云计算 - 4 - Spark的安装与应用
云计算 - 4 - Spark的安装与应用
-
- 目标
- Spark 的安装:
-
- 1、下载配置 Scala
-
- 1.1 下载 Scala
- 1.2 配置 Scala 的路径
- 1.3 测试 Scala 是否安装完成
- 2、下载配置Spark
-
- 2.1 下载Spark
- 2.2 配置 Spark 的路径
- 2.3 修改 Spark 的配置文件
- 3、将文件复制到子节点
- 4、启动Spark
- 5、测试Spark
-
- 5.1 创建测试文件
- 5.2 运行 WordCount 程序,得到结果
- Spark 的应用:
-
- 1、计算 pagerank
-
- 1.1 进入 spark-shell 交互式环境
- 1.2 编写程序
- 1.3 记录结果
- 2、WordCount
-
- 2.1 编写测试文件
- 2.2 进入 spark-shell 交互式环境
- 2.3 输入 WordCount 程序
- 2.4 记录结果
目标
实现 Linux 中 Spark 的安装与应用。
Spark 的安装:
1、下载配置 Scala
1.1 下载 Scala
创建文件夹 scala 用于安装 scala,通过 wget 下载 tar 包,然后解包安装 scala。
wget https://downloads.lightbend.com/scala/2.10.7/scala-2.10.7.tgz

tar -zxvf scala-2.10.7.taz

1.2 配置 Scala 的路径
通过修改 .bash_profile 文件来配置 Scala 路径,并使用 source 命令使其生效。

![]()
1.3 测试 Scala 是否安装完成
使用 scala -version 命令,若能正常显示,即说明安装配置成功。
![]()
2、下载配置Spark
2.1 下载Spark
类似于 Scala 的下载安装方式,同样使用 wget 下载 tar 包,然后解包,安装 Spark。
因下载时间过长,后面改为导入 tar 包安装。
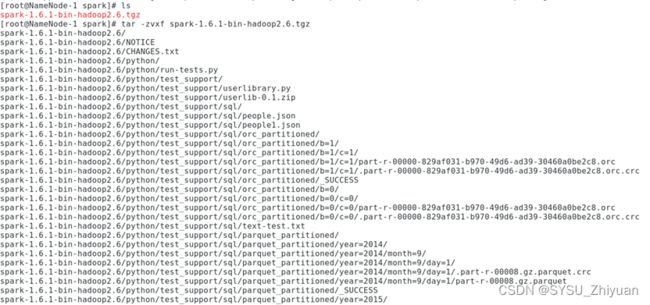
wget https://archive.apache.org/dist/spark/spark-1.6.1/spark-1.6.1-bin-hadoop2.6.tgz

tar -zvxf spark-1.6.1-bin-hadoop2.6.tgz
2.2 配置 Spark 的路径
通过修改 .bash_profile 文件来配置 Spark 路径,并使用 source 命令使其生效
![]()
![]()
2.3 修改 Spark 的配置文件
进入spark 的安装目录,转到 conf 目录中,创建并修改 slaves 文件,默认数据节点改为 DataNode-1
cd conf/
mv slaves.template slaves
vi slaves

mv spark-env.sh.template spark-env.sh
vi spark-env.sh

3、将文件复制到子节点
scp -r /home/spark/spark-1.6.1-bin-hadoop2.6 root@DataNode-1:/home/spark/
scp -r /home/scala/scala-2.10.7 root@DataNode-1:/home/scala/
scp ~/.bash_profile root@DataNode-1:~/.bash_profile


4、启动Spark

5、测试Spark
运行 spark 自带的 wordcount 程序进行测试
5.1 创建测试文件
创建一个 .txt 文件,输入一些字符,传入 HDFS 文件系统作为测试

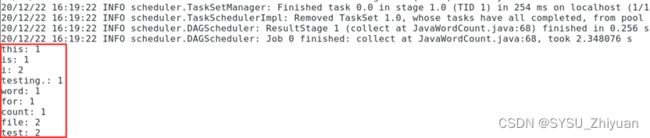
5.2 运行 WordCount 程序,得到结果
/home/spark/spark-1.6.1-bin-hadoop2.6/bin/run-exampleorg.apache.spark.examples.JavaWordCount hdfs://NameNode-1:9000/test111.txt
Spark 的应用:
1、计算 pagerank
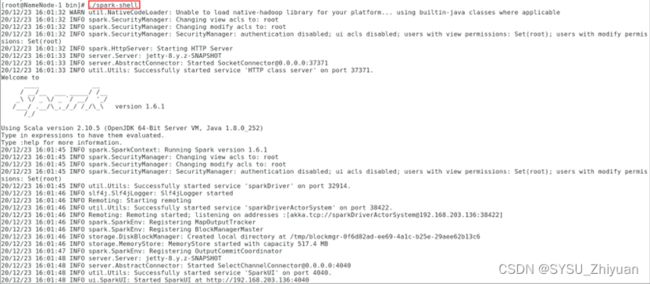
1.1 进入 spark-shell 交互式环境
1.2 编写程序
输入pagerank计算程序,如下:
import org.apache.spark.HashPartitioner
val links = sc.parallelize(List(("A",List("B","C")),("B",List("A","C")),("C",List("A","B", "D")),("D",List("C")))).partitionBy(new HashPartitioner(100)).persist()
var ranks=links.mapValues(v=>1.0)
for (i <- 0 until 10) {
val contributions=links.join(ranks).flatMap {
case (pageId,(links,rank)) => links.map(dest=>(dest,rank/links.size))
}
ranks=contributions.reduceByKey((x,y)=>x+y).mapValues(v=>0.15+0.85*v)
}
ranks.sortByKey().collect()
1.3 记录结果
运行程序,查看结果。
![]()
即:
(A,0.9850243302878132),
(B,0.9850243302878132),
(C,1.4621033282930214),
(D,0.5678480111313515)
符合预期。
2、WordCount
2.1 编写测试文件
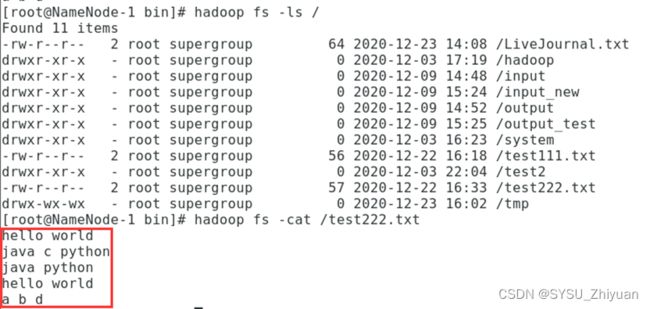
编写一个 .txt 文件作为 WordCount 的输入,传入 hdfs 文件系统中。
2.2 进入 spark-shell 交互式环境
同上一步 pagerank 1.1 中,进入 spark-shell 交互式环境。
2.3 输入 WordCount 程序
var input = sc.textFile("/NOTICE.txt")
input.flatMap(x=>x.split(" ")).countByValue()
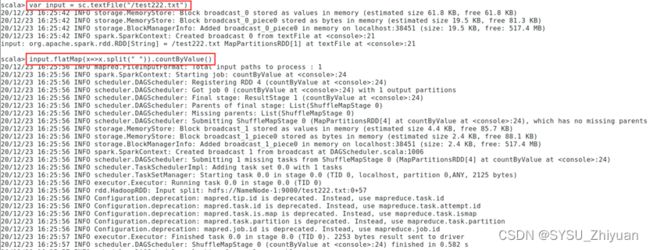
2.4 记录结果
运行程序,查看结果。
![]()
即:world -> 2, a -> 1, java -> 2, b -> 1, python -> 2, c -> 1, hello -> 2, d -> 1
符合预期。