【论文阅读--实时语义分割】RegSeg:Rethink Dilated Convolution for Real-time Semantic Segmentation
Abstract
- 语义分割的最新进展通常采用ImageNet预训练主干网,在其后面有一个 特殊的上下文模块,以快速增加视野。尽管取得了成功,但大部分计算所在的主干网没有足够大的视野来做出最佳决策。
- 最近的一些进展通过 快速降低主干中的分辨率 来解决这个问题,同时还具有一个或多个具有更高分辨率的并行分支。
- 我们采用了一种不同的方法,设计了一种受ResNeXt启发的块结构,该结构使用 两个具有不同扩张率的平行3×3卷积层 来增加视野,同时保留局部细节。通过在主干中重复这种块结构,我们不需要在其后面附加任何特殊的上下文模块。
此外,我们还提出了一种 轻量级解码器,它比普通解码器更好地恢复本地信息。为了证明我们方法的有效性,我们的模型RegSeg在实时城市景观和CamVid数据集上实现了最先进的结果。使用混合精度的T4 GPU,RegSeg在Cityscapes测试集上以30 FPS的速度达到78.3的mIOU,在CamVid测试集上以70 FPS的速度达到80.9的mIOU,两者都没有ImageNet预训练。
1 Introduction
语义分割的任务是为输入图像中的每个像素分配一个类。它的应用包括自动驾驶、自然场景理解和机器人技术。这也是自下而上的全景分割方法[7]的基础,该方法除了为每个像素分配一个类外,还将同一类的实例分隔开来。
【已有常用的方法 及问题】
以前在语义分割方面的进展通常采用ImageNet[10]预训练主干,并添加一个上下文模块,该模块具有较大的平均池(如PPM[50])或较大的扩展率(如ASPP[4]),以快速增加视野。它们利用ImageNet预训练权重,在PASCAL VOC 2012[12]等较小的数据集上实现更快的收敛和更高的精度,从头开始训练可能是不可能的。
这种方法有两个潜在问题。
- ImageNet主干通常在最后几个卷积层中有大量通道,因为它们用于将图像标记到ImageNet中1000个类中的一个。例如,ResNet18[16]以512个通道结束,ResNet50以2048个通道结束。Mobilenetv3[19]的作者发现,当适应语义分割时,将最后一个卷积层中的通道数量减半并不会降低准确性,这暗示了ImageNet模型的通道冗余。
- 第二,调整ImageNet模型以获取分辨率约为224×224的输入图像,但语义分割中的图像要大得多。例如,Cityscapes[8]的图像分辨率为1024×2048,CamVid[1]的分辨率为720×960。ImageNet模型缺乏对如此大的图像进行编码的视野。
【我们的方案】
这两个问题启发我们设计一个专门用于语义分割的主干。
通过引入一种称为D块的新型扩展块结构,我们直接在主干中增加了视野,并保持主干中通道的数量较低。我们从ResNeXt[45]块结构中得到启发,该结构在传统ResNet块中使用组卷积来提高其精度,同时保持相似的运行时复杂性。RegNet[36]采用了ResNeXt块,并在广泛的FLOP中提供了更好的基线。我们采用快速RegNetY-600MF进行语义分割,将原始的Y块替换为D块。特别是,在进行group conv时,D块对一半组使用一个扩张率,对另一半组使用另一个扩张率。通过重复RegSeg主干中的D块,我们可以轻松增加视野,而不会丢失局部细节。RegSeg的主干网使用的扩展率高达14,而且因为它有足够的视野,所以我们不附加任何上下文模块,比如ASPP或PPM。已有方案对于空洞卷积的顾虑:
许多最近的作品——如Auto DeepLab[30]、Explated SpineNet[37]和Detector[35]——都不愿在其架构设计空间中包含具有大膨胀率的膨胀卷积,并且仍然依赖ASPP或PPM等上下文模块来增加视野。我们认为这是因为扩张的conv在重量之间留下了洞。我们解决这个问题的方法是从较小的扩张率开始,并始终在D块的一个分支中将扩张率设置为1。我们希望这项工作能激励未来的研究人员在他们的模型中尝试更大的扩张率。我们还提出了一种轻量级解码器,可以有效地恢复主干中丢失的本地细节。以前的解码器(如DeepLabv3[5]中的解码器)速度太慢,无法实时运行,而常见的轻量级替代方案(如LRASPP[19])也没有那么有效。在相同的训练设置下,我们的解码器比LRASPP好1.0%。
RegSeg实时运行。使用混合精度的T4 GPU,RegSeg在Cityscapes上以每秒30帧的速度运行,在CamVid上以每秒70帧的速度运行。许多任务要求模型实时运行,例如自动驾驶或移动部署。实时模型比非实时模型效率更高,当扩展到相同的计算复杂度时,它们有可能超过最先进的模型。例如,EfficientNet[41]之前通过放大他们使用神经架构搜索发现的低计算模型,在ImageNet上获得了最先进的结果。
我们的贡献是(总结上面的内容):
- 我们提出了一种新的扩展块结构(D块),它可以轻松增加主干的视野,同时保持局部细节。通过重复RegSeg主干中的D块,我们可以在不需要额外计算的情况下控制视野。
- 我们推出了一款轻量级解码器,其性能优于普通解码器。
- 我们进行了大量实验,以证明我们方法的有效性。RegSeg在城市景观测试集上以30 FPS的速度达到7830万,在CamVid测试集上以70 FPS的速度达到8090万,这两种测试都没有ImageNet预训练。在Cityscapes测试集上,RegSeg的表现优于SFNet(DF2)[26]的最佳同行评审结果0.5%。在相同的训练设置下,RegSeg在城市景观val集上的表现比DDRNet-23[18]同时进行的、非对等审查的工作要好0.5%。
2 Related works
2.1. Network design
在ImageNet上发现的模型在一般网络设计中起着重要作用,它们的改进通常会转移到其他领域,如语义分割。
RegNet[11,36]发现,通过使用随机搜索来运行大量实验,并分析趋势以减少搜索空间,对ResNeXt[45]体系结构进行了许多改进。它们提供了大范围的flop的模型,在类似的训练环境下,这些模型的表现优于EfficientNet[41]。EfficientNetV2[42]是EfficientNet的改进版,在更高的分辨率下,使用常规CONV而不是深度CONV,训练速度更快。在本文中,我们从RegNet中得到启发,通过调整它们的块结构来进行语义分割。
2.2. 语义分割
- 全卷积网络(FCN)[31,38]在分割任务中优于传统方法。
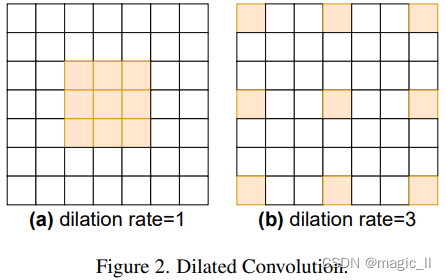
- DeepLabv3[4]在ImageNet预训练主干中使用扩张卷积,将输出步幅减少到16或8,而不是通常的32,并通过提出Atrus Spatial Pyramid Pooling module(ASPP)来增加感受野,该模块应用具有不同扩展率的卷积层的并行分支。图2显示了扩展的conv。
- PSPNet[50]提出的金字塔池模块(PPM)的示例,该模块通过首先应用平均池来应用具有不同输入分辨率的卷积层的并行分支。
- 在我们的论文中,我们提出了与ASPP结构相似的扩展块(D块),并将其作为主干的构建块,而不是在末端附加一个。
- DeepLabv3+[5]在DeepLabv3的基础上添加了一个简单的解码器,在输出步长4处添加了两个3×3的conv,以提高边界附近的分割质量。HRNetV2[44]将具有不同分辨率的并行分支保留在主干中,最好的分支位于输出步长4。
2.3. 实时语义分割
- MobilenetV3使用轻量级解码器LRASPP[19]来调整用于语义分割的快速ImageNet模型。
- BiSeNetV1[48]和BiSeNetV2[47]在主干中有两个分支(空间路径和上下文路径),并在最后合并它们,以在不进行ImageNet预训练的情况下获得良好的精度和性能。
- SFNet[26]提出了流量校准模块(FAM),以比双线性插值更好地对低分辨率特征进行上采样。
- STDC[13]通过移除空间路径并设计更好的主干线,重新思考了BiSeNet架构。
- HarDNet[3]主要使用3×3 conv,几乎不使用任何1×1 conv,从而减少了GPU内存流量消耗。
- DDRNet23[18]使用了两个分支,它们之间有多个双边融合,并在主干的末端附加了一个称为深度聚合金字塔池模块(DAPPM)的新上下文模块。DDRNet-23是一项尚未经过同行审查的并行工作。DDRNet-23是目前最先进的实时城市景观语义分割技术,我们发现,在相同的训练环境下,RegSeg的性能优于DDRNet23。
3 Methods
3.1. 感受野
我们对通过卷积获得的模型的视野(FOV)感兴趣,也就是我们所知的感受野。例如,两个3×3 conv的组合在内核大小和步幅上与一个5×5 conv相等,我们简单地说,视野是5。更一般地说,可以按照FCN[31]中所述迭代计算CONV组合的视野。假设到目前为止,conv的组成在内核大小和步幅上是相等的,一个k×k conv的步幅是s,我们用一个 k ′ ∗ k ′ k^{'}*k^{'} k′∗k′ 的 conv的步幅是 s ′ s^{'} s′。我们通过
k的最终值是感受野。
有效增加视野有两种主要方法:一种是在早期使用步幅2的卷积或平均池来下采样。另一种方法是使用扩张卷积。
- 扩张率为r的3×3 卷积与核尺寸为2r+1的conv的感受野相等。然而,为了不在权重之间留下任何孔,我们需要 k / s ≥ r k/s≥ r k/s≥r, 式中 k和s是使用截至当前点的CONV组成计算的,如前一段所述。这是r的上界,在实践中,我们选择的扩张率比上界低得多。
- 感受野和输入图像大小之间的关系极大地影响模型的准确性。例如,如果我们在ImageNet上使用测试裁剪大小为224×224的ResNet[16]架构,并在全局平均池之前查看特征图,则模型需要至少224 ∗ 2 − 1 = 447的感受野,左上角的像素可以看到整个图像。类似地,在图像大小为1024×2048的城市景观上,模型需要2047的视场才能看到输出图像的左上像素,4095的视场才能看到输入图像的右下像素。
3.2. 扩张模块
我们的扩展块(D块)的灵感来自RegNet[36]的Y块,也被称为SE-ResNeXt块[20]。Y块和我们新的D块利用群卷积(group conv)。假设输入通道=输出通道=w,这对于Y块和D块中的3×3 CONV总是正确的。群卷积有一个名为group width g的属性,g必须除以w。在向前传递过程中,带有w通道的输入被分成带有g通道的w/g组,每个组应用一个常规conv,输出被连接在一起再次形成w通道。由于每个组都有一个conv,我们可以对不同的组应用不同的扩张率来提取多尺度特征。例如,我们可以对一半组应用扩张率1,对另一半组应用扩张率10。这是我们D区的关键。
图3a示出了Y块。图3b显示了我们的D块。当d1=d2=1时,D块相当于Y块。在4.4节中,我们对一些具有4个不同扩张率分支的D块进行了实验,但发现它们并不比具有2个分支的D块好。图4显示了步幅=2时的D块。与ResNet D-variant[17]类似,当块的步幅=2时,我们在快捷分支上应用2×2平均池。BatchNorm[23]和ReLU紧跟在每个conv之后,除了在求和之前的ReLU 被替换为求和之后的ReLU。我们使用有1/4压缩率的SE。
现代深度学习框架支持group conv,每组应用相同的扩张率。由于D块对不同的组使用不同的扩张率,我们必须手动分割输入,应用conv,然后连接。我们用(d1,d2)来表示D块中的扩张率。表1中,我们证明了手动拆分和串联以及使用扩张卷积会影响速度。因此,Y块的速度略快于D块,尽管它们具有相同的FLOP复杂度和参数计数。当我们在实践中使用D块(1,1)时,我们不需要手动拆分和连接,因为两个分支使用相同的扩张率
3.3. 主干网
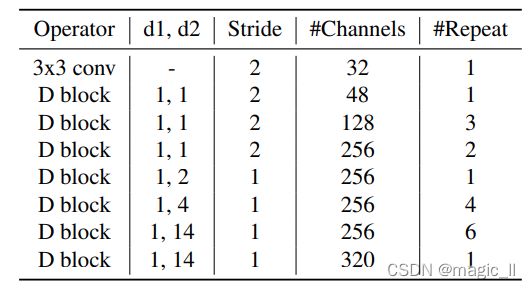
我们的主干是通过重复D块构建的,其风格类似于RegNet。主干从一个32通道3×3 conv开始,步幅为2。然后在1/4分辨率下有一个48通道D块,在1/8分辨率下有三个128通道D块,在1/16分辨率下有十三个256通道D块,在1/16分辨率下有一个320通道D块。所有D块的组宽g=16。我们不会将样本减少到1/32。我们在1/16时增加13个步幅1块的扩张率:1 (1,1)、1(1,2)、4(1,4) 和 7(1,14)。简而言之,我们将扩张率表示为 (1,1)+(1,2)+4∗(1, 4)+ 7∗(1, 14)。我们对所有其他块使用扩张率(1,1),使其与Y块等效,但当步幅=2时的2×2平均池除外。以类似于EfficientNetV2[42]的格式,我们在表2中展示RegSeg的主干。为最后13个块选择正确的扩张率是不容易的,我们在4.4节对扩张率进行了实验。
表2。主干网#Channels是输出通道的数量,而输入通道的数量是从上一个块推断出来的。当步幅=2且#repeat>1时,第一个区块的步幅为2,其余区块的步幅为1。
3.4. 解码器
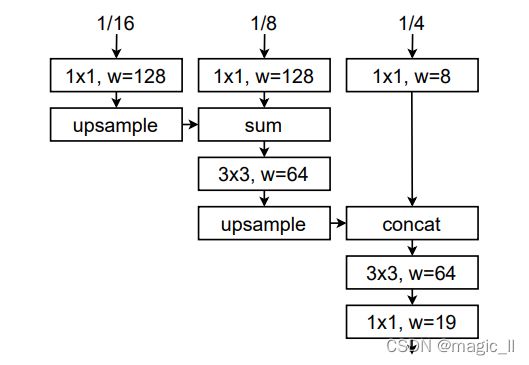
解码器的工作是恢复主干中丢失的本地细节。与DeepLabv3+[5]类似,我们使用[k*k,c]来表示带有c输出通道的k*k conv。我们将主干最后的1/4、1/8和1/16特征映射作为输入。我们将[1*1,128]conv应用于1/16,[1*1,128]conv应用于1/8,[1*1,8]conv应用于1/4。我们对1/16进行上采样,将其与1/8相加,并应用[3*3,64]conv。我们再次进行上采样,与1/4连接,并在最后的[1*1,19]conv之前应用[3*3,64]conv。除最后一个conv外,所有conv后面都跟有BatchNorm[23]和ReLU。解码器如图5所示。这种简单的解码器比许多具有相似latencies的现有解码器性能更好。我们在4.5章节实验了不同的解码器设计。
图5. 解码器。w表示输出通道的数量。除最后一个conv外,所有conv后面都跟有BatchNorm[23]和ReLU。
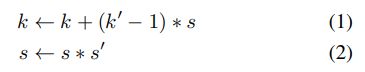

4 Experiments
4.1 Datasets
Cityscapes[8]是一个大型数据集,主要用于街景解析。它包含2975张训练图片、500张验证图片和1525张测试图片。我们不使用带有粗糙标签的20000张图片。共有19个类,忽略标签为255。图像大小为1024×2048。
CamVid[1]是另一个类似于城市景观的街道场景数据集。它包含367张用于训练的图像,101张用于验证,233张用于测试。在之前的工作[24,33,48]之后,我们只使用了11个类,并将所有其他类设置为ignore label=255。我们在trainval集合上进行训练,并在测试集合上进行评估。图像大小为720×960。
4.2. Train setting
在城市景观中
- 我们使用动量=0.9、初始学习率=0.05、权重衰减=0.0001的SGD,但我们不衰减参数。我们使用poly learning rate scheduler将当前学习率设置为初始学习率乘以 ( 1 − c u r _ i t e r t o t a l _ i t e r ) 0.9 (1-\frac{cur\_iter}{total\_iter})^{0.9} (1−total_itercur_iter)0.9。在前3000次迭代中,我们还应用了从0.1lr 到 lr 的线性预热[15]。在训练期间,我们采用随机水平翻转、随机缩放[400,1600]和随机裁剪768×768。我们使用了一组简化的RandAug[9]操作(自动对比度、均衡、旋转、颜色、对比度、亮度、清晰度)。
- 对于每幅图像,我们应用2个大小为0.2的随机操作。我们还使用类均匀抽样[51],类均匀百分比=0.5。我们使用交叉熵损失和batch size 为8。RegSeg使用PyTorch的[34]默认初始化,从随机初始化的权重中训练。我们在一个T4 GPU上训练1000个轮次。为了在不损失任何准确性的情况下加快训练,我们使用混合精度训练。在提交给测试服务器时,我们在trainval集合上进行训练,并额外使用1024×1024裁剪大小和Online Hard Example Mining loss [39] (OHEM)。OHEM损耗,也称为自举损耗,平均超过0.3的像素损耗,或者,如果原始比例小于1/16,则平均最高的1/16像素损耗。
- 在进行消融研究时,我们只训练了500个轮次。为了将消融研究所需的CPU数量减半,我们将图像以半分辨率存储在磁盘上,并在加载时将其重新调整为全分辨率,除非另有规定。在与DDRNet-23[18]进行比较时,以及在提交到测试服务器时,我们以全分辨率存储和加载图像。
在CamVid上,训练环境与城市景观中的类似。因为我们没有ImageNet预训练,而且CamVid很小,所以我们使用城市景观预训练模型。我们使用随机水平翻转、随机缩放[2881152],以及批量为12的720×960的随机裁剪。我们不使用RandAug或类均匀抽样。我们训练了200个轮。
4.3. 重复性
- 为了使我们的消融研究成为可能,我们需要结果的可重复性。我们按文件名对训练图像进行排序,以防止不同的文件系统导致不同的顺序。在随机初始化模型权重之前,我们将随机种子设置为0。在每个轮次开始时,我们将随机种子设置为当前轮次。通过这样做,我们消除了由于初始化不同模型或在不完整的训练后,恢复模型训练而导致的在训练期间处于随机数生成器不同状态的问题。此外,由于文件名的随机洗牌发生在每个轮次的开始,因此即使在不同的数据增强下,我们也可以保证图像的顺序相同。
即使经过这一谨慎的再现性程序,城市景观的变化仍然非常大,如表3所示。我们对同一模型进行4次训练,并测量标准偏差。这可能是因为类不平衡和分布外的验证集。
表3. 重复性。卡车、公共汽车和火车的课程在不同的次数上都有很大的差异,而其他未显示的课程则没有那么大的差异。通过从度量中删除这三个类,我们可以实现更小的变化- 类不平衡的存在是因为有些类显示较少,有些类的实例较小。由于训练集和验证集中的图像来自不同的城市,因此验证集来自不同的城市。通过在更大的数据集上进行预训练,这些问题可能会得到缓解,但我们关注的是从头开始的训练。我们对这些巨大的差异感到不满意,我们检查了各个类别的IOU,发现一些类别(卡车、公共汽车和火车)的差异比其他类别大得多。我们产生了一个新的度量,称为缩减的mIOU( m I O U R mIOU_R mIOUR),在取平均值之前,我们去掉了这三个类。如表3所示。它的差异要小得多,这使得我们的消融研究具有一定的重要性。
4.4. 主干消融研究
在表4上,我们对最后13个块的扩张率进行了实验,并显示了它们的感受野,同时修复了其他所有问题。我们始终保持d1=1,以保留本地细节。我们看到 (a) 有4个分支 (3、5和9行) 并不一定比2个分支好,(b)早期的扩张率应该很小 (第4行与第8行),以及©最好的感受野约为3800 (第1和第2行与第4、6和7行)。我们最好的主干比输出步幅为16的放大RegNetY-600MF[36]要好2.6%。
表4. 主干消融研究。我们最好的主干在早期有小的扩张率,在后期有大的扩张率。
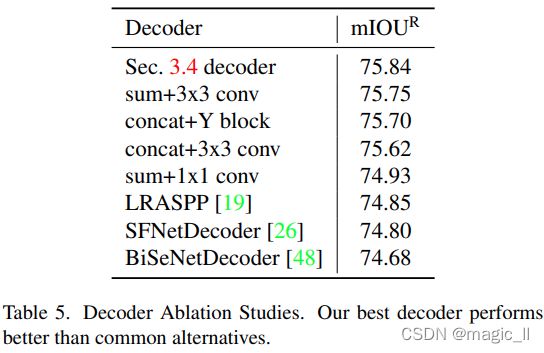
4.5. 解码器的消融实验
在表5中,固定主干结构的同时,我们对解码器设计进行了实验。我们将主干最后的1/4、1/8和1/16特征映射作为输入。我们总是将[1×128]conv应用于1/16,并将其双线性上采样2倍。如果将[1×1,128]conv与1/8相加,则将其应用于1/16;如果将[1×1,32]conv与1/16相连,则将[1×1,32]conv应用于1/8。在1/8和1/16求和或串联之后,我们可以使用1×1 conv、3×3 conv或Y块,所有输出通道=128,在最终1×1 conv到19个通道之前,进一步解码特征。
除最后一个卷积转换为19 channels,所有conv之后都紧跟着BatchNorm[23]和ReLU。除了我们最好的解码器外,所有这些解码器的输出步长均为8。我们看到,当使用求和时,3×3 conv比1×1 conv好0.8%。求和和拼接是相似的,3×3 conv和Y块是相似的。最好的解码器是第3.4节中描述的解码器,它额外使用了1/4的特征。现有解码器[19,26,48]的性能比我们最好的解码器差得多,这可能是因为它们是为没有大视场的主干设计的。
4.6. 训练技术与消融研究
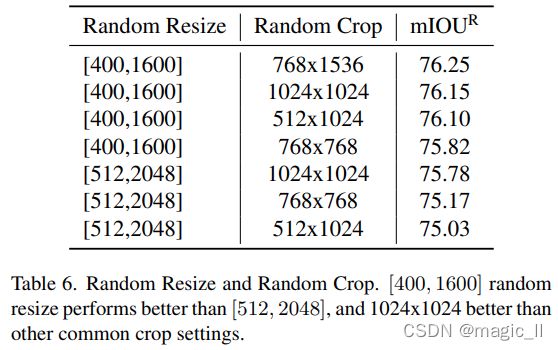
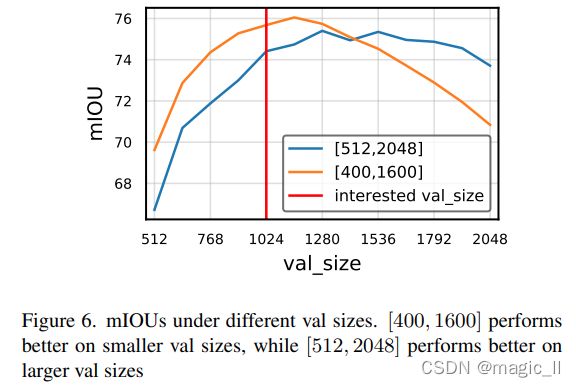
在表6中,我们对随机调整大小和随机裁剪超参数进行了实验。我们发现,在许多作物尺寸中,流行的[512,2048]随机调整尺寸的性能比[400,1600]调整尺寸的性能差。[400,1600]以1000为中心,而[512,2048]以1280为中心,所以[4001600]随机调整大小更符合我们的验证大小1024。这与最近的CopyPaste 论文[14]一致,他们使用[0.1]∗valsize,2.0∗valsize],在COCO[29]上的随机调整大小;以及FixRes论文[43],它们通过在ImageNet上使用更大的测试尺寸或更小的训练尺寸来修复train-test 的差异。在图6中,我们显示[400,1600]在较小的验证大小下表现更好,而[512,2048]在较大的验证大小下表现更好。
在表7中,我们结合了我们在之前的消融研究中发现的最好的主干和解码器,并用更多的训练设置进行了实验。对于本表中的实验,我们使用全分辨率而非半分辨率存储的图像。我们再次确认[400,1600]调整大小是有帮助的。训练1000个轮次而不是500个轮次,使用OHEM损耗可以获得巨大的性能提升。我们不使用1024×1024随机作物和OHEM损失,除非我们提交给测试服务器。
4.7. 时间
我们使用一个T4 GPU对RegSeg测试时间,精度参差不齐。我们将PyTorch 1.9[34]与CUDA 10.2结合使用。城市景观上的输入大小为1×3×1024×2048,而CamVid上的输入大小为1×3×720×960。经过10次预热迭代后,我们将在接下来的100次迭代中平均模型的时间。我们torch.backends.cudnn.benchmark=True,以及使用了 torch.cuda.synchronize()
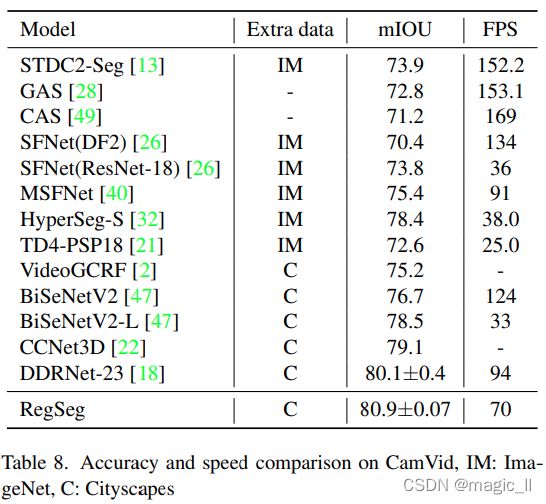
4.8. CamVid的比较
如表8所示,RegSeg在CamVid测试集上以每秒70帧的速度达到80.9mIOU。它的性能比之前的SOTA DDRNet-23好0.8%,比BiSeNetV2_L好2.4%。结果表明,RegSeg比DDRNet-23具有更好的通用性。请注意,两款模型的FPS不具有直接可比性,因为它们使用了不同的计时设置。
4.9. 城市景观比较
我们将其与其他实时模型进行比较,无论它们是否在ImageNet上进行了预训练。如图1和图7所示,RegSeg实现了最佳的参数精度和flops精度权衡。在表9中,我们展示了城市景观的精度和速度比较。再次请注意,不同模型的FPS没有直接可比性。
RegSeg的性能优于HarDNet[3],HarDNet[3]是之前的SOTA模型,没有额外数据,性能优于SFNet(DF2)[26],后者具有最好的同行评审结果,性能优于0.5%。RegSeg的表现也比流行的BiSeNet V2-L[47]好3.0%,比MobileNet V3+LRASPP[19]好5.7%。尽管DDRNet-23[18]的并行工作实现了比我们的模型更高的测试集精度,但我们认为他们的成功是由于他们的ImageNet预训练,同时也注意到RegSeg的参数和Flops要低得多。
为了说明我们的观点,我们展示了在使用完全相同的训练设置进行训练时,RegSeg的性能优于DDRNet23。在表10中,我们对每个模型进行3次训练,并显示平均值±一个标准偏差。使用第4.2节中介绍的训练设置。RegSeg的性能比DDRNet-23好0.5%,并且具有更好的参数和触发器效率。两种模型的FPS均使用第4.7章节的设置