- 计算机程序制作的小作品,义乌市中小学生电脑作品制作比赛201203
东南前哨
计算机程序制作的小作品
《义乌市中小学生电脑作品制作比赛201203》由会员分享,可在线阅读,更多相关《义乌市中小学生电脑作品制作比赛201203(4页珍藏版)》请在人人文库网上搜索。1、浙江省义乌市教育研修院关于举办2012年义乌市中小学生电脑作品制作比赛暨首届青少年网络道德建设专题创作活动的通知各中小学:为进一步推进和加强中小学信息技术教育,普及信息技术知识,培养学生创新精神和实践能力,提高信息技术水平,根据上级文件
- Python 舆论风向分析爬虫:全流程数据获取、清洗与情感剖析
西攻城狮北
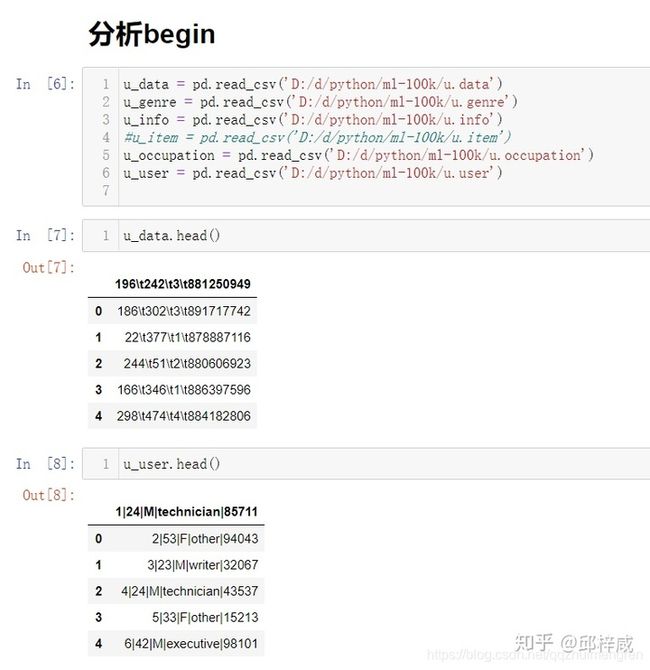
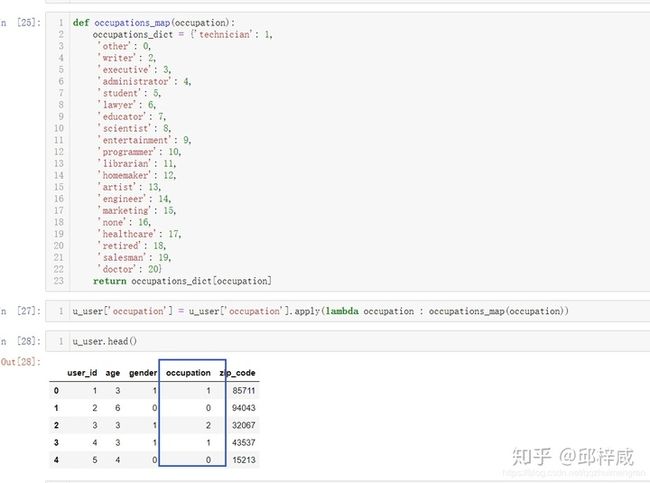
python爬虫开发语言实战案例
引言在当今信息爆炸的时代,互联网上充斥着海量的用户言论和观点。了解舆论风向对于企业、政府机构以及研究者等具有重要的意义,可以帮助他们及时把握公众情绪、调整策略与决策。Python作为一种强大的编程语言,在数据爬取与分析方面具有得天独厚的优势,能够助力我们高效地实现舆情监测与深入剖析。一、环境搭建与目标确定1.环境搭建为了顺利完成爬虫与数据分析任务,首先需要确保你的开发环境已经安装了以下Python
- 【HarmonyOS Next】鸿蒙监听手机按键
GeorgeGcs
HarmonyOS解决方案OpenHarmony知识体系harmonyos华为onKeyEvent按键监听事件按下鸿蒙
【HarmonyOSNext】鸿蒙监听手机按键一、前言应用开发中我们会遇到监听用户实体按键,或者扩展按键的需求。亦或者是在某些场景下,禁止用户按下某些按键的业务需求。这两种需求,鸿蒙都提供了对应的监听事件进行处理。onKeyEvent默认的按钮监听事件onKeyPreIme这是优先级最高的监听回调,别上面多了一个return开关,用于告诉系统监听事件是否再向下传递。窗口是第一级接收按钮事件的实体。
- 【vue】Mammoth.js的使用:将.docx转换成HTML
暴富暴富暴富啦啦啦
1024程序员节
mammoth.convertToHtml(input,options):把源文档转换为HTML文档mammoth.convertToMarkdown(input,options):把源文档转换为Markdown文档。mammoth.extractRawText(input):提取文档的原始文本。这将忽略文档中的所有格式。每个段落后跟两个换行符。npminstallelement-uimammot
- 麒麟v10安装mysql5.7(ARM架构)
qqxinxi
arm开发
下载路径:华为云镜像麒麟v10是潮流时代的新时髦的linux操作系统,但随着ARM架构流行,出现了一些卡点,不以为然,没当回事的大吃一惊。经常卡住。例如:在安装mysql5.7(ARM架构)最简单:使用rpmmysql-5.7.27.1.el7.aarch64.rpm文件比较小下载完之后rpm-ivhmysql-5.7.27.1.el7.aarch64.rpm比较简单常用的方法,再不能连接互联网时
- YOLOv8 Pose使用RKNN进行推理
い不靠譜︶朱Sir
实用项目部署YOLO人工智能pythonlinuxpip
关注微信公众号:朱sir的小站,发送202411081即可免费获取源代码下载链接一、简单介绍YOLOv8-Pose是一种基于YOLOv8架构的姿态估计模型,能够识别图像中的关键点位置,这些关键点通常表示人体的关节、特征点或其他显著位置。该模型在COCO关键点数据集上训练,适合多种姿势估计任务。二、ONNX推理1.首先需要先将Pytorch模型转换为Onnx模型,下载pt模型这里给出官方的权重下载地
- PyCharm 集成 DeepSeek:本地运行 or API 直连?打造你的 AI 编程神器!
AI云极
【AI智能系列】pycharm人工智能idedeepseek
在AI赋能编程的时代,如何让AI辅助写代码,提升开发效率?DeepSeek作为一款开源、强大、免费的AI编程助手,结合PyCharm,能够大幅提升Python编程体验。今天,我们就来详细讲解如何在PyCharm中接入DeepSeek,无论你想使用本地部署的DeepSeek,还是官方API版本,都能轻松实现!为什么选择DeepSeek+PyCharm?DeepSeekR1采用6710亿参数的MoE(
- Python3.5源码分析-sys模块及site模块导入
小屋子大侠
pythonPython分析python源码
Python3源码分析本文环境python3.5.2。参考书籍>python官网Python3的sys模块初始化根据分析完成builtins初始化后,继续分析sys模块的初始化,继续分析_Py_InitializeEx_Private函数的执行,void_Py_InitializeEx_Private(intinstall_sigs,intinstall_importlib){...sysmod=
- RealtimeSTT:实时语音转文本的开源神器,轻松实现高效语音处理
AI云极
【开源系列】语音识别开源
在语音技术飞速发展的时代,实时语音转文本(Speech-to-Text,简称STT)技术已逐渐成为语音助手、在线会议记录、字幕生成等应用的核心功能。今天要为大家推荐的是一款开源的实时语音转文本工具——RealtimeSTT,它功能强大且易于集成,为开发者提供了快速构建实时语音处理应用的能力。项目地址:GitHub-RealtimeSTT一、什么是RealtimeSTT?RealtimeSTT是一款
- java竞赛优化输入输出效率
px不是xp
蓝桥准备java开发语言
在编程竞赛中,输入输出效率至关重要。Java的`Scanner`和`System.out.println`虽然简单,但在处理大规模数据时会严重拖慢速度。以下是**竞赛专用输入输出模板**及其原理详解,助你轻松应对高频I/O场景。---###⚡竞赛级输入输出模板(Java)importjava.io.*;importjava.util.*;publicclassMain{ publicstatic
- 快速复制A库表数据前10000行到B库
musk1212
数据库sqlmysql
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档文章目录应用场景一、存储过程,快速复制A库表数据前10000行到B库二、使用优化点说明结构优化性能调整错误处理增强安全改进调用示例应用场景表结构可预先存在或不存在mysql5.7快速复制A库表数据前10000行到B库一、存储过程,快速复制A库表数据前10000行到B库/*设置自定义分隔符以处理存储过程中的分号*/DELIMITER$$
- 4070与3070ti显卡性能对比:哪款更适合您的需求?
mmoo_python
windows
4070与3070ti显卡性能对比:哪款更适合您的需求?在高性能显卡市场中,4070和3070ti无疑是两款备受瞩目的产品。它们专为那些对游戏或其他图形密集型任务有高要求的用户而设计,提供了卓越的性能和体验。然而,尽管这两款显卡都拥有强大的性能,但它们在某些方面仍有所不同。本文将详细对比4070和3070ti显卡,以帮助您根据自己的需求做出明智的选择。一、性能对比:3070ti略胜一筹首先,我们来
- HarmonyOS进程通信及原理
拥有一颗学徒的心
HarmonyOSharmonyos华为鸿蒙信息与通信分布式
大家好,我是学徒小z,最近在研究鸿蒙中一些偏底层原理的内容,今天分析进程通信给大家,请用餐文章目录进程间通信1.通过公共事件(@ohos.commonEventManager)公共事件的底层原理2.IPCKit能力LiteIPC的归属与特点1.所属内核2.核心思想3.公共事件子系统鸿蒙内核小知识进程间通信1.通过公共事件(@ohos.commonEventManager)公共事件的底层原理公共事件
- 深入了解 CDN:概念、原理、过程、作用及工作场景
羊村懒哥
网络网络加速缓存
目录一、CDN的概念二、CDN的工作原理三、CDN的工作过程四、CDN的作用五、CDN可结合使用的技术六、CDN能够解决的网络问题七、CDN的工作场景在当今互联网飞速发展的时代,用户对于网页加载速度和内容获取的时效性要求越来越高。CDN(ContentDeliveryNetwork,⭐内容分发网络)应运而生,它在提升网络性能和用户体验方面发挥着关键作用。本文将详细介绍CDN的概念、工作原理、工作过
- OpenLayers总结3
Super毛毛穗
WebGIS开发OpenLayersGISWebGIS
一、静态测距1.原理静态测距主要是针对地图上已有的矢量要素(如线要素),利用OpenLayers提供的几何计算函数来获取其长度。在实际操作中,先加载包含几何要素的GeoJSON数据到矢量图层,当鼠标指针移动到要素上时,获取该要素的几何信息,再调用getLength函数计算其长度。2.代码实现步骤及注释//引入必要的模块importVectorLayerfrom"ol/layer/Vector.js
- vue3-video-play 插件在 Vue 3 项目上的应用
放逐者-保持本心,方可放逐
vue3应用vue.js前端javascriptvue3-video-play
文章目录vue3-video-play插件在Vue3项目上的应用一、插件简介二、插件安装三、插件组件应用示例1.局部引入组件2.全局引入组件四、需要注意的事项五、本地环境将`package.json`中`"module":"./dist/index.es.js"`改为`"module":"./dist/index.mjs"`问题解析探索问题描述原因分析解决方案格式及应用实例vue3-video-p
- 【CUDA】Pytorch_Extensions
joker D888
深度学习pytorchpythoncudac++深度学习
【CUDA】Pytorch_Extensions为什么要开发CUDA扩展?当我们在PyTorch中实现自定义算子时,通常有两种选择:使用纯Python实现(简单但效率低)使用C++/CUDA扩展(高效但需要编译)对于计算密集型的操作(如神经网络中的自定义激活函数),使用CUDA扩展可以获得接近硬件极限的性能。本文将以实现一个多项式激活函数x²+x+1为例,展示完整的开发流程。完整CUDA扩展代码解
- 散热风扇常见的调速方式有哪几种
辉盈防爆散热风扇
其他
在现代电子设备中,散热风扇扮演着至关重要的角色,它们通过高效的空气流动帮助设备排热,保障设备的稳定运行。而散热风扇的调速方式,则是影响其散热效率和使用寿命的关键因素。那么,散热风扇如何调速?有哪几种调速方式?1.PWM(脉冲宽度调制)调速是有一个专用的PWM调速操控电路来调理,这个操控信号是要散热风扇生产厂家来完结,此功用可以使用频率和高低压电平来操控风扇转速,经过调整占空比来线性操控风扇转速,带
- 探索全金属耐高温交流散热风扇
辉盈防爆散热风扇
其他
随着科技的飞速发展,电子设备在高性能运算、长时间运行及极端环境应用中的需求日益增长,散热问题成为了制约其性能与寿命的关键因素之一。在这样的背景下,辉盈全金属耐高温交流散热风扇应运而生,以其优异的散热性能、稳定的运行特性及出色的耐温能力,成为了众多高端电子设备不可或缺的“降温卫士”。全金属材质的独特优势全金属散热风扇,顾名思义,其主体结构采用金属材料制成,如铝合金或不锈钢等。这些材料不仅具备高强度、
- Labelbox:引领AI与人类协作的未来
魏兴雄Milburn
Labelbox:引领AI与人类协作的未来labelbox-pythonLabelboxPythonClient项目地址:https://gitcode.com/gh_mirrors/la/labelbox-python项目介绍Labelbox是一款专为企业和学术研究社区设计的开源工具,旨在简化数据标注、生成高质量的人类反馈数据、评估和提升模型性能,并通过无缝结合AI与人类工作流程来自动化任务。无
- 探索HeidiSQL:一款强大的数据库管理工具
夏庭彭Maxine
探索HeidiSQL:一款强大的数据库管理工具HeidiSQLHeidiSQL:是一个免费且强大的SQL编辑器和数据库管理工具,支持MySQL、PostgreSQL、SQLite等多种数据库。适合数据库管理员和开发者使用HeidiSQL管理数据库和查询数据。项目地址:https://gitcode.com/gh_mirrors/he/HeidiSQL项目介绍HeidiSQL是一款开源的图形化数据库
- 基于python使用scanpy分析单细胞转录组数据
探序基因
单细胞分析python开发语言
探序基因肿瘤研究院整理相关后缀的格式介绍:.h5ad:是一种用于存储单细胞数据的文件格式,可以通过anndata库在Python中处理.loom:高效的数据存储格式(.loom文件),使得用户可以轻松地存储、查询和分析大规模的单细胞数据集。Loompy的设计目标是提供一个快速、灵活且易于使用的工具,以支持生物信息学家和研究人员在单细胞水平上进行数据分析。python的单细胞转录组数据结构说明:da
- 单细胞轨迹分析-monocle包的使用
探序基因
r语言
探序基因肿瘤研究院整理安装:monocle源码下载:https://www.bioconductor.org/packages/release/bioc/html/monocle.htmlR版本,4.2.0BiocManager::install("monocle")不过在安装过程中还是报错了:Warning:无法在https://bioconductor.org/packages/3.15/bi
- Java 运行时常量池笔记(详细版
小猫猫猫◍˃ᵕ˂◍
java笔记python
Java运行时常量池笔记(详细版)Java的运行时常量池(RuntimeConstantPool)是JVM方法区的一部分,用于存储编译期生成的字面量和符号引用。它是Java类文件常量池的运行时表示,具有动态性和共享性。运行时常量池的核心概念1.什么是运行时常量池?运行时常量池是JVM方法区的一部分,存储类文件中常量池的内容。它包含:字面量:如字符串、整数、浮点数等。符号引用:如类名、方法名、字段名
- Mybatis判断问题:深入解析与实战案例
DTcode7
sql数据库相关数据库mysqlSQL数据库开发sql
Mybatis判断问题:深入解析与实战案例基础概念与作用说明``标签``,``,````示例一:基本的``标签使用说明示例二:``,``,``的使用说明示例三:使用``标签简化条件语句说明实际工作中的使用技巧自行拓展内容在现代企业级应用开发中,MyBatis作为一款优秀的持久层框架,以其灵活的SQL映射机制和强大的动态SQL功能,深受广大开发者的喜爱。然而,在使用过程中,如何准确地进行条件判断,特
- uni-app adb安卓wifi无线调试
景影随形
uni-app网络错误
方法一adbconnect连接调试前提条件:电脑已安装adb工具手机和电脑连接的同一个WIFICMD进入到adb工具所在目录,可以使用HBuilder自带adb,如:D:\Tools\HBuilderX\plugins\launcher\tools\adbs,也可以使用AndroidSDK的adb。注意,第一次连接需要执行第一步和第二步,让手机监听5555端口,后续手机会自动监听5555端口,不需
- 本地搭建小型 DeepSeek 并进行微调
非著名架构师
大模型知识文档智能硬件人工智能大数据大模型deepseek
本文将指导您在本地搭建一个小型的DeepSeek模型,并进行微调,以处理您的特定数据。1.环境准备Python3.7或更高版本PyTorch1.8或更高版本CUDA(可选,用于GPU加速)Git2.克隆DeepSeek仓库bash复制gitclonehttps://github.com/deepseek-ai/deepseek.gitcddeepseek3.安装依赖bash复制pipinstall
- 在线预览 Word 文档
你不讲 wood
word开发语言前端vue.jsjavascriptnode.jsdocx-preview
引言随着互联网技术的发展,Web应用越来越复杂,用户对在线办公的需求也日益增加。在许多业务场景中,能够直接在浏览器中预览Word文档是一个非常实用的功能。这不仅可以提高用户体验,还能减少用户操作步骤,提升效率。实现原理1.后端服务假设后端服务已经提供了两个API接口:getFilesList:获取文件列表。previewFile:获取指定文件的内容。constexpress=require('ex
- 前端导出word文件—包含canvas(echarts图表)
Liuer_Qin
jscanvasechartsecharts前端javascript
一、使用的插件html-docx-js二、整体思路因为canvas是运行在内存中的,所以不能简单的通过dom获取canvas图片,需要手动的先将canvas转为image。三、实现先克隆要下载的DOM的副本。因为canvas是运行在内存中的,所以也不能通过cloneNode方法克隆下来(克隆下来是空的)。我们这里将原DOM中的canvas转成图片,然后插入到副本的对应位置,这样操作不会影响原DOM
- HarmonyOS全栈开发指南:从入门到精通,构建万物智联的未来生态(一)
林钟雪
Harmonyosharmonyos华为
一、HarmonyOS基础认知篇1.HarmonyOS发展历程与核心使命内容摘要:HarmonyOS,由华为公司于2019年首次公开发布,标志着华为在操作系统领域的深度布局。从最初的智能物联网设备操作系统定位,到如今面向万物智联时代的分布式全场景操作系统,HarmonyOS经历了多次迭代与升级。发展历程:初期探索:2019年,华为正式推出HarmonyOS,旨在打造一个适用于智能物联网设备的操作系
- Java常用排序算法/程序员必须掌握的8大排序算法
cugfy
java
分类:
1)插入排序(直接插入排序、希尔排序)
2)交换排序(冒泡排序、快速排序)
3)选择排序(直接选择排序、堆排序)
4)归并排序
5)分配排序(基数排序)
所需辅助空间最多:归并排序
所需辅助空间最少:堆排序
平均速度最快:快速排序
不稳定:快速排序,希尔排序,堆排序。
先来看看8种排序之间的关系:
1.直接插入排序
(1
- 【Spark102】Spark存储模块BlockManager剖析
bit1129
manager
Spark围绕着BlockManager构建了存储模块,包括RDD,Shuffle,Broadcast的存储都使用了BlockManager。而BlockManager在实现上是一个针对每个应用的Master/Executor结构,即Driver上BlockManager充当了Master角色,而各个Slave上(具体到应用范围,就是Executor)的BlockManager充当了Slave角色
- linux 查看端口被占用情况详解
daizj
linux端口占用netstatlsof
经常在启动一个程序会碰到端口被占用,这里讲一下怎么查看端口是否被占用,及哪个程序占用,怎么Kill掉已占用端口的程序
1、lsof -i:port
port为端口号
[root@slave /data/spark-1.4.0-bin-cdh4]# lsof -i:8080
COMMAND PID USER FD TY
- Hosts文件使用
周凡杨
hostslocahost
一切都要从localhost说起,经常在tomcat容器起动后,访问页面时输入http://localhost:8088/index.jsp,大家都知道localhost代表本机地址,如果本机IP是10.10.134.21,那就相当于http://10.10.134.21:8088/index.jsp,有时候也会看到http: 127.0.0.1:
- java excel工具
g21121
Java excel
直接上代码,一看就懂,利用的是jxl:
import java.io.File;
import java.io.IOException;
import jxl.Cell;
import jxl.Sheet;
import jxl.Workbook;
import jxl.read.biff.BiffException;
import jxl.write.Label;
import
- web报表工具finereport常用函数的用法总结(数组函数)
老A不折腾
finereportweb报表函数总结
ADD2ARRAY
ADDARRAY(array,insertArray, start):在数组第start个位置插入insertArray中的所有元素,再返回该数组。
示例:
ADDARRAY([3,4, 1, 5, 7], [23, 43, 22], 3)返回[3, 4, 23, 43, 22, 1, 5, 7].
ADDARRAY([3,4, 1, 5, 7], "测试&q
- 游戏服务器网络带宽负载计算
墙头上一根草
服务器
家庭所安装的4M,8M宽带。其中M是指,Mbits/S
其中要提前说明的是:
8bits = 1Byte
即8位等于1字节。我们硬盘大小50G。意思是50*1024M字节,约为 50000多字节。但是网宽是以“位”为单位的,所以,8Mbits就是1M字节。是容积体积的单位。
8Mbits/s后面的S是秒。8Mbits/s意思是 每秒8M位,即每秒1M字节。
我是在计算我们网络流量时想到的
- 我的spring学习笔记2-IoC(反向控制 依赖注入)
aijuans
Spring 3 系列
IoC(反向控制 依赖注入)这是Spring提出来了,这也是Spring一大特色。这里我不用多说,我们看Spring教程就可以了解。当然我们不用Spring也可以用IoC,下面我将介绍不用Spring的IoC。
IoC不是框架,她是java的技术,如今大多数轻量级的容器都会用到IoC技术。这里我就用一个例子来说明:
如:程序中有 Mysql.calss 、Oracle.class 、SqlSe
- 高性能mysql 之 选择存储引擎(一)
annan211
mysqlInnoDBMySQL引擎存储引擎
1 没有特殊情况,应尽可能使用InnoDB存储引擎。 原因:InnoDB 和 MYIsAM 是mysql 最常用、使用最普遍的存储引擎。其中InnoDB是最重要、最广泛的存储引擎。她 被设计用来处理大量的短期事务。短期事务大部分情况下是正常提交的,很少有回滚的情况。InnoDB的性能和自动崩溃 恢复特性使得她在非事务型存储的需求中也非常流行,除非有非常
- UDP网络编程
百合不是茶
UDP编程局域网组播
UDP是基于无连接的,不可靠的传输 与TCP/IP相反
UDP实现私聊,发送方式客户端,接受方式服务器
package netUDP_sc;
import java.net.DatagramPacket;
import java.net.DatagramSocket;
import java.net.Ine
- JQuery对象的val()方法执行结果分析
bijian1013
JavaScriptjsjquery
JavaScript中,如果id对应的标签不存在(同理JAVA中,如果对象不存在),则调用它的方法会报错或抛异常。在实际开发中,发现JQuery在id对应的标签不存在时,调其val()方法不会报错,结果是undefined。
- http请求测试实例(采用json-lib解析)
bijian1013
jsonhttp
由于fastjson只支持JDK1.5版本,因些对于JDK1.4的项目,可以采用json-lib来解析JSON数据。如下是http请求的另外一种写法,仅供参考。
package com;
import java.util.HashMap;
import java.util.Map;
import
- 【RPC框架Hessian四】Hessian与Spring集成
bit1129
hessian
在【RPC框架Hessian二】Hessian 对象序列化和反序列化一文中介绍了基于Hessian的RPC服务的实现步骤,在那里使用Hessian提供的API完成基于Hessian的RPC服务开发和客户端调用,本文使用Spring对Hessian的集成来实现Hessian的RPC调用。
定义模型、接口和服务器端代码
|---Model
&nb
- 【Mahout三】基于Mahout CBayes算法的20newsgroup流程分析
bit1129
Mahout
1.Mahout环境搭建
1.下载Mahout
http://mirror.bit.edu.cn/apache/mahout/0.10.0/mahout-distribution-0.10.0.tar.gz
2.解压Mahout
3. 配置环境变量
vim /etc/profile
export HADOOP_HOME=/home
- nginx负载tomcat遇非80时的转发问题
ronin47
nginx负载后端容器是tomcat(其它容器如WAS,JBOSS暂没发现这个问题)非80端口,遇到跳转异常问题。解决的思路是:$host:port
详细如下:
该问题是最先发现的,由于之前对nginx不是特别的熟悉所以该问题是个入门级别的:
? 1 2 3 4 5
- java-17-在一个字符串中找到第一个只出现一次的字符
bylijinnan
java
public class FirstShowOnlyOnceElement {
/**Q17.在一个字符串中找到第一个只出现一次的字符。如输入abaccdeff,则输出b
* 1.int[] count:count[i]表示i对应字符出现的次数
* 2.将26个英文字母映射:a-z <--> 0-25
* 3.假设全部字母都是小写
*/
pu
- mongoDB 复制集
开窍的石头
mongodb
mongo的复制集就像mysql的主从数据库,当你往其中的主复制集(primary)写数据的时候,副复制集(secondary)会自动同步主复制集(Primary)的数据,当主复制集挂掉以后其中的一个副复制集会自动成为主复制集。提供服务器的可用性。和防止当机问题
mo
- [宇宙与天文]宇宙时代的经济学
comsci
经济
宇宙尺度的交通工具一般都体型巨大,造价高昂。。。。。
在宇宙中进行航行,近程采用反作用力类型的发动机,需要消耗少量矿石燃料,中远程航行要采用量子或者聚变反应堆发动机,进行超空间跳跃,要消耗大量高纯度水晶体能源
以目前地球上国家的经济发展水平来讲,
- Git忽略文件
Cwind
git
有很多文件不必使用git管理。例如Eclipse或其他IDE生成的项目文件,编译生成的各种目标或临时文件等。使用git status时,会在Untracked files里面看到这些文件列表,在一次需要添加的文件比较多时(使用git add . / git add -u),会把这些所有的未跟踪文件添加进索引。
==== ==== ==== 一些牢骚
- MySQL连接数据库的必须配置
dashuaifu
mysql连接数据库配置
MySQL连接数据库的必须配置
1.driverClass:com.mysql.jdbc.Driver
2.jdbcUrl:jdbc:mysql://localhost:3306/dbname
3.user:username
4.password:password
其中1是驱动名;2是url,这里的‘dbna
- 一生要养成的60个习惯
dcj3sjt126com
习惯
一生要养成的60个习惯
第1篇 让你更受大家欢迎的习惯
1 守时,不准时赴约,让别人等,会失去很多机会。
如何做到:
①该起床时就起床,
②养成任何事情都提前15分钟的习惯。
③带本可以随时阅读的书,如果早了就拿出来读读。
④有条理,生活没条理最容易耽误时间。
⑤提前计划:将重要和不重要的事情岔开。
⑥今天就准备好明天要穿的衣服。
⑦按时睡觉,这会让按时起床更容易。
2 注重
- [介绍]Yii 是什么
dcj3sjt126com
PHPyii2
Yii 是一个高性能,基于组件的 PHP 框架,用于快速开发现代 Web 应用程序。名字 Yii (读作 易)在中文里有“极致简单与不断演变”两重含义,也可看作 Yes It Is! 的缩写。
Yii 最适合做什么?
Yii 是一个通用的 Web 编程框架,即可以用于开发各种用 PHP 构建的 Web 应用。因为基于组件的框架结构和设计精巧的缓存支持,它特别适合开发大型应
- Linux SSH常用总结
eksliang
linux sshSSHD
转载请出自出处:http://eksliang.iteye.com/blog/2186931 一、连接到远程主机
格式:
ssh name@remoteserver
例如:
ssh
[email protected]
二、连接到远程主机指定的端口
格式:
ssh name@remoteserver -p 22
例如:
ssh i
- 快速上传头像到服务端工具类FaceUtil
gundumw100
android
快速迭代用
import java.io.DataOutputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOExceptio
- jQuery入门之怎么使用
ini
JavaScripthtmljqueryWebcss
jQuery的强大我何问起(个人主页:hovertree.com)就不用多说了,那么怎么使用jQuery呢?
首先,下载jquery。下载地址:http://hovertree.com/hvtart/bjae/b8627323101a4994.htm,一个是压缩版本,一个是未压缩版本,如果在开发测试阶段,可以使用未压缩版本,实际应用一般使用压缩版本(min)。然后就在页面上引用。
- 带filter的hbase查询优化
kane_xie
查询优化hbaseRandomRowFilter
问题描述
hbase scan数据缓慢,server端出现LeaseException。hbase写入缓慢。
问题原因
直接原因是: hbase client端每次和regionserver交互的时候,都会在服务器端生成一个Lease,Lease的有效期由参数hbase.regionserver.lease.period确定。如果hbase scan需
- java设计模式-单例模式
men4661273
java单例枚举反射IOC
单例模式1,饿汉模式
//饿汉式单例类.在类初始化时,已经自行实例化
public class Singleton1 {
//私有的默认构造函数
private Singleton1() {}
//已经自行实例化
private static final Singleton1 singl
- mongodb 查询某一天所有信息的3种方法,根据日期查询
qiaolevip
每天进步一点点学习永无止境mongodb纵观千象
// mongodb的查询真让人难以琢磨,就查询单天信息,都需要花费一番功夫才行。
// 第一种方式:
coll.aggregate([
{$project:{sendDate: {$substr: ['$sendTime', 0, 10]}, sendTime: 1, content:1}},
{$match:{sendDate: '2015-
- 二维数组转换成JSON
tangqi609567707
java二维数组json
原文出处:http://blog.csdn.net/springsen/article/details/7833596
public class Demo {
public static void main(String[] args) { String[][] blogL
- erlang supervisor
wudixiaotie
erlang
定义supervisor时,如果是监控celuesimple_one_for_one则删除children的时候就用supervisor:terminate_child (SupModuleName, ChildPid),如果shutdown策略选择的是brutal_kill,那么supervisor会调用exit(ChildPid, kill),这样的话如果Child的behavior是gen_