HDFS的xshell基本操作
首先打开虚拟机centos以及他的三个克隆机,并打开xshell连接到这四台虚拟机。
![]()
![]() 到此就已成功打开和连接。
到此就已成功打开和连接。
然后在xshell中连接的主机centos7上输入如下命令打开集群:(一条一条的输入)
cd /opt/hadoop-3.1.4/sbin
./start-dfs.sh
./start-yarn.sh
./mr-jobhistory-daemon.sh start historyserver
jps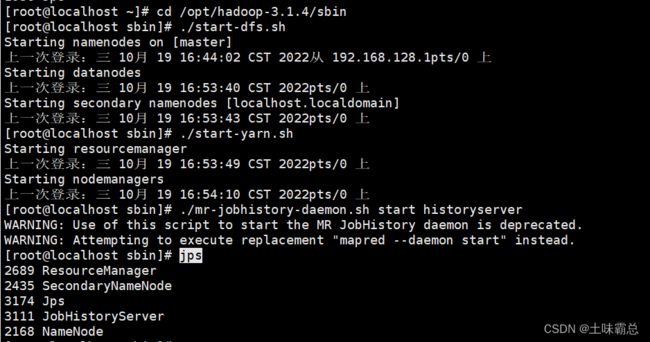
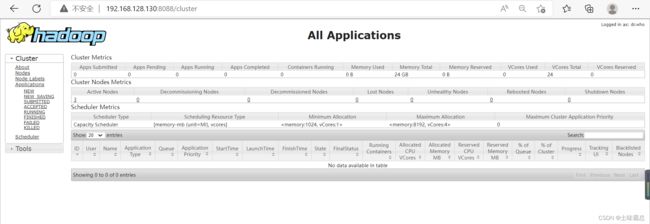
接下来使用下面三个网站可以看到自己操作之后在hadoop上面的改变,其中链接中的ip地址是自己的虚拟机地址,每个人不一定相同。
http://192.168.128.130:50070/dfshealth.html#tab-overview

http://192.168.128.130:8088/cluster
http://192.168.128.130:19888/jobhistory
 启动集群之后就可以开始使用hadoop的命令了。
启动集群之后就可以开始使用hadoop的命令了。
1. 查看指令 ls
hdfs dfs -ls [-h] [-R]
path 指定目录路径
-R 递归查看指定目录及其子目录
调用格式: hdfs dfs -ls /目录
(1)查看根目录:
hdfs dfs -ls / (2)递归查看所有目录以及目录的子目录:
(2)递归查看所有目录以及目录的子目录:
hdfs dfs -ls -R /
2. 创建目录 mkdir
hdfs dfs -mkdir [-p]
path 为待创建的目录
-p选项的行为与linux mkdir -p非常相似,它会沿着路径创建父目录
调用格式: hdfs dfs -mkdir (-p) /目录
(1)创建一个目录,假设创建名为dir1的目录,创建之后使用ls相关命令查看我们所创建的目录:
hdfs dfs -mkdir /dir1
hdfs dfs -ls / (2)递归创建父目录 ,依旧使用ls相关命令进行查看:
(2)递归创建父目录 ,依旧使用ls相关命令进行查看:
hdfs dfs -mkdir -p /dir2/dir22
hdfs dfs -ls / 除此之外还可以使用我前面给的连接进行查看(再次注意,每一个人的ip地址不同,对应的链接中的地址也不一样)。
除此之外还可以使用我前面给的连接进行查看(再次注意,每一个人的ip地址不同,对应的链接中的地址也不一样)。
使用如下方法进行查看:

然后在这里面就可以看到我们刚才所创建的文件夹dir1和dir2:
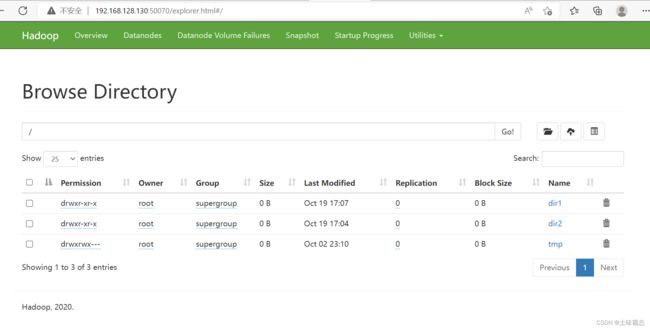 点击dir2可以进入dir2文件,并且看到刚才创建的dir22文件夹:
点击dir2可以进入dir2文件,并且看到刚才创建的dir22文件夹:
![]()
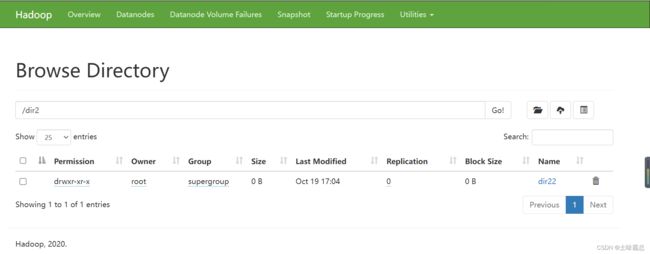 在状态栏中将/dir2改成/回到根目录 :
在状态栏中将/dir2改成/回到根目录 :
3. 上传指令 put
hdfs dfs -put [-f] [-p]
将本地文件系统的文件上传到分布式文件系统
-f 覆盖目标文件(已存在下)
-p 保留访问和修改时间,所有权和权限
localsrc 本地文件系统(客户端所在机器)
dst 目标文件系统(HDFS)
调用格式:hdfs dfs -put /本地文件 /目的目录
(注意:所有节点的防火墙都要关闭,不然可能会上传失败。同时put是拷贝原文件,意味着原文件依旧存在。)
(1)首先使用touch创建一个txt文件,这个文件是在本地系统里面的。然后向创建的txt文件中编辑一些文字。然后再使用put命令将这个本地系统的文件上传到hdfs系统中。
touch b.txt
ls
vi b.txt
hdfs dfs -put b.txt /dir1 但是我这里报错了,并没有上传成功,他说没有找到主机的路由:
但是我这里报错了,并没有上传成功,他说没有找到主机的路由:
 然后我才发现,是我的防火墙没有关闭完,需要对所有的节点都关闭防火墙,我之前只是在创建hadoop集群的时候关闭了主节点的防火墙,而没有关闭三个克隆机的节点。使用如下命令关闭三个克隆机的防火墙。
然后我才发现,是我的防火墙没有关闭完,需要对所有的节点都关闭防火墙,我之前只是在创建hadoop集群的时候关闭了主节点的防火墙,而没有关闭三个克隆机的节点。使用如下命令关闭三个克隆机的防火墙。
systemctl status firewalld.service
systemctl stop firewalld.service & systemctl disable firewalld.service 然后再次在主节点使用put命令上传txt文件,当没有反应就上传成功了。
然后再次在主节点使用put命令上传txt文件,当没有反应就上传成功了。
![]() 具体的我们可以到50070查看,我们看到在dir1目录下已经有了b.txt文件:
具体的我们可以到50070查看,我们看到在dir1目录下已经有了b.txt文件:

4. 上传指令 moveFromLocal
本地文件系统的文件上传到分布式文件系统
调用格式:同put
注意:这里是将本地文件剪切到分布式文件系统,意味着原文件就没有了。
我在xshell中输入如下命令进行文件的上传剪切,发现他报错:
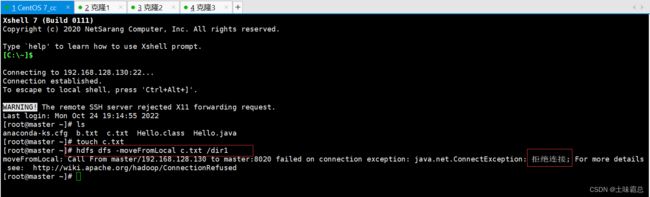
原因就是因为我在写这篇文章的时候间隔了很久,我中途把虚拟机关了的,而我现在重新打开虚拟机,并用xshell连接上虚拟机之后就直接开始输入命令了,这说明,我在进行操作之前没有将打开集群。而hadoop的命令实现是需要先打开Hadoop集群的。所以我用这篇文章开始的命令打开集群再进行操作之后就不会报错了。

然后继续使用下面的命令将文件剪切上传到分布式文件系统的dir1目录下,也就是hadoop集群中:
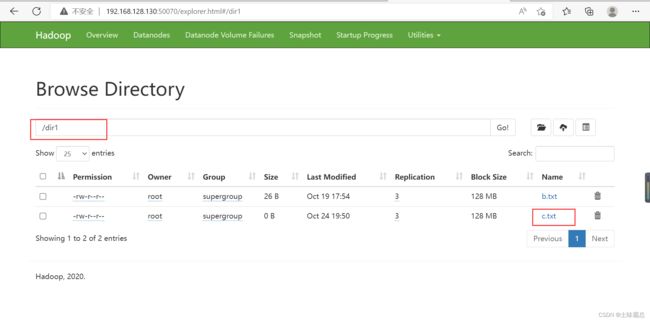
hdfs dfs -moveFromLocal c.txt /dir1首先我先查看了原本根目录下的文件,在剪切上传之后又查看了一边,发现根目录下已经没有c.txt了,而在dir1的目录下面有了c.txt文件。

 5. 下载文件 get
5. 下载文件 get
hdfs dfs -get [-f] [-p]
下载文件到本地文件系统指定目录,localdst必须是目录
-f 覆盖目标文件(已存在下)
-p 保留访问和修改时间,所有权和权限
使用下面的命令将dir1目录下的c.txt下载到目录/中,即根目录:
hdfs dfs -get /dir1/c.txt /![]()
6. 移动数据 mv
hdfs dfs -mv
移动文件到指定文件夹下
可以使用该命令移动数据,重命名文件的名称
具体使用的命令如下,将dir1文件夹下的c.txt文件移动到dir2文件夹下面:
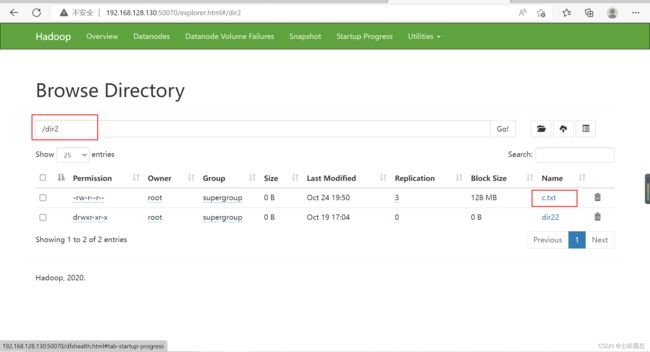
hdfs dfs -mv /dir1/c.txt /dir2![]()
最后在dir2文件夹中发现有了c.txt:
 7. 删除文件 rm
7. 删除文件 rm
hdfs dfs -rm [-r] [-skipTrash]
注意:如果删除文件夹需要加-r
使用下面的命令删除文件夹dir2下面的c.txt文件:
hdfs dfs -rm /dir2/c.txt使用命令删除文件夹dir2:
hdfs dfs -rm -r /dir2删除之后,在网页50070中可以发现文件夹dir2已经不存在了。

8. 拷贝文件 cp
hdfs dfs -cp [-f] [-p]
将文件拷贝到目标路径中
-f 覆盖目标文件(已存在下)
-p 保留访问和修改时间,所有权和权限
下面我将要把b.txt文件拷贝到dir2文件夹中,首先要先将文件b.txt使用put命令上传到分布式文件系统中,然后在进行拷贝。由于我前面的操作把文件夹dir2删除了,所以在拷贝之前我还需要使用mkdir命令重新创建一个dir2文件夹。命令如下:
hdfs dfs -put b.txt /
hdfs dfs -mkdir /dir2
hdfs dfs -cp /dir1/b.txt /dir2
9. 查看文件内容 cat
hdfs dfs -cat
读取指定文件全部内容,显示在标准输出控制台
注意:对于大文件内容读取,慎重
hdfs dfs -cat /b.txt
10. 追加数据到HDFS文件中 appendToFile
hdfs dfs -appendToFile
将所有给定本地文件的内容追加到给定dst文件
dst如果文件不存在,将创建该文件
hdfs dfs -appendToFile
注:HDFS适合存储大文件,appendToFile 可以实现对小文件进行一个合并。
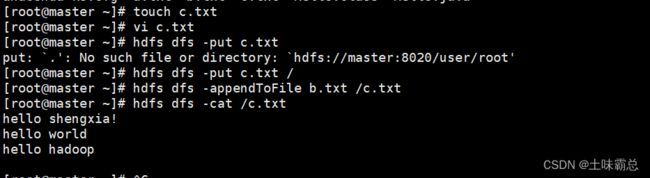
首先用touch创建一个c.txt的文件,然后使用vi命令向文件夹中写入一些语句;最重要的是,要将该文件使用put命令上传到Hadoop系统中。然后再进行数据追加的操作,不然可能输出的内容不对,具体命令如下:
touch c.txt
vi c.txt
cat c.txt
cat b.txt
hdfs dfs -put c.txt /
hdfs dfs -appendToFile b.txt /c.txt
hdfs dfs -cat /c.txt
具体结果如下: