电商搜索场景结构化匹配 使用命名实体识别(NER)+类目预测(意图识别)+bert4keras实现k-bert
上一篇的文章中电商搜索使用BM25算法召回+其他匹配特征主要讲了BM25算法的召回以及一些特征的融入,本篇继续进行剩余特征如核心词匹配,同义词匹配 ,上下位词,query类目与商品title类目匹配以及商品的业态等特征
整体结构图如下:
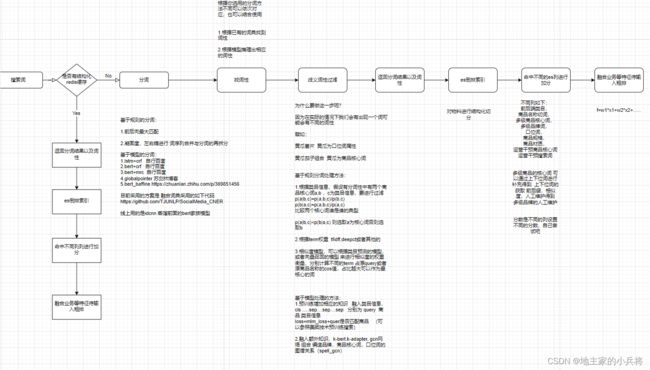
示例: 乐事薯片黄瓜
分词: 乐事 薯片 黄瓜
词性:品牌,商品核心词,口位词
这里面 补充一下:
一.分词的话你可以参照 知乎上面的 分词或者命名实体识别融合词典
二.词性匹配要注意 词性消歧义,因为不同的词在不同的商品中可能会有不同的词性,例如山东新鲜黄瓜, 黄瓜味薯片 这里面的黄瓜分别为商品核心词,口位词
具体的做法 当然不局限这些,你都可以尝试:
譬如:
黄瓜薯片 黄瓜为口位词属性
黄瓜茄子组合 黄瓜为商品核心词
基于规则分词处理方法:
1.根据类目信息,假设有分词性中有两个商品核心词a,b ,c为类目信息,要进行过滤
p(a|b,c)=p(a,b,c)/p(b,c)
p(b|a,c)=p(a,b,c)/p(a,c)
比较两个核心词谁是谁的典型
p(a|b,c)
2.根据term权重 tfidff,deepct或者其他的
3.相似度模型,可以根据类目预测的模型,或者向量召回的模型 来进行相似度的权重衡量,分别计算不同的term 占原query或者原商品名称的cos值,占比越大可以作为最核心的词
基于模型处理的方法:
1.预训练增加相应的知识 融入类目信息,cls .....sep....sep....sep 分别为 query 商品 类目信息
loss=mlm_loss+quer是否匹配商品 (可以参照美团技术预训练搜索)
2.融入额外知识,k-bert,k-adapter, gcn网络 组合 编造品牌,商品核心词,口位词的图谱关系(spellgcn https://github.com/ACL2020SpellGCN/SpellGCN )
这里使用k-bert 来实现https://arxiv.org/pdf/1909.07606.pdf
罗列的知识库体系如下:
乐事 类别 品牌
薯片 类别 商品
黄瓜 类别 商品
黄瓜 类别 口位
乐事 售卖 薯片
薯片 属性 黄瓜
可口 竞品 百事
可口 类别 品牌
百事 类别 品牌
可乐 类别 商品
雪碧 类别 商品
巧克力 属性 牛奶味
牛奶味 类别 口味
牛奶 类别 口味
巧克力 类别 商品
法国 售卖 香槟
#本文使用的bert4keras 实现k-bert 将下面的三个函数 粘贴到models.py(bert4keras的源码)
def extend_with_vi_model(BaseModel):
"""添加下三角的Attention Mask(语言模型用)
"""
class VI_Model(VI_Mask, BaseModel):
"""带下三角Attention Mask的派生模型
"""
def __init__(self, *args, **kwargs):
super(VI_Model, self).__init__(*args, **kwargs)
self.with_mlm = self.with_mlm or True
return VI_Model
class VI_Mask(object):
"""定义下三角Attention Mask(语言模型用)
"""
def compute_attention_bias(self, inputs=None):
"""通过idxs序列的比较来得到对应的mask
"""
if self.attention_bias is None:
def vi_mask(s):
mask = K.cast(s, K.floatx())
mask=-(1 - mask) * K.infinity()
mask = K.expand_dims(mask, axis=1)
mask = K.tile(mask, [1, 12,1, 1])
return mask
self.attention_bias = self.apply(
inputs=self.inputs[-1],
layer=Lambda,
function=vi_mask,
name='Attention-VI-Mask'
)
return self.attention_bias
class Kbert(BERT):
"""构建GPT模型
链接:https://github.com/openai/finetune-transformer-lm
"""
@insert_arguments(final_activation='softmax')
@delete_arguments('with_pool', 'with_mlm')
def __init__(self, **kwargs):
super(Kbert, self).__init__(**kwargs)
self.custom_position_ids = True
def get_inputs(self):
"""BERT的输入是token_ids和segment_ids
(但允许自行传入位置id,以实现一些特殊需求)
"""
x_in = self.apply(
layer=Input, shape=(self.sequence_length,), name='Input-Token'
)
inputs = [x_in]
if self.segment_vocab_size > 0:
s_in = self.apply(
layer=Input,
shape=(self.sequence_length,),
name='Input-Segment'
)
inputs.append(s_in)
if self.custom_position_ids:
p_in = self.apply(
layer=Input,
shape=(self.sequence_length,),
name='Input-Position'
)
inputs.append(p_in)
vm_in = self.apply(
layer=Input,
shape=(self.sequence_length,self.sequence_length),
name='Input-Vmask'
)
inputs.append(vm_in)
return inputs
def apply_embeddings(self, inputs):
"""GPT的embedding是token、position、segment三者embedding之和
跟BERT的主要区别是三者相加之后没有加LayerNormalization层。
"""
inputs = inputs[:]
x = inputs.pop(0)
s = inputs.pop(0)
p = inputs.pop(0)
x = self.apply(
inputs=x,
layer=Embedding,
input_dim=self.vocab_size,
output_dim=self.embedding_size,
embeddings_initializer=self.initializer,
mask_zero=True,
name='Embedding-Token'
)
if 1==1:
name = 'Embedding-Segment'
s = self.apply(
inputs=s,
layer=Embedding,
input_dim=2,
output_dim=self.embedding_size,
embeddings_initializer=self.initializer,
name=name
)
x = self.apply(
inputs=[x, s], layer=Add, name='Embedding-Token-Segment'
)
x = self.apply(
inputs=self.simplify([x, p]),
layer=PositionEmbedding,
input_dim=self.max_position,
output_dim=self.embedding_size,
merge_mode='add',
hierarchical=self.hierarchical_position,
embeddings_initializer=self.initializer,
custom_position_ids=self.custom_position_ids,
name='Embedding-Position'
)
x = self.apply(
inputs=x,
layer=Dropout,
rate=self.dropout_rate,
name='Embedding-Dropout'
)
if self.embedding_size != self.hidden_size:
x = self.apply(
inputs=x,
layer=Dense,
units=self.hidden_size,
kernel_initializer=self.initializer,
name='Embedding-Mapping'
)
return x
def apply_final_layers(self, inputs):
"""剩余部分
"""
x = inputs
# Language Model部分
x = self.apply(
inputs=x,
layer=Embedding,
arguments={'mode': 'dense'},
name='Embedding-Token'
)
x = self.apply(
inputs=x,
layer=Activation,
activation=self.final_activation,
name='LM-Activation'
)
return x
def load_variable(self, checkpoint, name):
"""加载单个变量的函数
"""
variable = super(GPT, self).load_variable(checkpoint, name)
if name == 'gpt/embeddings/word_embeddings':
return self.load_embeddings(variable)
else:
return variable
def variable_mapping(self):
"""映射到TF版GPT权重格式
"""
mapping = super(GPT, self).variable_mapping()
mapping = {
k: [
i.replace('bert/', 'gpt/').replace('encoder', 'transformer')
for i in v
]
for k, v in mapping.items()
}
return mapping
#######################
######自定义模型#########
######自定义模型##########
#######################
base = build_transformer_model(config_path, application='kbert', model='kbert')
三.命中es不同的列,里面会有多级商品核心词,多级商品品牌
譬如 伊利特仑苏鲜奶 品牌 伊利,特仑苏 商品核心词:鲜奶 牛奶 奶制品
多级品牌是维护的,多级商品核心词是实体识别出来 或者切词切出来,牛奶 ,奶制品是 上下位词处理的
四.命中es不同的列,加不同的分数
query中原词、同义词到指定的列做召回