基于NN的编码:Content-adaptive neural network post-processing filter(Nokia Technologies)
JVET-V0075
该提案为了深度学习作为滤波的编解码器复杂度之间进行权衡,提出了一种新的训练方法:在一个足够大的数据集上预先训练一个相对较小的后处理神经网络,然后将其作为编码操作的一部分专门用于输入视频序列,对网络进行微调。
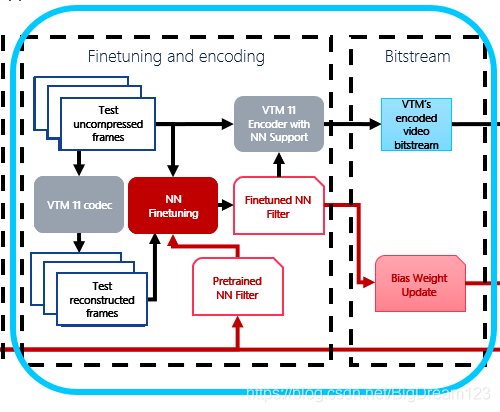
网络结构和工作流程
我们的NN过滤器的架构如图1所示。NN的输入是YUV+归一化的QP。第一块包括64个核的卷积层(不包括偏置)、偏置层、作为非线性激活函数的LeakyReLU。跟随4个与第一个块中的层相似的块,但是每个块的输入都添加到块的输出(通过使用skip connection)。最后一个块与第一个块类似(没有跳过连接)。将输入的YUV通道相加为神经网络的输出。

流程可分为三个主要阶段。
- 第一阶段是对视频数据集上的神经网络滤波器进行离线预训练。
- 第二阶段包括在输入视频序列上的预处理神经网络滤波器进行微调,获得权重更新。
- 第三阶段是实际的解码操作,将更新后的网络应用于解码端

预训练
使用BVI-DVC数据集离线执行预训练。我们为BVI-DVC数据集中的每个内容类content class训练了一个神经网络,其内容分辨率从4K到WQVGA不等。在200个视频序列中,我们使用了所有的64帧,除了class A,为了减少训练时间,只使用了前16帧。随机选取160个序列作为训练集,40个序列作为验证集。视频序列采用VTM11.0编码器进行编码,序列QP值分别为22、27、32、37和42,采用Random Access配置,然后由解码器进行重建。对于每个epoch,每个视频序列中的所有帧以随机顺序选择一次。从这些视频序列的每一帧中,从重建序列中提取一个128x128的patch作为NN滤波器的输入,并将相应的未压缩的patch作为ground-truth数据。通过在帧内随机选择patch的位置来裁剪patch。必要时,使用边界像素进行填充。归一化帧QP被用作额外的输入通道,叠加到Y、U、V通道。通过复制相邻的行和列对色度通道进行上采样。
每个class都有一个单独的网络。
对于训练的损失函数,我们使用加权均方误差(MSE)之间的filtered output patches和ground-truth patches,计算在YUV域。Y、U和V通道的MSE值加权如下:8:1:1。
微调
微调阶段的目的是使预训练的神经网络滤波器适应目标视频内容。为了生成微调阶段的输入数据,JVET-CTC视频数据集中的所有序列都由VTM 11.0使用QP值等于22、27、32、37和42的随机访问(RA)配置进行编码。结果,每个编码生成输入数据,用于获得用于具有特定序列QP的特定序列的微调网络。
重建帧和原始帧被裁剪成128x128的小块,分别形成输入数据和真实数据。将重建帧的QP作为第四输入通道。对于每个视频序列和每个QP,我们在所有patches和所有帧上微调NN滤波器。
从预先训练好的神经网络权值出发,在微调过程中只对偏置项进行优化,以减少更新所需的比特率开销。在所有151811个参数中,只有323个表示可训练的偏差项。我们使用YUV域中的加权均方误差作为损失函数。在每个微调阶段,所有的patches对都是随机的,并输入到训练过程中。当训练损失已平缓或即将平缓时,微调停止。
在微调结束时,计算微调偏差项和预训练偏差项之间的差值作为权重更新。对整个视频序列以及该视频序列中的所有Y、U、V信道获得单个权重更新。然后使用LZMA2算法对该权重更新进行压缩。
编解码
首先对从内容自适应过程获得的压缩权重更新进行解压缩,然后通过简单地将偏差更新值添加到原始(预训练的)偏差项来更新解码器侧的NN滤波器。
使用TensorFlow C API(版本2.3.1)和提供的动态库将内容自适应后处理过滤器集成到VTM 11.0中[3]。在CTU级别应用过滤器。通过添加两个CTU级别标志(一个用于亮度,一个用于色度)来修改位流语法,这两个标志指示是否使用NN过滤器。最后,通过率失真优化(RDO)进行决策。
实验结果
| BD-rate Over VTM-11.0 |
|||||||||
| Y-PSNR |
U-PSNR |
V-PSNR |
Y-MSIM |
U-MSIM |
V-MSIM |
EncT |
DecT |
bit DIFF |
|
| Class C |
-2,36 % |
-5,23 % |
-3,27 % |
-0,32 % |
-5,80 % |
-3,32 % |
127 % |
69109 % |
1 % |
| Class D |
-2,81 % |
-1,63 % |
-0,09 % |
0,45 % |
-2,10 % |
-0,04 % |
110 % |
23799 % |
1 % |
JVET-W0057
网络结构和训练方法和JVET-V0075类似,不同的是,针对不同的分辨率,使用不同的模型参数,称为smallNN(用于class B/C/D/F)和bigNN(用于class A),网络的结构如下图所示。每个块包含一个卷积层、一个偏置层和一个非线性激活函数(LeakRelu)。
对于smallNN,其前四个块卷积层的输出通道数为64,最后一个块的卷积层输出通道数为3。对于bigNN,其前四个块卷积层的输出通道数为512,最后一个块的卷积层输出通道数为3。
整个训练流程和V0075类似,也是主要包含三个步骤:
- 大数据集上离线预训练
- CTC数据集上微调(特定序列特定Qp),获得权重更新(偏置参数)
- 编解码操作(解码权重参数,更新权重,编码视频,更新后的NN滤波器对解码后的重建帧后处理)

预训练
数据集:BVI-DVC 数据集(未压缩和重建帧),使用VTM11.0进行编码( QP 值等于 22、27、32、37 和 42,RA配置),从帧中随机裁剪128x128大小的块(必要时使用边界像素填充)。
网络输入为YUV和归一化Qp四通道。
每个分辨率类训练一个模型。损失函数是在 MSE Loss。 Y、U 和 V 通道的 MSE 值加权如下:8:1:1。

微调
目标是将预训练的 NN 专门用于特定的视频序列。
数据:JVET CTC 视频序列(原始和解码版本)。(VTM 11.0 使用 QP 值等于 22、27、32、37 和 42 的 RA 配置编码),从帧中裁剪128x128的块。
仅微调偏差项,仅将偏差更新发送到解码器(使用LZMA2 压缩) 。 对于Small NN,在所有 151,811 个参数中,只有 323 个代表可训练的偏差项。 对于 Big NN,在所有 9,472,003 个参数中,只有 2563 个代表可训练偏差项。
两个带有 EP 的 CTU 标志,一个用于亮度,一个用于色度
解码
解码偏置参数更新,偏差更新用于适应预训练的神经网络。
以CTU单元应用用于后处理的微调神经网络。
应用如下:

- rec:输入NN滤波器的重建值
- CCN(rec):NN滤波网络的输出
- s:缩放因子,亮度选项:{0.8, 0.9, 1.0, 1.2}(根据经验选择的值),色度为1
|
|
BD-rate Over VTM-11.0 |
||||||||
| Y-PSNR |
U-PSNR |
V-PSNR |
Y-MSIM |
U-MSIM |
V-MSIM |
EncT |
DecT |
bit DIFF |
|
| Class B |
-2,75 % |
-9,88 % |
-5,52 % |
-1,56 % |
-11,18 % |
-6,82 % |
154 % |
66710 % |
0 % |
| Class C |
-3,02 % |
-5,68 % |
-3,66 % |
-1,14 % |
-6,51 % |
-4,03 % |
126 % |
47611 % |
1 % |
| Class D |
-3,37 % |
0,53 % |
0,61 % |
-0,16 % |
-0,96 % |
0,24 % |
113 % |
17189 % |
1 % |
| Class F |
0,44 % |
1,80 % |
2,90 % |
0,11 % |
-0,28 % |
1,31 % |
124 % |
26836 % |
0 % |
| BD-rate Over VTM-11.0 + NN filter single scaling factor |
|||||||||
| Y-PSNR |
U-PSNR |
V-PSNR |
Y-MSIM |
U-MSIM |
V-MSIM |
EncT |
DecT |
bit DIFF |
|
| Class B |
-0,06 % |
-0,32 % |
-0,24 % |
0,01 % |
-0,33 % |
-0,24 % |
98 % |
96 % |
0 % |
| Class C |
-0,23 % |
-0,32 % |
-0,26 % |
-0,07 % |
-0,19 % |
-0,16 % |
94 % |
80 % |
0 % |
| Class D |
-0,20 % |
-0,33 % |
-0,16 % |
-0,01 % |
0,04 % |
0,00 % |
98 % |
77 % |
0 % |
| Class F |
-0,13 % |
-0,08 % |
-0,06 % |
0,03 % |
-0,09 % |
-0,07 % |
95 % |
86 % |
0 % |