使用Mahout实现基于用户的协同过滤(user-based CF)算法/Mahout推荐系统入门实践
- Mahout简介
Mahout是 Apache Software Foundation(ASF)旗下的一个开源项目,提供一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序。Mahout包含许多实现,包括聚类、分类、推荐过滤、频繁子项挖掘。此外,通过使用Apache Hadoop库,Mahout可以有效地扩展到云中。
官网链接:https://mahout.apache.org

Mahout可实现的机器学习算法如下表所示:
| 算法类型 |
算法名称 |
中文名称 |
| 分类算法 |
Logistic Regression |
逻辑回归 |
| Bayesian |
贝叶斯 |
|
| SVM |
支持向量机 |
|
| Perceptron |
感知器算法 |
|
| Neural Network |
神经网络 |
|
| Random Forests |
随机森林 |
|
| Restricted Boltzmann Machines |
有限波尔兹曼机 |
|
| 聚类算法 |
Canopy Clustering |
Canopy聚类 |
| K-means Clustering |
K均值算法 |
|
| Fuzzy K-means |
模糊K均值 |
|
| Expectation Maximization |
EM聚类(期望最大化聚类) |
|
| Mean Shift Clustering |
均值漂移聚类 |
|
| Hierarchical Clustering |
层次聚类 |
|
| Dirichlet Process Clustering |
狄里克雷过程聚类 |
|
| Latent Dirichlet Allocation |
LDA聚类 |
|
| Spectral Clustering |
谱聚类 |
|
| 关联规则挖掘 |
Parallel FP Growth Algorithm |
并行FP Growth算法 |
| 回归 |
Locally Weighted Linear Regression |
局部加权线性回归 |
| 降维/维约简 |
Singular Value Decomposition |
奇异值分解 |
| Principal Components Analysis |
主成分分析 |
|
| Independent Component Analysis |
独立成分分析 |
|
| Gaussian Discriminative Analysis |
高斯判别分析 |
|
| 进化算法 |
并行化了Watchmaker框架 |
|
| 推荐/协同过滤 |
Non-distributed recommenders |
Taste(UserCF,ItemCF,SlopeOne) |
| Distributed Recommenders |
ItemCF |
|
| 向量相似度计算 |
RowSimilarityJob |
计算列间相似度 |
| VectorDistanceJob |
计算向量间距离 |
|
| 非Map-Reduce算法 |
Hidden Markov Models |
隐马尔科夫模型 |
| 集合方法扩展 |
Collections |
扩展了java的Collections类 |
- Mahout源码目录说明

buildtools:buildtools目录下是用于核心程序构建的配置文件,以mahout-buildtools的模块名称在mahout的pom.xml文件中进行说明;
bin:bin目录下只有一个名为mahout的文件,是一个shell脚本文件,用于在hadoop平台的命令行下调用mahout中的程序;
mahout-core:核心程序模块;
mahout-math:在核心程序中使用的一些数据通用计算模块;
distribution:distribution目录下有两个配置文件:bin.xml和src.xml,保存了mahout安装时的一些配置信息;
examples:对mahout中各种机器学习算法的应用程序。

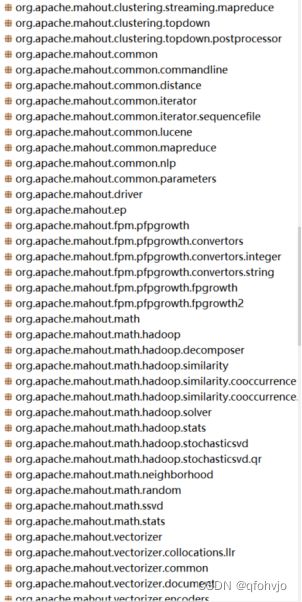
common:公共类包:异常、数据刷新接口、权重常量;
model: 定义数据模型接口;
neighborhood: 定义近邻算法的接口;
recommender: 定义推荐算法的接口;
similarity: 定义相似度算法的接口;
hadoop: 基于hadoop的分步式算法的实现类;
impl: 单机内存算法实现类。
- Mahout环境搭建
主机环境:Windows 10专业版、Java(TM) SE Runtime Environment (build 1.8.0_221-b11)、Java HotSpot(TM) 64-Bit Server VM (build 25.221-b11, mixed mode)、Eclipse 2018-12、Apache Maven 3.8.5。
首先安装Eclipse Luna插件。
下载m2e。
下载之前可以修改eclipse.ini中JVM最大可用内存,不然很可能出现java.lang.OutOfMemoryError:Java heap space的问题。

检验m2e是否已安装成功。
新建Maven项目。



在官网下载mahout的jar包。
下载地址:http://archive.apache.org/dist/mahout/0.9/

将相关的jar包导入项目中。

环境搭建完毕。
使用Mahout实现基于用户的协同过滤(user-based CF)算法
协同过滤(collaboratIve filtering)是目前最经典且常用的推荐算法,它基于对用户历史行为数据的挖掘发现用户的喜好偏向,并预测用户可能喜好的产品进行推荐。协同是指通过兴趣相似的群体喜好找到用户可能喜欢的物品,过滤是指过滤掉一些不值得推荐的数据。协同过滤算法可以根据与用户具有共同喜好的用户进行推荐,可以根据用户喜欢的物品来为用户推荐相似的物品,也可以综合推荐。
协同过滤推荐算法分为三种类型。第一种是基于用户(user-based)的协同过滤算法,第二种是基于项目(item-based)的协同过滤算法,第三种是基于模型(model-based)的协同过滤。
下面介绍基于用户(user-based)的协同过滤算法。
基于用户的协同过滤算法步骤如下:
第一步:收集代表用户兴趣的信息,一般是用户对物品的评价;
第二步:计算目标用户的(前k个)相似用户(neighborhood);
第三步:找出相似用户喜欢的物品,并预测目标用户对这些物品的评分;
第四步:过滤掉目标用户已经拥有的物品;
第五步:将剩余物品按照预测评分排序,返回前n个物品。
计算相似度可以用到以下方法:
1.杰卡德相似系数(Jaccard similarity coefficient)
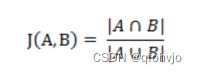
2.夹角余弦(Cosine)
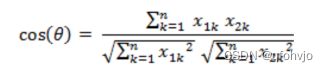
3.欧式距离(Euclidean Distance)
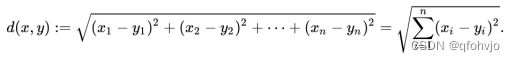
依据推荐目的的不同可以选择进行不同形式的推荐,较常见的推荐结果有Top-N推荐和关系推荐。Top-N推荐是针对个体用户产生,对每个人产生不一样的结果。关系推荐是对最近邻用户的记录进行关系规则(association rules)挖掘。
下面介绍如何使用Mahout实现基于用户的协同过滤算法:
首先新建数据文件item.csv。
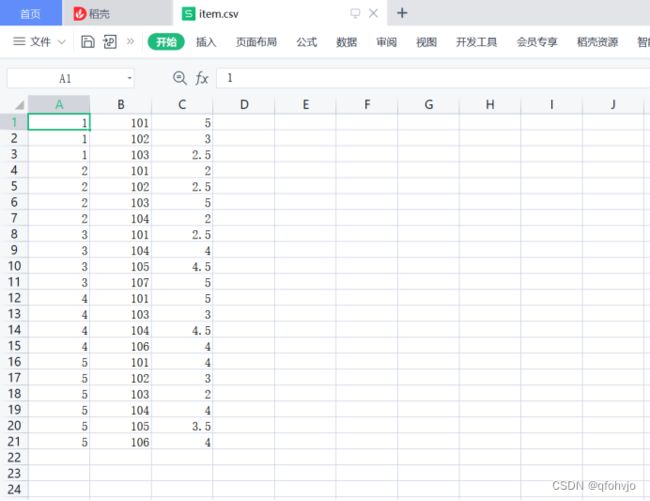
该数据第一列表示用户ID,第二列表示物品ID,第三列表示用户对物品的评分。
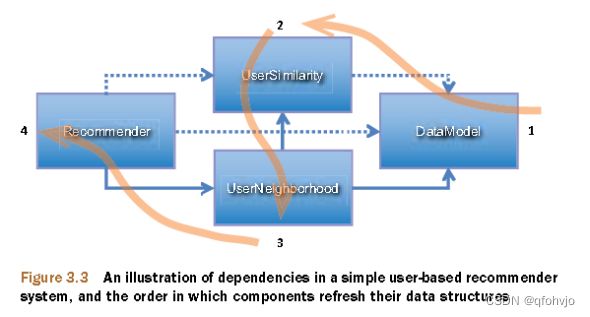
下图为Mahout基于用户的协同过滤的调用流程:
新建Java类MyCF.java,代码如下:
package com.zqq.mahout.zhangqiqi;
import java.io.File;
import java.io.IOException;
import java.util.List;
import org.apache.mahout.cf.taste.common.TasteException;
import org.apache.mahout.cf.taste.impl.common.LongPrimitiveIterator;
import org.apache.mahout.cf.taste.impl.model.file.FileDataModel;
import org.apache.mahout.cf.taste.impl.neighborhood.NearestNUserNeighborhood;
import org.apache.mahout.cf.taste.impl.recommender.GenericUserBasedRecommender;
import org.apache.mahout.cf.taste.impl.similarity.EuclideanDistanceSimilarity;
import org.apache.mahout.cf.taste.model.DataModel;
import org.apache.mahout.cf.taste.recommender.RecommendedItem;
import org.apache.mahout.cf.taste.recommender.Recommender;
import org.apache.mahout.cf.taste.similarity.UserSimilarity;
public class MyCF {
final static int NEIGHBORHOOD_NUM = 2;//相似用户个数
final static int RECOMMENDER_NUM = 3;//推荐物品个数
public static void main(String[] args) throws IOException, TasteException {
String file = "C:\\Users\\1\\Desktop\\item.csv";
DataModel model = new FileDataModel(new File(file));
UserSimilarity user = new EuclideanDistanceSimilarity(model);//利用欧式距离定义相似度
NearestNUserNeighborhood neighbor = new NearestNUserNeighborhood(NEIGHBORHOOD_NUM, user, model);//基于用户的推荐算法
Recommender r = new (model, neighbor, user);
LongPrimitiveIterator iter = model.getUserIDs();
while (iter.hasNext()) {
long uid = iter.nextLong();
List list = r.recommend(uid, RECOMMENDER_NUM);
System.out.printf("uid:%s", uid);
for (RecommendedItem ritem : list) {
System.out.printf("(%s,%f)", ritem.getItemID(), ritem.getValue());
}
System.out.println();
}
}
}
运行结果如下图所示:
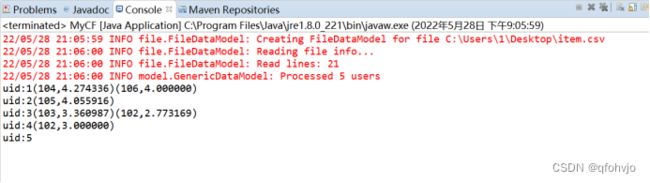
运行结果说明:
为用户1推荐3个相关的物品,但只有104和106这2个物品被推荐;
为用户2推荐3个相关的物品,但只有105这1个物品被推荐;
为用户3推荐3个相关的物品,但只有103和102这2个物品被推荐;
为用户4推荐3个相关的物品,但只有102这1个物品被推荐;
为用户5推荐3个相关的物品,没有可推荐的物品。
---------------------------------------------------------------------------------
本文参考了许多博主的文章,但是当时没有记录链接,实在抱歉!