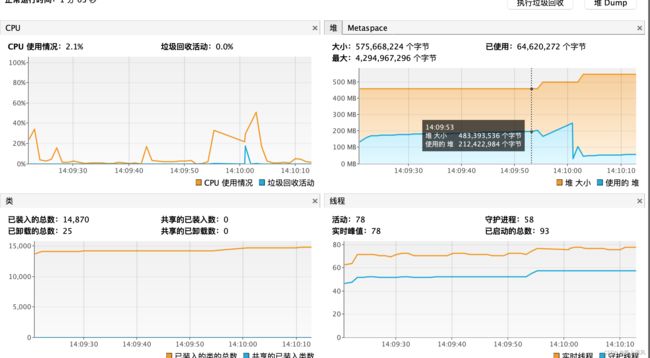
通过 jvisualvm 连接上 这个 jvm process,参看 堆大小 竟然达到了 4、5G。
解决过程
直到最近才有时间,来探究一下 到底 为什么 要占用 这么大的内存?
我们下 去掉 jvm 配置 的 heap -Xms1000m -Xmx16000m 参数,看看程序哪里报的错。
Exception in thread "main" com.yyb.flink.core.exception.StreamBasicException: Context submit error
at com.yyb.flink.core.context.AbstractContextProxy.submit(AbstractContextProxy.java:72)
at com.yyb.flink.core.context.AbstractContextProxy.submit(AbstractContextProxy.java:101)
at com.yyb.flink.app.table.dim.dataGen.JoinWithDataGenTable.main(JoinWithDataGenTable.java:39)
Caused by: org.apache.flink.util.FlinkException: Failed to execute job 'JoinWithDataGenTable'.
at org.apache.flink.streaming.api.environment.StreamExecutionEnvironment.executeAsync(StreamExecutionEnvironment.java:1969)
at org.apache.flink.streaming.api.environment.StreamExecutionEnvironment.execute(StreamExecutionEnvironment.java:1847)
at org.apache.flink.streaming.api.environment.LocalStreamEnvironment.execute(LocalStreamEnvironment.java:69)
at org.apache.flink.streaming.api.environment.StreamExecutionEnvironment.execute(StreamExecutionEnvironment.java:1833)
at com.yyb.flink.core.context.AbstractContextProxy.IfPresentSinkExecute(AbstractContextProxy.java:94)
at com.yyb.flink.core.context.AbstractContextProxy.submit(AbstractContextProxy.java:69)
... 2 more
Caused by: java.lang.RuntimeException: org.apache.flink.runtime.client.JobInitializationException: Could not start the JobMaster.
at org.apache.flink.util.ExceptionUtils.rethrow(ExceptionUtils.java:316)
at org.apache.flink.util.function.FunctionUtils.lambda$uncheckedFunction$2(FunctionUtils.java:75)
at java.util.concurrent.CompletableFuture.uniApply(CompletableFuture.java:602)
at java.util.concurrent.CompletableFuture$UniApply.tryFire(CompletableFuture.java:577)
at java.util.concurrent.CompletableFuture$Completion.exec(CompletableFuture.java:443)
at java.util.concurrent.ForkJoinTask.doExec(ForkJoinTask.java:289)
at java.util.concurrent.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1056)
at java.util.concurrent.ForkJoinPool.runWorker(ForkJoinPool.java:1692)
at java.util.concurrent.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:157)
Caused by: org.apache.flink.runtime.client.JobInitializationException: Could not start the JobMaster.
at org.apache.flink.runtime.jobmaster.DefaultJobMasterServiceProcess.lambda$new$0(DefaultJobMasterServiceProcess.java:97)
at java.util.concurrent.CompletableFuture.uniWhenComplete(CompletableFuture.java:760)
at java.util.concurrent.CompletableFuture$UniWhenComplete.tryFire(CompletableFuture.java:736)
at java.util.concurrent.CompletableFuture.postComplete(CompletableFuture.java:474)
at java.util.concurrent.CompletableFuture$AsyncSupply.run(CompletableFuture.java:1595)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$201(ScheduledThreadPoolExecutor.java:180)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:293)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.util.concurrent.CompletionException: java.lang.OutOfMemoryError: Java heap space
at java.util.concurrent.CompletableFuture.encodeThrowable(CompletableFuture.java:273)
at java.util.concurrent.CompletableFuture.completeThrowable(CompletableFuture.java:280)
at java.util.concurrent.CompletableFuture$AsyncSupply.run(CompletableFuture.java:1592)
... 7 more
Caused by: java.lang.OutOfMemoryError: Java heap space
at java.util.ArrayDeque.allocateElements(ArrayDeque.java:147)
at java.util.ArrayDeque.(ArrayDeque.java:203)
at org.apache.flink.runtime.executiongraph.failover.flip1.FailureRateRestartBackoffTimeStrategy.(FailureRateRestartBackoffTimeStrategy.java:59)
at org.apache.flink.runtime.executiongraph.failover.flip1.FailureRateRestartBackoffTimeStrategy$FailureRateRestartBackoffTimeStrategyFactory.create(FailureRateRestartBackoffTimeStrategy.java:153)
at org.apache.flink.runtime.scheduler.DefaultSchedulerFactory.createInstance(DefaultSchedulerFactory.java:97)
at org.apache.flink.runtime.jobmaster.DefaultSlotPoolServiceSchedulerFactory.createScheduler(DefaultSlotPoolServiceSchedulerFactory.java:110)
at org.apache.flink.runtime.jobmaster.JobMaster.createScheduler(JobMaster.java:340)
at org.apache.flink.runtime.jobmaster.JobMaster.(JobMaster.java:317)
at org.apache.flink.runtime.jobmaster.factories.DefaultJobMasterServiceFactory.internalCreateJobMasterService(DefaultJobMasterServiceFactory.java:107)
at org.apache.flink.runtime.jobmaster.factories.DefaultJobMasterServiceFactory.lambda$createJobMasterService$0(DefaultJobMasterServiceFactory.java:95)
at org.apache.flink.runtime.jobmaster.factories.DefaultJobMasterServiceFactory$$Lambda$1246/1142234774.get(Unknown Source)
at org.apache.flink.util.function.FunctionUtils.lambda$uncheckedSupplier$4(FunctionUtils.java:112)
at org.apache.flink.util.function.FunctionUtils$$Lambda$1247/405573242.get(Unknown Source)
at java.util.concurrent.CompletableFuture$AsyncSupply.run(CompletableFuture.java:1590)
... 7 more
然后我们找到 代码所在的位置:
FailureRateRestartBackoffTimeStrategy.class
FailureRateRestartBackoffTimeStrategy(
Clock clock, int maxFailuresPerInterval, long failuresIntervalMS, long backoffTimeMS) {
checkArgument(
maxFailuresPerInterval > 0,
"Maximum number of restart attempts per time unit must be greater than 0.");
checkArgument(failuresIntervalMS > 0, "Failures interval must be greater than 0 ms.");
checkArgument(backoffTimeMS >= 0, "Backoff time must be at least 0 ms.");
this.failuresIntervalMS = failuresIntervalMS;
this.backoffTimeMS = backoffTimeMS;
this.maxFailuresPerInterval = maxFailuresPerInterval;
this.failureTimestamps = new ArrayDeque<>(maxFailuresPerInterval); //这里
this.strategyString = generateStrategyString();
this.clock = checkNotNull(clock);
}
ArrayDeque.class
public ArrayDeque(int numElements) {
allocateElements(numElements);
}
private void allocateElements(int numElements) {
elements = new Object[calculateSize(numElements)]; //这里
}
可以知道,如果这个 numElements、maxFailuresPerInterval 设置的 比较大的话,那么这里就会直接 申请 这么大 的 object数组,就有可能 heap OutOfMemoryError。
回想到 我们曾经 设置 flink FailureRateRestartStrategyConfiguration 的 次数 为 Integer.MAX_VALUE,那么就 将通了。
为什么要设置这么大的失败重启次数,当时是因为 下载 s3文件,时不时会出现 timeOut 问题,所以 flink 的 FailureRateRestartStrategyConfiguration 设置为 Integer.MAX_VALUE,没有想到 致使 jobManager 的 内存占用 变得这么大了。
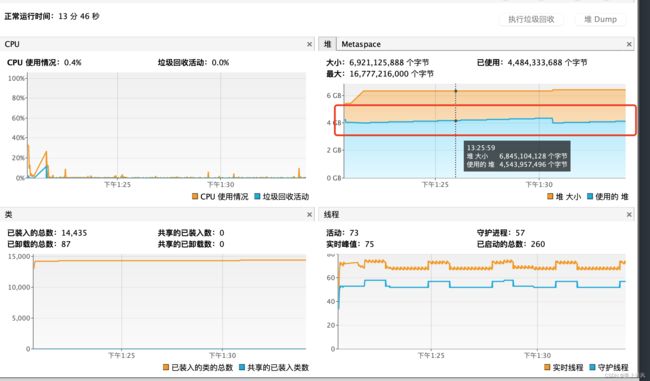
解决效果
设置 FailureRateRestartStrategyConfiguration 的 次数 为 3

设置 FailureRateRestartStrategyConfiguration 的 次数 为 10000.