多层感知机(MLP)
多层感知机(MLP)
文章目录
- 多层感知机(MLP)
-
- 线性函数
- 激活函数
-
- 1.为什么要使用激活函数
- 2. 激活函数需要具备的性质:
- 3.常用的激活函数
-
- ReLU
- sigmoid
- tanh
- 多层感知机
-
- 隐藏层
- 单隐藏层多分类问题
-
- Softmax
- 多隐藏层
- pytorch的使用
-
- 线性模型
-
- 问题引入
-
- 模型设计
- 损失函数
- 梯度下降
- 优化器
- 训练过程
- 整体代码
线性函数
y=kx+b
一元一次方程
激活函数
1.为什么要使用激活函数
a. 不使用激活函数,每一层输出都是上层输入的线性函数,无论神经网络有多少层,输出都是输入的线性组合。
b. 使用激活函数,能够给神经元引入非线性因素,使得神经网络可以任意逼近任何非线性函数,这样神经网络就可以利用到更多的非线性模型中。
2. 激活函数需要具备的性质:
a.连续并可导(允许少数点上不可导)的非线性函数。可导的激活函数可以直接利用数值优化的方法来学习网络参数。
b.激活函数及其导函数要尽可能的简单,有利于提高网络计算效率。
c.激活函数的导函数的值域要在一个合适的区间内,不能太大也不能太小,否则会影响训练的效率和稳定性。
3.常用的激活函数

ReLU
y = torch.relu(x)
sigmoid



tanh
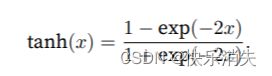


多层感知机
隐藏层
我们可以通过在网络中加入一个或多个隐藏层来克服线性模型的限制, 使其能处理更普遍的函数关系类型。 要做到这一点,最简单的方法是将许多全连接层堆叠在一起。 每一层都输出到上面的层,直到生成最后的输出。 我们可以把前L−1层看作表示,把最后一层看作线性预测器。 这种架构通常称为多层感知机(multilayer perceptron),通常缩写为MLP。

单隐藏层多分类问题

Softmax
、
多隐藏层


pytorch的使用
线性模型
问题引入
以知小明1小时打2行代码,2分钟4行,3分钟6行,问:4分钟打几行代码?
| x | y | |
|---|---|---|
| 1 | 2 | |
| 2 | 4 | |
| 3 | 6 | |
| 4 | ? |
import torch
#数据作为矩阵参与Tensor计算
x_data = torch.Tensor([1.0],[2.0],[3.0])
y_data = torch.Tensor([2.0],[4.0],[6.0])
模型设计
设y = w * x +b
pytorch代码
#固定继承于Module
class LinearModel(torch.nn.Module):
#构造函数初始化
def __init__(self):
#调用父类的init
super(LinearModel, self).__init__()
#Linear对象包括weight(w)以及bias(b)两个成员张量
self.linear = torch.nn.Linear(1,1)
#前馈函数forward,对父类函数中的overwrite
def forward(self, x):
#调用linear中的call(),以利用父类forward()计算wx+b
y_pred = self.linear(x)
return y_pred
#反馈函数backward由module自动根据计算图生成
损失函数


criterion = torch.nn.MSELoss(size_average=False)





梯度下降
ω = ω − α ∂ c o s t ∂ ω \omega = \omega - \alpha \frac{\partial cost}{\partial \omega} ω=ω−α∂ω∂cost
优化器
#model.parameters()用于检查模型中所能进行优化的张量
#learningrate(lr)表学习率,可以统一也可以不统一
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
训练过程
for epoch in range(100):
#前馈计算y_pred
y_pred = model(x_data)
#前馈计算损失loss
loss = criterion(y_pred,y_data)
#打印调用loss时,会自动调用内部__str__()函数,避免产生计算图
print(epoch,loss)
#梯度清零
optimizer.zero_grad()
#梯度反向传播,计算图清除
loss.backward()
#根据传播的梯度以及学习率更新参数
optimizer.step()
整体代码
import torch
#数据作为矩阵参与Tensor计算
x_data = torch.Tensor([[1.0],[2.0],[3.0]])
y_data = torch.Tensor([[2.0],[4.0],[6.0]])
#固定继承于Module
class LinearModel(torch.nn.Module):
#构造函数初始化
def __init__(self):
#调用父类的init
super(LinearModel, self).__init__()
#Linear对象包括weight(w)以及bias(b)两个成员张量
self.linear = torch.nn.Linear(1,1)
#前馈函数forward,对父类函数中的overwrite
def forward(self, x):
#调用linear中的call(),以利用父类forward()计算wx+b
y_pred = self.linear(x)
return y_pred
#反馈函数backward由module自动根据计算图生成
model = LinearModel()
#构造的criterion对象所接受的参数为(y',y)
criterion = torch.nn.MSELoss(size_average=False)
#model.parameters()用于检查模型中所能进行优化的张量
#learningrate(lr)表学习率,可以统一也可以不统一
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
for epoch in range(1000):
#前馈计算y_pred
y_pred = model(x_data)
#前馈计算损失loss
loss = criterion(y_pred,y_data)
#打印调用loss时,会自动调用内部__str__()函数,避免产生计算图
print(epoch,loss)
#梯度清零
optimizer.zero_grad()
#梯度反向传播,计算图清除
loss.backward()
#根据传播的梯度以及学习率更新参数
optimizer.step()
#Output
print('w = ', model.linear.weight.item())
print('b = ', model.linear.bias.item())
#TestModel
x_test = torch.Tensor([[4.0]])
y_test = model(x_test)
print('y_pred = ',y_test.data)
学习率更新参数
optimizer.step()
#Output
print('w = ', model.linear.weight.item())
print('b = ', model.linear.bias.item())
#TestModel
x_test = torch.Tensor([[4.0]])
y_test = model(x_test)
print('y_pred = ',y_test.data)